Questo blog è la seconda parte dell'implementazione di una configurazione multi-datacenter per PostgreSQL. In questo colpo, mostreremo come distribuire PostgreSQL in questo tipo di ambiente e come eseguire il failover in caso di errore principale utilizzando la funzione di ripristino automatico di ClusterControl.
A questo punto, assumiamo che tu abbia la connettività tra i data center (come abbiamo visto nella prima parte di questo blog) e che tu abbia i server necessari per questo compito (come abbiamo anche menzionato nel parte precedente).
Distribuisci un cluster PostgreSQL
Utilizzeremo ClusterControl per questa attività, quindi supponiamo che tu l'abbia installato (potrebbe essere installato sullo stesso server Load Balancer, ma se puoi utilizzarne uno diverso anche meglio).
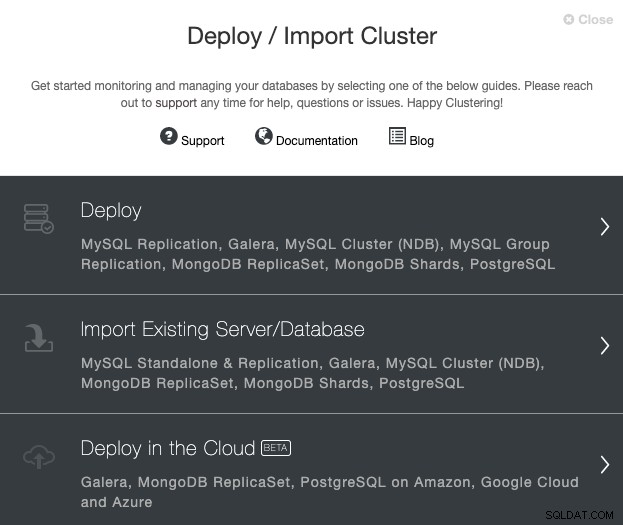
Vai al tuo server ClusterControl e seleziona l'opzione 'Distribuisci'. Se hai già un'istanza PostgreSQL in esecuzione, devi invece selezionare "Importa server/database esistente".
Quando si seleziona PostgreSQL, è necessario specificare Utente, Chiave o Password e la porta su connettersi tramite SSH ai nostri host PostgreSQL. Hai anche bisogno del nome per il tuo nuovo cluster e se vuoi che ClusterControl installi per te il software e le configurazioni corrispondenti.
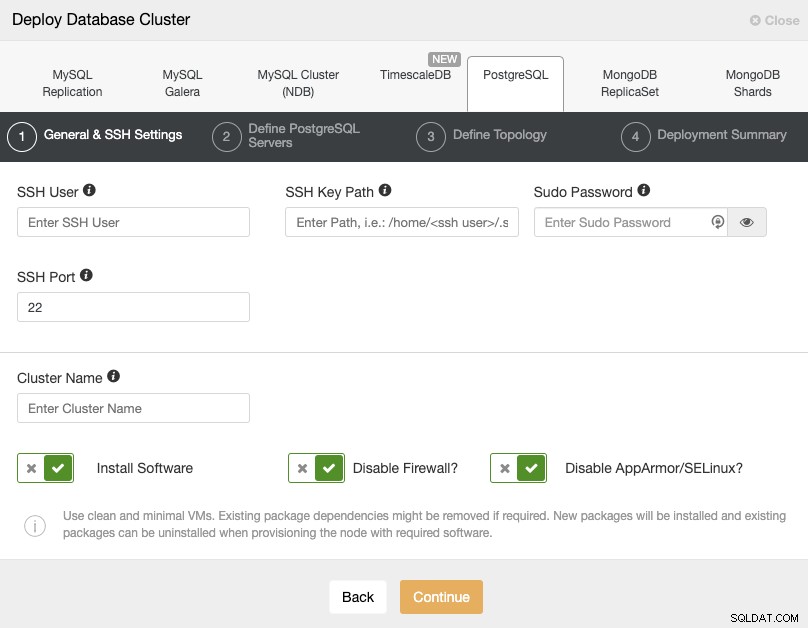
Controlla i requisiti utente ClusterControl per questa attività qui, ma se hai seguito nel blog precedente, dovresti usare l'utente 'remoto' qui e la porta SSH corretta (come accennato, si consiglia di usarne una diversa se si utilizza l'indirizzo IP pubblico per accedervi anziché una VPN).
