Un esempio in cui ciò può fare la differenza è che può impedire un'ottimizzazione delle prestazioni che evita di aggiungere informazioni sul controllo delle versioni delle righe alle tabelle con attivatori successivi.
Questo è trattato da Paul White qui
La dimensione effettiva dei dati archiviati è irrilevante:è la dimensione potenziale che conta.
Allo stesso modo, se si utilizzano tabelle ottimizzate per la memoria dal 2016 è possibile utilizzare colonne LOB o combinazioni di larghezze di colonna che potrebbero potenzialmente superare il limite inrow ma con una penalità.
Le colonne (massimo) vengono sempre archiviate fuori riga. Per le altre colonne, se la dimensione della riga di dati nella definizione della tabella può superare 8.060 byte, SQL Server esegue il push delle colonne a lunghezza variabile più grandi fuori dalla riga. Ancora una volta, non dipende dalla quantità di dati che memorizzi lì.
Ciò può avere un grande effetto negativo sul consumo di memoria e sulle prestazioni
Un altro caso in cui la dichiarazione eccessiva delle larghezze delle colonne può fare una grande differenza è se la tabella verrà mai elaborata utilizzando SSIS. La memoria allocata per colonne a lunghezza variabile (non BLOB) è fissa per ogni riga in un albero di esecuzione ed è per la lunghezza massima dichiarata delle colonne che può portare a un utilizzo inefficiente dei buffer di memoria (esempio). Sebbene lo sviluppatore del pacchetto SSIS possa dichiarare una dimensione della colonna inferiore rispetto alla fonte, è meglio che questa analisi venga eseguita in anticipo e applicata lì.
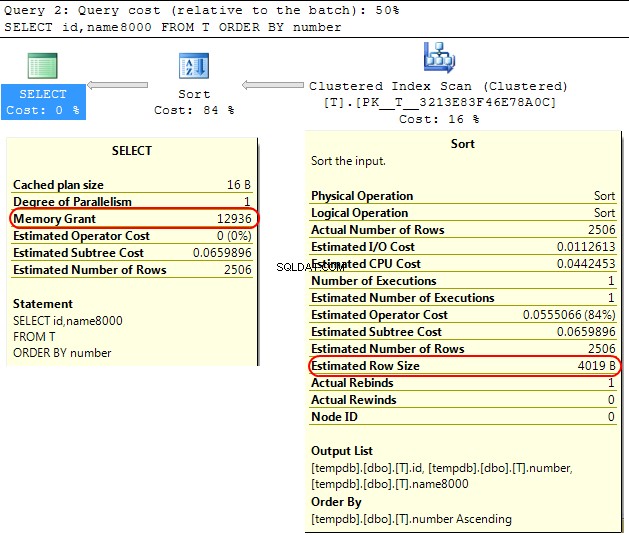
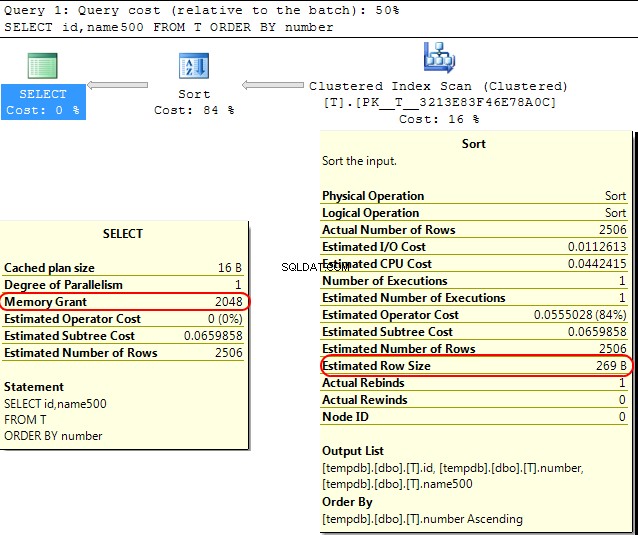
Nel motore di SQL Server stesso un caso simile è che quando si calcola la concessione di memoria da allocare per SORT operazioni SQL Server presuppone che varchar(x) le colonne consumeranno in media x/2 byte.
Se la maggior parte del tuo varchar le colonne sono più piene di quanto ciò possa portare al sort operazioni che si riversano su tempdb .
Nel tuo caso se il tuo varchar le colonne sono dichiarate come 8000 byte ma in realtà hanno un contenuto molto inferiore a quello che alla tua query verrà allocata memoria che non richiede, il che è ovviamente inefficiente e può portare ad attese per le concessioni di memoria.
Questo è trattato nella Parte 2 di SQL Workshops Webcast 1 scaricabile da qui o vedi sotto.
use tempdb;
CREATE TABLE T(
id INT IDENTITY(1,1) PRIMARY KEY,
number int,
name8000 VARCHAR(8000),
name500 VARCHAR(500))
INSERT INTO T
(number,name8000,name500)
SELECT number, name, name /*<--Same contents in both cols*/
FROM master..spt_values
SELECT id,name500
FROM T
ORDER BY number
SELECT id,name8000
FROM T
ORDER BY number