Qualsiasi programmatore ti dirà che scrivere codice multi-thread sicuro può essere difficile. Richiede grande cura e una buona comprensione dei problemi tecnici coinvolti. Come persona del database, potresti pensare che questo tipo di difficoltà e complicazioni non si applichi quando scrivi T-SQL. Quindi, può essere un po' uno shock rendersi conto che il codice T-SQL è anche vulnerabile al tipo di condizioni di gara e ad altri rischi per l'integrità dei dati più comunemente associati alla programmazione multi-thread. Questo è vero sia che si tratti di una singola istruzione T-SQL o di un gruppo di istruzioni racchiuse in una transazione esplicita.
Al centro del problema c'è il fatto che i sistemi di database consentono l'esecuzione di più transazioni contemporaneamente. Questo è uno stato di cose ben noto (e molto desiderabile), ma gran parte del codice T-SQL di produzione presuppone ancora tranquillamente che i dati sottostanti non cambino durante l'esecuzione di una transazione o di una singola istruzione DML come SELECT , INSERT , UPDATE , DELETE o MERGE .
Anche quando l'autore del codice è a conoscenza dei possibili effetti di modifiche simultanee dei dati, troppo spesso si presume che l'uso di transazioni esplicite fornisca una protezione maggiore di quella effettivamente giustificata. Questi presupposti e idee sbagliate possono essere sottili e sono certamente in grado di fuorviare anche i professionisti esperti di database.
Ora, ci sono casi in cui questi problemi non contano molto in senso pratico. Ad esempio, il database potrebbe essere di sola lettura o potrebbe esserci qualche altra garanzia genuina che nessun altro cambierà i dati sottostanti mentre ci stiamo lavorando. Allo stesso modo, l'operazione in questione potrebbe non richiedere risultati che sono esattamente corretta; i nostri consumatori di dati potrebbero essere perfettamente soddisfatti di un risultato approssimativo (anche uno che non rappresenta lo stato di commit del database in nessun punto nel tempo).
Problemi di concorrenza
La questione dell'interferenza tra attività eseguite contemporaneamente è un problema familiare agli sviluppatori di applicazioni che lavorano in linguaggi di programmazione come C# o Java. Le soluzioni sono molte e varie, ma generalmente prevedono l'utilizzo di operazioni atomiche o ottenere una risorsa mutuamente esclusiva (come un lucchetto ) mentre è in corso un'operazione sensibile. Laddove non vengono prese le dovute precauzioni, i probabili risultati sono dati danneggiati, un errore o forse anche un arresto anomalo completo.
Molti degli stessi concetti (ad es. operazioni atomiche e blocchi) esistono nel mondo dei database, ma sfortunatamente spesso presentano differenze cruciali di significato . La maggior parte delle persone del database è a conoscenza delle proprietà ACID delle transazioni del database, dove la A sta per atomico . SQL Server utilizza anche blocchi (e altri dispositivi di mutua esclusione internamente). Nessuno di questi termini significa esattamente ciò che un programmatore C# o Java esperto si aspetterebbe ragionevolmente e anche molti professionisti di database hanno una comprensione confusa di questi argomenti (come testimonierà una rapida ricerca utilizzando il tuo motore di ricerca preferito).
Per ribadire, a volte questi problemi non saranno una preoccupazione pratica. Se scrivi una query per contare il numero di ordini attivi in un sistema di database, quanto è importante se il conteggio è leggermente fuori scala? O se riflette lo stato del database in un altro momento?
È comune per i sistemi reali fare un compromesso tra concorrenza e coerenza (anche se il progettista non ne era a conoscenza in quel momento – informato i compromessi sono forse un animale più raro). I sistemi reali spesso funzionano abbastanza bene , con eventuali anomalie di breve durata o ritenute irrilevanti. Un utente che vede uno stato incoerente su una pagina Web risolverà spesso il problema aggiornando la pagina. Se il problema viene segnalato, molto probabilmente verrà chiuso come Non riproducibile. Non sto dicendo che questo è uno stato di cose desiderabile, sto solo riconoscendo che accade.
Tuttavia, è estremamente utile comprendere i problemi di concorrenza a un livello fondamentale. Essere a conoscenza di loro ci permette di scrivere in modo corretto (o informato corretto-abbastanza) T-SQL come richiesto dalle circostanze. Ancora più importante, ci consente di evitare di scrivere T-SQL che potrebbe compromettere l'integrità logica dei nostri dati.
Ma SQL Server fornisce garanzie ACID!