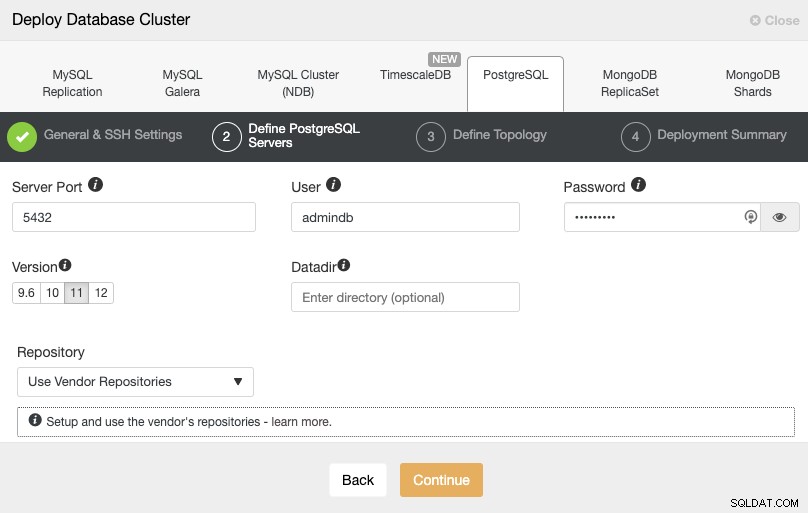
Dopo aver impostato le informazioni di accesso SSH, è necessario definire l'utente del database, versione e datadir (opzionale). Puoi anche specificare quale repository utilizzare. Nel passaggio successivo, devi aggiungere i tuoi server al cluster che creerai.
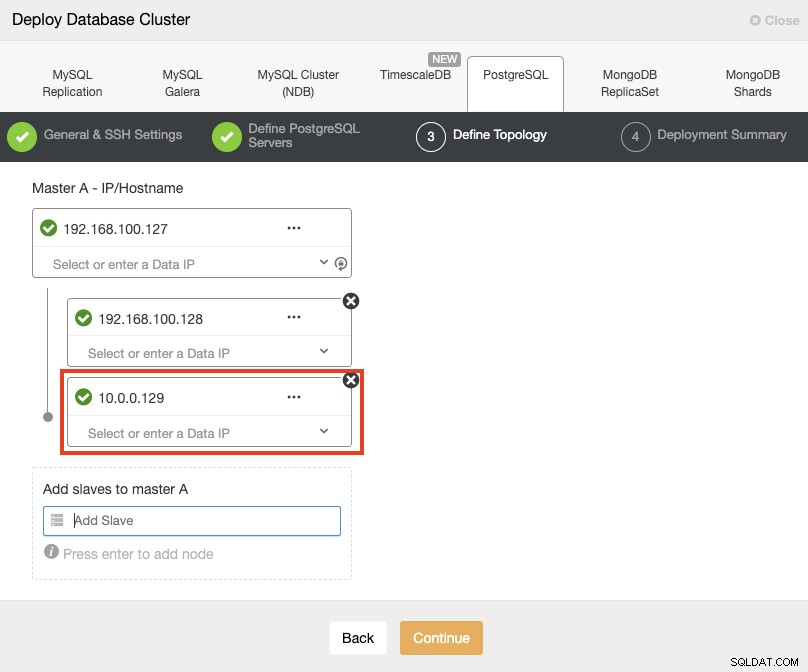
Quando aggiungi i tuoi server, puoi inserire IP o nome host. In questa parte utilizzerai gli indirizzi IP pubblici dei tuoi server e, come puoi vedere nel riquadro rosso, sto usando una rete diversa per il secondo nodo di standby. ClusterControl non ha alcuna limitazione sulla rete da utilizzare. L'unico requisito al riguardo è avere l'accesso SSH al nodo.
Quindi, seguendo il nostro esempio precedente, questi indirizzi IP dovrebbero essere:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)Nell'ultimo passaggio, puoi scegliere se la tua replica sarà Sincrona o Asincrona.
