Spostare i tuoi dati in un servizio cloud pubblico è una decisione importante. Tutti i principali fornitori di cloud offrono servizi di database cloud, con Amazon RDS per MySQL probabilmente il più popolare.
In questo blog analizzeremo da vicino di cosa si tratta, come funziona e confronteremo i suoi pro e contro.
RDS (Relational Database Service) è un'offerta di Amazon Web Services. In breve, è un Database as a Service, in cui Amazon distribuisce e gestisce il tuo database. Si occupa di attività come il backup e l'applicazione di patch al software del database, nonché l'elevata disponibilità. Alcuni database sono supportati da RDS, ma qui siamo principalmente interessati a MySQL:Amazon supporta MySQL e MariaDB. C'è anche Aurora, che è il clone di MySQL di Amazon, migliorato, soprattutto nell'area della replica e dell'alta disponibilità.
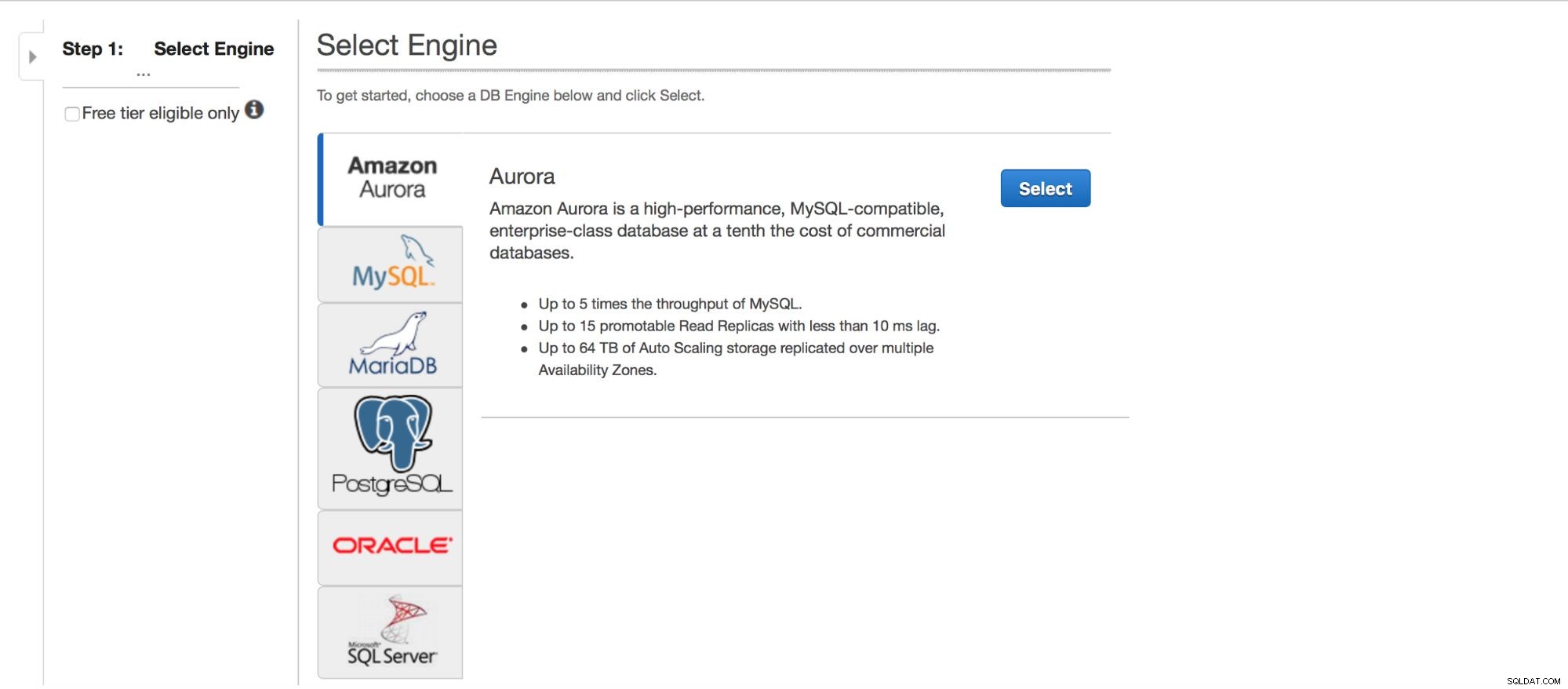
Distribuzione di MySQL tramite RDS
Diamo un'occhiata alla distribuzione di MySQL tramite RDS. Abbiamo scelto MySQL e quindi ci vengono presentati un paio di modelli di distribuzione tra cui scegliere.
