Un indice di supporto può potenzialmente aiutare a evitare la necessità di un ordinamento esplicito nel piano di query quando si ottimizzano le query T-SQL che coinvolgono le funzioni della finestra. Da un indice di supporto Intendo uno con gli elementi di partizionamento e ordinamento della finestra come chiave di indice e il resto delle colonne che appaiono nella query come colonne incluse nell'indice. Mi riferisco spesso a tale modello di indicizzazione come a un POC index come acronimo di partizionamento , ordinare e copertura . Naturalmente, se un elemento di partizionamento o ordinamento non compare nella funzione della finestra, ometti quella parte dalla definizione dell'indice.
Ma che dire delle query che coinvolgono più funzioni della finestra con diverse esigenze di ordinamento? Allo stesso modo, cosa succede se altri elementi nella query oltre alle funzioni della finestra richiedono anche la disposizione dei dati di input ordinati nel piano, ad esempio una clausola ORDER BY di presentazione? Ciò può comportare che diverse parti del piano debbano elaborare i dati di input in ordini diversi.
In tali circostanze, in genere accetti che l'ordinamento esplicito sia inevitabile nel piano. Potresti scoprire che la disposizione sintattica delle espressioni nella query può influire su quante operatori di ordinamento espliciti che ottieni nel piano. Seguendo alcuni suggerimenti di base, a volte puoi ridurre il numero di operatori di ordinamento esplicito, che ovviamente possono avere un impatto importante sulle prestazioni della query.
Ambiente per le demo
Nei miei esempi, userò il database di esempio PerformanceV5. Puoi scaricare il codice sorgente per creare e popolare questo database qui.
Ho eseguito tutti gli esempi su SQL Server 2019 Developer, dove è disponibile la modalità batch su rowstore.
In questo articolo, voglio concentrarmi sui suggerimenti che hanno a che fare con il potenziale del calcolo della funzione finestra nel piano per fare affidamento sui dati di input ordinati senza richiedere un'attività di ordinamento esplicita aggiuntiva nel piano. Ciò è rilevante quando l'ottimizzatore utilizza un trattamento in modalità riga seriale o parallela delle funzioni della finestra e quando si utilizza un operatore Window Aggregate in modalità batch seriale.
SQL Server non supporta attualmente una combinazione efficiente di un input di conservazione dell'ordine parallelo prima di un operatore di Window Aggregate in modalità batch parallelo. Quindi, per utilizzare un operatore Window Aggregate in modalità batch parallela, l'ottimizzatore deve inserire un operatore di ordinamento intermedio in modalità batch parallela, anche quando l'input è già preordinato.
Per semplicità, puoi prevenire il parallelismo in tutti gli esempi mostrati in questo articolo. Per ottenere ciò senza dover aggiungere un suggerimento a tutte le query e senza impostare un'opzione di configurazione a livello di server, è possibile impostare l'opzione di configurazione con ambito database MAXDOP a 1 , in questo modo:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Ricorda di reimpostarlo su 0 dopo aver finito di testare gli esempi in questo articolo. Te lo ricorderò alla fine.
In alternativa, puoi prevenire il parallelismo a livello di sessione con il DBCC OPTIMIZER_WHATIF non documentato comando, in questo modo:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
Per ripristinare l'opzione quando hai finito, richiamala di nuovo con il valore 0 come numero di CPU.
Quando hai finito di provare tutti gli esempi in questo articolo con il parallelismo disabilitato, ti consiglio di abilitare il parallelismo e di provare di nuovo tutti gli esempi per vedere cosa cambia.
Suggerimenti 1 e 2
Prima di iniziare con i suggerimenti, diamo un'occhiata a un semplice esempio con una funzione di finestra progettata per beneficiare di un supp class="border indent shadow orting index.
