Il concetto di design buono o cattivo è relativo. Allo stesso tempo, ci sono alcuni standard di programmazione, che nella maggior parte dei casi garantiscono efficacia, manutenibilità e testabilità. Ad esempio, nei linguaggi orientati agli oggetti, questo è l'uso dell'incapsulamento, dell'ereditarietà e del polimorfismo. Esiste una serie di modelli di progettazione che in diversi casi hanno un effetto positivo o negativo sulla progettazione dell'applicazione a seconda della situazione. D'altra parte, ci sono degli opposti, a seguito dei quali a volte porta alla progettazione del problema.
Questo design di solito ha i seguenti indicatori (uno o più alla volta):
- Rigidità (è difficile modificare il codice, poiché una semplice modifica interessa molti punti);
- Immobility (è complicato dividere il codice in moduli che possono essere utilizzati in altri programmi);
- Viscosità (è abbastanza difficile sviluppare o testare il codice);
- Complessità inutile (c'è una funzionalità inutilizzata nel codice);
- Ripetizione inutile (Copia/Incolla);
- Scarsa leggibilità (è difficile capire a cosa serve il codice e mantenerlo);
- Fragilità (è facile interrompere la funzionalità anche con piccole modifiche).
È necessario essere in grado di comprendere e distinguere queste caratteristiche per evitare la progettazione di un problema o per prevedere le possibili conseguenze del suo utilizzo. Questi indicatori sono descritti nel libro «Agile Principles, Patterns, And Practices in C#» di Robert Martin. Tuttavia, in questo articolo e in altri articoli di recensione è presente una breve descrizione e nessun esempio di codice.
Elimineremo questo inconveniente soffermandoci su ciascuna caratteristica.
Rigidità
Come è stato accennato, un codice rigido è difficile da modificare, anche le più piccole cose. Questo potrebbe non essere un problema se il codice non viene modificato spesso o del tutto. Pertanto, il codice risulta essere abbastanza buono. Tuttavia, se è necessario modificare il codice ed è difficile farlo, diventa un problema, anche se funziona.
Uno dei casi di rigidità più diffusi consiste nello specificare esplicitamente i tipi di classe invece di utilizzare astrazioni (interfacce, classi base, ecc.). Di seguito, puoi trovare un esempio del codice:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Qui la classe A dipende molto dalla classe B. Quindi, se in futuro è necessario utilizzare un'altra classe anziché la classe B, ciò richiederà la modifica della classe A e porterà a un nuovo test. Inoltre, se la classe B interessa altre classi, la situazione diventerà molto complicata.
La soluzione alternativa è un'astrazione che consiste nell'introdurre l'interfaccia IComponent tramite il costruttore della classe A. In questo caso, non dipenderà più dalla particolare classe  e dipenderà solo dall'interfaccia IComponent. La classe В a sua volta deve implementare l'interfaccia IComponent.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Forniamo un esempio specifico. Si supponga che esista un insieme di classi che registrano le informazioni:ProductManager e Consumer. Il loro compito è archiviare un prodotto nel database e ordinarlo di conseguenza. Entrambe le classi registrano eventi rilevanti. Immagina che all'inizio ci fosse un registro in un file. Per fare ciò, è stata utilizzata la classe FileLogger. Inoltre, le classi erano dislocate in diversi moduli (assiemi).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Se all'inizio bastava utilizzare solo il file, e poi diventa necessario accedere ad altri repository, come un database o un servizio di raccolta e archiviazione dati basato su cloud, allora dovremo modificare tutte le classi nella logica aziendale modulo (Modulo 2) che utilizza FileLogger. Dopotutto, questo può rivelarsi difficile. Per risolvere questo problema, possiamo introdurre un'interfaccia astratta per lavorare con il logger, come mostrato di seguito.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} In questo caso, quando si cambia un tipo di logger, è sufficiente modificare il codice client (Main), che inizializza il logger e lo aggiunge al costruttore di ProductManager e Consumer. Pertanto, abbiamo chiuso le classi di business logic dalla modifica del tipo di logger come richiesto.
