Nei blog precedenti, io e i miei colleghi ti abbiamo mostrato come monitorare le prestazioni, gestire e distribuire cluster, eseguire backup e persino abilitare il failover automatico per TimescaleDB.
In questo blog ti mostreremo come ridimensionare la tua singola istanza TimescaleDB in un cluster multinodo in pochi semplici passaggi.
Inizieremo con una configurazione comune, un'istanza a nodo singolo in esecuzione su CentosOS. Il nodo è attivo e funzionante ed è già monitorato e gestito da ClusterControl.
Se desideri imparare a distribuire o importare la tua istanza TimescaleDB, dai un'occhiata al blog scritto dal mio collega Sebastian Insausti, "Come distribuire facilmente TimescaleDB".
L'impostazione è la seguente...
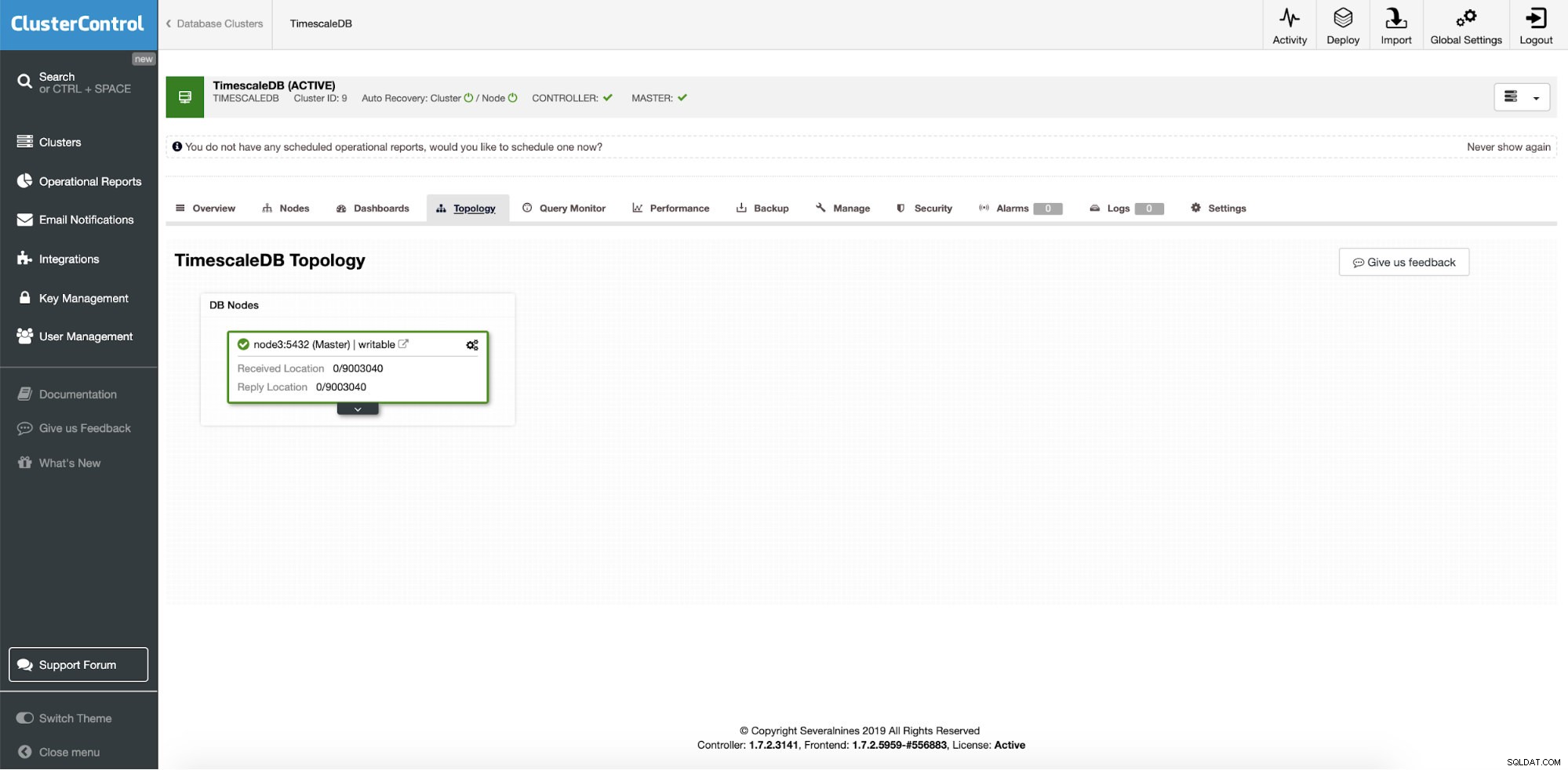 ClusterControl:istanza singola TimescaleDB
ClusterControl:istanza singola TimescaleDB Quindi, è una singola istanza di produzione e vogliamo convertirla in cluster senza tempi di inattività. Il nostro obiettivo principale è ridimensionare le operazioni di lettura delle applicazioni su altre macchine con la possibilità di utilizzarle come server HA di staging durante la scrittura di arresti anomali del server.