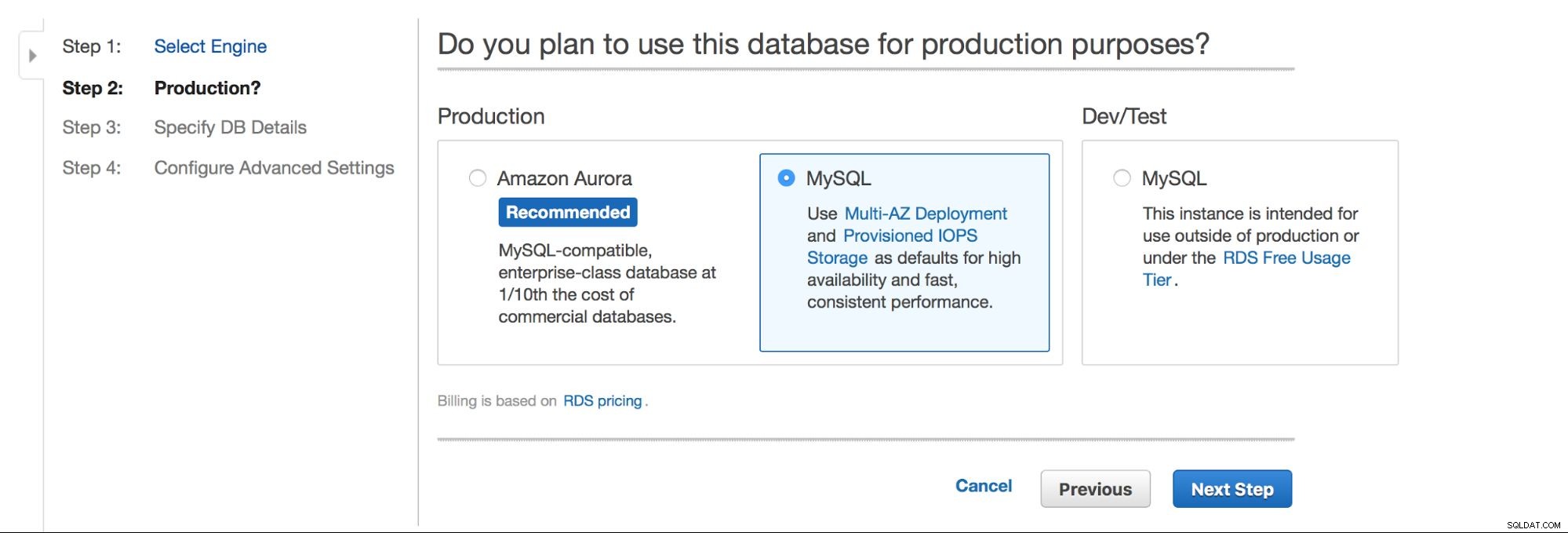
La scelta principale è:vogliamo avere un'alta disponibilità o no? Viene promossa anche Aurora.
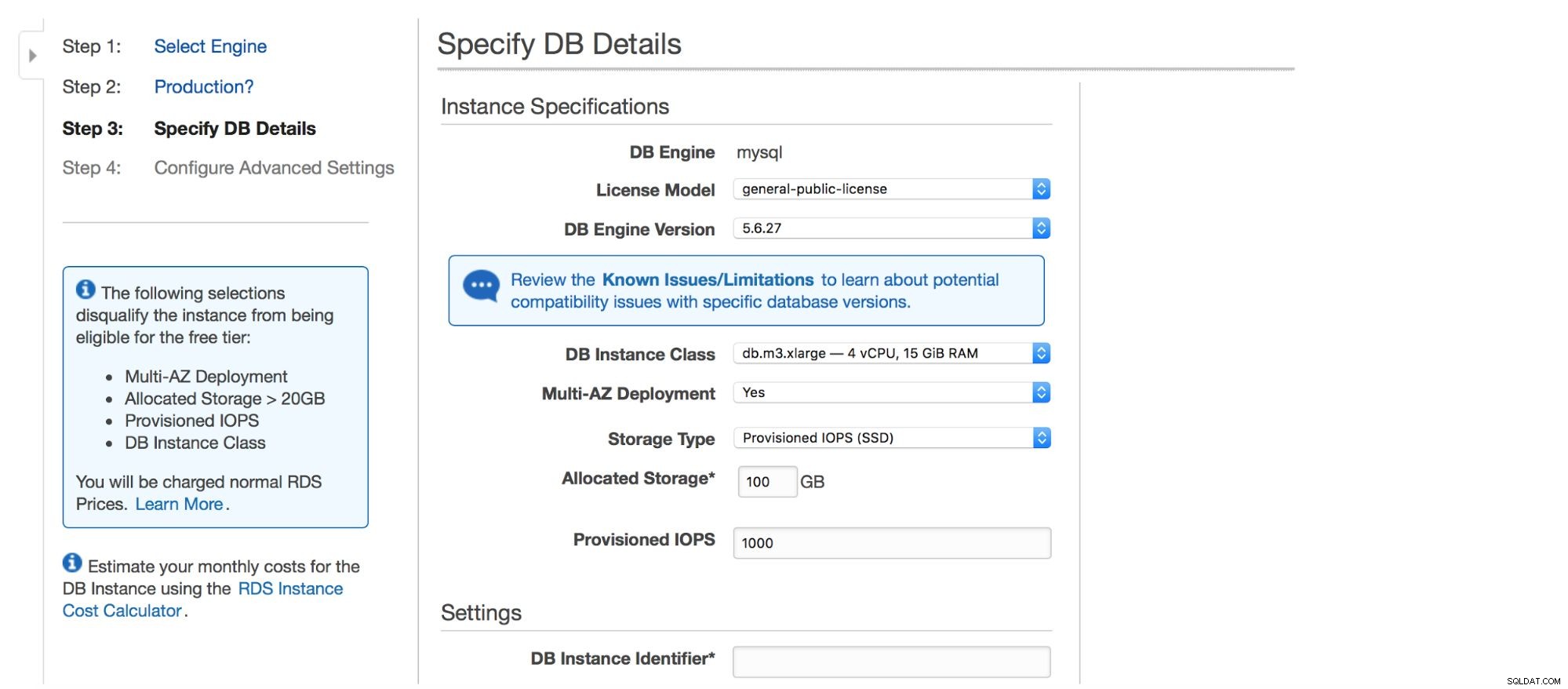
La finestra di dialogo successiva fornisce alcune opzioni per la personalizzazione. Puoi scegliere una delle tante versioni di MySQL:sono disponibili diverse versioni 5.5, 5.6 e 5.7. Istanza del database:puoi scegliere tra le dimensioni tipiche delle istanze disponibili in una determinata regione.
