La gestione di NULL è uno degli aspetti più complicati della modellazione dei dati e della manipolazione dei dati con SQL. Cominciamo dal fatto che un tentativo di spiegare esattamente cos'è un NULL non è banale in sé e per sé. Anche tra le persone che hanno una buona conoscenza della teoria relazionale e dell'SQL, sentirai opinioni molto forti sia a favore che contro l'uso di NULL nel tuo database. Che piacciano o meno a loro, come professionista di database devi spesso affrontarli e dato che i NULL aggiungono complessità alla scrittura del codice SQL, è una buona idea rendere prioritaria la loro comprensione. In questo modo puoi evitare inutili bug e insidie.
Questo articolo è il primo di una serie sulle complessità NULL. Comincio con la copertura di cosa sono i NULL e come si comportano nei confronti. Quindi tratterò le incongruenze del trattamento NULL in diversi elementi linguistici. Infine, tratterò le funzionalità standard mancanti relative alla gestione di NULL in T-SQL e suggerisco alternative disponibili in T-SQL.
La maggior parte della copertura è rilevante per qualsiasi piattaforma che implementa un dialetto di SQL, ma in alcuni casi menziono aspetti specifici di T-SQL.
Nei miei esempi userò un database di esempio chiamato TSQLV5. Puoi trovare lo script che crea e popola questo database qui e il suo diagramma ER qui.
NULL come indicatore di un valore mancante
Iniziamo con la comprensione di cosa sono i NULL. In SQL, un NULL è un indicatore, o un segnaposto, per un valore mancante. È il tentativo di SQL di rappresentare nel database una realtà in cui un determinato valore di attributo è talvolta presente e talvolta mancante. Si supponga, ad esempio, di dover archiviare i dati dei dipendenti in una tabella Dipendenti. Hai attributi per nome, secondo nome e cognome. Gli attributi firstname e lastname sono obbligatori e quindi li definisci come non consentiti NULL. L'attributo middlename è facoltativo e quindi lo definisci come consentendo NULL.
Se ti stai chiedendo cosa ha da dire il modello relazionale sui valori mancanti, il creatore del modello Edgar F. Codd ci credeva. In effetti, ha anche fatto una distinzione tra due tipi di valori mancanti:mancante ma applicabile (indicatore di valori A) e mancante ma inapplicabile (indicatore di valori I). Se prendiamo l'attributo secondo nome come esempio, nel caso in cui un dipendente ha un secondo nome, ma per motivi di privacy sceglie di non condividere le informazioni, dovresti utilizzare l'indicatore A-Values. Nel caso in cui un dipendente non abbia affatto un secondo nome, dovresti utilizzare l'indicatore I-Values. Qui, lo stesso attributo a volte potrebbe essere rilevante e presente, a volte mancante ma applicabile ea volte mancante ma inapplicabile. Altri casi potrebbero essere più chiari, supportando solo un tipo di valori mancanti. Ad esempio, supponiamo di avere una tabella Ordini con un attributo chiamato data di spedizione contenente la data di spedizione dell'ordine. Un ordine che è stato spedito avrà sempre una data di spedizione presente e pertinente. L'unico caso per non avere una data di spedizione nota sarebbe per gli ordini che non sono stati ancora spediti. Quindi, qui, deve essere presente un valore di data di spedizione pertinente o deve essere utilizzato l'indicatore I-Values.
I progettisti di SQL hanno scelto di non entrare nella distinzione tra valori mancanti applicabili e inapplicabili e ci hanno fornito NULL come indicatore per qualsiasi tipo di valore mancante. Per la maggior parte, SQL è stato progettato per presupporre che i NULL rappresentino il tipo di valore mancante mancante ma applicabile. Di conseguenza, soprattutto quando l'utilizzo di NULL è come segnaposto per un valore inapplicabile, la gestione SQL NULL predefinita potrebbe non essere quella che ritieni corretta. A volte sarà necessario aggiungere una logica di gestione NULL esplicita per ottenere il trattamento che ritieni corretto per te.
Come best practice, se sai che un attributo non dovrebbe consentire NULL, assicurati di applicarlo con un vincolo NOT NULL come parte della definizione di colonna. Ci sono un paio di ragioni importanti per questo. Uno dei motivi è che se non lo applichi, a un certo punto o nell'altro, i NULL arriveranno. Potrebbe essere il risultato di un bug nell'applicazione o dell'importazione di dati errati. Usando un vincolo, sai che i NULL non arriveranno mai al tavolo. Un altro motivo è che l'ottimizzatore valuta vincoli come NOT NULL per una migliore ottimizzazione, evitando il lavoro non necessario alla ricerca di NULL e abilitando determinate regole di trasformazione.