Considera la seguente query, che chiamerò Query 1:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Non preoccuparti del fatto che l'esempio è artificioso. Non esiste una buona ragione commerciale per calcolare un totale parziale di ID ordine:questa tabella ha dimensioni decenti con righe da 1 mm e volevo mostrare un semplice esempio con una funzione finestra comune come quella che applica un calcolo totale parziale.
Seguendo lo schema di indicizzazione POC, crei il seguente indice per supportare la query:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Il piano per questa query è mostrato nella Figura 1.
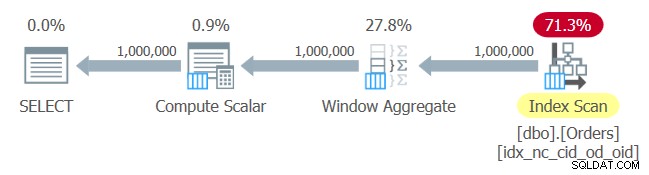 Figura 1:piano per la query 1
Figura 1:piano per la query 1
Nessuna sorpresa qui. Il piano applica una scansione dell'ordine dell'indice che hai appena creato, fornendo i dati ordinati all'operatore Window Aggregate, senza la necessità di un ordinamento esplicito.
Quindi, considera la seguente query, che coinvolge più funzioni della finestra con diverse esigenze di ordinamento, nonché una clausola ORDER BY di presentazione:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Farò riferimento a questa query come Query 2. Il piano per questa query è mostrato nella Figura 2.
 Figura 2:piano per la query 2
Figura 2:piano per la query 2
Si noti che nel piano sono presenti quattro operatori di ordinamento.
Se analizzi le varie funzioni della finestra e le esigenze di ordinamento delle presentazioni, scoprirai che esistono tre distinte esigenze di ordinamento:
- custid, orderdate, orderid
- ID ordine
- custid, orderid
Dato che uno di essi (il primo nell'elenco sopra) può essere supportato dall'indice che hai creato in precedenza, ti aspetteresti di vedere solo due tipi nel piano. Allora, perché il piano ha quattro tipi? Sembra che SQL Server non tenti di essere troppo sofisticato riorganizzando l'ordine di elaborazione delle funzioni nel piano per ridurre al minimo gli ordinamenti. Elabora le funzioni nel piano nell'ordine in cui appaiono nella query. Questo è almeno il caso della prima occorrenza di ogni esigenza di ordinazione distinta, ma lo approfondirò a breve.
Puoi eliminare la necessità di alcuni tipi nel piano applicando le due semplici pratiche seguenti:
Suggerimento 1:se disponi di un indice per supportare alcune delle funzioni della finestra nella query, specifica prima quelle.
Suggerimento 2:se la query include funzioni di finestra con le stesse esigenze di ordinamento dell'ordinamento di presentazione nella query, specifica queste funzioni per ultime.
Seguendo questi suggerimenti, riorganizzi l'ordine di apparizione delle funzioni della finestra nella query in questo modo:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Farò riferimento a questa query come Query 3. Il piano per questa query è mostrato nella Figura 3.
 Figura 3:piano per la query 3
Figura 3:piano per la query 3
Come puoi vedere, il piano ora ha solo due tipi.
Suggerimento 3
SQL Server non cerca di essere troppo sofisticato nel riorganizzare l'ordine di elaborazione delle funzioni della finestra nel tentativo di ridurre al minimo gli ordinamenti nel piano. Tuttavia, è capace di un certo semplice riarrangiamento. Esamina le funzioni della finestra in base all'ordine di apparizione nella query e ogni volta che rileva una nuova esigenza di ordinamento distinta, cerca ulteriori funzioni della finestra con la stessa esigenza di ordinamento e, se le trova, le raggruppa insieme alla prima occorrenza. In alcuni casi, può persino utilizzare lo stesso operatore per calcolare più funzioni della finestra.
Considera la seguente query come esempio:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Farò riferimento a questa query come Query 4. Il piano per questa query è mostrato nella Figura 4.
