Nota:questo post è stato originariamente pubblicato solo nel nostro eBook, High Performance Techniques for SQL Server, Volume 3. Puoi trovare informazioni sui nostri eBook qui.
Un requisito che vedo occasionalmente è avere una query restituita con ordini raggruppati per cliente, che mostri il totale massimo dovuto visto per qualsiasi ordine fino ad oggi (un "massimo in esecuzione"). Quindi immagina queste righe di esempio:
| SalesOrderID | ID cliente | Data dell'ordine | TotalDue |
|---|---|---|---|
| 12 | 2 | 01-01-2014 | 37.55 |
| 23 | 1 | 02-01-2014 | 45.29 |
| 31 | 2 | 03-01-2014 | 24.56 |
| 32 | 2 | 04-01-2014 | 89.84 |
| 37 | 1 | 05-01-2014 | 32.56 |
| 44 | 2 | 06-01-2014 | 45.54 |
| 55 | 1 | 07-01-2014 | 99.24 |
| 62 | 2 | 08-01-2014 | 12.55 |
Alcune righe di dati di esempio
I risultati desiderati dai requisiti dichiarati sono i seguenti:in parole povere, ordina gli ordini di ciascun cliente per data ed elenca ogni ordine. Se questo è il valore TotalDue più alto per tutti gli ordini visti fino a quella data, stampa il totale dell'ordine, altrimenti stampa il valore TotalDue più alto da tutti gli ordini precedenti:
| SalesOrderID | ID cliente | Data dell'ordine | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 02-01-2014 | 45.29 | 45.29 |
| 23 | 1 | 05-01-2014 | 32.56 | 45.29 |
| 31 | 1 | 07-01-2014 | 99.24 | 99.24 |
| 32 | 2 | 01-01-2014 | 37.55 | 37.55 |
| 37 | 2 | 03-01-2014 | 24.56 | 37.55 |
| 44 | 2 | 04-01-2014 | 89.84 | 89.84 |
| 55 | 2 | 06-01-2014 | 45.54 | 89.84 |
| 62 | 2 | 08-01-2014 | 12.55 | 89.84 |
Campione dei risultati desiderati
Molte persone vorrebbero istintivamente utilizzare un cursore o un ciclo while per ottenere ciò, ma ci sono diversi approcci che non coinvolgono questi costrutti.
Subquery correlata
Questo approccio sembra essere l'approccio più semplice e diretto al problema, ma è stato dimostrato più volte che non è scalabile, poiché le letture crescono in modo esponenziale man mano che la tabella diventa più grande:
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = (SELECT MAX(TotalDue)
FROM Sales.SalesOrderHeader
WHERE CustomerID = h.CustomerID
AND SalesOrderID <= h.SalesOrderID)
FROM Sales.SalesOrderHeader AS h
ORDER BY CustomerID, SalesOrderID; Ecco il piano contro AdventureWorks2014, utilizzando SQL Sentry Plan Explorer:
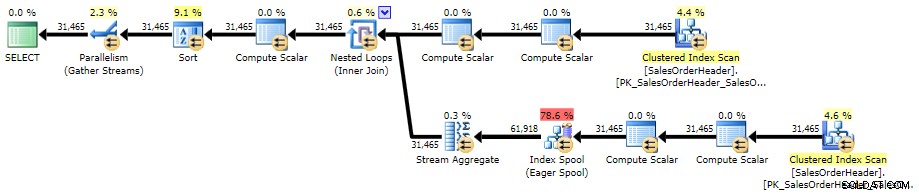 Piano di esecuzione per subquery correlate (clicca per ingrandire)
Piano di esecuzione per subquery correlate (clicca per ingrandire)
CROSS APPLY autoreferenziale
Questo approccio è quasi identico all'approccio Subquery correlato, in termini di sintassi, forma del piano e prestazioni su larga scala.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDue
FROM Sales.SalesOrderHeader AS h
CROSS APPLY
(
SELECT MaxTotalDue = MAX(TotalDue)
FROM Sales.SalesOrderHeader AS i
WHERE i.CustomerID = h.CustomerID
AND i.SalesOrderID <= h.SalesOrderID
) AS x
ORDER BY h.CustomerID, h.SalesOrderID; Il piano è abbastanza simile al piano di subquery correlato, l'unica differenza è la posizione di un tipo:
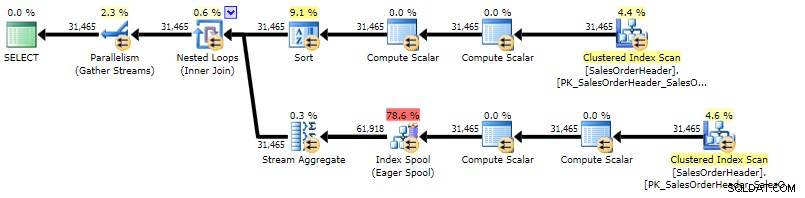 Piano di esecuzione per CROSS APPLY (clicca per ingrandire)
Piano di esecuzione per CROSS APPLY (clicca per ingrandire)
CTE ricorsivo
Dietro le quinte, questo utilizza i loop, ma finché non lo eseguiamo effettivamente, possiamo in qualche modo fingere che non lo faccia (anche se è facilmente il pezzo di codice più complicato che vorrei mai scrivere per risolvere questo particolare problema):
;WITH /* Recursive CTE */ cte AS