Un numero maggiore di nodi dovrebbe anche ridurre i tempi di inattività della manutenzione delle applicazioni. Come l'applicazione delle patch nella modalità di riavvio in sequenza:un nodo è stato patchato alla volta mentre altri nodi stanno servendo le connessioni al database.
L'ultimo requisito è creare un unico indirizzo per il nostro nuovo cluster in modo che i nostri nuovi nodi siano visibili per l'applicazione da un'unica posizione.

Possiamo riassumere il nostro piano d'azione in due fasi principali:
- Aggiunta di letture di replica
- Installa e configura Haproxy
Aggiunta di letture di replica
Se andiamo alle azioni del cluster e selezioniamo "Aggiungi slave di replica", possiamo creare una nuova replica da zero o aggiungere un database TimescaleDB esistente come replica.
 ClusterControl:Aggiungi replica slave
ClusterControl:Aggiungi replica slave 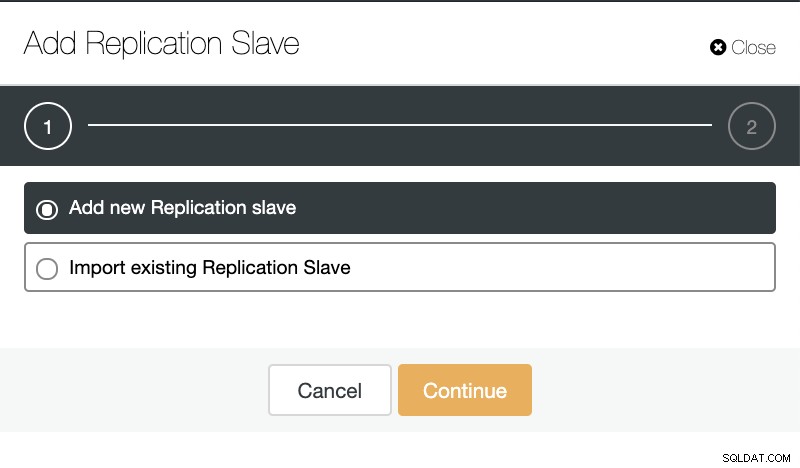 ClusterControl:Aggiungi nuovo slave di replica, Importa slave di replica esistente
ClusterControl:Aggiungi nuovo slave di replica, Importa slave di replica esistente Come puoi vedere nell'immagine sottostante, dobbiamo solo scegliere il nostro server Master, inserire l'indirizzo IP per il nostro nuovo server slave e la porta del database.