Oltre ai collegamenti diretti alle classi utilizzate, possiamo monitorare la rigidità in altre varianti che possono comportare difficoltà durante la modifica del codice. Ci può essere un insieme infinito di loro. Tuttavia, cercheremo di fornire un altro esempio. Supponiamo che ci sia un codice che mostra l'area di un motivo geometrico sulla console.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Come puoi vedere, quando aggiungi un nuovo pattern, dovremo cambiare i metodi della classe ShapeHelper. Una delle opzioni è quella di passare l'algoritmo di rendering nelle classi di motivi geometrici (Rettangolo e Cerchio), come mostrato di seguito. In questo modo isoleremo la logica pertinente nelle classi corrispondenti riducendo così la responsabilità della classe ShapeHelper prima di visualizzare le informazioni sulla console.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} Di conseguenza, abbiamo effettivamente chiuso la classe ShapeHelper per le modifiche che aggiungono nuovi tipi di modelli utilizzando l'ereditarietà e il polimorfismo.
Immobilità
Possiamo monitorare l'immobilità quando dividiamo il codice in moduli riutilizzabili. Di conseguenza, il progetto potrebbe smettere di svilupparsi ed essere competitivo.
A titolo di esempio, prenderemo in considerazione un programma desktop, il cui codice intero è implementato nel file dell'applicazione eseguibile (.exe) ed è stato progettato in modo che la logica di business non sia costruita in moduli o classi separate. Successivamente, lo sviluppatore ha affrontato i seguenti requisiti aziendali:
- Per modificare l'interfaccia utente trasformandola in un'applicazione Web;
- Pubblicare la funzionalità del programma come un insieme di servizi Web disponibili per client di terze parti da utilizzare nelle proprie applicazioni.
In questo caso, questi requisiti sono difficili da soddisfare, poiché l'intero codice si trova nel modulo eseguibile.
L'immagine sotto mostra un esempio di un design immobile in contrasto con quello che non ha questo indicatore. Sono separati da una linea punteggiata. Come si può notare, l'allocazione del codice sui moduli riutilizzabili (Logic), così come la pubblicazione della funzionalità a livello di Web services, ne consentono l'utilizzo in diverse applicazioni client (App), il che è un indubbio vantaggio.
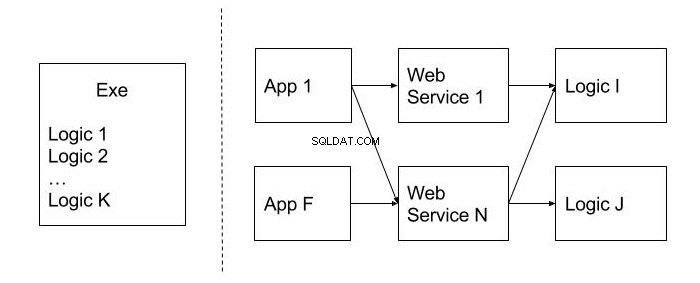
L'immobilità può anche essere definita un design monolitico. È difficile dividerlo in unità più piccole e utili del codice. Come possiamo eludere questo problema? In fase di progettazione, è meglio pensare alla probabilità di utilizzare questa o quella funzionalità in altri sistemi. È meglio collocare il codice che dovrebbe essere riutilizzato in moduli e classi separati.
Viscosità
Ne esistono di due tipi:
- Viscosità di sviluppo
- Viscosità ambientale
Possiamo vedere la viscosità di sviluppo mentre proviamo a seguire il design dell'applicazione selezionato. Ciò può accadere quando un programmatore deve soddisfare troppi requisiti mentre esiste un modo più semplice per lo sviluppo. Inoltre, la viscosità di sviluppo può essere vista quando il processo di assemblaggio, distribuzione e test non è efficace.