Confronti che coinvolgono NULL
C'è qualche difficoltà nella valutazione dei predicati da parte di SQL quando sono coinvolti NULL. Per prima cosa tratterò i confronti che coinvolgono le costanti. Più avanti tratterò i confronti che coinvolgono variabili, parametri e colonne.
Quando si utilizzano predicati che confrontano gli operandi negli elementi della query come WHERE, ON e HAVING, i possibili risultati del confronto dipendono dal fatto che uno qualsiasi degli operandi possa essere un NULL. Se sai con certezza che nessuno degli operandi può essere un NULL, il risultato del predicato sarà sempre VERO o FALSO. Questo è ciò che è noto come logica del predicato a due valori, o in breve, semplicemente logica a due valori. Questo è il caso, ad esempio, del confronto di una colonna definita come non ammessa NULL con un altro operando non NULL.
Se uno qualsiasi degli operandi nel confronto può essere un NULL, ad esempio una colonna che consente NULL, utilizzando sia gli operatori di uguaglianza (=) che di disuguaglianza (<>,>, <,>=, <=, ecc.), sei ora alla mercé della logica dei predicati a tre valori. Se in un determinato confronto i due operandi sono valori non NULL, ottieni comunque TRUE o FALSE come risultato. Tuttavia, se uno qualsiasi degli operandi è NULL, si ottiene un terzo valore logico denominato UNKNOWN. Nota che questo è il caso anche quando si confrontano due NULL. Il trattamento di TRUE e FALSE da parte della maggior parte degli elementi di SQL è piuttosto intuitivo. Il trattamento di SCONOSCIUTO non è sempre così intuitivo. Inoltre, diversi elementi di SQL gestiscono il caso SCONOSCIUTO in modo diverso, come spiegherò in dettaglio più avanti nell'articolo in "Incoerenze di trattamento NULL".
Ad esempio, supponiamo di dover eseguire una query sulla tabella Sales.Orders nel database di esempio TSQLV5 e di restituire gli ordini spediti il 2 gennaio 2019. Utilizzare la query seguente:
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
È chiaro che il predicato del filtro restituisce TRUE per le righe la cui data di spedizione è il 2 gennaio 2019 e che tali righe devono essere restituite. È anche chiaro che il predicato restituisce FALSE per le righe in cui è presente la data di spedizione, ma non è il 2 gennaio 2019, e che tali righe devono essere eliminate. Ma per quanto riguarda le righe con una data di spedizione NULL? Ricorda che sia i predicati basati sull'uguaglianza che i predicati basati sulla disuguaglianza restituiscono UNKNOWN se uno qualsiasi degli operandi è NULL. Il filtro WHERE è progettato per eliminare tali righe. È necessario ricordare che il filtro WHERE restituisce le righe per le quali il predicato del filtro restituisce TRUE e scarta le righe per le quali il predicato restituisce FALSE o UNKNOWN.
Questa query genera il seguente output:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
Supponiamo di dover restituire gli ordini che non sono stati spediti il 2 gennaio 2019. Per quanto ti riguarda, gli ordini che non sono stati ancora spediti dovrebbero essere inclusi nell'output. Usi una query simile all'ultima, negando solo il predicato, in questo modo:
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
Questa query restituisce il seguente output:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
L'output esclude naturalmente le righe con data di spedizione 2 gennaio 2019, ma esclude anche le righe con data di spedizione NULL. Ciò che potrebbe essere controintuitivo qui è ciò che accade quando si utilizza l'operatore NOT per negare un predicato che restituisce SCONOSCIUTO. Ovviamente NON VERO è FALSO e NON FALSO è VERO. Tuttavia, NOT UNKNOWN rimane SCONOSCIUTO. La logica di SQL alla base di questo progetto è che se non sai se una proposizione è vera, non sai nemmeno se la proposizione non è vera. Ciò significa che quando si utilizzano gli operatori di uguaglianza e disuguaglianza nel predicato del filtro, né la forma positiva né quella negativa del predicato restituiscono le righe con i NULL.
