La crescente domanda di sistemi ad alta disponibilità e SLA rigorosi ci spinge a sostituire le procedure manuali con soluzioni automatizzate. Ma hai il tempo e le risorse necessarie per affrontare da solo la complessità delle operazioni di failover? Sacrificherai i tempi di inattività del database di produzione per impararlo nel modo più difficile?
ClusterControl fornisce un supporto avanzato per il rilevamento e la gestione degli errori. Viene utilizzato da molte organizzazioni aziendali, mantenendo attivi e operativi i sistemi di produzione più critici in modalità 24 ore su 24, 7 giorni su 7.
Questa soluzione di gestione del database ti supporta anche con la distribuzione di diversi proxy di carico. Questi proxy svolgono un ruolo chiave nello stack HA, quindi non è necessario modificare la stringa di connessione dell'applicazione o la voce DNS per reindirizzare le connessioni dell'applicazione al nuovo nodo master.
Quando viene rilevato un errore, ClusterControl esegue tutto il lavoro in background per eleggere un nuovo master, distribuire server slave di failover e configurare i servizi di bilanciamento del carico. In questo blog imparerai come ottenere il failover automatico di TimescaleDB nei tuoi sistemi di produzione.
Distribuzione di intere topologie di replica
A partire da ClusterControl 1.7.2 è possibile distribuire un'intera configurazione di replica TimescaleDB nello stesso modo in cui si distribuisce PostgreSQL:è possibile utilizzare il menu "Deploy Cluster" per distribuire un server primario e uno o più TimescaleDB standby. Vediamo come appare.
Innanzitutto, è necessario definire i dettagli di accesso durante la distribuzione di nuovi cluster utilizzando ClusterControl. Richiede l'accesso con password root o sudo a tutti i nodi su cui verrà distribuito il tuo nuovo cluster.
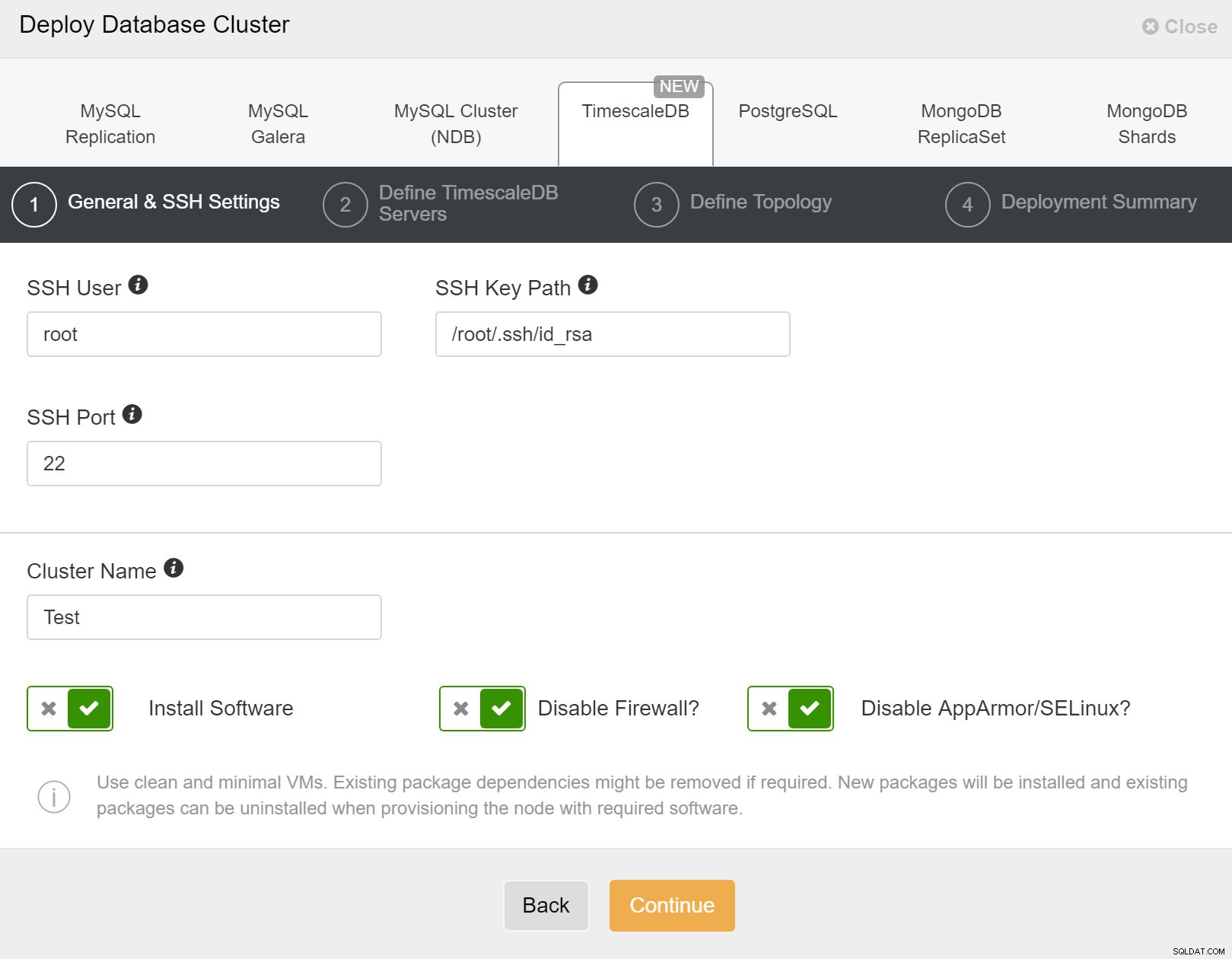 ClusterControl:distribuire un nuovo cluster
