Le tue responsabilità come DBA (o DBCC CHECKDB . Puoi arrivarci in parte creando un semplice piano di manutenzione con un "Attività di verifica dell'integrità del database", tuttavia, nella mia mente, questo è solo selezionare una casella di controllo.
Se guardi più da vicino, c'è ben poco che puoi fare per controllare come funziona l'attività. Anche il pannello Proprietà piuttosto ampio espone molte impostazioni per il sottopiano di manutenzione, ma praticamente nulla sul DBCC comandi che eseguirà. Personalmente penso che dovresti adottare un approccio molto più proattivo e controllato su come esegui il tuo CHECKDB operazioni negli ambienti di produzione, creando i tuoi lavori e realizzando manualmente il tuo DBCC comandi. Potresti adattare la tua pianificazione o i comandi stessi a database diversi, ad esempio il database di appartenenza ASP.NET non è probabilmente così cruciale come il tuo database di vendita e potrebbe tollerare controlli meno frequenti e/o meno accurati.
Ma per i tuoi database cruciali, ho pensato di mettere insieme un post per dettagliare alcune delle cose su cui avrei indagato al fine di ridurre al minimo l'interruzione DBCC i comandi possono causare - e di quali miti e trambusto di marketing dovresti stare attento. E voglio ringraziare Paul "Mr. DBCC" Randal (@PaulRandal) per aver fornito un prezioso contributo, non solo per questo post specifico, ma anche per gli infiniti consigli che fornisce sul suo blog, #sqlhelp e nella formazione SQLskills Immersion.
Prendi tutte queste idee con le pinze e fai del tuo meglio per eseguire test adeguati nel tuo ambiente:non tutti questi suggerimenti produrranno prestazioni migliori in tutti gli ambienti. Ma devi a te stesso, ai tuoi utenti e ai tuoi stakeholder almeno considerare l'impatto che il tuo CHECKDB le operazioni potrebbero avere e adottare misure per mitigare tali effetti ove possibile, senza introdurre rischi inutili non controllando le cose giuste.
Riduci il rumore e consuma tutti gli errori
Non importa dove stai eseguendo CHECKDB , usa sempre WITH NO_INFOMSGS opzione. Questo semplicemente sopprime tutto l'output irrilevante che ti dice solo quante righe ci sono in ogni tabella; se sei interessato a queste informazioni, puoi ottenerle da semplici query sui DMV e non mentre DBCC è in esecuzione. Sopprimere l'output rende molto meno probabile la perdita di un messaggio critico sepolto in tutto quell'output felice.
Allo stesso modo, dovresti sempre usare WITH ALL_ERRORMSGS opzione, ma soprattutto se si esegue SQL Server 2008 RTM o SQL Server 2005 (in questi casi, l'elenco degli errori per oggetto potrebbe essere troncato a 200). Per qualsiasi CHECKDB operazioni diverse dai rapidi controlli ad hoc, dovresti considerare di indirizzare l'output a un file. Management Studio è limitato a 1000 righe di output da DBCC CHECKDB , quindi potresti perdere alcuni errori se superi questa cifra.
Sebbene non sia strettamente un problema di prestazioni, l'utilizzo di queste opzioni ti impedirà di dover eseguire nuovamente il processo. Ciò è particolarmente critico se sei nel mezzo del ripristino di emergenza.
Scarica i controlli logici ove possibile
Nella maggior parte dei casi, CHECKDB passa la maggior parte del suo tempo a eseguire controlli logici dei dati. Se hai la possibilità di eseguire questi controlli su una copia vera dei dati, puoi concentrare i tuoi sforzi sulla struttura fisica dei tuoi sistemi di produzione e utilizzare il server secondario per gestire tutti i controlli logici e alleviare il carico dal primario. Tramite server secondario , intendo solo quanto segue:
- Il luogo in cui testi i tuoi ripristini completi, perché testi i tuoi ripristini, giusto?
Altre persone (in particolare la gigantesca forza del marketing che è Microsoft) potrebbero averti convinto che altre forme di server secondari sono adatte per DBCC controlli. Ad esempio:
- un gruppo di disponibilità AlwaysOn leggibile secondario;
- uno snapshot di un database con mirroring;
- un log spedito secondario;
- Mirroring SAN;
- o altre varianti...