La prossima opzione è una scelta piuttosto importante:vuoi usare la distribuzione multi-AZ o no? Si tratta di un'elevata disponibilità. Se non desideri utilizzare la distribuzione multi-AZ, verrà installata una singola istanza. In caso di guasto, ne verrà avviata una nuova e il suo volume di dati verrà rimontato su di essa. Questo processo richiede del tempo, durante il quale il database non sarà disponibile. Naturalmente, puoi ridurre al minimo questo impatto utilizzando gli slave e promuovendone uno, ma non è un processo automatizzato. Se vuoi avere un'alta disponibilità automatizzata, dovresti usare la distribuzione multi-AZ. Quello che accadrà è che verranno create due istanze di database. Uno ti è visibile. Una seconda istanza, in una zona di disponibilità separata, non è visibile all'utente. Agirà come una copia shadow, pronta a prendere il controllo del traffico una volta che il nodo attivo si guasta. Non è ancora una soluzione perfetta poiché il traffico deve essere spostato dall'istanza non riuscita a quella shadow. Nei nostri test, ci sono voluti circa 45 secondi per eseguire un failover ma, ovviamente, può dipendere dalle dimensioni dell'istanza, dalle prestazioni di I/O ecc. Ma è molto meglio del failover non automatizzato in cui sono coinvolti solo gli slave.
Infine, abbiamo le impostazioni di archiviazione - tipo, dimensione, PIOPS (ove applicabile) e le impostazioni del database - identificatore, utente e password.
Nel passaggio successivo, alcune altre opzioni sono in attesa dell'input dell'utente.
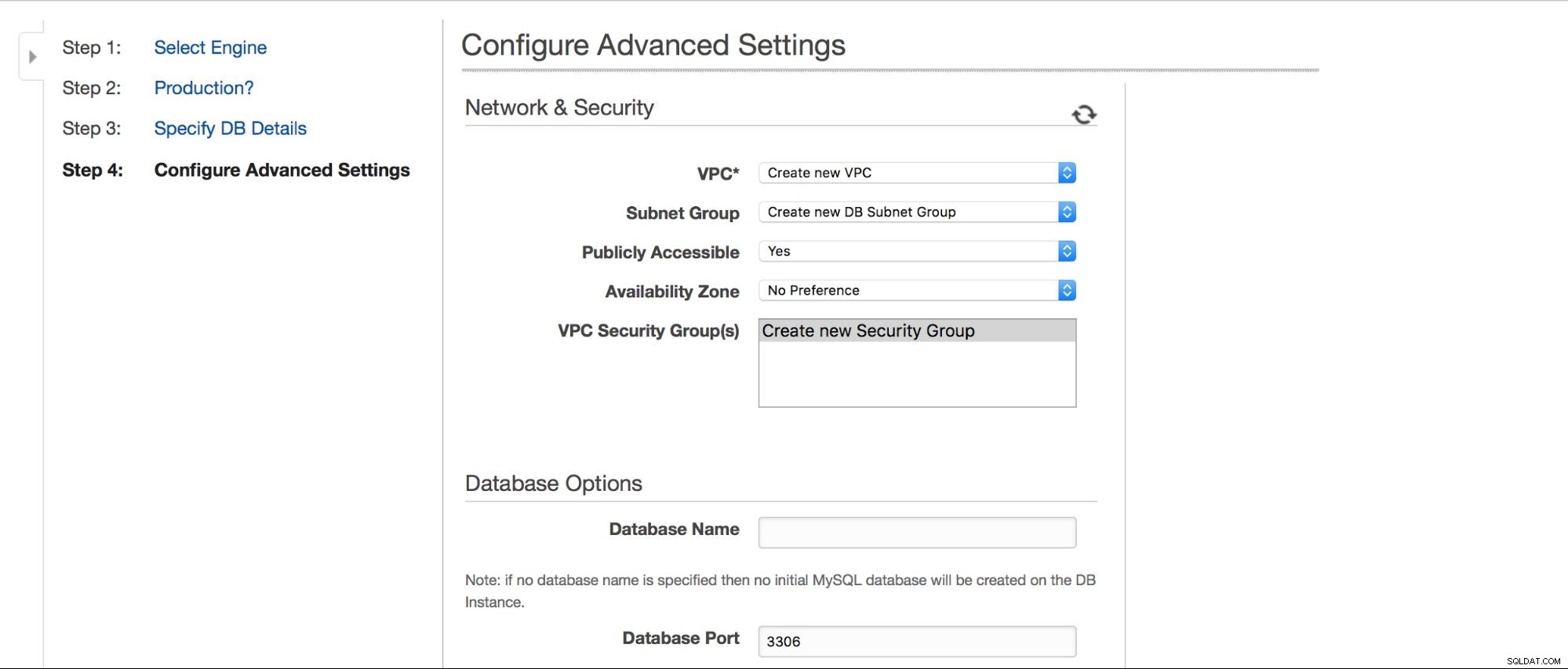
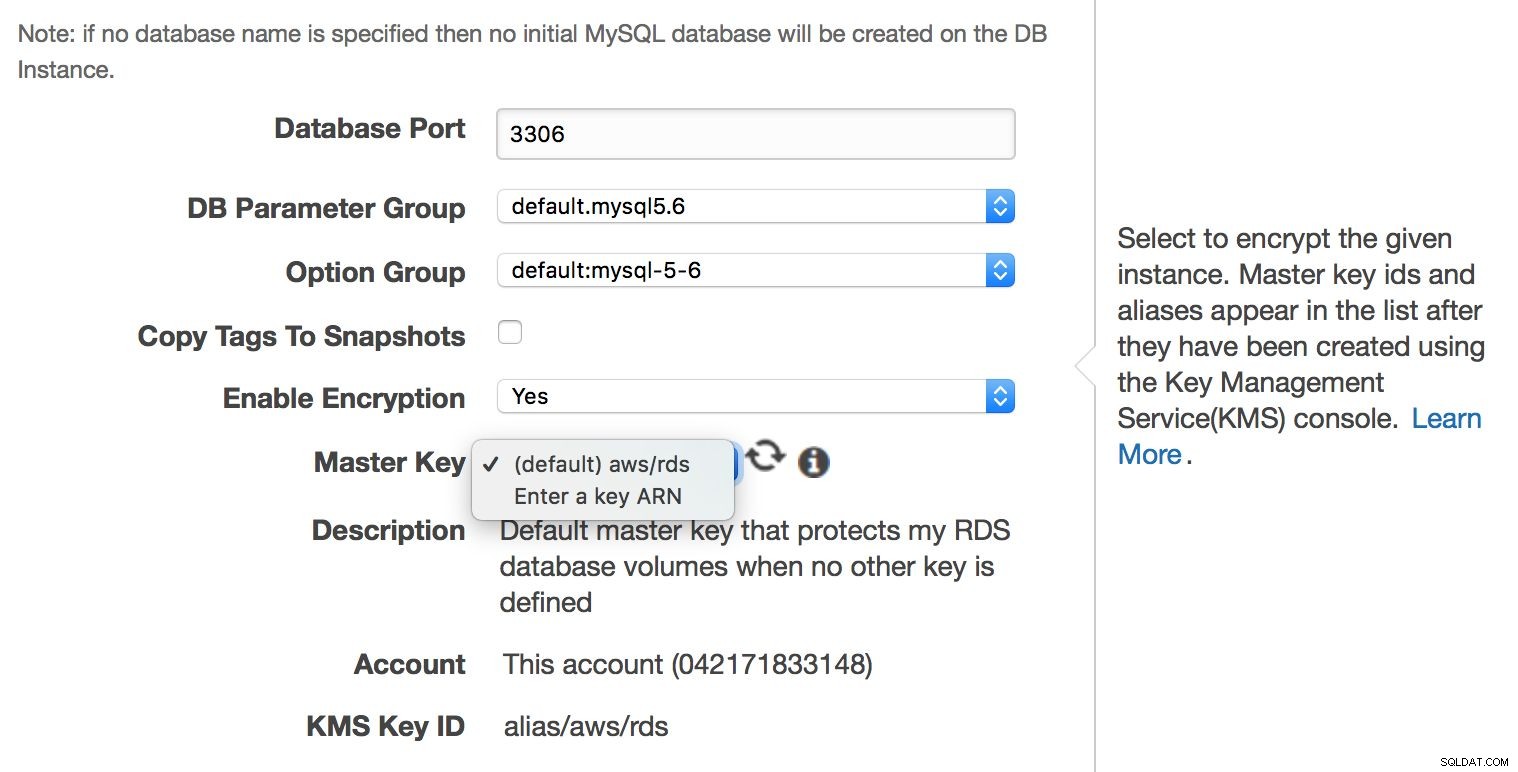
Possiamo scegliere dove deve essere creata l'istanza:VPC, sottorete, se è disponibile pubblicamente o meno (come in - se un IP pubblico deve essere assegnato all'istanza RDS), zona di disponibilità e gruppo di sicurezza VPC. Quindi, abbiamo le opzioni del database:primo schema da creare, porta, parametri e gruppi di opzioni, se i tag dei metadati devono essere inclusi o meno negli snapshot, le impostazioni di crittografia.