Sì, lo fa, ma non sono sempre quello che ti aspetteresti e non proteggono tutto. Il più delle volte, gli esseri umani leggono molto di più in ACID di quanto sia giustificato.
I componenti più frequentemente fraintesi dell'acronimo ACID sono le parole Atomic, Consistent e Isolated – di cui parleremo tra poco. L'altro, Resistente , è abbastanza intuitivo purché ricordi che si applica solo a persistenti (recuperabile) utente dati.
Detto questo, SQL Server 2014 inizia a offuscare i confini della proprietà Durable con l'introduzione della durabilità ritardata generale e della durabilità solo dello schema OLTP in memoria. Li cito solo per completezza, non discuteremo ulteriormente di queste nuove funzionalità. Passiamo alle proprietà ACID più problematiche:
La proprietà atomica
Molti linguaggi di programmazione forniscono operazioni atomiche che può essere utilizzato per proteggere da race condition e altri effetti indesiderati di concorrenza, in cui più thread di esecuzione possono accedere o modificare strutture di dati condivise. Per lo sviluppatore dell'applicazione, un'operazione atomica viene fornita con una garanzia esplicita di isolamento completo dagli effetti di altre elaborazioni simultanee in un programma multi-thread.
Una situazione analoga si verifica nel mondo dei database, in cui più query T-SQL accedono e modificano contemporaneamente i dati condivisi (cioè il database) da thread diversi. Nota che qui non stiamo parlando di query parallele; le normali query a thread singolo vengono regolarmente pianificate per essere eseguite contemporaneamente all'interno di SQL Server su thread di lavoro separati.
Sfortunatamente, la proprietà atomica delle transazioni SQL garantisce solo che le modifiche ai dati eseguite all'interno di una transazione hanno esito positivo o negativo come unità . Niente di più. Non vi è certamente alcuna garanzia di isolamento completo dagli effetti di altri trattamenti simultanei. Notare anche di passaggio che la proprietà della transazione atomica non dice nulla su alcuna garanzia sulla lettura dati.
Dichiarazioni singole
Inoltre, non c'è niente di speciale in una singola dichiarazione in SQL Server. Quando una transazione contenente esplicita (BEGIN TRAN...COMMIT TRAN ) non esiste, una singola istruzione DML viene comunque eseguita all'interno di una transazione di autocommit. Le stesse garanzie ACID si applicano a una singola dichiarazione e anche le stesse limitazioni. In particolare, una singola istruzione viene fornita senza particolari garanzie che i dati non cambieranno mentre è in corso.
Considera la seguente query di AdventureWorks sul giocattolo:
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); La query ha lo scopo di visualizzare le informazioni sull'ordine che è classificato al primo posto per Quantità. Il piano di esecuzione è il seguente:
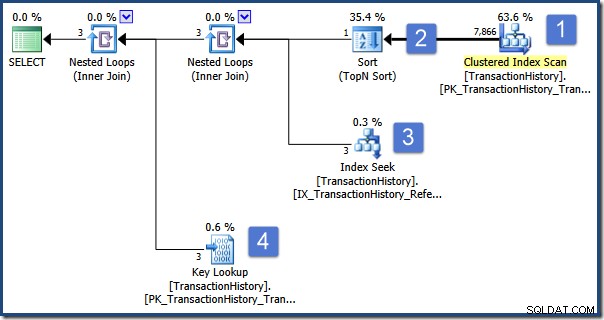
Le operazioni principali di questo piano sono:
- Scansiona la tabella per trovare le righe con il tipo di transazione richiesto
- Trova l'ID ordine con l'ordinamento più alto in base alle specifiche nella sottoquery
- Trova le righe (nella stessa tabella) con l'ID ordine selezionato utilizzando un indice non cluster
- Cerca i dati della colonna rimanenti utilizzando l'indice cluster
Ora immagina che un utente simultaneo modifichi l'Ordine 495, cambiando il suo Tipo di transazione da P a W, e commetta la modifica al database. Per fortuna, questa modifica viene eseguita mentre la nostra query esegue l'operazione di ordinamento (passaggio 2).
Al termine dell'ordinamento, la ricerca dell'indice al passaggio 3 trova le righe con l'ID ordine selezionato (che risulta essere 495) e la ricerca chiave al passaggio 4 recupera le colonne rimanenti dalla tabella di base (dove il tipo di transazione è ora W) .
Questa sequenza di eventi significa che la nostra query produce un risultato apparentemente impossibile:

Invece di trovare ordini con tipo di transazione P come specificato dalla query, i risultati mostrano il tipo di transazione W.