 Figura 4:piano per la query 4
Figura 4:piano per la query 4
Le funzioni della finestra con le stesse esigenze di ordinamento non sono raggruppate nella query. Tuttavia, ci sono ancora solo due tipi nel piano. Questo perché ciò che conta in termini di ordine di elaborazione nel piano è la prima occorrenza di ciascuna esigenza di ordinazione distinta. Questo mi porta al terzo consiglio.
Suggerimento 3:assicurati di seguire i suggerimenti 1 e 2 per la prima occorrenza di ogni distinta esigenza di ordinazione. Le occorrenze successive della stessa esigenza di ordinamento, anche se non adiacenti, vengono individuate e raggruppate insieme alla prima.
Suggerimenti 4 e 5
Si supponga di voler restituire le colonne risultanti da calcoli finestrati in un determinato ordine da sinistra a destra nell'output. Ma cosa succede se l'ordine non è lo stesso dell'ordine che ridurrà al minimo gli ordinamenti nel piano?
Ad esempio, supponiamo di volere lo stesso risultato di quello prodotto dalla query 2 in termini di ordine delle colonne da sinistra a destra nell'output (ordine delle colonne:altre cols, sum2, sum1, sum3), ma preferiresti avere il stesso piano come quello che hai per la query 3 (ordine delle colonne:altri cols, sum1, sum3, sum2), che ha ottenuto due tipi invece di quattro.
È perfettamente fattibile se hai familiarità con il quarto suggerimento.
Suggerimento 4:i suddetti consigli si applicano all'ordine di apparizione delle funzioni della finestra nel codice, anche se all'interno di un'espressione di tabella denominata come CTE o vista, e anche se la query esterna restituisce le colonne in un ordine diverso rispetto a espressione di tabella denominata. Pertanto, se è necessario restituire le colonne in un determinato ordine nell'output, ed è diverso dall'ordine ottimale in termini di minimizzazione degli ordinamenti nel piano, seguire i suggerimenti in termini di ordine di apparizione all'interno di un'espressione di tabella denominata e restituire le colonne nella query esterna nell'ordine di output desiderato.
La seguente query, che chiamerò Query 5, illustra questa tecnica:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Il piano per questa query è mostrato nella Figura 5.
 Figura 5:piano per la query 5
Figura 5:piano per la query 5
Si ottengono comunque solo due ordinamenti nel piano nonostante il fatto che l'ordine delle colonne nell'output sia:other cols, sum2, sum1, sum3, come nella query 2.
Un avvertimento su questo trucco con l'espressione della tabella denominata è che se le colonne nell'espressione della tabella non sono referenziate dalla query esterna, sono escluse dal piano e quindi non contano.
Considera la seguente query, che chiamerò Query 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Qui tutte le colonne dell'espressione della tabella sono referenziate dalla query esterna, quindi l'ottimizzazione avviene in base alla prima occorrenza distinta di ciascuna necessità di ordinamento all'interno dell'espressione della tabella:
- max1:custid, orderdate, orderid
- max3:ID ordine
- max2:custid, orderid
Ciò si traduce in un piano con solo due tipi, come mostrato nella Figura 6.
 Figura 6:piano per la query 6
Figura 6:piano per la query 6
Ora cambia solo la query esterna rimuovendo i riferimenti a max2, max1, max3, avg2, avg1 e avg3, in questo modo:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Farò riferimento a questa query come Query 7. I calcoli di max1, max3, max2, avg1, avg3 e avg2 nell'espressione della tabella sono irrilevanti per la query esterna, quindi sono esclusi. I restanti calcoli che coinvolgono le funzioni della finestra nell'espressione della tabella, che sono rilevanti per la query esterna, sono quelli di sum2, sum1 e sum3. Sfortunatamente, non vengono visualizzati nell'espressione della tabella nell'ordine ottimale in termini di minimizzazione degli ordinamenti. Come puoi vedere nel piano per questa query come mostrato nella Figura 7, ci sono quattro tipi.