Sfortunatamente, non è così e nessuno di questi secondari è un luogo valido e affidabile per eseguire i controlli in alternativa al primario. Solo un backup uno per uno può fungere da vera copia; qualsiasi altra cosa che si basi su cose come l'applicazione dei backup dei log per raggiungere uno stato coerente non rifletterà in modo affidabile i problemi di integrità sul primario.
Quindi, piuttosto che provare a scaricare i tuoi controlli logici su un secondario e non eseguirli mai sul primario, ecco cosa suggerisco:
- Assicurati di testare frequentemente i ripristini dei tuoi backup completi. E no, questo non include
COPY_ONLYbackup da un secondario AG, per gli stessi motivi di cui sopra, ciò sarebbe valido solo nel caso in cui tu abbia appena avviato il secondario con un ripristino completo. - Esegui
DBCC CHECKDBspesso contro il pieno ripristinare, prima di fare qualsiasi altra cosa. Ancora una volta, la riproduzione dei record di registro a questo punto invaliderà questo database come una copia vera della fonte. - Esegui
DBCC CHECKDBcontro la tua primaria, magari divisa nei modi suggeriti da Paul Randal, e/o con orari meno frequenti, e/o usandoPHYSICAL_ONLYpiù spesso che non. Questo può dipendere dalla frequenza e dall'affidabilità delle tue prestazioni (2). - Non dare mai per scontato che i controlli sul secondario siano sufficienti. Anche con una replica esatta del database primario, possono verificarsi problemi fisici nel sottosistema di I/O del database primario che non si propagheranno mai al secondario.
- Analizza sempre
DBCCproduzione. Basta eseguirlo e ignorarlo, per spuntarlo da un elenco, è utile quanto eseguire backup e dichiarare il successo senza mai testare che puoi effettivamente ripristinare quel backup quando necessario.
Esperimento con i flag di traccia 2549, 2562 e 2566
Ho eseguito alcuni test approfonditi di due flag di traccia (2549 e 2562) e ho scoperto che possono produrre miglioramenti sostanziali delle prestazioni, tuttavia Lonny segnala che non sono più necessari o utili. Se sei nel 2016 o più recente, salta questa intera sezione . Se utilizzi una versione precedente, questi due flag di traccia sono descritti in modo molto più dettagliato nella KB #2634571, ma sostanzialmente:
- Traccia bandiera 2549
- Ciò ottimizza il processo checkdb trattando ogni singolo file di database come residente su un disco sottostante univoco. Questo va bene se il tuo database ha un singolo file di dati o se sai che ogni file di database si trova, in effetti, su un'unità separata. Se il tuo database ha più file e condividono un unico mandrino collegato direttamente, dovresti fare attenzione a questo flag di traccia, poiché potrebbe causare più danni che benefici.
IMPORTANTE :sql.sasquatch segnala una regressione nel comportamento di questo flag di traccia in SQL Server 2014.
- Ciò ottimizza il processo checkdb trattando ogni singolo file di database come residente su un disco sottostante univoco. Questo va bene se il tuo database ha un singolo file di dati o se sai che ogni file di database si trova, in effetti, su un'unità separata. Se il tuo database ha più file e condividono un unico mandrino collegato direttamente, dovresti fare attenzione a questo flag di traccia, poiché potrebbe causare più danni che benefici.
- Traccia bandiera 2562
- Questo flag considera l'intero processo di checkdb come un singolo batch, a costo di un maggiore utilizzo di tempdb (fino al 5% della dimensione del database).
- Utilizza un algoritmo migliore per determinare come leggere le pagine dal database, riducendo la contesa sui latch (in particolare per
DBCC_MULTIOBJECT_SCANNER). Tieni presente che questo miglioramento specifico si trova nel percorso del codice di SQL Server 2012, quindi ne trarrai vantaggio anche senza il flag di traccia. Questo può evitare errori come:
Timeout durante l'attesa del latch:classe 'DBCC_MULTIOBJECT_SCANNER'.
