APP (Annotazione di persistenza Java ) è la soluzione standard di Java per colmare il divario tra i modelli di dominio orientati agli oggetti e i sistemi di database relazionali. L'idea è di mappare le classi Java alle tabelle relazionali e le proprietà di quelle classi alle righe della tabella. Questo cambia la semantica dell'esperienza complessiva della codifica Java, collaborando senza soluzione di continuità con due diverse tecnologie all'interno dello stesso paradigma di programmazione. Questo articolo fornisce una panoramica e la sua implementazione di supporto in Java.
Una panoramica
I database relazionali sono forse la più stabile di tutte le tecnologie di persistenza disponibili nell'informatica invece di tutte le complessità che ne derivano. Questo perché oggi, anche nell'era dei cosiddetti "big data", i database relazionali "NoSQL" sono costantemente richiesti e prosperi. I database relazionali sono una tecnologia stabile non per semplici parole ma per la sua esistenza nel corso degli anni. NoSQL può essere utile per gestire grandi quantità di dati strutturati nell'azienda, ma i numerosi carichi di lavoro transazionali sono gestiti meglio tramite database relazionali. Inoltre, ci sono alcuni ottimi strumenti analitici associati ai database relazionali.
Per comunicare con i database relazionali, ANSI ha standardizzato un linguaggio chiamato SQL (Linguaggio di query strutturato ). Un'istruzione scritta in questo linguaggio può essere utilizzata sia per definire che per manipolare i dati. Ma il problema di SQL nel trattare con Java è che hanno una struttura sintattica non corrispondente e molto diversa al centro, il che significa che SQL è procedurale mentre Java è orientato agli oggetti. Quindi, si cerca una soluzione funzionante in modo tale che Java possa parlare in modo orientato agli oggetti e il database relazionale sarebbe comunque in grado di capirsi. JPA è la risposta a tale richiesta e fornisce il meccanismo per stabilire una soluzione funzionante tra i due.
Relativo alla mappatura degli oggetti
I programmi Java interagiscono con i database relazionali utilizzando il JDBC (Connettività database Java ) API. Un driver JDBC è la chiave per la connettività e consente a un programma Java di manipolare quel database utilizzando l'API JDBC. Una volta stabilita la connessione, il programma Java genera query SQL sotto forma di String s per comunicare le operazioni di creazione, inserimento, aggiornamento ed eliminazione. Questo è sufficiente per tutti gli scopi pratici, ma scomodo dal punto di vista di un programmatore Java. E se la struttura delle tabelle relazionali potesse essere rimodellata in classi Java pure e quindi potessi gestirle nel solito modo orientato agli oggetti? La struttura di una tabella relazionale è una rappresentazione logica dei dati in forma tabellare. Le tabelle sono composte da colonne che descrivono gli attributi di entità e le righe sono la raccolta di entità. Ad esempio, una tabella EMPLOYEE può contenere le seguenti entità con i loro attributi.
| Emp_number | Nome | dept_no | Stipendio | Luogo |
| 112233 | Pietro | 123 | 1200 | LA |
| 112244 | Ray | 234 | 1300 | NY |
| 112255 | Sabbia | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Le righe sono univoche per chiave primaria (emp_number) all'interno di una tabella; ciò consente una ricerca rapida. Una tabella può essere correlata a una o più tabelle da una chiave, come una chiave esterna (dept_no), che si riferisce alla riga equivalente in un'altra tabella.
Secondo la specifica Java Persistence 2.1, JPA aggiunge supporto per la generazione di schemi, metodi di conversione del tipo, uso del grafico di entità nelle query e operazioni di ricerca, contesto di persistenza non sincronizzato, invocazione di procedure memorizzate e iniezione nelle classi listener di entità. Include anche miglioramenti al linguaggio di query Java Persistence, all'API Criteria e alla mappatura delle query native.
Insomma, fa di tutto per dare l'illusione che non ci sia parte procedurale nella gestione dei database relazionali e che tutto sia orientato agli oggetti.
