Le chiavi primarie ed esterne sono caratteristiche fondamentali dei database relazionali, come originariamente notato nell'articolo di EF Codd, "A Relational Model of Data for Large Shared Data Banks", pubblicato nel 1970. La citazione spesso ripetuta è:"La chiave, l'intera chiave, e nient'altro che la chiave, quindi aiutami Codd."
Sfondo:chiavi primarie
Una chiave primaria è un vincolo in SQL Server, che agisce per identificare in modo univoco ogni riga in una tabella. La chiave può essere definita come una singola colonna non NULL o una combinazione di colonne non NULL che genera un valore univoco e viene utilizzata per imporre l'integrità dell'entità per una tabella. Una tabella può avere solo una chiave primaria e quando viene definito un vincolo di chiave primaria per una tabella, viene creato un indice univoco. Tale indice sarà un indice cluster per impostazione predefinita, a meno che non venga specificato come indice non cluster quando viene definito il vincolo della chiave primaria.
Considera Sales.SalesOrderHeader tabella nella AdventureWorks2012 Banca dati. Questa tabella contiene le informazioni di base su un ordine cliente, inclusa la data dell'ordine e l'ID cliente, e ogni vendita è identificata in modo univoco da un SalesOrderID , che è la chiave primaria per la tabella. Ogni volta che viene aggiunta una nuova riga alla tabella, il vincolo della chiave primaria (denominato PK_SalesOrderHeader_SalesOrderID ) viene verificato per garantire che non esista già alcuna riga con lo stesso valore per SalesOrderID .
Chiavi estere
Separate dalle chiavi primarie, ma molto correlate, ci sono le chiavi esterne. Una chiave esterna è una colonna o una combinazione di colonne uguale alla chiave primaria, ma in una tabella diversa. Le chiavi esterne vengono utilizzate per definire una relazione e imporre l'integrità tra due tabelle.
Per continuare a utilizzare l'esempio sopra menzionato, il SalesOrderID esiste come chiave esterna in Sales.SalesOrderDetail tabella, in cui sono memorizzate informazioni aggiuntive sulla vendita, come ID prodotto e prezzo. Quando una nuova vendita viene aggiunta a SalesOrderHeader tabella, non è necessario aggiungere una riga per quella vendita a SalesOrderDetail table Tuttavia, quando si aggiunge una riga a SalesOrderDetail tabella, una riga corrispondente per SalesOrderID deve esistono in SalesOrderHeader tabella.
Al contrario, quando si eliminano i dati, una riga per uno specifico SalesOrderID può essere cancellato in qualsiasi momento da SalesOrderDetail tabella, ma per eliminare una riga da SalesOrderHeader tabella, righe associate da SalesOrderDetail dovrà prima essere eliminato.
A differenza dei vincoli di chiave primaria, quando viene definito un vincolo di chiave esterna per una tabella, per impostazione predefinita SQL Server non crea un indice. Tuttavia, non è raro che sviluppatori e amministratori di database li aggiungano manualmente. La chiave esterna può essere parte di una chiave primaria composita per la tabella, nel qual caso esisterebbe un indice cluster con la chiave esterna come parte della chiave di clustering. In alternativa, le query possono richiedere un indice che includa la chiave esterna e una o più colonne aggiuntive nella tabella, in modo che venga creato un indice non cluster per supportare tali query. Inoltre, gli indici sulle chiavi esterne possono fornire vantaggi in termini di prestazioni per i join di tabelle che coinvolgono la chiave primaria ed esterna e possono influire sulle prestazioni quando il valore della chiave primaria viene aggiornato o se la riga viene eliminata.