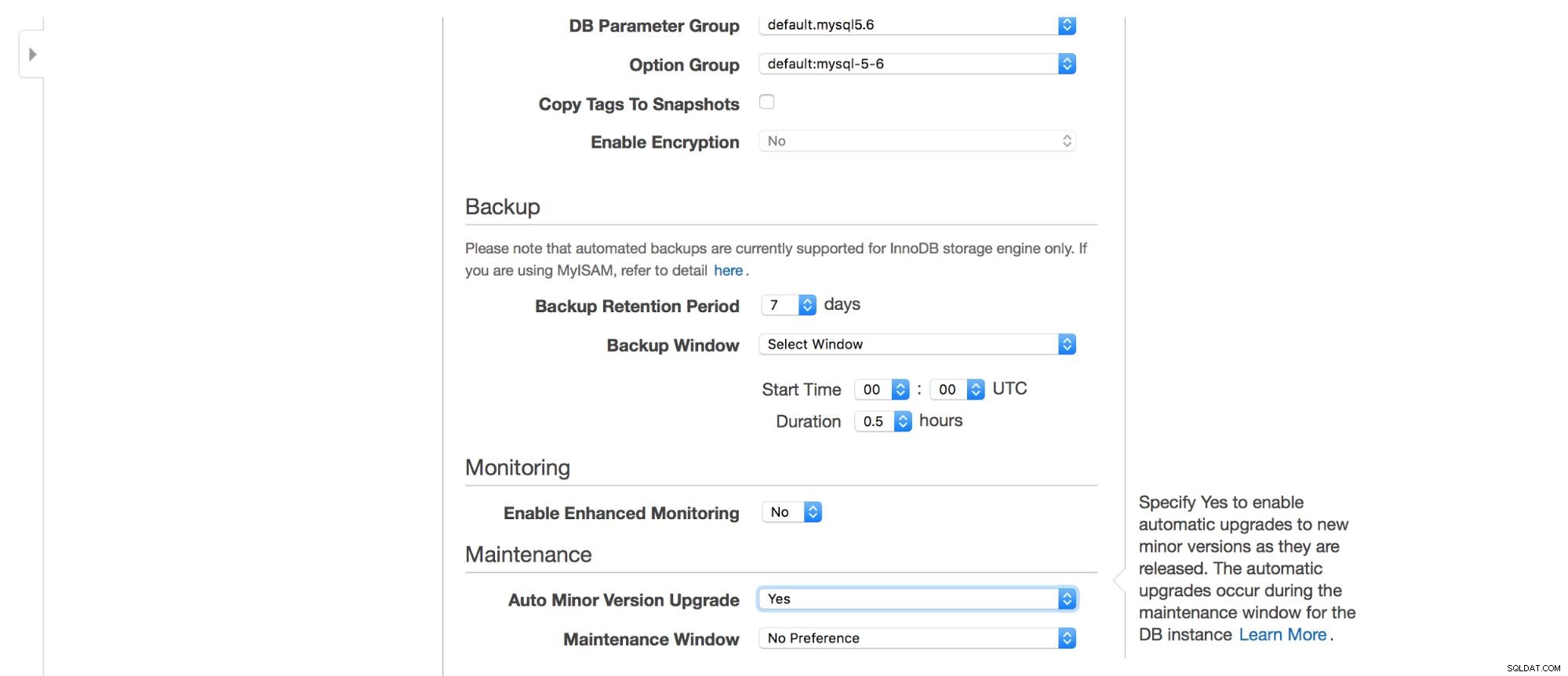
Quindi, opzioni di backup:per quanto tempo vuoi conservare i tuoi backup? Quando li vorresti presi? Una configurazione simile è correlata alle manutenzioni - a volte gli amministratori Amazon devono eseguire la manutenzione sull'istanza RDS - avverrà all'interno di una finestra predefinita che puoi impostare qui. Tieni presente che non è possibile non selezionare almeno 30 minuti per la finestra di manutenzione, ecco perché avere un'istanza multi-AZ in produzione è davvero importante. La manutenzione può comportare il riavvio del nodo o la mancanza di disponibilità per qualche tempo. Senza multi-AZ, devi accettare quei tempi di inattività. Con l'implementazione multi-AZ, si verifica il failover.
Infine, abbiamo le impostazioni relative al monitoraggio aggiuntivo:vogliamo averlo abilitato o no?
Gestione RDS
In questo capitolo daremo uno sguardo più da vicino a come gestire MySQL RDS. Non esamineremo tutte le opzioni disponibili, ma vorremmo evidenziare alcune delle funzionalità rese disponibili da Amazon.
Istantanee
MySQL RDS utilizza i volumi EBS come storage, quindi può utilizzare snapshot EBS per scopi diversi. Backup, slave:tutto basato su snapshot. È possibile creare istantanee manualmente oppure possono essere scattate automaticamente, quando si presenta tale necessità. È importante tenere presente che gli snapshot EBS, in generale (non solo nelle istanze RDS), aggiungono un sovraccarico alle operazioni di I/O. Se vuoi scattare un'istantanea, aspettati che le tue prestazioni di I/O diminuiscano. A meno che non utilizzi la distribuzione multi-AZ, cioè. In tal caso, l'istanza "shadow" verrà utilizzata come fonte di snapshot e nessun impatto sarà visibile sull'istanza di produzione.
Diversinines DevOps Guide to Database ManagementScopri cosa devi sapere per automatizzare e gestire i tuoi database open sourceScarica gratuitamenteBackup
I backup si basano su snapshot. Come accennato in precedenza, puoi definire la pianificazione e la conservazione del backup quando crei una nuova istanza. Naturalmente, puoi modificare queste impostazioni in seguito, tramite l'opzione "modifica istanza".
In qualsiasi momento puoi ripristinare uno snapshot:devi andare alla sezione snapshot, scegliere lo snapshot che desideri ripristinare e ti verrà presentata una finestra di dialogo simile a quella che hai visto quando hai creato una nuova istanza. Questa non è una sorpresa in quanto puoi ripristinare uno snapshot solo in una nuova istanza:non è possibile ripristinarlo su una delle istanze RDS esistenti. Potrebbe sorprendere, ma anche in ambiente cloud può avere senso riutilizzare l'hardware (e le istanze che già possiedi). In un ambiente condiviso, le prestazioni di una singola istanza virtuale possono differire:potresti preferire attenersi al profilo delle prestazioni con cui hai già familiarità. Sfortunatamente, non è possibile in RDS.