- I due flag di traccia precedenti sono disponibili nelle seguenti versioni:
- Aggiornamento cumulativo SQL Server 2008 Service Pack 2 9+
(10.00.4330 -> 10.00.5499)Aggiornamento cumulativo SQL Server 2008 Service Pack 3 4+
(10.00.5775+)Aggiornamento cumulativo SQL Server 2008 R2 RTM 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 aggiornamento cumulativo 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, tutte le versioni
(11.00.2100+) - Traccia bandiera 2566
- Se si utilizza ancora SQL Server 2005, questo flag di traccia, introdotto nel 2005 SP2 CU#9 (9.00.3282) (sebbene non documentato nell'articolo della Knowledge Base dell'aggiornamento cumulativo, KB n. 953752), tenta di correggere le scarse prestazioni di
DATA_PURITYcontrolli su sistemi basati su x64. A un certo punto, potresti vedere più dettagli in KB #945770, ma sembra che l'articolo sia stato cancellato sia dal sito di supporto di Microsoft che dal computer WayBack. Questo flag di traccia non dovrebbe essere necessario nelle versioni più moderne di SQL Server, poiché il problema nel Query Processor è stato risolto.
- Se si utilizza ancora SQL Server 2005, questo flag di traccia, introdotto nel 2005 SP2 CU#9 (9.00.3282) (sebbene non documentato nell'articolo della Knowledge Base dell'aggiornamento cumulativo, KB n. 953752), tenta di correggere le scarse prestazioni di
Se intendi utilizzare uno di questi flag di traccia, ti consiglio vivamente di impostarli a livello di sessione utilizzando DBCC TRACEON piuttosto che come flag di traccia di avvio. Non solo ti consente di disattivarli senza dover eseguire il ciclo di SQL Server, ma ti consente anche di implementarli solo quando esegui determinati CHECKDB comandi, al contrario delle operazioni che utilizzano qualsiasi tipo di riparazione.
Riduci l'impatto di I/O:ottimizza tempdb
DBCC CHECKDB può fare un uso intenso di tempdb, quindi assicurati di pianificare l'utilizzo delle risorse lì. Questa è di solito una buona cosa da fare in ogni caso. Per CHECKDB ti consigliamo di allocare correttamente lo spazio a tempdb; l'ultima cosa che vuoi è per CHECKDB progresso (e qualsiasi altra operazione simultanea) per dover attendere un aumento automatico. Puoi farti un'idea dei requisiti usando WITH ESTIMATEONLY , come spiega Paolo qui. Tieni presente che la stima può essere piuttosto bassa a causa di un bug in SQL Server 2008 R2. Inoltre, se stai utilizzando il flag di traccia 2562, assicurati di soddisfare i requisiti di spazio aggiuntivi.
E, naturalmente, tutti i consigli tipici per l'ottimizzazione di tempdb su qualsiasi sistema sono appropriati anche qui:assicurati che tempdb sia sul proprio set di veloce mandrini, assicurati che sia dimensionato per ospitare tutte le altre attività simultanee senza dover crescere, assicurati di utilizzare un numero ottimale di file di dati, ecc. Alcune altre risorse che potresti prendere in considerazione:
- Ottimizzazione delle prestazioni di tempdb (MSDN)
- Pianificazione della capacità per tempdb (MSDN)
- Un mito di SQL Server DBA al giorno:(12/30) tempdb dovrebbe sempre avere un file di dati per core del processore
Riduci l'impatto I/O:controlla lo snapshot
Per eseguire CHECKDB , le versioni moderne di SQL Server tenteranno di creare uno snapshot nascosto del database sulla stessa unità (o su tutte le unità se i file di dati si estendono su più unità). Non puoi controllare questo meccanismo, ma se vuoi controllare dove CHECKDB opera, crea prima il tuo snapshot (è richiesta l'Enterprise Edition) su qualsiasi unità ti piace ed esegui il DBCC comando contro lo snapshot. In entrambi i casi, ti consigliamo di eseguire questa operazione durante un periodo di inattività relativo, per ridurre al minimo l'attività di copia in scrittura che passerà attraverso lo snapshot. E non vorrai che questa pianificazione entri in conflitto con operazioni di scrittura pesanti, come la manutenzione dell'indice o ETL.