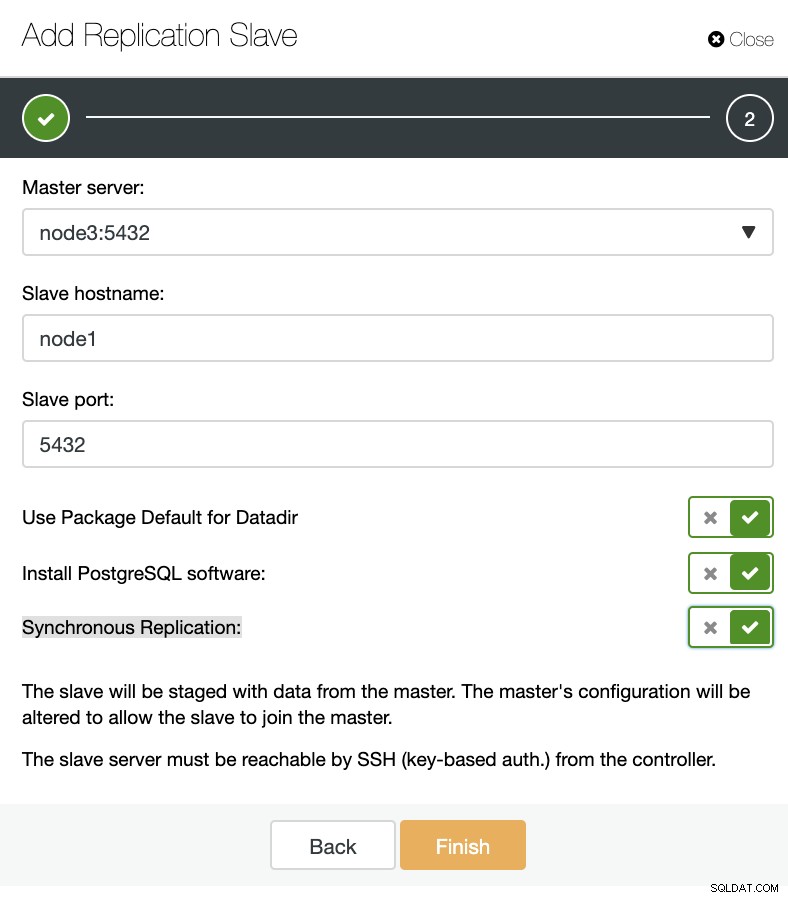 ClusterControl:Aggiungi replica slave
ClusterControl:Aggiungi replica slave Quindi possiamo scegliere se vogliamo che ClusterControl installi il software per noi e se lo slave di replica deve essere sincrono o asincrono. Quando importi un server slave esistente puoi utilizzare l'opzione di importazione come segue:
 ClusterControl:importazione slave di replica per TimescaleDB
ClusterControl:importazione slave di replica per TimescaleDB In entrambi i modi, possiamo aggiungere tutte le repliche che vogliamo. Nel