Questo esempio è piuttosto semplice. Ci sono casi più complicati che coinvolgono subquery. Esiste un bug comune quando si utilizza il predicato NOT IN con una sottoquery, quando la sottoquery restituisce un NULL tra i valori restituiti. La query restituisce sempre un risultato vuoto. Il motivo è che la forma positiva del predicato (la parte IN) restituisce VERO quando viene trovato il valore esterno e SCONOSCIUTO quando non viene trovato a causa del confronto con il NULL. Quindi la negazione del predicato con l'operatore NOT restituisce sempre FALSO o SCONOSCIUTO, rispettivamente, mai un VERO. Tratto questo bug in dettaglio in bug T-SQL, insidie e best practice:sottoquery, incluse soluzioni suggerite, considerazioni sull'ottimizzazione e best practice. Se non hai già familiarità con questo classico bug, assicurati di controllare questo articolo poiché il bug è abbastanza comune e ci sono semplici misure che puoi adottare per evitarlo.
Tornando alla nostra esigenza, che dire del tentativo di restituire gli ordini con una data di spedizione diversa dal 2 gennaio 2019, utilizzando l'operatore diverso da (<>):
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
Sfortunatamente, entrambi gli operatori di uguaglianza e disuguaglianza restituiscono UNKNOWN quando uno qualsiasi degli operandi è NULL, quindi questa query genera il seguente output come la query precedente, esclusi i NULL:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
Per isolare il problema dei confronti con NULL che producono SCONOSCIUTO utilizzando l'uguaglianza, la disuguaglianza e la negazione dei due tipi di operatori, tutte le seguenti query restituiscono un set di risultati vuoto:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
Secondo SQL, non dovresti controllare se qualcosa è uguale a NULL o diverso da NULL, piuttosto se qualcosa è NULL o non è NULL, usando gli operatori speciali IS NULL e IS NOT NULL, rispettivamente. Questi operatori utilizzano una logica a due valori, restituendo sempre TRUE o FALSE. Ad esempio, utilizza l'operatore IS NULL per restituire gli ordini non spediti, in questo modo:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
Questa query genera il seguente output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
Utilizza l'operatore NON È NULL per restituire gli ordini spediti, in questo modo:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
Questa query genera il seguente output:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
Utilizza il codice seguente per restituire gli ordini spediti in una data diversa dal 2 gennaio 2019, nonché gli ordini non spediti:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
Questa query genera il seguente output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
In una parte successiva della serie tratterò le funzionalità standard per il trattamento NULL che attualmente mancano in T-SQL, incluso il predicato DISTINCT , che hanno il potenziale per semplificare notevolmente la gestione di NULL.
Confronti con variabili, parametri e colonne
La sezione precedente si è concentrata sui predicati che confrontano una colonna con una costante. In realtà, però, confronterai principalmente una colonna con variabili/parametri o con altre colonne. Tali confronti comportano ulteriori complessità.
Dal punto di vista della gestione NULL, variabili e parametri vengono trattati allo stesso modo. Userò le variabili nei miei esempi, ma i punti che faccio sulla loro gestione sono altrettanto rilevanti per i parametri.
Considera la seguente query di base (la chiamerò Query 1), che filtra gli ordini spediti in una determinata data:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Uso una variabile in questo esempio e la inizializzo con una data di esempio, ma anche questa potrebbe essere stata una query parametrizzata in una procedura memorizzata o una funzione definita dall'utente.
Questa esecuzione di query genera il seguente output:
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
Il piano per la query 1 è mostrato nella figura 1.
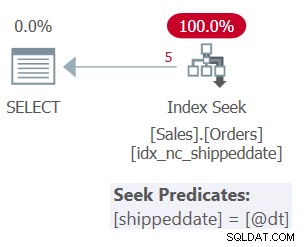 Figura 1:piano per la query 1
Figura 1:piano per la query 1
La tabella ha un indice di copertura per supportare questa query. L'indice si chiama idx_nc_shippeddate ed è definito con l'elenco di chiavi (shippeddate, orderid). Il predicato del filtro della query è espresso come un argomento di ricerca (SARG) , il che significa che consente all'ottimizzatore di considerare l'applicazione di un'operazione di ricerca nell'indice di supporto, andando direttamente all'intervallo di righe di qualificazione. Ciò che rende il predicato del filtro SARGable è che utilizza un operatore che rappresenta un intervallo consecutivo di righe di qualificazione nell'indice e che non applica la manipolazione alla colonna filtrata. Il piano che ottieni è il piano ottimale per questa query.