Come semplice esempio, possiamo considerare il lavoro con le costanti che devono essere collocate (By Design) in un modulo separato (Modulo 1) per essere utilizzato da altri componenti (Modulo 2 e Modulo 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Se per qualsiasi motivo il processo di assemblaggio richiede molto tempo, sarà difficile per gli sviluppatori attendere fino al termine. Inoltre, va notato che il modulo costante contiene entità miste che appartengono a diverse parti della logica aziendale (moduli finanziari e di marketing). Pertanto, il modulo costante può essere modificato abbastanza spesso per motivi indipendenti l'uno dall'altro, il che può portare a problemi aggiuntivi come la sincronizzazione delle modifiche.
Tutto ciò rallenta il processo di sviluppo e può stressare i programmatori. Le varianti del design meno viscoso consisterebbero nel creare moduli di costanti separati - di uno per il modulo corrispondente di logica aziendale - o nel passare le costanti nel posto giusto senza prendere un modulo separato per loro.
Un esempio della viscosità dell'ambiente può essere lo sviluppo e il test dell'applicazione sulla macchina virtuale client remota. A volte questo flusso di lavoro diventa insopportabile a causa di una connessione Internet lenta, quindi lo sviluppatore può ignorare sistematicamente il test di integrazione del codice scritto, che può eventualmente portare a bug sul lato client quando si utilizza questa funzionalità.
Complessità inutile
In questo caso, il design ha funzionalità effettivamente inutilizzate. Questo fatto può complicare il supporto e la manutenzione del programma, oltre ad aumentare i tempi di sviluppo e test. Si consideri ad esempio il programma che richiede la lettura di alcuni dati dal database. Per fare ciò è stato creato il componente DataManager, che viene utilizzato in un altro componente.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Se lo sviluppatore aggiunge un nuovo metodo a DataManager per scrivere i dati nel database (WriteData), che difficilmente verrà utilizzato in futuro, sarà anche una complessità inutile.
Un altro esempio è un'interfaccia per tutti gli scopi. Consideriamo ad esempio un'interfaccia con il metodo Process single che accetta un oggetto di tipo stringa.
interface IProcessor
{
void Process(string message);
} Se l'attività consistesse nell'elaborare un certo tipo di messaggio con una struttura ben definita, sarebbe più facile creare un'interfaccia rigorosamente tipizzata, piuttosto che far deserializzare agli sviluppatori questa stringa ogni volta in un particolare tipo di messaggio.
L'uso eccessivo dei modelli di progettazione nei casi in cui ciò non è affatto necessario può portare anche alla progettazione della viscosità.
Perché perdere tempo a scrivere un codice potenzialmente inutilizzato? A volte, il QA deve testare questo codice, perché è effettivamente pubblicato ed è aperto per l'uso da parte di client di terze parti. Questo rimanda anche il tempo di rilascio. Includere una funzionalità per il futuro vale solo se il suo possibile vantaggio supera i costi per il suo sviluppo e test.
Ripetizione inutile
Forse, la maggior parte degli sviluppatori ha affrontato o si imbatterà in questa funzionalità, che consiste nel copiare più volte la stessa logica o il codice. La minaccia principale è la vulnerabilità di questo codice durante la modifica:riparando qualcosa in un punto, potresti dimenticarti di farlo in un altro. Inoltre, ci vuole più tempo per apportare modifiche rispetto alla situazione in cui il codice non contiene questa funzionalità.
La ripetizione inutile può essere dovuta alla negligenza degli sviluppatori, oltre che alla rigidità/fragilità del design quando è molto più difficile e rischioso non ripetere il codice piuttosto che farlo. Tuttavia, in ogni caso, la ripetibilità non è una buona idea, ed è necessario migliorare costantemente il codice, passando parti riutilizzabili a metodi e classi comuni.