nostro caso di esempio, aggiungeremo due nodi. CusterControl creerà un lavoro interno e si occuperà di tutti i passaggi necessari senza uno alla volta.
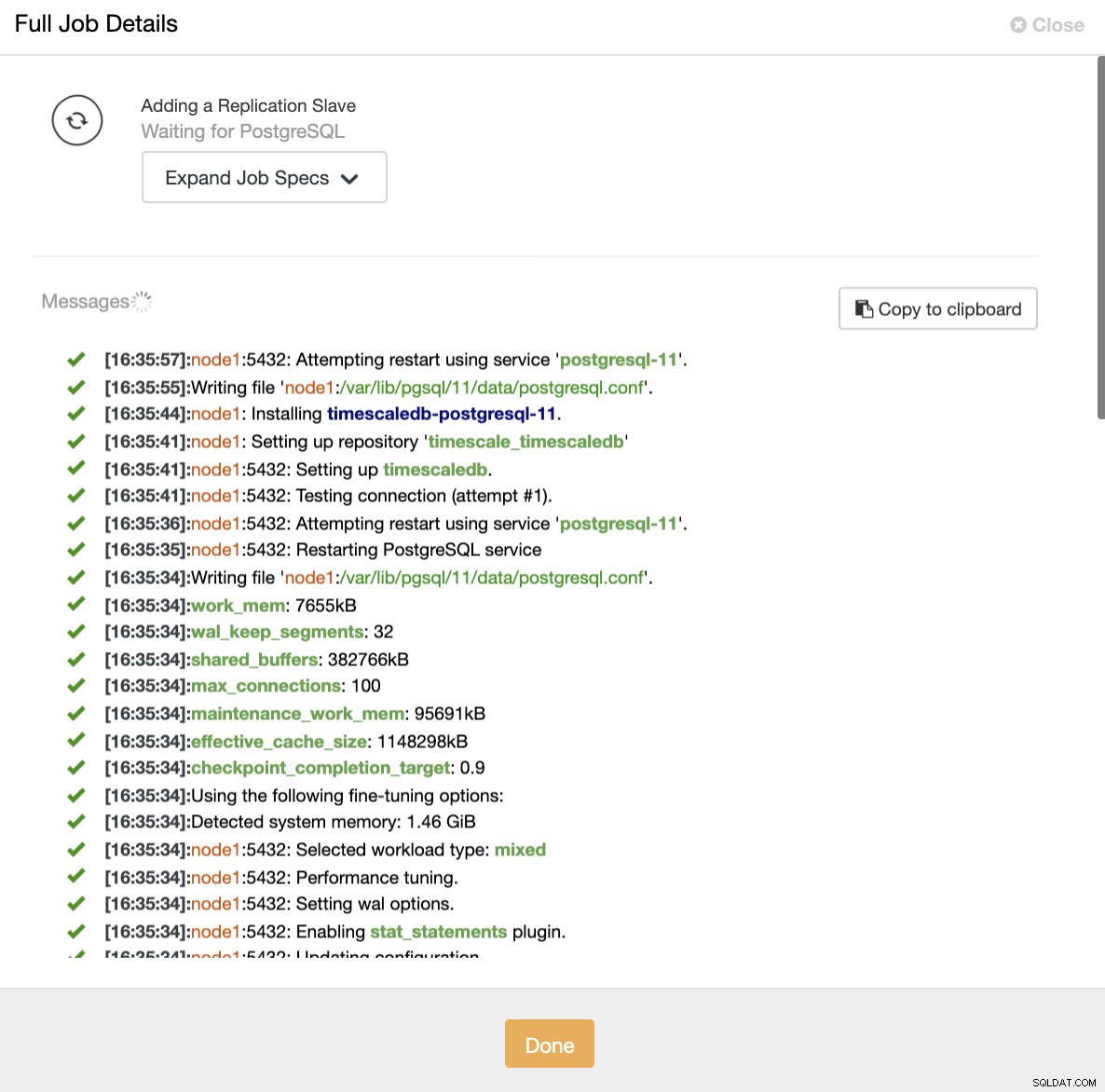 ClusterControl:aggiungi replica di lettura
ClusterControl:aggiungi replica di lettura Aggiunta di un Load Balancer a TimescaleDB
A questo punto, i nostri dati vengono distribuiti su più nodi o data center se si sceglie di aggiungere nodi slave di replica in una posizione diversa. Il cluster viene ridimensionato con due nodi di replica di lettura aggiuntivi.
