Le funzioni RANK, DENSE_RANK e ROW_NUMBER vengono utilizzate per recuperare un valore intero crescente. Iniziano con un valore basato sulla condizione imposta dalla clausola ORDER BY. Tutte queste funzioni richiedono la clausola ORDER BY per funzionare correttamente. In caso di dati partizionati, il contatore di numeri interi viene ripristinato a 1 per ciascuna partizione.
In questo articolo, studieremo in dettaglio le funzioni RANK, DENSE_RANK e ROW_NUMBER, ma prima creiamo dati fittizi su cui queste funzioni possono essere utilizzate a meno che il tuo database non sia completamente sottoposto a backup.
Preparazione di dati fittizi
Esegui il seguente script per creare un database chiamato ShowRoom e contenente una tabella chiamata Cars (che contiene 15 record casuali di auto):
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
Funzione RANK
La funzione RANK viene utilizzata per recuperare le righe classificate in base alla condizione della clausola ORDER BY. Ad esempio, se vuoi trovare il nome dell'auto con la terza potenza più alta, puoi utilizzare la funzione RANK.
Vediamo la funzione RANK in azione:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
Lo script sopra trova e classifica tutti i record nella tabella Cars e li ordina in ordine di potenza decrescente. L'output è simile a questo:
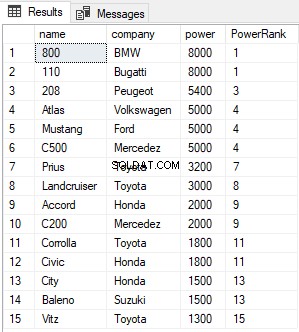
La colonna PowerRank nella tabella sopra contiene il RANK delle vetture ordinate in ordine decrescente di potenza. Una cosa interessante della funzione RANK è che se c'è un pareggio tra N record precedenti per il valore nella colonna ORDER BY, la funzione RANK salta le successive N-1 posizioni prima di incrementare il contatore. Ad esempio, nel risultato sopra, c'è un pareggio per i valori nella colonna di potenza tra la 1a e la 2a riga, quindi la funzione RANK salta il record successivo (2-1 =1) e salta direttamente alla 3a riga.
La funzione RANK può essere utilizzata in combinazione con la clausola PARTITION BY. In tal caso, il rango verrà reimpostato per ogni nuova partizione. Dai un'occhiata al seguente script:
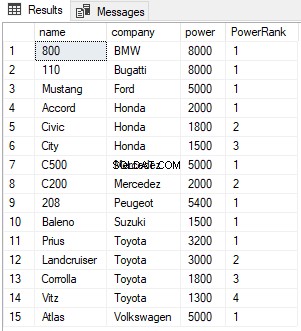
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
Nello script sopra, partiamo i risultati per colonna dell'azienda. Ora per ogni azienda, il RANK verrà reimpostato su 1 come mostrato di seguito:
Funzione DENSE_RANK
La funzione DENSE_RANK è simile alla funzione RANK, tuttavia la funzione DENSE_RANK non salta alcun rango se c'è un pareggio tra i ranghi dei record precedenti. Dai un'occhiata al seguente script.
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
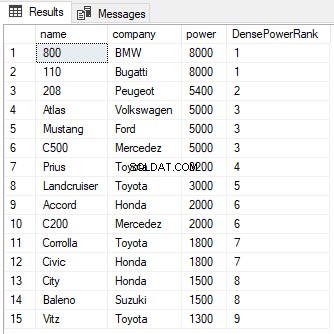
Si può vedere dall'output che nonostante ci sia un pareggio tra i ranghi delle prime due righe, il rango successivo non viene saltato ed è stato assegnato un valore di 2 invece di 3. Come con la funzione RANK, la clausola PARTITION BY può essere utilizzato anche con la funzione DENSE_RANK come mostrato di seguito:
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
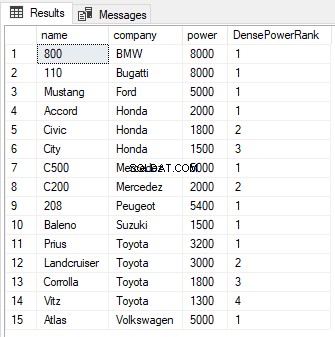
Funzione NUMERO_RIGA
A differenza delle funzioni RANK e DENSE_RANK, la funzione ROW_NUMBER restituisce semplicemente il numero di riga dei record ordinati che iniziano con 1. Ad esempio, se le funzioni RANK e DENSE_RANK dei primi due record nella colonna ORDER BY sono uguali, a entrambi viene assegnato 1 come loro RANK e DENSE_RANK. Tuttavia, la funzione ROW_NUMBER assegnerà i valori 1 e 2 a quelle righe senza tener conto del fatto che sono ugualmente prese in considerazione. Esegui il seguente script per vedere la funzione ROW_NUMBER in azione.