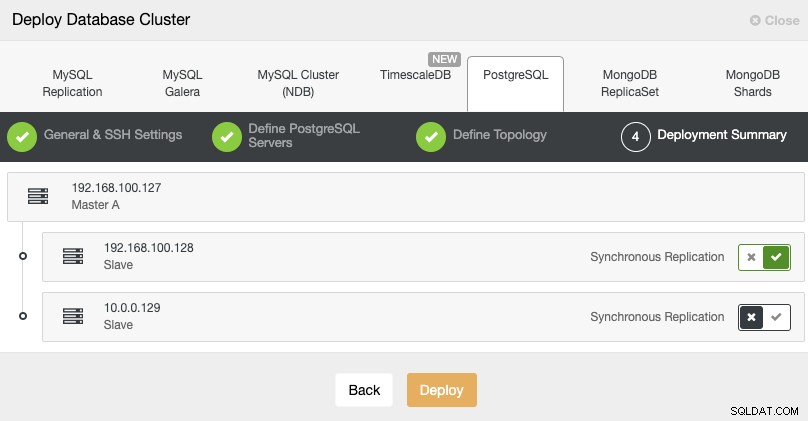
In questo caso, è importante utilizzare la replica asincrona per il nodo remoto , in caso contrario, il tuo cluster potrebbe essere interessato dalla latenza o da problemi di rete.
Puoi monitorare lo stato della creazione del tuo nuovo cluster dal monitor attività ClusterControl.
Una volta terminata l'attività, puoi vedere il tuo nuovo cluster PostgreSQL nella schermata principale di ClusterControl.

Aggiunta di un sistema di bilanciamento del carico PostgreSQL (HAProxy)
Una volta creato il cluster, puoi eseguire diverse attività su di esso, come aggiungere un sistema di bilanciamento del carico (HAProxy) o una nuova replica.
Per seguire il nostro esempio precedente, aggiungiamo un load balancer che, come accennato, ti aiuterà a gestire il tuo ambiente HA. Per questo, vai su ClusterControl -> Seleziona PostgreSQL Cluster -> Azioni cluster -> Aggiungi Load Balancer.
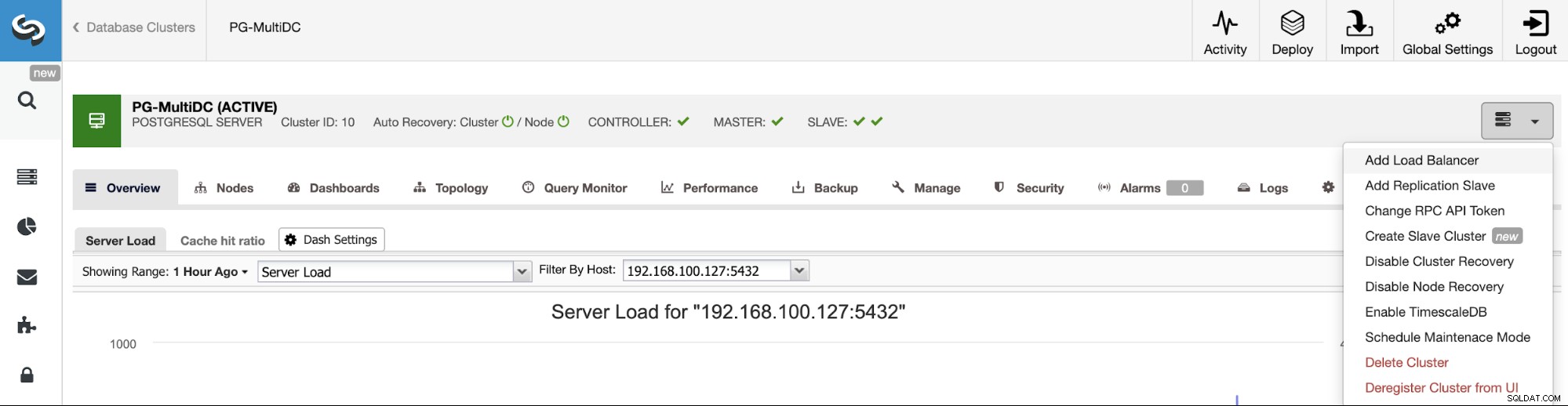
Qui devi aggiungere le informazioni che ClusterControl utilizzerà per installare e configurare il tuo Bilanciatore di carico HAProxy. Questo Load Balancer può essere installato nello stesso server ClusterControl, ma se puoi utilizzarne uno diverso, ancora meglio.