Nel AdventureWorks2012 database, è presente una tabella, SalesOrderDetail , con SalesOrderID come chiave esterna. Per il SalesOrderDetail tabella, SalesOrderID e SalesOrderDetailID si combinano per formare la chiave primaria, supportata da un indice cluster. Se il SalesOrderDetail la tabella non aveva un indice su SalesOrderID colonna, quindi quando una riga viene eliminata da SalesOrderHeader , SQL Server dovrebbe verificare che nessuna riga per lo stesso SalesOrderID il valore esiste. Senza alcun indice che contenga SalesOrderID colonna, SQL Server dovrebbe eseguire un'analisi completa della tabella di SalesOrderDetail . Come puoi immaginare, più grande è la tabella di riferimento, più tempo impiegherà l'eliminazione.
Un esempio
Possiamo vederlo nell'esempio seguente, che utilizza copie delle suddette tabelle da AdventureWorks2012 database che sono stati ampliati utilizzando uno script che può essere trovato qui. Lo script è stato sviluppato da Jonathan Kehayias (blog | @SQLPoolBoy) e crea un SalesOrderHeaderEnlarged tabella con 1.258.600 righe e un SalesOrderDetailEnlarged tabella con 4.852.680 righe. Dopo l'esecuzione dello script, il vincolo di chiave esterna è stato aggiunto utilizzando le istruzioni seguenti. Nota che il vincolo viene creato con ON DELETE CASCADE opzione. Con questa opzione, quando viene emesso un aggiornamento o un'eliminazione rispetto a SalesOrderHeaderEnlarged tabella, righe nelle tabelle corrispondenti – in questo caso solo SalesOrderDetailEnlarged – vengono aggiornati o eliminati.
Inoltre, l'indice cluster predefinito per SalesOrderDetailEnglarged è stato eliminato e ricreato per avere solo SalesOrderDetailID come chiave primaria, in quanto rappresenta un design tipico.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Con il vincolo della chiave esterna e nessun indice di supporto, è stata emessa una singola eliminazione rispetto a SalesOrderHeaderEnlarged table, che ha comportato la rimozione di una riga da SalesOrderHeaderEnlarged e 72 righe da SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Le statistiche IO e le informazioni sui tempi hanno mostrato quanto segue:
SQL Server analizza e compila tempo:Tempo CPU =8 ms, tempo trascorso =8 ms.
Tabella 'SalesOrderDetailEnlarged'. Conteggio scansioni 1, letture logiche 50647, letture fisiche 8, letture read-ahead 50667, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Worktable'. Conteggio scansioni 2, letture logiche 7, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'SalesOrderHeaderEnlarged'. Conteggio scansioni 0, letture logiche 15, letture fisiche 14, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tempi di esecuzione di SQL Server:
Tempo CPU =1045 ms, tempo trascorso =1898 ms.
Utilizzando SQL Sentry Plan Explorer, il piano di esecuzione mostra una scansione dell'indice cluster rispetto a SalesOrderDetailEnlarged poiché non esiste un indice su SalesOrderID :
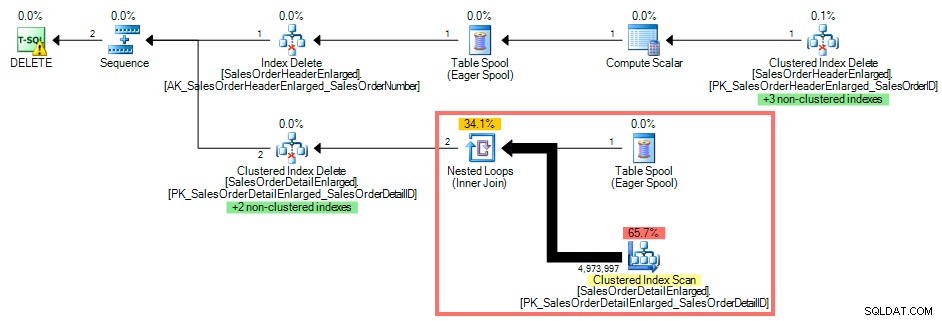
Piano di query senza indice sulla chiave esterna
L'indice non cluster per supportare SalesOrderDetailEnlarged è stato quindi creato utilizzando la seguente istruzione:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
È stata eseguita un'altra eliminazione per un SalesOrderID che ha interessato una riga in SalesOrderHeaderEnlarged e 72 righe in SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Le statistiche IO e le informazioni sui tempi hanno mostrato un notevole miglioramento:
SQL Server analizza e compila tempo:Tempo CPU =0 ms, tempo trascorso =7 ms.