Potresti aver visto suggerimenti per forzare CHECKDB per eseguire in modalità offline utilizzando il WITH TABLOCK opzione. Sconsiglio vivamente questo approccio. Se il tuo database viene utilizzato attivamente, la scelta di questa opzione renderà gli utenti frustrati. E se il database non viene utilizzato attivamente, non stai risparmiando spazio su disco evitando uno snapshot, poiché non ci saranno attività di copia in scrittura da archiviare.
Riduci l'impatto di I/O:evita gli errori 665/1450/1452
In alcuni casi potresti visualizzare uno dei seguenti errori:
Il sistema operativo ha restituito l'errore 1450 (risorse di sistema insufficienti per completare il servizio richiesto.) a SQL Server durante una scrittura all'offset 0x[…] nel file con handle 0x[…]. Si tratta in genere di una condizione temporanea e SQL Server continuerà a ripetere l'operazione. Se la condizione persiste, è necessario intraprendere un'azione immediata per correggerla.
Il sistema operativo ha restituito l'errore 665 (l'operazione richiesta non può essere completata a causa di una limitazione del file system) a SQL Server durante una scrittura all'offset 0x[…] nel file '[file]'
Ci sono alcuni suggerimenti qui per ridurre il rischio di questi errori durante CHECKDB operazioni e riducendone l'impatto in generale, con diverse correzioni disponibili, a seconda del sistema operativo e della versione di SQL Server in uso:
- Errori di file sparsi:1450 o 665 dovuti alla frammentazione del file:correzioni e soluzioni alternative
- SQL Server segnala un errore del sistema operativo 1450 o 1452 o 665 (tentativi)
Riduci l'impatto sulla CPU
DBCC CHECKDB è multi-thread per impostazione predefinita (ma solo in Enterprise Edition). Se il tuo sistema è vincolato alla CPU o desideri semplicemente CHECKDB per utilizzare meno CPU a costo di un'esecuzione più lunga, puoi considerare di ridurre il parallelismo in un paio di modi diversi:
DBCC CHECKDB (così come CHECKFILEGROUP e CHECKTABLE ). Il flag di traccia 2528 è descritto qui. Ovviamente questo è valido solo in Enterprise Edition, perché nonostante ciò che attualmente dice Books Online, la verità è che CHECKDB non va in parallelo nell'edizione standard. DBCC il comando stesso non supporta MAXDOP (almeno prima di SQL Server 2014 SP2), rispetta l'impostazione globale max degree of parallelism . Probabilmente non è qualcosa che farei in produzione a meno che non avessi altre opzioni, ma questo è un modo generale per controllare determinati DBCC comandi se non puoi sceglierli come target in modo più esplicito.
Chiedevamo un migliore controllo sul numero di CPU che DBCC CHECKDB utilizza, ma erano stati ripetutamente negati fino a SQL Server 2014 SP2. Quindi ora puoi aggiungere WITH MAXDOP = n al comando.