Un'altra opzione in RDS è il ripristino point-in-time, una caratteristica molto importante, un requisito per chiunque abbia bisogno di prendersi cura dei propri dati. Qui le cose sono più complesse e meno luminose. Per cominciare, è importante tenere a mente che MySQL RDS nasconde i log binari all'utente. Puoi modificare un paio di impostazioni ed elencare i binlog creati, ma non hai accesso diretto ad essi:per eseguire qualsiasi operazione, incluso il loro utilizzo per il ripristino, puoi utilizzare solo l'interfaccia utente o la CLI. Ciò limita le tue opzioni a ciò che Amazon ti consente di fare e ti consente di ripristinare il backup fino all'ultimo "tempo ripristinabile" che viene calcolato in un intervallo di 5 minuti. Quindi, se i tuoi dati sono stati rimossi alle 9:33a, puoi ripristinarli solo fino allo stato alle 9:30a. Il ripristino point-in-time funziona allo stesso modo del ripristino degli snapshot:viene creata una nuova istanza.
Ridimensionamento, replica
MySQL RDS consente lo scale-out aggiungendo nuovi slave. Quando viene creato uno slave, viene acquisita un'istantanea del master e viene utilizzata per creare un nuovo host. Questa parte funziona abbastanza bene. Sfortunatamente, non è possibile creare una topologia di replica più complessa come quella che coinvolge master intermedi. Non sei in grado di creare una configurazione master - master, che lascia qualsiasi HA nelle mani di Amazon (e distribuzioni multi-AZ). Da quello che possiamo dire, non c'è modo di abilitare GTID (non che tu possa trarne vantaggio in quanto non hai alcun controllo sulla replica, nessun CHANGE MASTER in RDS), solo posizioni binlog regolari e vecchio stile.
La mancanza di GTID rende non fattibile l'uso della replica multithread - mentre è possibile impostare un numero di lavoratori utilizzando gruppi di parametri RDS, senza GTID questo è inutilizzabile. Il problema principale è che non c'è modo di individuare una singola posizione del log binario in caso di arresto anomalo:alcuni lavoratori potrebbero essere rimasti indietro, altri potrebbero essere più avanzati. Se utilizzi l'ultimo evento applicato, perderai i dati che non sono stati ancora applicati da quei lavoratori "in ritardo". Se utilizzerai l'evento più vecchio, molto probabilmente ti ritroverai con errori di "chiave duplicata" causati da eventi applicati da quei lavoratori più avanzati. Certo, c'è un modo per risolvere questo problema, ma non è banale e richiede molto tempo, sicuramente non è qualcosa che potresti facilmente automatizzare.
Gli utenti creati su MySQL RDS non hanno il privilegio SUPER, quindi le operazioni, che sono semplici in MySQL autonomo, non sono banali in RDS. Amazon ha deciso di utilizzare le procedure memorizzate per consentire all'utente di eseguire alcune di queste operazioni. Da quello che possiamo dire, una serie di potenziali problemi sono coperti anche se non è sempre stato così:ricordiamo quando non è stato possibile ruotare al registro binario successivo sul master. Un arresto anomalo del master + la corruzione del binlog potrebbero rendere interrotti tutti gli slave - ora c'è una procedura per questo:rds_next_master_log .
Uno slave può essere promosso manualmente a master. Ciò ti consentirebbe di creare una sorta di HA in cima al meccanismo multi-AZ (o bypassarlo), ma è stato reso inutile dal fatto che non puoi rislavare nessuno degli slave esistenti al nuovo master. Ricorda, non hai alcun controllo sulla replica. Questo rende l'intero esercizio futile, a meno che il tuo maestro non possa accogliere tutto il tuo traffico. Dopo aver promosso un nuovo master, non puoi eseguire il failover su di esso perché non ha alcuno slave per gestire il tuo carico. La creazione di nuovi slave richiederà tempo poiché è necessario creare prima gli snapshot EBS e ciò potrebbe richiedere ore. Quindi, devi riscaldare l'infrastruttura prima di poterla caricare.
Mancanza di SUPER Privilegi
Come affermato in precedenza, RDS non garantisce agli utenti il privilegio SUPER e questo diventa fastidioso per qualcuno che è abituato ad averlo su MySQL. Dai per scontato che, nelle prime settimane, imparerai quanto spesso è necessario fare cose che fai piuttosto frequentemente, come uccidere le query o utilizzare lo schema delle prestazioni. In RDS, dovrai attenerti all'elenco predefinito di procedure archiviate e utilizzarle invece di eseguire le operazioni direttamente. Puoi elencarli tutti usando la seguente query:
SELECT specific_name FROM information_schema.routines;Come per la replica, vengono coperte una serie di attività, ma se ti trovi in una situazione che non è ancora stata affrontata, sei sfortunato.
Interoperabilità e configurazioni di cloud ibrido
Questa è un'altra area in cui RDS manca di flessibilità. Supponiamo che tu voglia creare una configurazione mista cloud/on-premise:hai un'infrastruttura RDS e desideri creare un paio di slave in locale. Il problema principale che dovrai affrontare è che non c'è modo di spostare i dati fuori da RDS se non per eseguire un dump logico. Puoi acquisire snapshot di dati RDS ma non hai accesso ad essi e non puoi spostarli da AWS. Inoltre, non hai accesso fisico all'istanza per utilizzare xtrabackup, rsync o persino cp. L'unica opzione per te è usare mysqldump, mydumper o strumenti simili. Ciò aggiunge complessità (l'insieme dei caratteri e le impostazioni di confronto possono potenzialmente causare problemi) e richiede molto tempo (ci vuole molto tempo per scaricare e caricare i dati utilizzando gli strumenti di backup logico).
È possibile configurare la replica tra RDS e un'istanza esterna (in entrambi i modi, quindi è possibile anche migrare i dati in RDS), ma può richiedere molto tempo.