La causa principale è chiara:la nostra query presumeva implicitamente che i dati non potessero cambiare mentre era in corso la nostra query a istruzione singola. La finestra di opportunità in questo caso era relativamente ampia a causa del blocking sort, ma lo stesso tipo di race condition può verificarsi in qualsiasi fase dell'esecuzione della query, in generale. Naturalmente, i rischi sono generalmente maggiori con livelli aumentati di modifiche simultanee, tabelle più grandi e dove nel piano di query vengono visualizzati operatori di blocco.
Un altro mito persistente nella stessa area generale è che MERGE è da preferire a INSERT separato , UPDATE e DELETE perché l'istruzione singola MERGE è atomico. Questa è una sciocchezza, ovviamente. Torneremo su questo tipo di ragionamento più avanti nella serie.
Il messaggio generale a questo punto è che, a meno che non vengano adottate misure esplicite per garantire diversamente, le righe di dati e le voci di indice possono cambiare, spostare la posizione o scomparire del tutto in qualsiasi momento durante il processo di esecuzione. Un'immagine mentale del cambiamento costante e casuale nel database è una buona idea da tenere a mente durante la scrittura di query T-SQL.
La proprietà di coerenza
Anche la seconda parola dell'acronimo ACID ha una gamma di possibili interpretazioni. In un database di SQL Server, Coerenza significa solo che una transazione lascia il database in uno stato che non viola alcun vincolo attivo. È importante comprendere appieno quanto sia limitata tale affermazione:le uniche garanzie ACID di integrità dei dati e coerenza logica sono quelle fornite dai vincoli attivi.
SQL Server fornisce una gamma limitata di vincoli per imporre l'integrità logica, inclusa PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE e NOT NULL . Questi sono tutti garantiti per essere soddisfatti al momento del commit di una transazione. Inoltre, SQL Server garantisce il fisico integrità del database in ogni momento, ovviamente.
I vincoli incorporati non sono sempre sufficienti per far rispettare tutte le regole di business e di integrità dei dati che vorremmo. È certamente possibile essere creativi con le strutture standard, ma queste diventano rapidamente complesse e possono comportare l'archiviazione di dati duplicati.
Di conseguenza, la maggior parte dei database reali contiene almeno alcune routine T-SQL scritte per applicare regole aggiuntive, ad esempio nelle procedure memorizzate e nei trigger. La responsabilità di garantire che questo codice funzioni correttamente ricade interamente sull'autore:la proprietà Consistency non fornisce protezioni specifiche.
Per sottolineare il punto, gli pseudo-vincoli scritti in T-SQL devono funzionare correttamente indipendentemente dalle modifiche simultanee che potrebbero verificarsi. Uno sviluppatore di applicazioni potrebbe proteggere un'operazione sensibile come quella con un'istruzione di blocco. La cosa più vicina ai programmatori T-SQL che hanno a disposizione per la procedura memorizzata a rischio e il codice trigger è il sp_getapplock, usato relativamente di rado procedura memorizzata di sistema. Questo non vuol dire che sia l'unica, o addirittura preferita, opzione, solo che esiste e può essere la scelta giusta in alcune circostanze.
La proprietà di isolamento
Questa è facilmente la più spesso fraintesa delle proprietà della transazione ACID.
In linea di principio, un completamente isolato la transazione viene eseguita come l'unica attività in esecuzione sul database durante la sua durata. Altre transazioni possono iniziare solo una volta che la transazione corrente è completamente terminata (ad es. commit o rollback). Se eseguita in questo modo, una transazione sarebbe davvero un'operazione atomica , nel senso stretto che una persona non del database attribuirebbe alla frase.
In pratica, le transazioni del database operano invece con un grado di isolamento specificato dal livello di isolamento delle transazioni attualmente in vigore (che si applica ugualmente alle dichiarazioni autonome, ricorda). Questo compromesso (il laurea di isolamento) è la conseguenza pratica dei compromessi tra concorrenza e correttezza menzionati in precedenza. Un sistema che elaborasse letteralmente le transazioni una per una, senza sovrapposizioni temporali, fornirebbe un isolamento completo, ma il throughput complessivo del sistema sarebbe probabilmente scarso.
La prossima volta
La parte successiva di questa serie continuerà l'esame dei problemi di concorrenza, delle proprietà ACID e dell'isolamento delle transazioni con uno sguardo dettagliato al livello di isolamento serializzabile, un altro esempio di qualcosa che potrebbe non significare quello che pensi che significhi.
[Vedi l'indice per l'intera serie]