Ma cosa succede se si desidera consentire agli utenti di richiedere ordini non spediti? Tali ordini hanno una data di spedizione NULL. Ecco un tentativo di passare un NULL come data di input:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Come già sai, un predicato che utilizza un operatore di uguaglianza produce UNKNOWN quando uno qualsiasi degli operandi è NULL. Di conseguenza, questa query restituisce un risultato vuoto:
orderid shippeddate ----------- ----------- (0 rows affected)
Anche se T-SQL supporta un operatore IS NULL, non supporta un operatore IS
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
Questa query genera l'output corretto:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
Ma il piano per questa query, come mostrato nella Figura 2, non è ottimale.
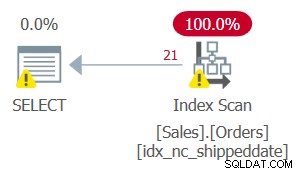 Figura 2:piano per la query 2
Figura 2:piano per la query 2
Poiché hai applicato la manipolazione alla colonna filtrata, il predicato del filtro non è più considerato un SARG. L'indice è ancora coprente, quindi può essere utilizzato; ma invece di applicare una ricerca nell'indice che va direttamente all'intervallo di righe di qualificazione, viene scansionata l'intera foglia dell'indice. Supponiamo che la tabella contenga 50.000.000 di ordini, con solo 1.000 ordini non spediti. Questo piano eseguirà la scansione di tutte le 50.000.000 di righe invece di eseguire una ricerca che va direttamente alle 1.000 righe qualificanti.
Una forma di predicato di filtro che ha entrambi il significato corretto che stiamo cercando ed è considerata un argomento di ricerca è (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Ecco una query che utilizza questo predicato SARGable (lo chiameremo Query 3):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
Il piano per questa query è mostrato nella Figura 3.
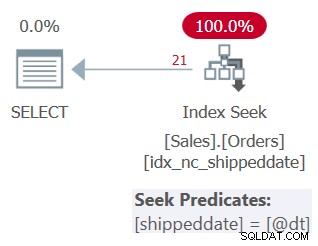 Figura 3:piano per la query 3
Figura 3:piano per la query 3
Come puoi vedere, il piano applica una ricerca nell'indice di supporto. Il predicato di ricerca dice shippingdate =@dt, ma è progettato internamente per gestire i valori NULL proprio come i valori non NULL per il bene del confronto.
Questa soluzione è generalmente considerata ragionevole. È standard, ottimale e corretto. Il suo principale svantaggio è che è dettagliato. E se avessi più predicati di filtro basati su colonne NULLable? Finiresti rapidamente con una clausola WHERE lunga e ingombrante. E peggiora molto quando devi scrivere un predicato di filtro che coinvolge una colonna NULLable alla ricerca di righe in cui la colonna è diversa dal parametro di input. Il predicato diventa quindi:(shippeddate <> @dt AND ((shippeddate IS NULL AND @dt IS NOT NULL) OR (shippeddate NON È NULL e @dt IS NULL))).
Puoi vedere chiaramente la necessità di una soluzione più elegante che sia concisa e ottimale. Sfortunatamente, alcuni ricorrono a una soluzione non standard in cui si disattiva l'opzione di sessione ANSI_NULLS. Questa opzione fa sì che SQL Server utilizzi la gestione non standard degli operatori di uguaglianza (=) e diversi da (<>) con logica a due valori anziché logica a tre valori, trattando i valori NULL come valori non NULL a scopo di confronto. Questo è almeno il caso finché uno degli operandi è un parametro/variabile o un valore letterale.
Eseguire il codice seguente per disattivare l'opzione ANSI_NULLS nella sessione:
SET ANSI_NULLS OFF;
Esegui la query seguente utilizzando un semplice predicato basato sull'uguaglianza:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Questa query restituisce i 21 ordini non spediti. Ottieni lo stesso piano mostrato in precedenza nella Figura 3, che mostra una ricerca nell'indice.
Esegui il codice seguente per tornare al comportamento standard in cui ANSI_NULLS è attivo:
SET ANSI_NULLS ON;
Affidarsi a un tale comportamento non standard è fortemente sconsigliato. La documentazione afferma inoltre che il supporto per questa opzione verrà rimosso in alcune versioni future di SQL Server. Inoltre, molti non si rendono conto che questa opzione è applicabile solo quando almeno uno degli operandi è un parametro/variabile o una costante, anche se la documentazione è abbastanza chiara a riguardo. Non si applica quando si confrontano due colonne come in un join.