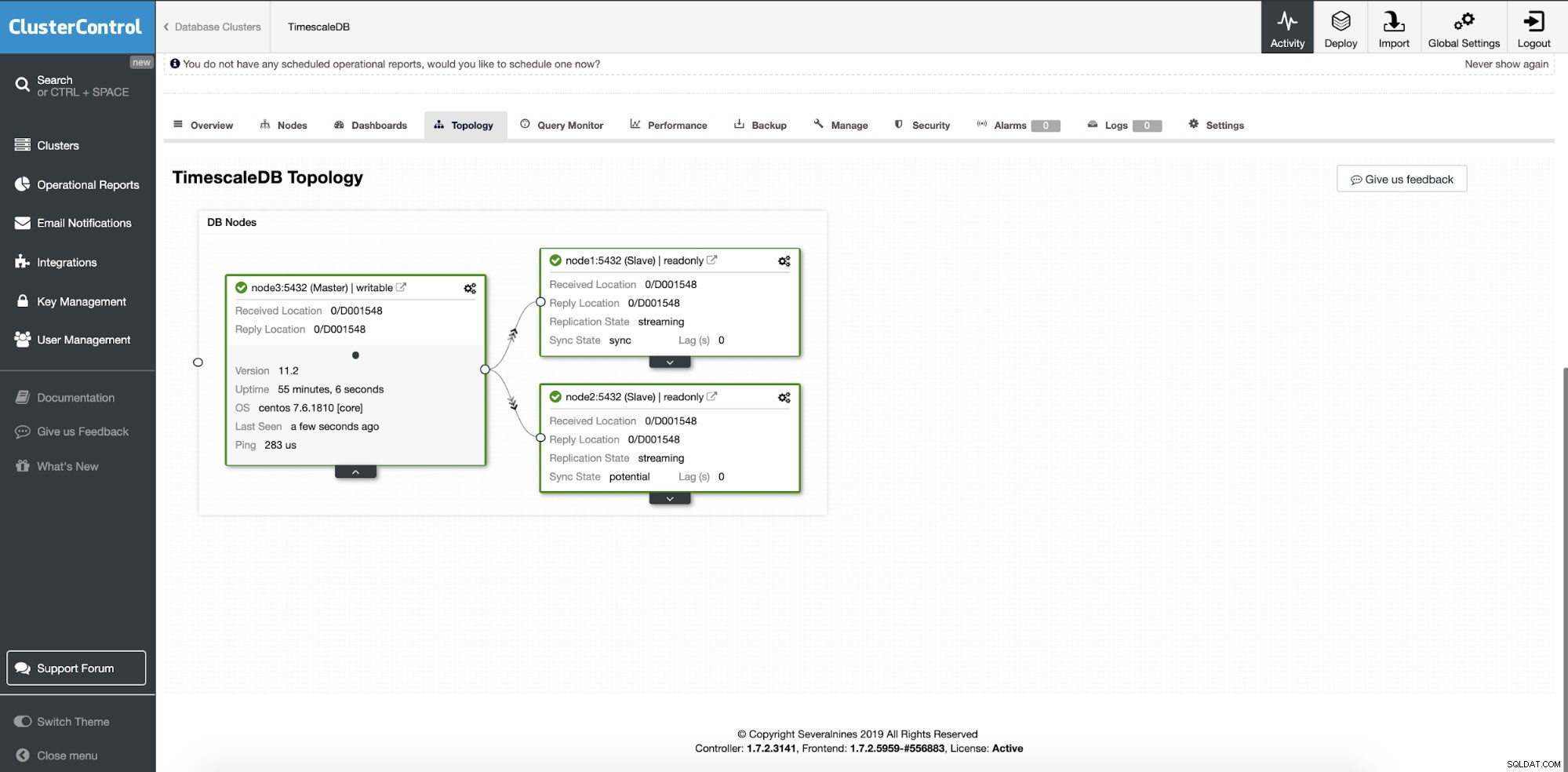 ClusterControl:aggiunti due nodi
ClusterControl:aggiunti due nodi La domanda è come fa l'applicazione a sapere a quale nodo del database accedere? Useremo HAProxy e diverse porte per le operazioni di scrittura e lettura.
Dal cluster TimescaleDB, dal menu contestuale scegli di aggiungere il servizio di bilanciamento del carico.

Ora dobbiamo fornire la posizione del server in cui installare Haproxy, quale criterio vogliamo utilizzare per le connessioni al database e quali nodi prendono parte alla configurazione di Haproxy.