 Figura 7:Piano per la query 7
Figura 7:Piano per la query 7
Se stai pensando che è improbabile che tu abbia colonne nella query interna a cui non farai riferimento nella query esterna, pensa alle visualizzazioni. Ogni volta che esegui una query su una vista, potresti essere interessato a un diverso sottoinsieme di colonne. Con questo in mente, il quinto suggerimento potrebbe aiutare a ridurre gli ordinamenti nel piano.
Suggerimento 5:nella query interna di un'espressione di tabella denominata come un CTE o una vista, raggruppa tutte le funzioni della finestra con le stesse esigenze di ordinamento e segui i suggerimenti 1 e 2 nell'ordine dei gruppi di funzioni.
Il codice seguente implementa una vista basata su questo consiglio:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Ora interroga la vista richiedendo solo le colonne dei risultati con finestra sum2, sum1 e sum3, in questo ordine:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Farò riferimento a questa query come Query 8. Ottieni il piano mostrato nella Figura 8 con solo due tipi.
 Figura 8:piano per la query 8
Figura 8:piano per la query 8
Suggerimento 6
Quando si dispone di una query con più funzioni di finestra con più esigenze di ordinamento distinte, è opinione comune che sia possibile supportarne solo una con dati preordinati tramite un indice. Questo è il caso anche quando tutte le funzioni della finestra hanno rispettivi indici di supporto.
Lascia che lo dimostri. Ricorda in precedenza quando hai creato l'indice idx_nc_cid_od_oid, che può supportare le funzioni della finestra che richiedono i dati ordinati per custid, orderdate, orderid, come la seguente espressione:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Supponiamo che, oltre a questa funzione finestra, nella stessa query sia necessaria anche la seguente funzione finestra:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Questa funzione della finestra trarrebbe vantaggio dal seguente indice:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
La seguente query, che chiamerò Query 9, richiama entrambe le funzioni della finestra:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Il piano per questa query è mostrato nella Figura 9.
 Figura 9:Piano per la query 9
Figura 9:Piano per la query 9
Ottengo le seguenti statistiche temporali per questa query sul mio computer, con risultati scartati in SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
Come spiegato in precedenza, SQL Server esegue la scansione delle espressioni con finestra in ordine di apparizione nella query e calcola di poter supportare la prima con un'analisi ordinata dell'indice idx_nc_cid_od_oid. Ma poi aggiunge un operatore di ordinamento al piano per ordinare i dati come richiede la funzione della seconda finestra. Ciò significa che il piano ha un ridimensionamento N log N. Non considera l'utilizzo dell'indice idx_nc_cid_oid per supportare la seconda funzione della finestra. Probabilmente stai pensando che non può, ma prova a pensare un po' fuori dagli schemi. Non potresti calcolare ciascuna delle funzioni della finestra in base al rispettivo ordine di indice e quindi unire i risultati? In teoria, è possibile e, a seconda delle dimensioni dei dati, della disponibilità dell'indicizzazione e di altre risorse disponibili, la versione di join a volte potrebbe fare di meglio. SQL Server non considera questo approccio, ma puoi sicuramente implementarlo scrivendo tu stesso il join, in questo modo:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Farò riferimento a questa query come Query 10. Il piano per questa query è mostrato nella Figura 10.
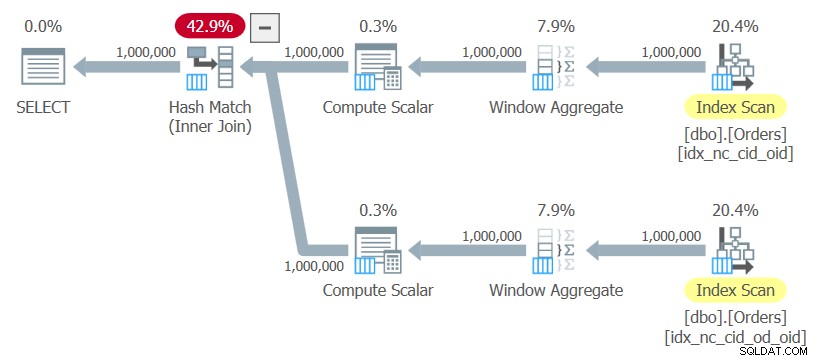 Figura 10:piano per la query 10
Figura 10:piano per la query 10
Il piano utilizza scansioni ordinate dei due indici senza alcun ordinamento esplicito, calcola le funzioni della finestra e utilizza un hash join per unire i risultati. Questo piano scala linearmente rispetto al precedente che ha N log N ridimensionamento.