D'altra parte, se vuoi rimanere in un ambiente RDS e estendere la tua infrastruttura attraverso l'Atlantico o dalla costa orientale a quella occidentale degli Stati Uniti, RDS ti consente di farlo:puoi facilmente scegliere una regione quando crei un nuovo schiavo.
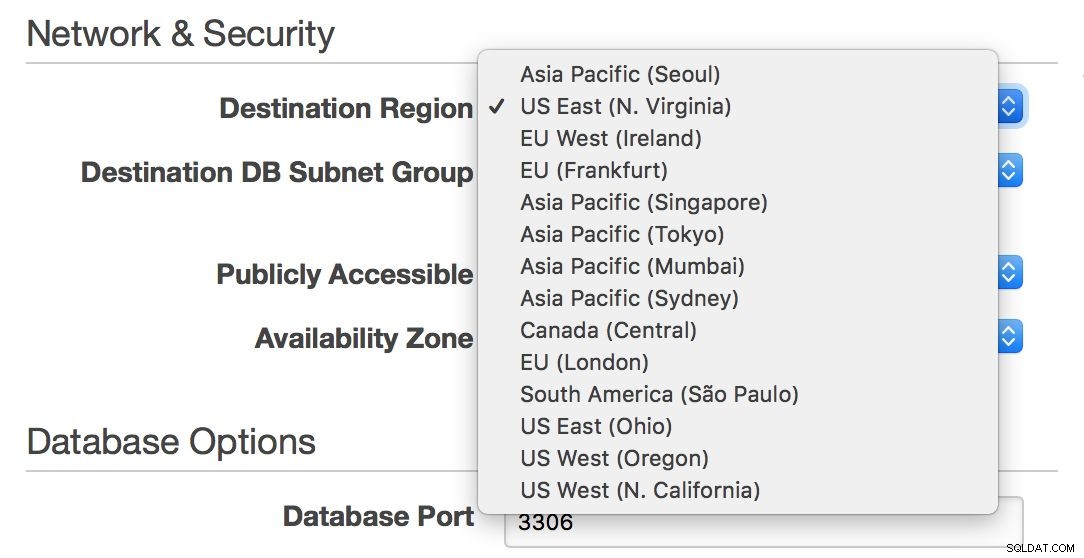
Sfortunatamente, se desideri spostare il tuo master da una regione all'altra, questo non è praticamente possibile senza tempi di inattività, a meno che il tuo singolo nodo non sia in grado di gestire tutto il tuo traffico.
Sicurezza
Sebbene MySQL RDS sia un servizio gestito, gli ingegneri di Amazon non si occupano di tutti gli aspetti relativi alla sicurezza. Amazon lo chiama "Modello di responsabilità condivisa". In breve, Amazon si occupa della sicurezza della rete e del livello di storage (in modo che i dati vengano trasferiti in modo sicuro), del sistema operativo (patch, security fix). D'altra parte, l'utente deve prendersi cura del resto del modello di sicurezza. Assicurati che il traffico da e verso l'istanza RDS sia limitato all'interno del VPC, assicurati che l'autenticazione a livello di database sia eseguita correttamente (nessun account utente MySQL senza password), verifica che la sicurezza dell'API sia garantita (le AMI sono impostate correttamente e con privilegi minimi richiesti). L'utente deve anche occuparsi delle impostazioni del firewall (gruppi di sicurezza) per ridurre al minimo l'esposizione di RDS e del VPC in cui si trova alle reti esterne. È anche responsabilità dell'utente implementare la crittografia dei dati inattivi, a livello di applicazione o di database, creando in primo luogo un'istanza RDS crittografata.
La crittografia a livello di database può essere abilitata solo alla creazione dell'istanza, non puoi crittografare un database esistente già in esecuzione.
Limiti RDS
Se prevedi di utilizzare RDS o se lo stai già utilizzando, devi essere consapevole delle limitazioni che derivano da MySQL RDS.
Mancanza di SUPER privilegio può essere, come abbiamo detto, molto fastidioso. Sebbene le stored procedure si occupino di una serie di operazioni, è una curva di apprendimento poiché è necessario imparare a fare le cose in un modo diverso. La mancanza del privilegio SUPER può anche creare problemi nell'utilizzo di strumenti di monitoraggio e trend esterni:ci sono ancora alcuni strumenti che potrebbero richiedere questo privilegio per alcune parti delle sue funzionalità.
La mancanza di accesso diretto alla directory dei dati e ai log di MySQL rende più difficile l'esecuzione delle azioni che li coinvolge. Di tanto in tanto capita che un DBA debba analizzare i log binari o l'errore di coda, la query lenta o il log generale. Sebbene sia possibile accedere a quei registri su RDS, è più ingombrante che fare tutto ciò di cui hai bisogno accedendo alla shell sull'host MySQL. Anche il download locale richiede del tempo e aggiunge ulteriore latenza a qualsiasi cosa tu faccia.
Mancanza di controllo sulla topologia di replica, disponibilità elevata solo nelle implementazioni multi-AZ. Dato che non hai il controllo sulla replica, non puoi implementare alcun tipo di meccanismo di alta disponibilità nel tuo livello di database. Non importa che tu abbia diversi schiavi, non puoi usarne alcuni come candidati master perché anche se promuovi uno schiavo a padrone, non c'è modo di rislavare gli schiavi rimanenti da questo nuovo padrone. Ciò costringe gli utenti a utilizzare implementazioni multi-AZ e ad aumentare i costi (l'istanza "ombra" non è gratuita, l'utente deve pagarla).