Le mie scoperte
Volevo dimostrare alcune di queste tecniche in un ambiente che potevo controllare. Ho installato AdventureWorks2012, quindi l'ho ampliato utilizzando lo script di ingrandimento AW scritto da Jonathan Kehayias (blog | @SQLPoolBoy), che ha portato il database a circa 7 GB. Quindi ho eseguito una serie di CHECKDB comanda contro di essa e li cronometra. Ho usato un semplice DBCC CHECKDB da solo, quindi tutti gli altri comandi utilizzati WITH NO_INFOMSGS, ALL_ERRORMSGS . Quindi quattro test con (a) nessun flag di traccia, (b) 2549, (c) 2562 e (d) entrambi 2549 e 2562. Quindi ho ripetuto quei quattro test, ma ho aggiunto il PHYSICAL_ONLY opzione, che ignora tutti i controlli logici. I risultati (media su 10 esecuzioni di test) sono eloquenti:
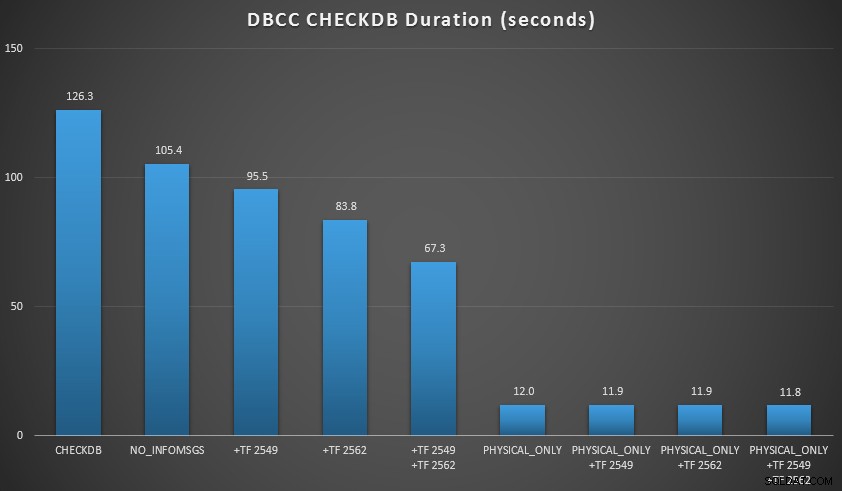
RISULTATI CHECKDB rispetto a 7 GB di database
Quindi ho ampliato ulteriormente il database, facendo molte copie delle due tabelle ingrandite, portando a una dimensione del database appena a nord di 70 GB, ed ho eseguito di nuovo i test. I risultati, ancora una volta in media su 10 esecuzioni di test:
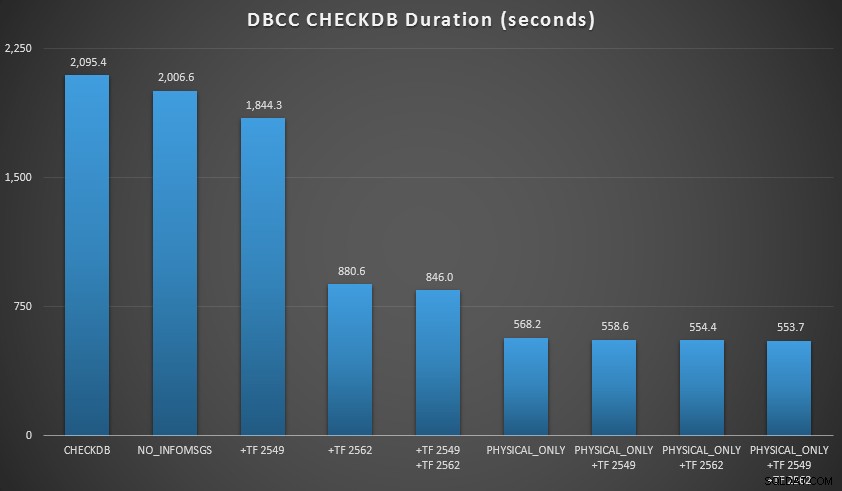
RISULTATI CHECKDB rispetto a 70 GB di database
In questi due scenari, ho imparato quanto segue (ancora una volta, tenendo presente che il tuo chilometraggio può variare e che dovrai eseguire i tuoi test per trarre conclusioni significative):
- Con database di piccole dimensioni,
NO_INFOMSGSl'opzione può ridurre significativamente il tempo di elaborazione quando i controlli vengono eseguiti in SSMS. Su database più grandi, tuttavia, questo vantaggio diminuisce, poiché il tempo e il lavoro spesi per trasmettere le informazioni diventano una parte così insignificante della durata complessiva. 21 secondi su 2 minuti sono sostanziali; 88 secondi su 35 minuti, non tanto. - I due flag di traccia che ho testato hanno avuto un impatto significativo sulle prestazioni, rappresentando una riduzione del tempo di esecuzione del 40-60% quando entrambi sono stati utilizzati insieme.
- Posso ridurre i tempi di elaborazione sulla mia istanza principale del 70-90% rispetto a un
CHECKDBstandard chiama senza opzioni. - Nel mio scenario, i flag di traccia hanno avuto un impatto minimo sulla durata durante l'esecuzione di
PHYSICAL_ONLYcontrolli.