Ottengo le seguenti statistiche temporali per questa query sulla mia macchina (di nuovo con risultati scartati in SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
Per ricapitolare, ecco il nostro sesto consiglio.
Suggerimento 6:quando disponi di più funzioni finestra con più esigenze di ordinamento distinte e sei in grado di supportarle tutte con indici, prova una versione di join e confronta le prestazioni con la query senza join.
Pulizia
Se hai disabilitato il parallelismo impostando l'opzione di configurazione con ambito database MAXDOP su 1, riattiva il parallelismo impostandolo su 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Se hai utilizzato l'opzione di sessione non documentata DBCC OPTIMIZER_WHATIF con l'opzione CPU impostata su 1, riattiva il parallelismo impostandolo su 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Puoi riprovare tutti gli esempi con il parallelismo abilitato, se lo desideri.
Usa il codice seguente per ripulire i nuovi indici che hai creato:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
E il codice seguente per rimuovere la vista:
DROP VIEW IF EXISTS dbo.MyView;
Segui i suggerimenti per ridurre al minimo il numero di tipi
Le funzioni della finestra devono elaborare i dati di input ordinati. L'indicizzazione può aiutare a eliminare l'ordinamento nel piano, ma normalmente solo per una precisa esigenza di ordinazione. Le query con più esigenze di ordinazione in genere coinvolgono alcuni tipi nei loro piani. Tuttavia, seguendo alcuni suggerimenti, puoi ridurre al minimo il numero di ordinamenti necessari. Ecco un riepilogo dei suggerimenti che ho menzionato in questo articolo:
- Suggerimento 1: Se si dispone di un indice per supportare alcune delle funzioni della finestra nella query, specificarle prima.
- Suggerimento 2: Se la query coinvolge funzioni di finestra con la stessa esigenza di ordinamento dell'ordinamento di presentazione nella query, specificare tali funzioni per ultime.
- Suggerimento 3: Assicurati di seguire i suggerimenti 1 e 2 per la prima occorrenza di ogni distinta esigenza di ordinazione. Le occorrenze successive della stessa esigenza ordinativa, anche se non adiacenti, vengono individuate e raggruppate insieme alla prima.
- Suggerimento 4: I suddetti consigli si applicano all'ordine di apparizione delle funzioni della finestra nel codice, anche se all'interno di un'espressione di tabella denominata come CTE o vista, e anche se la query esterna restituisce le colonne in un ordine diverso rispetto all'espressione di tabella denominata. Pertanto, se è necessario restituire le colonne in un determinato ordine nell'output, ed è diverso dall'ordine ottimale in termini di minimizzazione degli ordinamenti nel piano, seguire i suggerimenti in termini di ordine di apparizione all'interno di un'espressione di tabella denominata e restituire le colonne nella query esterna nell'ordine di output desiderato.
- Suggerimento 5: Nella query interna di un'espressione di tabella denominata come un CTE o una vista, raggruppa tutte le funzioni della finestra con le stesse esigenze di ordinamento e segui i suggerimenti 1 e 2 nell'ordine dei gruppi di funzioni.
- Suggerimento 6: Quando hai più funzioni di finestra con più esigenze di ordinamento distinte e sei in grado di supportarle tutte con indici, prova una versione di join e confronta le sue prestazioni con la query senza il join.