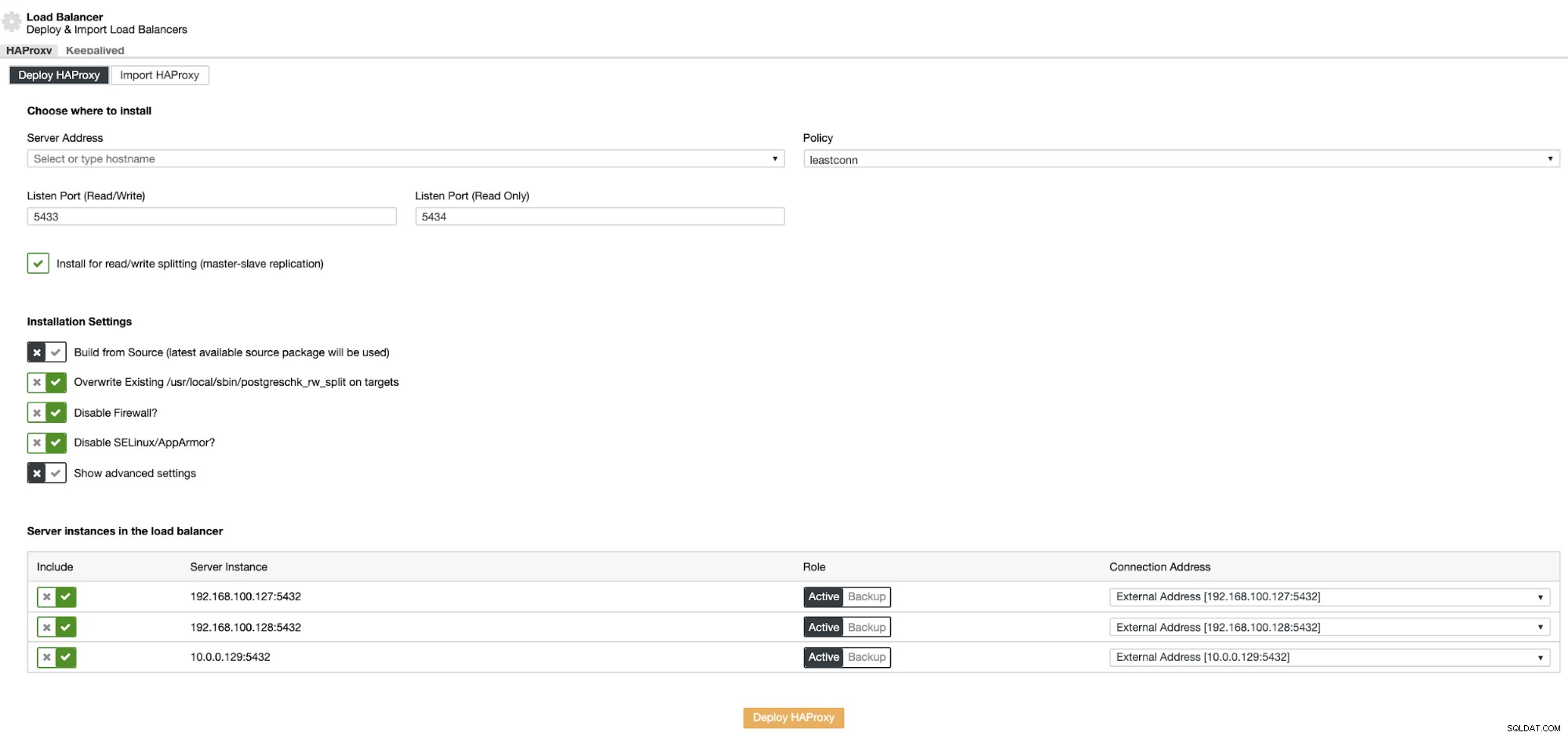
Le informazioni che devi introdurre sono:
Azione:distribuisci o importa.
Indirizzo server:indirizzo IP per il server HAProxy (può essere lo stesso indirizzo IP ClusterControl).
Porta di ascolto (lettura/scrittura):porta per la modalità di lettura/scrittura.
Porta di ascolto (sola lettura):porta per la modalità di sola lettura.