Leggibilità scarsa
Puoi monitorare questa funzionalità quando è difficile leggere un codice e capire per cosa è stato creato. I motivi della scarsa leggibilità possono essere la non conformità con i requisiti per l'esecuzione del codice (sintassi, variabili, classi), una logica di implementazione complicata, ecc.
Di seguito puoi trovare l'esempio del codice di difficile lettura, che implementa il metodo con la variabile booleana.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Qui possiamo delineare diversi problemi. In primo luogo, i nomi dei metodi e delle variabili non sono conformi alle convenzioni generalmente accettate. In secondo luogo, l'implementazione del metodo non è delle migliori.
Forse vale la pena prendere un valore booleano, piuttosto che una stringa. Tuttavia, è meglio convertirlo in un valore booleano all'inizio del metodo, piuttosto che utilizzare il metodo per determinare la lunghezza della stringa.
In terzo luogo, il testo dell'eccezione non corrisponde allo stile ufficiale. Leggendo tali testi, si può avere la sensazione che il codice sia stato creato da un dilettante (tuttavia, potrebbe esserci un punto in discussione). Il metodo potrebbe essere riscritto come segue se assume un valore booleano:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Ecco un altro esempio di refactoring se devi ancora prendere una stringa:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Si consiglia di eseguire il refactoring con il codice di difficile lettura, ad esempio, quando la sua manutenzione e clonazione portano a più bug.
Fragilità
La fragilità di un programma significa che può essere facilmente bloccato durante la modifica. Esistono due tipi di arresti anomali:errori di compilazione ed errori di runtime. I primi possono essere un lato posteriore della rigidità. Questi ultimi sono i più pericolosi in quanto si verificano sul lato client. Quindi, sono un indicatore della fragilità.
Senza dubbio, l'indicatore è relativo. Qualcuno corregge il codice con molta attenzione e la possibilità che si verifichi un arresto anomalo è piuttosto bassa, mentre altri lo fanno in fretta e con noncuranza. Tuttavia, un codice diverso con gli stessi utenti può causare una quantità diversa di errori. Probabilmente possiamo dire che più è difficile capire il codice e fare affidamento sui tempi di esecuzione del programma, piuttosto che sulla fase di compilazione, più fragile è il codice.
Inoltre, la funzionalità che non verrà modificata spesso si arresta in modo anomalo. Può risentire dell'elevato accoppiamento della logica dei diversi componenti.
Considera l'esempio particolare. Qui la logica dell'autorizzazione dell'utente con un determinato ruolo (definito come parametro rolled) per accedere a una particolare risorsa (definita come ResourceUri) si trova nel metodo statico.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Come puoi vedere, la logica è complicata. È ovvio che l'aggiunta di nuovi ruoli e risorse lo romperà facilmente. Di conseguenza, un determinato ruolo potrebbe ottenere o perdere l'accesso a una risorsa. La creazione della classe Resource che memorizza internamente l'identificatore della risorsa e l'elenco dei ruoli supportati, come mostrato di seguito, ridurrebbe la fragilità.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} In questo caso, per aggiungere nuove risorse e ruoli, non è necessario modificare affatto il codice della logica di autorizzazione, cioè in realtà non c'è nulla da violare.
Cosa può aiutare a rilevare gli errori di runtime? La risposta è test manuale, automatico e unitario. Migliore è l'organizzazione del processo di test, più è probabile che il codice fragile si verifichi sul lato client.
Spesso, la fragilità è il retro di altri identificatori di cattiva progettazione come rigidità, scarsa leggibilità e ripetizioni inutili.
Conclusione
Abbiamo cercato di delineare e descrivere i principali identificatori di cattivo design. Alcuni di loro sono interdipendenti. Devi capire che la questione del design non porta sempre inevitabilmente a delle difficoltà. Indica solo che possono verificarsi. Minore è il monitoraggio di questi identificatori, minore è questa probabilità.