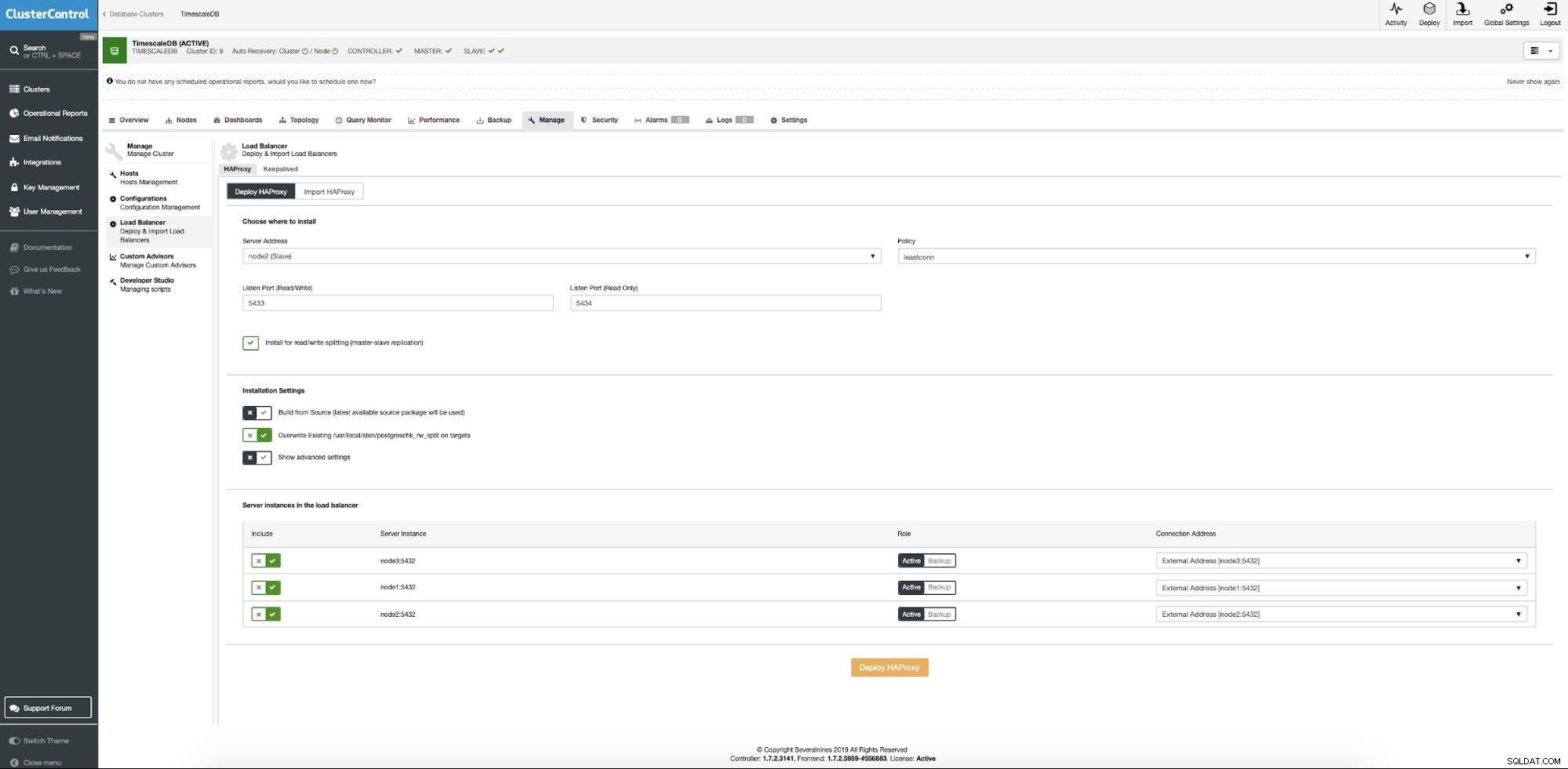
Quando tutto è pronto, premi il pulsante di distribuzione. Dopo alcuni minuti, dovremmo preparare la nostra configurazione del cluster. ClusterControl si occuperà di tutti i prerequisiti e le configurazioni per distribuire il servizio di bilanciamento del carico.
Dopo una distribuzione riuscita, possiamo vedere la topologia del nostro nuovo cluster; con bilanciamento del carico e nodi di lettura aggiuntivi. Con più nodi integrati, ClusterControl abilita automaticamente il ripristino automatico. In questo modo, quando il nodo master si interrompe, l'operazione di failover inizierà da sola.