Disponibilità ridotta grazie ai tempi di inattività pianificati. Quando si distribuisce un'istanza RDS, si è costretti a scegliere un intervallo di tempo settimanale di 30 minuti durante il quale le operazioni di manutenzione possono essere eseguite sull'istanza RDS. Da un lato, questo è comprensibile poiché RDS è un Database as a Service, quindi gli aggiornamenti hardware e software delle tue istanze RDS sono gestiti dagli ingegneri AWS. D'altra parte, questo riduce la tua disponibilità perché non puoi impedire che il tuo database principale si interrompa per la durata del periodo di manutenzione. Anche in questo caso, l'utilizzo dell'installazione multi-AZ aumenta la disponibilità poiché le modifiche si verificano prima sull'istanza shadow e quindi viene eseguito il failover. Il failover stesso, tuttavia, non è trasparente, quindi, in un modo o nell'altro, si perde il tempo di attività. Questo ti obbliga a progettare la tua app tenendo a mente errori master MySQL imprevisti. Non che sia un modello di progettazione errato:i database possono bloccarsi in qualsiasi momento e la tua applicazione dovrebbe essere costruita in modo tale da resistere anche allo scenario più terribile. È solo che con RDS hai opzioni limitate per l'alta disponibilità.
Opzioni ridotte per l'implementazione della disponibilità elevata. Data la mancanza di flessibilità nella gestione della topologia di replica, l'unico metodo di disponibilità elevata fattibile è la distribuzione multi-AZ. Questo metodo è buono, ma ci sono strumenti per la replica di MySQL che minimizzerebbero ulteriormente i tempi di inattività. Ad esempio, MHA o ClusterControl, se utilizzati in connessione con ProxySQL, possono fornire (in alcune condizioni come la mancanza di transazioni di lunga durata) un processo di failover trasparente per l'applicazione. Mentre sei su RDS, non potrai utilizzare questo metodo.
Ridotte informazioni sulle prestazioni del tuo database. Sebbene tu possa ottenere le metriche da MySQL stesso, a volte non è sufficiente per avere una visione completa della situazione di 10.000 piedi. Ad un certo punto, la maggior parte degli utenti dovrà affrontare problemi davvero strani causati da hardware difettoso o infrastruttura difettosa:pacchetti di rete persi, connessioni interrotte bruscamente o utilizzo inaspettatamente elevato della CPU. Quando hai accesso al tuo host MySQL, puoi sfruttare molti strumenti che ti aiutano a diagnosticare lo stato di un server Linux. Quando utilizzi RDS, sei limitato a quali parametri sono disponibili in Cloudwatch, lo strumento di monitoraggio e trend di Amazon. Qualsiasi diagnosi più dettagliata richiede di contattare l'assistenza e chiedere loro di verificare e risolvere il problema. Questo può essere veloce, ma può anche essere un processo molto lungo con molte comunicazioni e-mail avanti e indietro.
Blocco del fornitore causato dal processo complesso e dispendioso in termini di tempo per estrarre i dati da MySQL RDS. RDS non garantisce l'accesso alla directory dei dati di MySQL, quindi non c'è modo di utilizzare strumenti standard del settore come xtrabackup per spostare i dati in modo binario. D'altra parte, l'RDS sotto il cofano è un MySQL gestito da Amazon, è difficile dire se è compatibile al 100% con l'upstream o meno. RDS è disponibile solo su AWS, quindi non saresti in grado di eseguire una configurazione ibrida.
Riepilogo
MySQL RDS ha sia punti di forza che di debolezza. Questo è un ottimo strumento per coloro che desiderano concentrarsi sull'applicazione senza doversi preoccupare di gestire il database. Distribuisci un database e inizi a inviare query. Non è necessario creare script di backup o configurare soluzioni di monitoraggio perché è già stato eseguito dagli ingegneri AWS:tutto ciò che devi fare è usarlo.
C'è anche un lato oscuro di MySQL RDS. Mancanza di opzioni per creare configurazioni e ridimensionamenti più complessi al di fuori della semplice aggiunta di più slave. Mancanza di supporto per una migliore disponibilità elevata rispetto a quanto proposto nelle distribuzioni multi-AZ. Accesso ingombrante ai log di MySQL. Mancanza di accesso diretto alla directory dei dati MySQL e mancanza di supporto per i backup fisici, il che rende difficile spostare i dati fuori dall'istanza RDS.
Per riassumere, RDS potrebbe funzionare bene per te se apprezzi la facilità d'uso rispetto al controllo dettagliato del database. Devi tenere a mente che, in futuro, potresti diventare troppo grande per MySQL RDS. Non stiamo necessariamente parlando qui solo di prestazioni. Si tratta più delle esigenze della tua organizzazione per una topologia di replica più complessa o della necessità di avere una visione migliore delle operazioni del database per affrontare rapidamente i diversi problemi che si verificano di volta in volta. In tal caso, se le dimensioni del tuo set di dati sono già aumentate, potresti trovare difficile uscire dall'RDS. Prima di prendere qualsiasi decisione per spostare i tuoi dati in RDS, i gestori delle informazioni devono considerare i requisiti e i vincoli della loro organizzazione in aree specifiche.
Nei prossimi due post sul blog ti mostreremo come portare i tuoi dati fuori dall'RDS in una posizione separata. Discuteremo sia della migrazione a EC2 che all'infrastruttura locale.