Attuazione dell'APP
JPA descrive la gestione dei dati relazionali nell'applicazione Java. È una specifica e ci sono una serie di implementazioni di essa. Alcune implementazioni popolari sono Hibernate, EclipseLink e Apache OpenJPA. JPA definisce i metadati tramite annotazioni nelle classi Java o tramite file di configurazione XML. Tuttavia, possiamo utilizzare sia XML che annotazione per descrivere i metadati. In tal caso, la configurazione XML sovrascrive le annotazioni. Ciò è ragionevole perché le annotazioni vengono scritte con il codice Java, mentre i file di configurazione XML sono esterni al codice Java. Pertanto, in seguito, se del caso, è necessario apportare modifiche ai metadati; nel caso di configurazione basata su annotazioni, richiede l'accesso diretto al codice Java. Questo potrebbe non essere sempre possibile. In tal caso, possiamo scrivere una configurazione di metadati nuova o modificata in un file XML senza alcun accenno di modifica nel codice originale e avere comunque l'effetto desiderato. Questo è il vantaggio dell'utilizzo della configurazione XML. Tuttavia, la configurazione basata su annotazioni è più comoda da usare ed è la scelta popolare tra i programmatori.
- Ibernazione è la più popolare e avanzata tra tutte le implementazioni JPA grazie a Red Hat. Utilizza le proprie modifiche e funzionalità aggiuntive che possono essere utilizzate in aggiunta alla sua implementazione JPA. Ha una comunità di utenti più ampia ed è ben documentato. Alcune delle funzionalità proprietarie aggiuntive sono il supporto per multi-tenancy, l'unione di entità non associate nelle query, la gestione del timestamp e così via.
- EclipseLink si basa su TopLink ed è un'implementazione di riferimento delle versioni JPA. Fornisce funzionalità JPA standard oltre ad alcune interessanti caratteristiche proprietarie, come il supporto da multi-tenancy, la gestione degli eventi di modifica del database e così via.
Utilizzo di JPA in un programma Java SE
Per utilizzare JPA in un programma Java, è necessario un provider JPA come Hibernate o EclipseLink o qualsiasi altra libreria. Inoltre, è necessario un driver JDBC che si connetta al database relazionale specifico. Ad esempio, nel codice seguente, abbiamo utilizzato le seguenti librerie:
- Fornitore: EclipseLink
- Driver JDBC: Driver JDBC per MySQL (Connettore/J)
Stabiliremo una relazione tra due tabelle, Dipendente e Dipartimento, come uno a uno e uno a molti, come illustrato nel diagramma EER seguente (vedere la Figura 1).
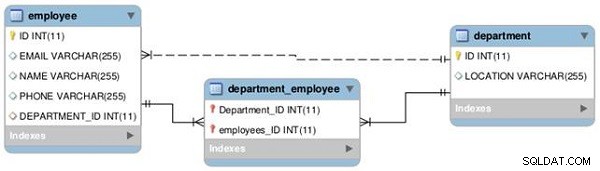
Figura 1: Relazioni tra tabelle
Il dipendente la tabella è mappata a una classe di entità utilizzando l'annotazione come segue:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
E il dipartimento la tabella è mappata a una classe di entità come segue:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Il file di configurazione, persistence.xml , viene creato in META-INF directory. Questo file contiene la configurazione della connessione, come il driver JDBC utilizzato, il nome utente e la password per l'accesso al database e altre informazioni rilevanti richieste dal provider JPA per stabilire la connessione al database.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Le entità non persistono. La logica deve essere applicata per manipolare le entità per gestire il loro ciclo di vita persistente. L'Gestore entità l'interfaccia fornita da JPA consente all'applicazione di gestire e cercare entità nel database relazionale. Creiamo un oggetto query con l'aiuto di EntityManager per comunicare con il database. Per ottenere EntityManager per un determinato database, utilizzeremo un oggetto che implementa un EntityManagerFactory interfaccia. C'è un statico metodo, chiamato createEntityManagerFactory , nella Persistenza classe che restituisce EntityManagerFactory per l'unità di persistenza specificata come Stringa discussione. Nella seguente rudimentale implementazione, abbiamo implementato la logica.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Ora siamo pronti per creare l'interfaccia principale dell'applicazione. Qui, abbiamo implementato solo l'operazione di inserimento per motivi di semplicità e vincoli di spazio.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Nota: Consulta la documentazione dell'API Java appropriata per informazioni dettagliate sulle API utilizzate nel codice precedente. |
Conclusione
Come dovrebbe essere ovvio, la terminologia centrale di JPA e del contesto di persistenza è più vasta di quanto viene qui fornito, ma iniziare con una rapida panoramica è meglio del lungo e intricato codice sporco e dei loro dettagli concettuali. Se hai una piccola esperienza di programmazione in JDBC di base, apprezzerai senza dubbio il modo in cui JPA può semplificarti la vita. Approfondiremo gradualmente l'APP man mano che andremo avanti nei prossimi articoli.