Politica:può essere:
- leastconn:il server con il numero più basso di connessioni riceve la connessione.
- roundrobin:ogni server viene utilizzato a turno, in base al loro peso.
- fonte:l'indirizzo IP di origine viene sottoposto a hash e diviso per il peso totale dei server in esecuzione per designare quale server riceverà la richiesta.
Installa per la suddivisione in lettura/scrittura:per la replica master-slave.
Crea dal sorgente:puoi scegliere Installa da un gestore di pacchetti o compila dal sorgente.
E devi selezionare quali server vuoi aggiungere alla configurazione HAProxy.
Inoltre, puoi configurare Impostazioni avanzate come Utente amministratore, Nome backend, Timeout e altro.
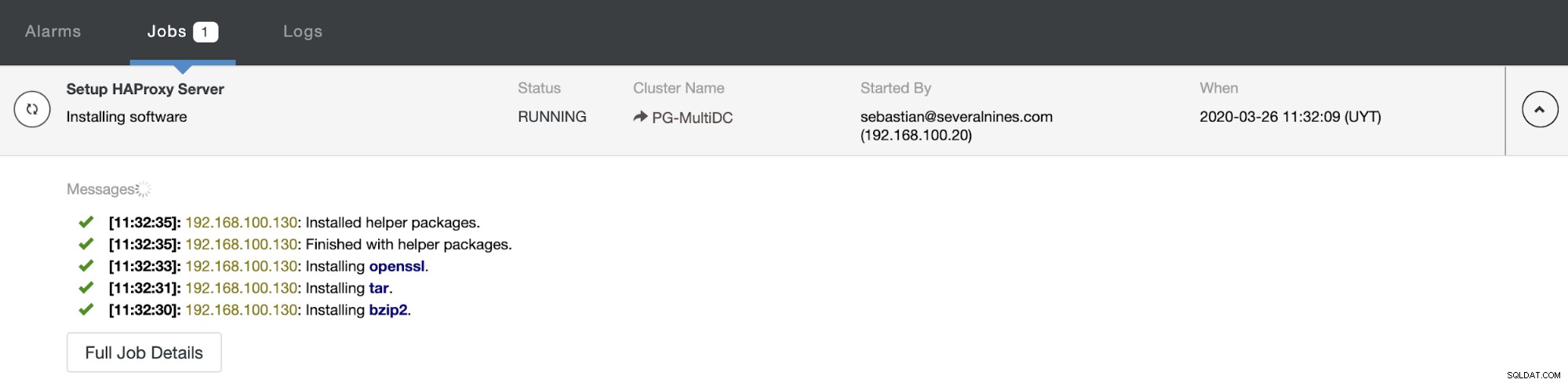
Al termine della configurazione e confermato la distribuzione, puoi seguire l'avanzamento nella sezione Attività sull'interfaccia utente di ClusterControl.