Tabella 'SalesOrderDetailEnlarged'. Conteggio scansioni 1, letture logiche 48, letture fisiche 13, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Worktable'. Conteggio scansioni 2, letture logiche 7, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'SalesOrderHeaderEnlarged'. Conteggio scansioni 0, letture logiche 15, letture fisiche 15, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tempi di esecuzione di SQL Server:
Tempo CPU =0 ms, tempo trascorso =27 ms.
E il piano di query mostrava una ricerca dell'indice dell'indice non cluster su SalesOrderID , come previsto:
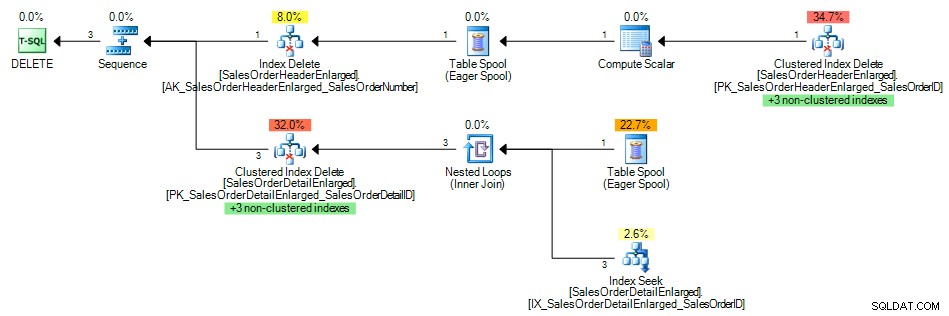
Piano di query con indice sulla chiave esterna
Il tempo di esecuzione della query è sceso da 1898 ms a 27 ms, una riduzione del 98,58% e legge per SalesOrderDetailEnlarged la tabella è diminuita da 50647 a 48, con un miglioramento del 99,9%. Percentuali a parte, considera l'I/O da solo generato dall'eliminazione. Il SalesOrderDetailEnlarged table è solo 500 MB in questo esempio, e per un sistema con 256 GB di memoria disponibile, una tabella che occupa 500 MB nella cache del buffer non sembra una situazione terribile. Ma una tabella di 5 milioni di righe è relativamente piccola; la maggior parte dei grandi sistemi OLTP ha tabelle con centinaia di milioni di righe. Inoltre, non è raro che esistano più riferimenti a chiavi esterne per una chiave primaria, in cui l'eliminazione della chiave primaria richiede l'eliminazione da più tabelle correlate. In tal caso, è possibile visualizzare durate estese per le eliminazioni che non è solo un problema di prestazioni, ma anche un problema di blocco, a seconda del livello di isolamento.
Conclusione
In genere si consiglia di creare un indice che conduca alle colonne della chiave esterna, per supportare non solo i join tra le chiavi primarie ed esterne, ma anche gli aggiornamenti e le eliminazioni. Si noti che questa è una raccomandazione generale, poiché esistono scenari di casi limite in cui l'indice aggiuntivo sulla chiave esterna non è stato utilizzato a causa delle dimensioni estremamente ridotte della tabella e gli aggiornamenti dell'indice aggiuntivi hanno effettivamente influito negativamente sulle prestazioni. Come per qualsiasi modifica dello schema, le aggiunte all'indice devono essere verificate e monitorate dopo l'implementazione. È importante garantire che gli indici aggiuntivi producano gli effetti desiderati e non influiscano negativamente sulle prestazioni della soluzione. Vale anche la pena notare quanto spazio aggiuntivo è richiesto dagli indici per le chiavi esterne. Questo è essenziale da considerare prima di creare gli indici e, se forniscono un vantaggio, deve essere preso in considerazione per la pianificazione della capacità in futuro.