Quindi, come gestisci i join che coinvolgono colonne di join NULLable se vuoi ottenere una corrispondenza quando i due lati sono NULL? Ad esempio, utilizzare il codice seguente per creare e popolare le tabelle T1 e T2:
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Il codice crea indici di copertura su entrambe le tabelle per supportare un join basato sulle chiavi di join (k1, k2, k3) in entrambi i lati.
Usa il codice seguente per aggiornare le statistiche sulla cardinalità, gonfiando i numeri in modo che l'ottimizzatore possa pensare che hai a che fare con tabelle più grandi:
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
Usa il codice seguente nel tentativo di unire le due tabelle usando semplici predicati basati sull'uguaglianza:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; Proprio come con i precedenti esempi di filtraggio, anche qui i confronti tra NULL usando un operatore di uguaglianza producono SCONOSCIUTO, risultando in non corrispondenze. Questa query genera un output vuoto:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
L'uso di ISNULL o COALESCE come in un esempio di filtro precedente, la sostituzione di un NULL con un valore che normalmente non può apparire nei dati in entrambi i lati, determina una query corretta (farò riferimento a questa query come Query 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); Questa query genera il seguente output:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Tuttavia, proprio come la manipolazione di una colonna filtrata interrompe la SARGability del predicato del filtro, la manipolazione di una colonna di join impedisce la possibilità di fare affidamento sull'ordine dell'indice. Questo può essere visto nel piano per questa query come mostrato nella Figura 4.
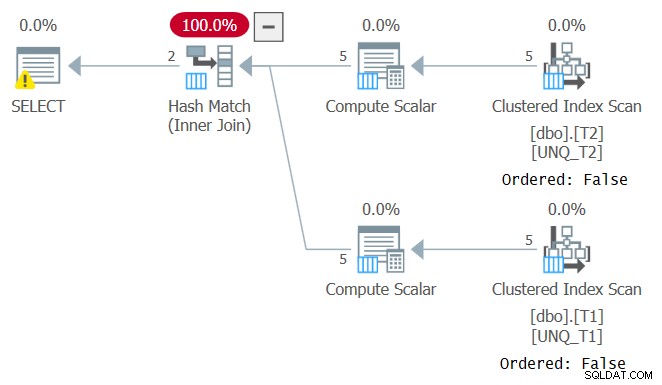 Figura 4:piano per la query 4
Figura 4:piano per la query 4
Un piano ottimale per questa query è quello che applica scansioni ordinate dei due indici di copertura seguite da un algoritmo Merge Join, senza un ordinamento esplicito. L'ottimizzatore ha scelto un piano diverso poiché non poteva fare affidamento sull'ordine dell'indice. Se tenti di forzare un algoritmo Merge Join usando INNER MERGE JOIN, il piano si baserebbe comunque su scansioni non ordinate degli indici, seguite da un ordinamento esplicito. Provalo!
Ovviamente puoi usare i lunghi predicati simili ai predicati SARGable mostrati in precedenza per filtrare le attività:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); Questa query produce il risultato desiderato e consente all'ottimizzatore di fare affidamento sull'ordine dell'indice. Tuttavia, la nostra speranza è di trovare una soluzione che sia ottimale e concisa.
Esiste una tecnica elegante e concisa poco conosciuta che puoi utilizzare sia nei join che nei filtri, sia allo scopo di identificare le corrispondenze che per identificare le non corrispondenze. Questa tecnica è stata scoperta e documentata già anni fa, come nell'eccellente articolo di Paul White Undocumented Query Plans:Equality Comparisons del 2011. Ma per qualche motivo sembra che ancora molte persone non ne siano consapevoli e sfortunatamente finiscano per usare un metodo non ottimale, lungo e soluzioni non standard. Merita sicuramente più visibilità e amore.
La tecnica si basa sul fatto che operatori di insiemi come INTERSECT ed EXCEPT utilizzano un approccio di confronto basato sulla distinzione quando si confrontano i valori e non un approccio di confronto basato su uguaglianza o disuguaglianza.
Considera la nostra attività di unione come esempio. Se non avessimo bisogno di restituire colonne diverse dalle chiavi di join, avremmo usato una semplice query (la chiamerò Query 5) con un operatore INTERSECT, in questo modo:
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
Questa query genera il seguente output:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
Il piano per questa query è mostrato nella Figura 5, a conferma che l'ottimizzatore è stato in grado di fare affidamento sull'ordine dell'indice e di utilizzare un algoritmo Merge Join.