Al termine, puoi andare su ClusterControl -> Nodes -> nodo HAProxy e verifica lo stato corrente.
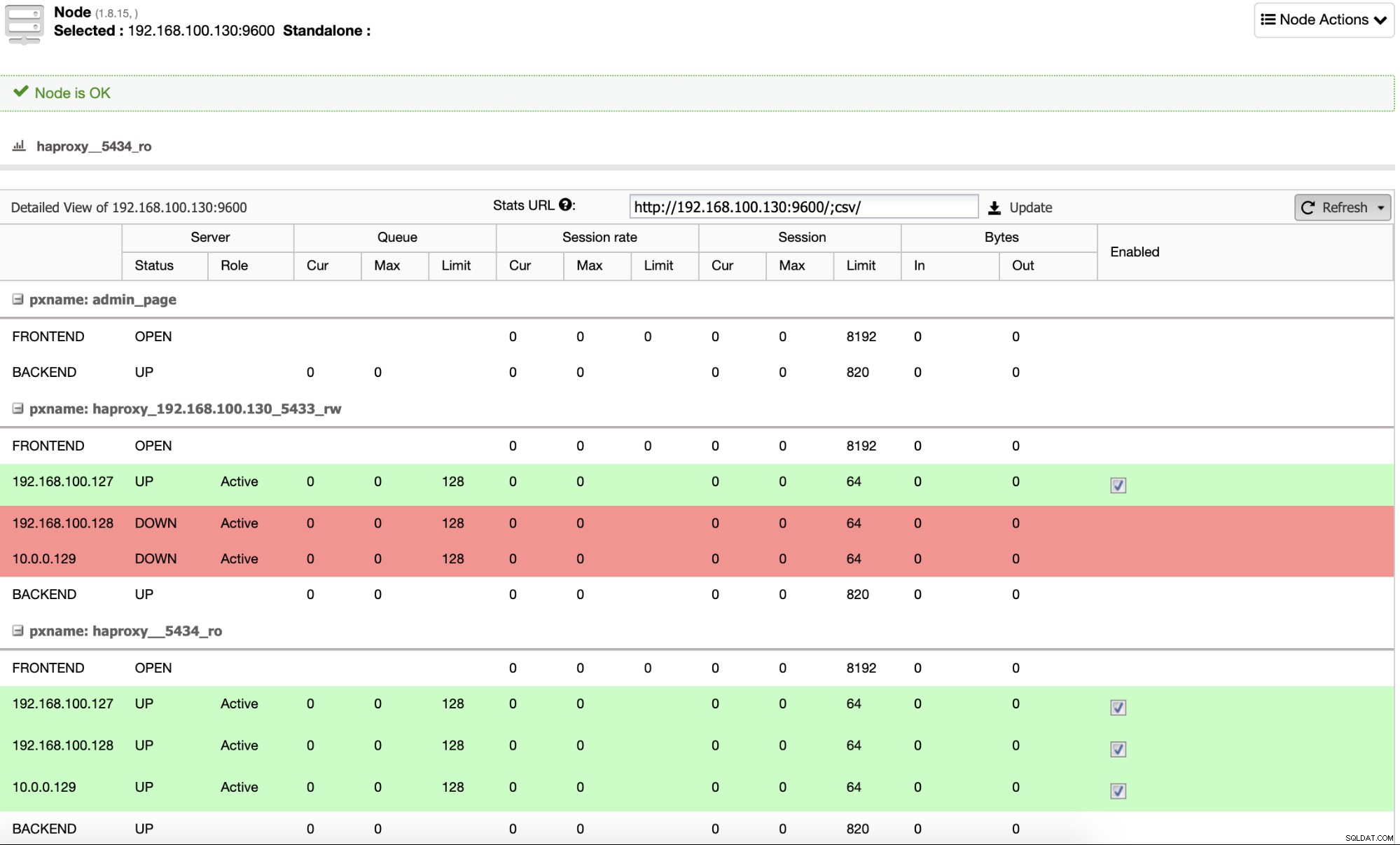
Per impostazione predefinita, ClusterControl configura HAProxy con due porte diverse, una per Read- Scrivi, che verrà utilizzato dall'applicazione o dall'utente per scrivere (e leggere) i dati, e un altro per Sola lettura, che verrà utilizzato per bilanciare il traffico di lettura tra tutti i nodi. Nella porta Read-Write è abilitato solo il nodo master e, in caso di guasto del master, ClusterControl promuoverà lo slave più avanzato a master e riconfigura questa porta per disabilitare il vecchio master e abilitare il nuovo. In questo modo, la tua applicazione può continuare a funzionare in caso di errore del database master, poiché il traffico viene reindirizzato dal Load Balancer al nodo corretto.