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue = TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader
) AS x
WHERE rn = 1
UNION ALL
SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue,
MaxTotalDue = CASE
WHEN r.TotalDue > cte.MaxTotalDue THEN r.TotalDue
ELSE cte.MaxTotalDue
END
FROM cte
CROSS APPLY
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader AS h
WHERE h.CustomerID = cte.CustomerID
AND h.SalesOrderID > cte.SalesOrderID
) AS r
WHERE r.rn = 1
)
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM cte
ORDER BY CustomerID, SalesOrderID
OPTION (MAXRECURSION 0); Puoi immediatamente vedere che il piano è più complesso dei due precedenti, il che non sorprende vista la query più complessa:
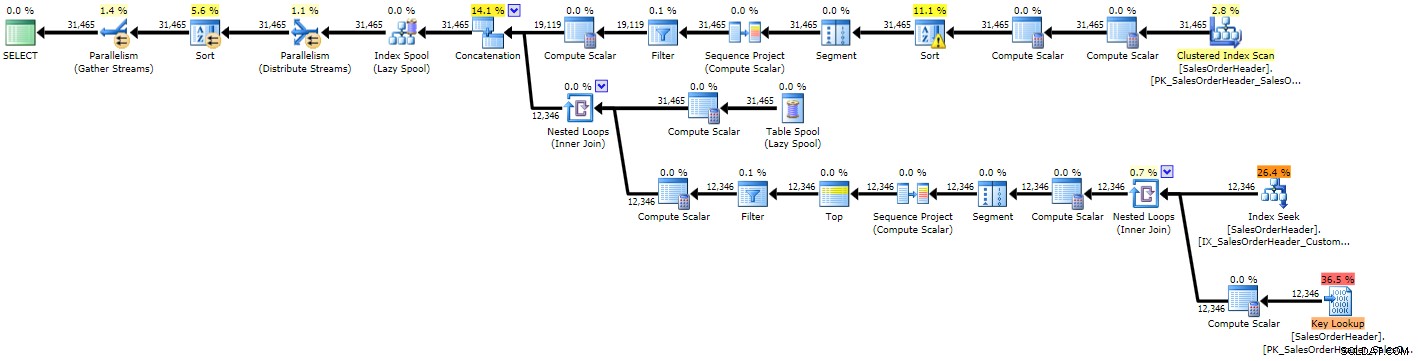 Piano di esecuzione per CTE ricorsivo (clicca per ingrandire)
Piano di esecuzione per CTE ricorsivo (clicca per ingrandire)
A causa di alcune stime errate, vediamo una ricerca dell'indice con una ricerca chiave di accompagnamento che probabilmente avrebbe dovuto essere entrambe sostituite da una singola scansione e otteniamo anche un'operazione di ordinamento che alla fine deve essere riversata su tempdb (puoi vederlo nel suggerimento se passi il mouse sopra l'operatore di ordinamento con l'icona di avviso):

MAX() OLTRE (RIGHE SENZA LIMITI)
Questa è una soluzione disponibile solo in SQL Server 2012 e versioni successive, poiché utilizza le estensioni appena introdotte per le funzioni della finestra.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = MAX(TotalDue) OVER
(
PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS UNBOUNDED PRECEDING
)
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID; Il piano mostra esattamente perché si adatta meglio di tutti gli altri; ha solo un'operazione di scansione dell'indice in cluster, invece di due (o la scelta sbagliata di una scansione e una ricerca + ricerca nel caso del CTE ricorsivo):
 Piano di esecuzione per MAX() OVER() (clicca per ingrandire)
Piano di esecuzione per MAX() OVER() (clicca per ingrandire)
Confronto delle prestazioni
I piani ci portano sicuramente a credere che il nuovo MAX() OVER() la capacità in SQL Server 2012 è un vero vincitore, ma che ne dici di metriche di runtime tangibili? Ecco come si confrontano le esecuzioni:

Le prime due query erano quasi identiche; mentre in questo caso il CROSS APPLY era migliore in termini di durata complessiva di un piccolo margine, la subquery correlata a volte lo batte un po'. Il CTE ricorsivo è sostanzialmente più lento ogni singola volta e puoi vedere i fattori che contribuiscono a ciò, vale a dire le stime errate, l'enorme quantità di letture, la ricerca della chiave e l'operazione di ordinamento aggiuntiva. E come ho già dimostrato con i totali parziali, la soluzione SQL Server 2012 è migliore in quasi tutti gli aspetti.
Conclusione
Se utilizzi SQL Server 2012 o versioni successive, vorrai sicuramente acquisire familiarità con tutte le estensioni delle funzioni di windowing introdotte per la prima volta in SQL Server 2005:potrebbero darti alcuni miglioramenti delle prestazioni piuttosto seri durante la rivisitazione del codice ancora in esecuzione " alla vecchia maniera". Se vuoi saperne di più su alcune di queste nuove funzionalità, ti consiglio vivamente il libro di Itzik Ben-Gan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Se non utilizzi ancora SQL Server 2012, almeno in questo test, puoi scegliere tra CROSS APPLY e la subquery correlata. Come sempre, dovresti testare vari metodi rispetto ai tuoi dati sul tuo hardware.