Naturalmente, e non posso sottolinearlo abbastanza, si tratta di database relativamente piccoli e utilizzati solo in modo da poter eseguire test ripetuti e misurati in un ragionevole lasso di tempo. Questo server aveva 80 CPU logiche e 128 GB di RAM e io ero l'unico utente. La durata e l'interazione con altri carichi di lavoro sul sistema possono alterare un po' questi risultati. Ecco un rapido assaggio dell'utilizzo tipico della CPU, utilizzando SQL Sentry, durante uno dei CHECKDB operazioni (e nessuna delle opzioni ha davvero cambiato l'impatto complessivo sulla CPU, solo la durata):
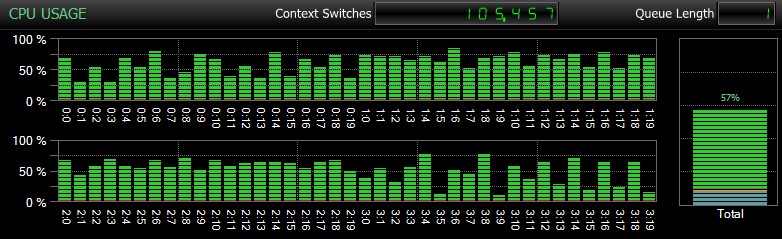
Impatto della CPU durante CHECKDB – modalità di campionamento
Ed ecco un'altra vista, che mostra profili CPU simili per tre diversi CHECKDB di esempio operazioni in modalità storica (ho sovrapposto una descrizione dei tre test campionati in questo intervallo):
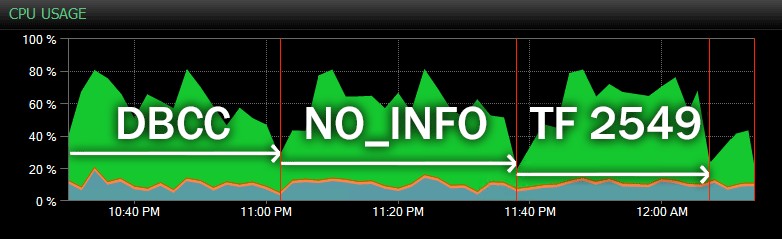
Impatto della CPU durante CHECKDB – modalità storica
Su database ancora più grandi, ospitati su server più occupati, potresti vedere effetti diversi ed è molto probabile che il tuo chilometraggio vari. Quindi per favore esegui la tua due diligence e prova queste opzioni e traccia i flag durante un tipico carico di lavoro simultaneo prima di decidere come vuoi avvicinarti a CHECKDB .
Conclusione
DBCC CHECKDB è una parte molto importante ma spesso sottovalutata della tua responsabilità come DBA o architetto e cruciale per la protezione dei dati della tua azienda. Non prendere alla leggera questa responsabilità e fai del tuo meglio per assicurarti di non sacrificare nulla nell'interesse di ridurre l'impatto sulle istanze di produzione. Ancora più importante:guarda oltre le schede tecniche di marketing per essere sicuro di comprendere appieno quanto siano valide quelle promesse e se sei disposto a scommettere su di esse i dati della tua azienda. Risparmiare su alcuni assegni o scaricarli in posizioni secondarie non valide potrebbe essere un disastro in attesa di verificarsi.
Dovresti anche prendere in considerazione la lettura di questi articoli PSS:
- Un CHECKDB più veloce – Parte I
- Un CHECKDB più veloce – Parte II
- Un CHECKDB più veloce – Parte III
- Un CHECKDB più veloce – Parte IV (UDT CLR SQL)
E questo post di Brent Ozar:
- 3 modi per eseguire DBCC CHECKDB più velocemente
Infine, se hai una domanda irrisolta su DBCC CHECKDB , pubblicalo nell'hashtag #sqlhelp su Twitter. Paul controlla spesso quel tag e, poiché la sua foto dovrebbe apparire nell'articolo principale di Books Online, è probabile che se qualcuno può rispondere, può farlo. Se è troppo complesso per 140 caratteri, puoi chiedere qui (e mi assicurerò che Paul lo veda prima o poi) o postare su un forum come Database Administrators Stack Exchange.