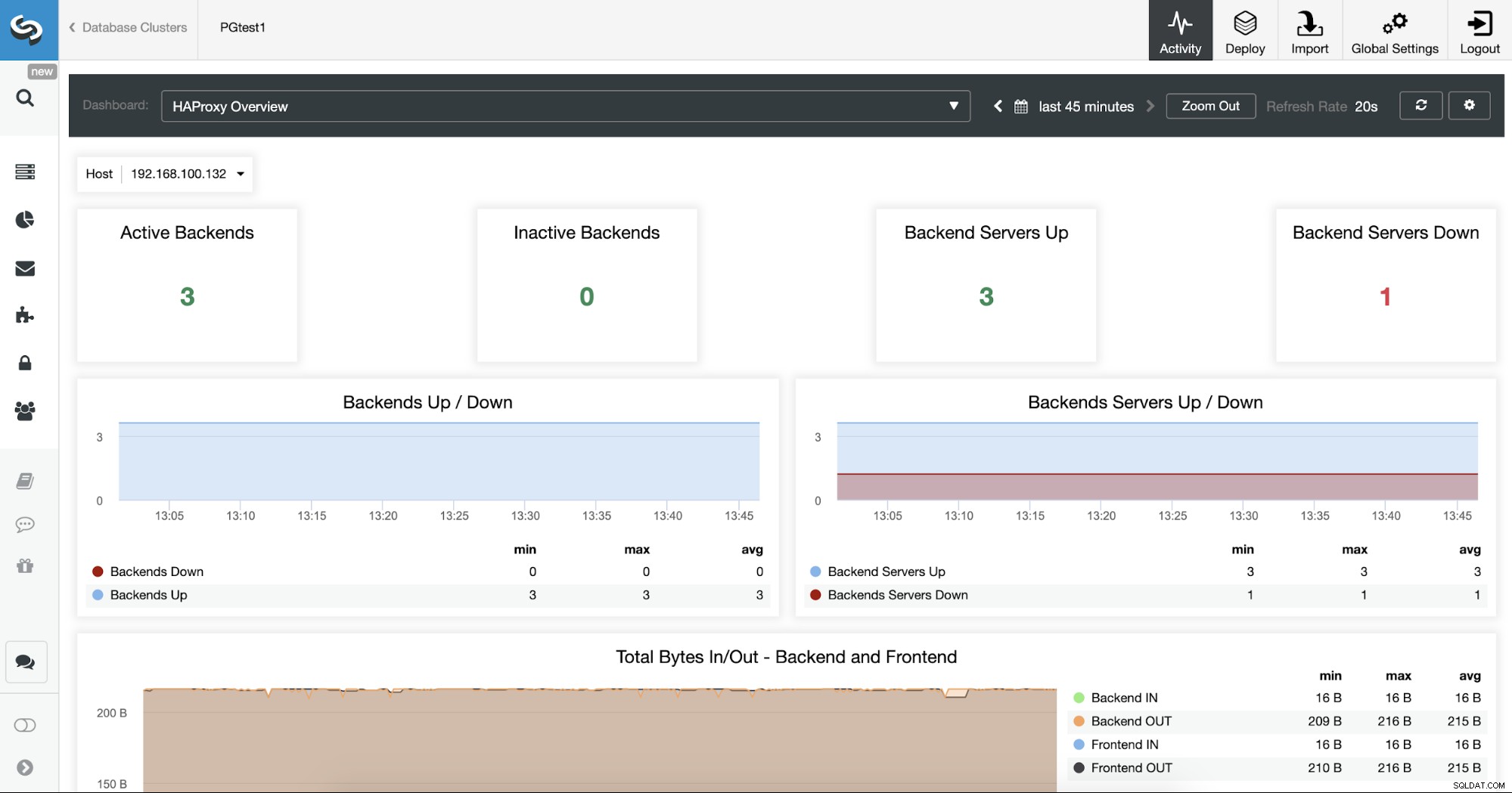
Puoi anche monitorare i tuoi server HAProxy controllando la sezione Dashboard.
Ora puoi migliorare il tuo design HA aggiungendo un nuovo nodo HAProxy nel datacenter remoto e la configurazione del servizio Keepalived tra di loro. Keepalived ti consentirà di utilizzare un indirizzo IP virtuale assegnato al nodo Load Balancer attivo. Se questo nodo fallisce, questo IP virtuale verrà migrato al nodo HAProxy secondario, quindi avere questo IP configurato nella tua applicazione ti consentirà di mantenere tutto funzionante in caso di problemi con Load Balancer.
Tutta questa configurazione può essere eseguita utilizzando ClusterControl.
Conclusione
Seguendo questo blog in due parti puoi implementare una configurazione multi-datacenter per PostgreSQL con High Availability e connettività SSH tra i datacenter, per evitare la complessità di una configurazione VPN.
Utilizzando la replica asincrona per il nodo remoto eviterai qualsiasi problema relativo alla latenza e alle prestazioni della rete e utilizzando ClusterControl avrai il failover automatico (o manuale) in caso di guasto (tra le altre numerose funzionalità). Questo potrebbe essere il modo più semplice per raggiungere questa topologia e speriamo che ti possa essere utile.