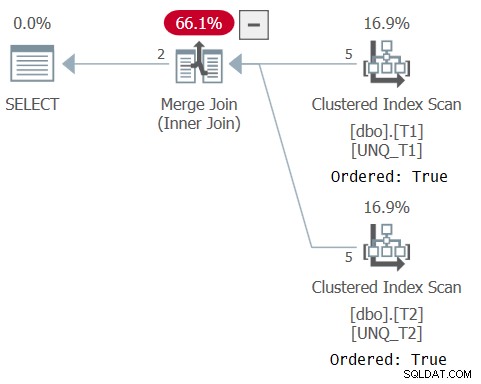 Figura 5:piano per la query 5
Figura 5:piano per la query 5
Come osserva Paul nel suo articolo, il piano XML per l'operatore set utilizza un operatore di confronto IS implicito (CompareOp="IS" ) rispetto all'operatore di confronto EQ utilizzato in un join normale (CompareOp="EQ" ). Il problema con una soluzione che si basa esclusivamente su un operatore di insiemi è che ti limita a restituire solo le colonne che stai confrontando. Ciò di cui abbiamo veramente bisogno è una sorta di ibrido tra un join e un operatore di insiemi, che consenta di confrontare un sottoinsieme di elementi restituendone altri aggiuntivi come fa un join e utilizzando il confronto basato sulla distinzione (IS) come fa un operatore di insiemi. Ciò è ottenibile utilizzando un join come costrutto esterno e un predicato EXISTS nella clausola ON del join basato su una query con un operatore INTERSECT che confronta le chiavi di join dai due lati, in questo modo (farò riferimento a questa soluzione come Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
L'operatore INTERSECT opera su due query, ciascuna formando un insieme di una riga in base alle chiavi di unione da entrambi i lati. Quando le due righe sono uguali, la query INTERSECT restituisce una riga; il predicato EXISTS restituisce TRUE, risultando in una corrispondenza. Quando le due righe non sono uguali, la query INTERSECT restituisce un set vuoto; il predicato EXISTS restituisce FALSE, risultando in una non corrispondenza.
Questa soluzione genera l'output desiderato:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Il piano per questa query è mostrato nella Figura 6, a conferma che l'ottimizzatore è stato in grado di fare affidamento sull'ordine dell'indice.
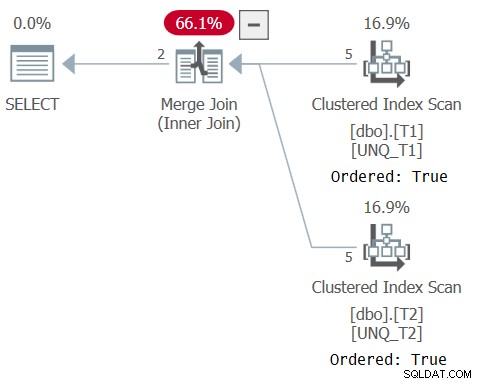 Figura 6:piano per la query 6
Figura 6:piano per la query 6
Puoi utilizzare una costruzione simile come predicato di filtro che coinvolge una colonna e un parametro/variabile per cercare corrispondenze in base alla distinzione, in questo modo:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Il piano è lo stesso di quello mostrato in precedenza nella Figura 3.
Puoi anche negare il predicato per cercare non corrispondenze, in questo modo:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Questa query genera il seguente output:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
In alternativa, puoi utilizzare un predicato positivo, ma sostituire INTERSECT con EXCEPT, in questo modo:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Tieni presente che i piani nei due casi potrebbero essere diversi, quindi assicurati di sperimentare in entrambi i modi con grandi quantità di dati.
Conclusione
I NULL aggiungono la loro quota di complessità alla scrittura del codice SQL. Vuoi sempre pensare al potenziale per la presenza di NULL nei dati e assicurarti di utilizzare i costrutti di query corretti e aggiungere la logica pertinente alle tue soluzioni per gestire correttamente i NULL. Ignorarli è un modo sicuro per finire con bug nel tuo codice. Questo mese mi sono concentrato su cosa sono i NULL e su come vengono gestiti nei confronti che coinvolgono costanti, variabili, parametri e colonne. Il mese prossimo continuerò la copertura discutendo delle incongruenze del trattamento NULL nei diversi elementi del linguaggio e delle funzionalità standard mancanti per la gestione di NULL.