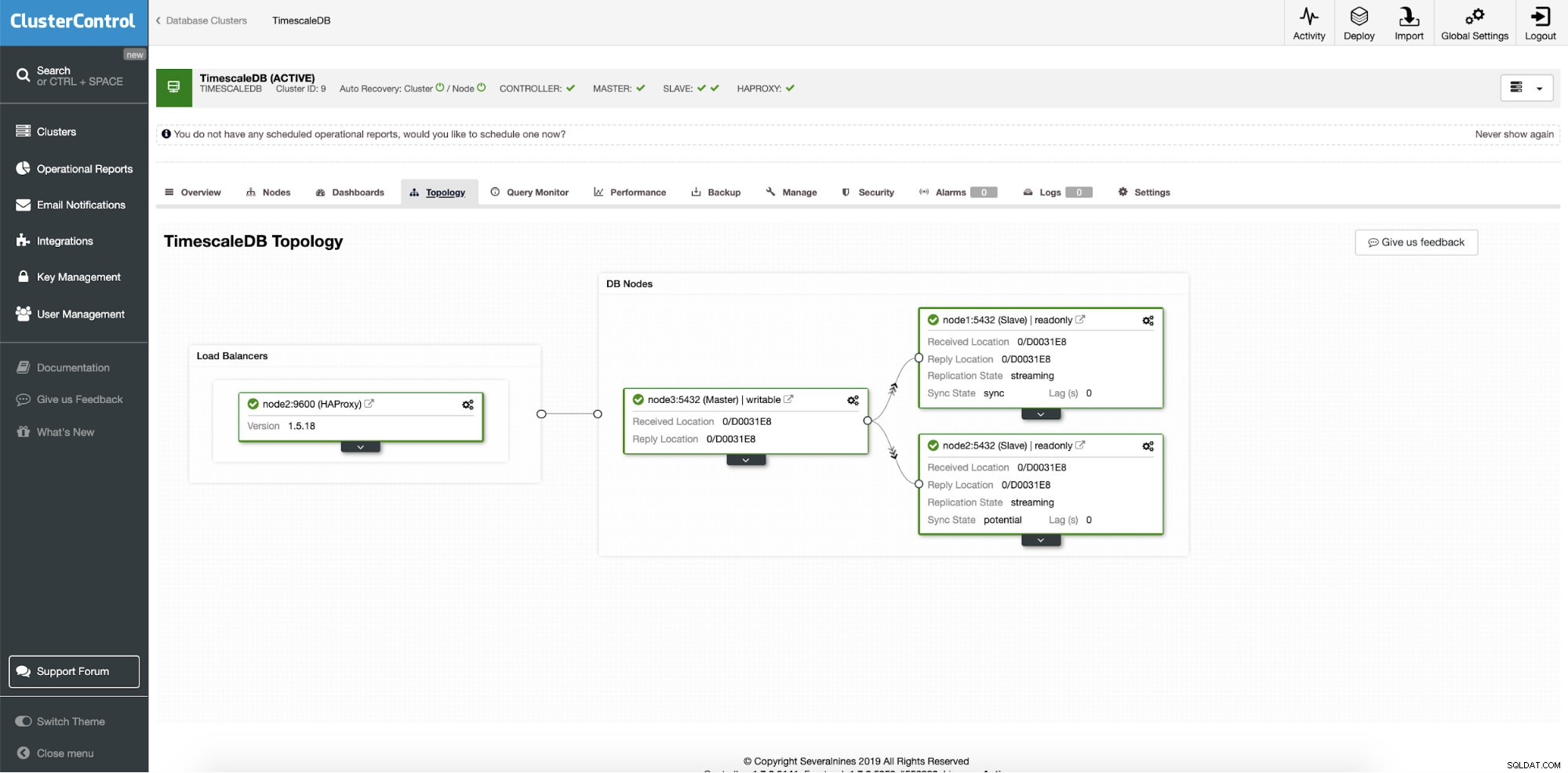 ClusterControl:topologia finale
ClusterControl:topologia finale Conclusione
TimescaleDB è un database open source inventato per rendere SQL scalabile per dati di serie temporali. Avere un modo automatizzato per estendere il proprio cluster è una chiave per ottenere prestazioni ed efficienza. Come abbiamo visto sopra, ora puoi scalare TimescaleDB usando ClusterControl con facilità.