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
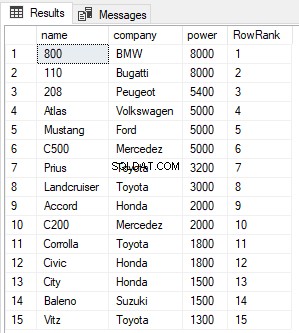
Dall'output, puoi vedere che la funzione ROW_NUMBER assegna semplicemente un nuovo numero di riga a ciascun record indipendentemente dal suo valore.
La clausola PARTITION BY può essere utilizzata anche con la funzione ROW_NUMBER come mostrato di seguito:
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
L'output è simile a questo:
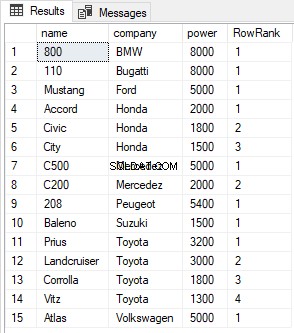
Somiglianze tra le funzioni RANK, DENSE_RANK e ROW_NUMBER
Le funzioni RANK, DENSE_RANK e ROW_NUMBER hanno le seguenti somiglianze:
1- Tutte richiedono una clausola order by.
2- Tutte restituiscono un numero intero crescente con un valore base di 1.
3- Se combinate con una clausola PARTITION BY, tutte queste funzioni reimpostano il valore intero restituito su 1 come abbiamo visto.
4- Se non ci sono valori duplicati nella colonna utilizzata dalla clausola ORDER BY, questi le funzioni restituiscono lo stesso output.
Per illustrare l'ultimo punto, creiamo una nuova tabella Car1 nel database ShowRoom senza valori duplicati nella colonna di alimentazione. Esegui il seguente script:
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
L'output è simile a questo:
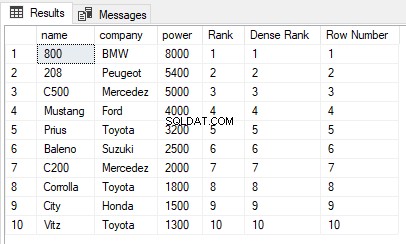
Puoi vedere che non ci sono valori duplicati nella colonna di alimentazione che viene utilizzata nella clausola ORDER BY, quindi l'output delle funzioni RANK, DENSE_RANK e ROW_NUMBER è lo stesso.
Differenza tra le funzioni RANK, DENSE_RANK e ROW_NUMBER
L'unica differenza tra la funzione RANK, DENSE_RANK e ROW_NUMBER è quando ci sono valori duplicati nella colonna utilizzata nella clausola ORDER BY.
Se torni alla tabella Cars nel database ShowRoom, puoi vedere che contiene molti valori duplicati. Proviamo a trovare il RANK, DENSE_RANK e ROW_NUMBER della tabella Cars1 ordinata per potenza. Esegui il seguente script:
SELECT nome, azienda, potere,
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
L'output è simile a questo:
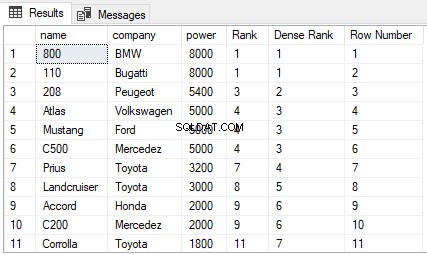
Dall'output, puoi vedere che la funzione RANK salta i successivi N-1 ranghi se c'è un pareggio tra N ranghi precedenti. D'altra parte, la funzione DENSE_RANK non salta i ranghi se c'è un pareggio tra i ranghi. Infine, la funzione ROW_NUMBER non si occupa di classifica. Restituisce semplicemente il numero di riga dei record ordinati. Anche se sono presenti record duplicati nella colonna utilizzata nella clausola ORDER BY, la funzione ROW_NUMBER non restituirà valori duplicati. Invece, continuerà ad aumentare indipendentemente dai valori duplicati.
Link utili:
Per saperne di più sulle funzioni ROW_NUMBER(), RANK() e DENSE_RANK(), leggi il fantastico articolo di Ahmad Yaseen:
Metodi per classificare le righe in SQL Server:ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE()