ClusterControl:distribuire un nuovo cluster Successivamente, dobbiamo definire l'utente e la password per l'utente TimescaleDB.
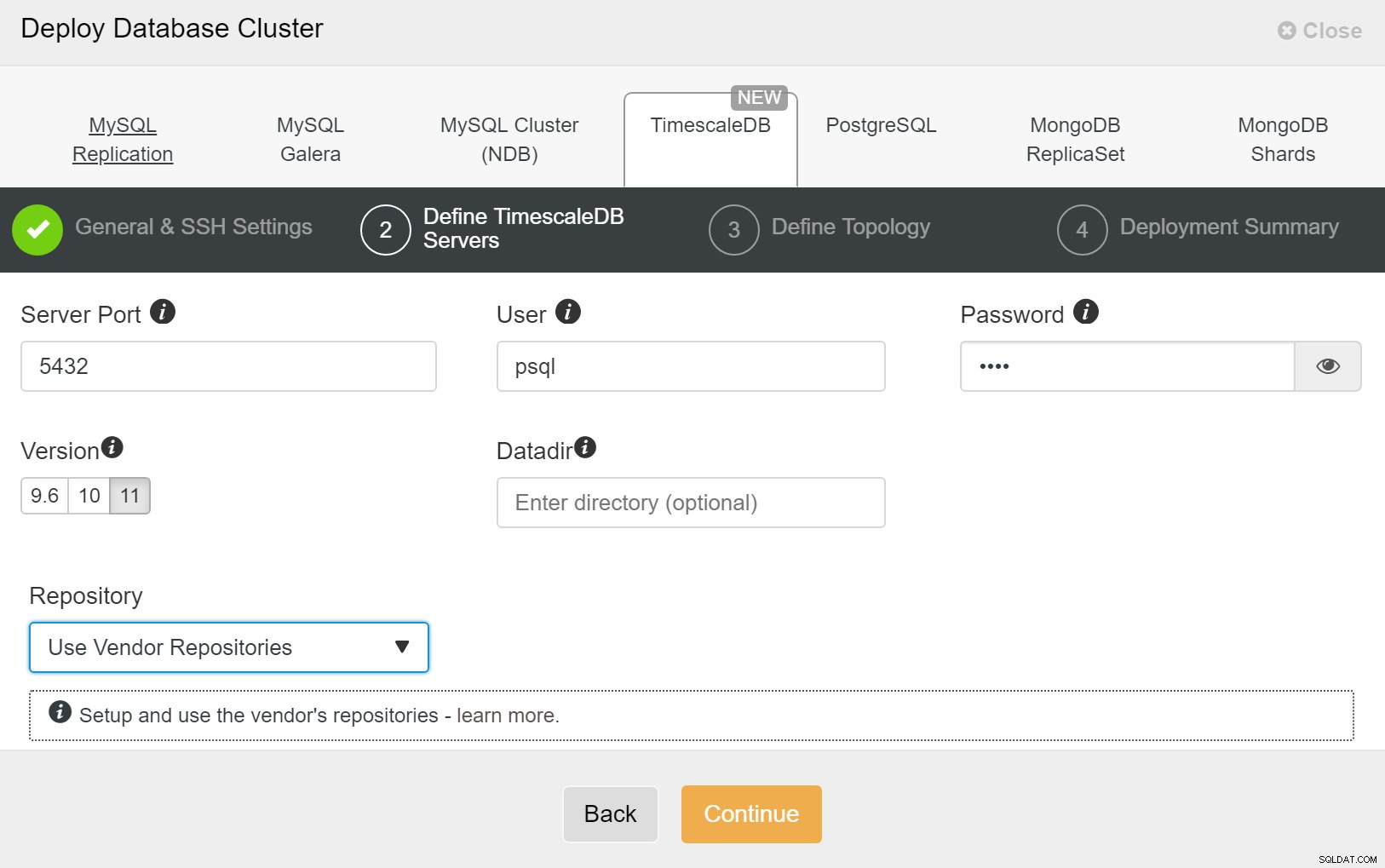 ClusterControl:distribuzione del cluster di database
ClusterControl:distribuzione del cluster di database Infine, si desidera definire la topologia:quale host dovrebbe essere il principale e quali host dovrebbero essere configurati come standby. Mentre definisci gli host nella topologia, ClusterControl verificherà se l'accesso ssh funziona come previsto, consentendoti di rilevare tempestivamente eventuali problemi di connettività. Nell'ultima schermata, ti verrà chiesto il tipo di replica sincrona o asincrona.
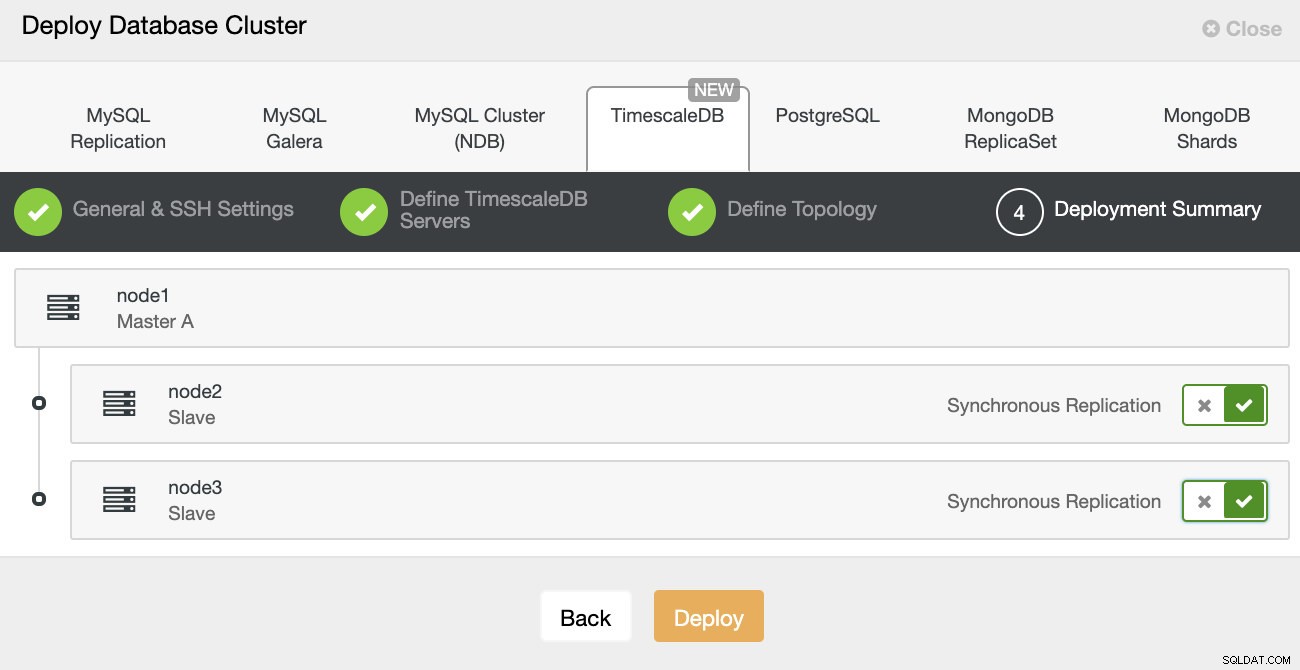 Distribuzione ClusterControl
Distribuzione ClusterControl Ecco fatto, si tratta quindi di avviare la distribuzione. Viene creato un lavoro in ClusterControl e sarai in grado di seguirne l'avanzamento.
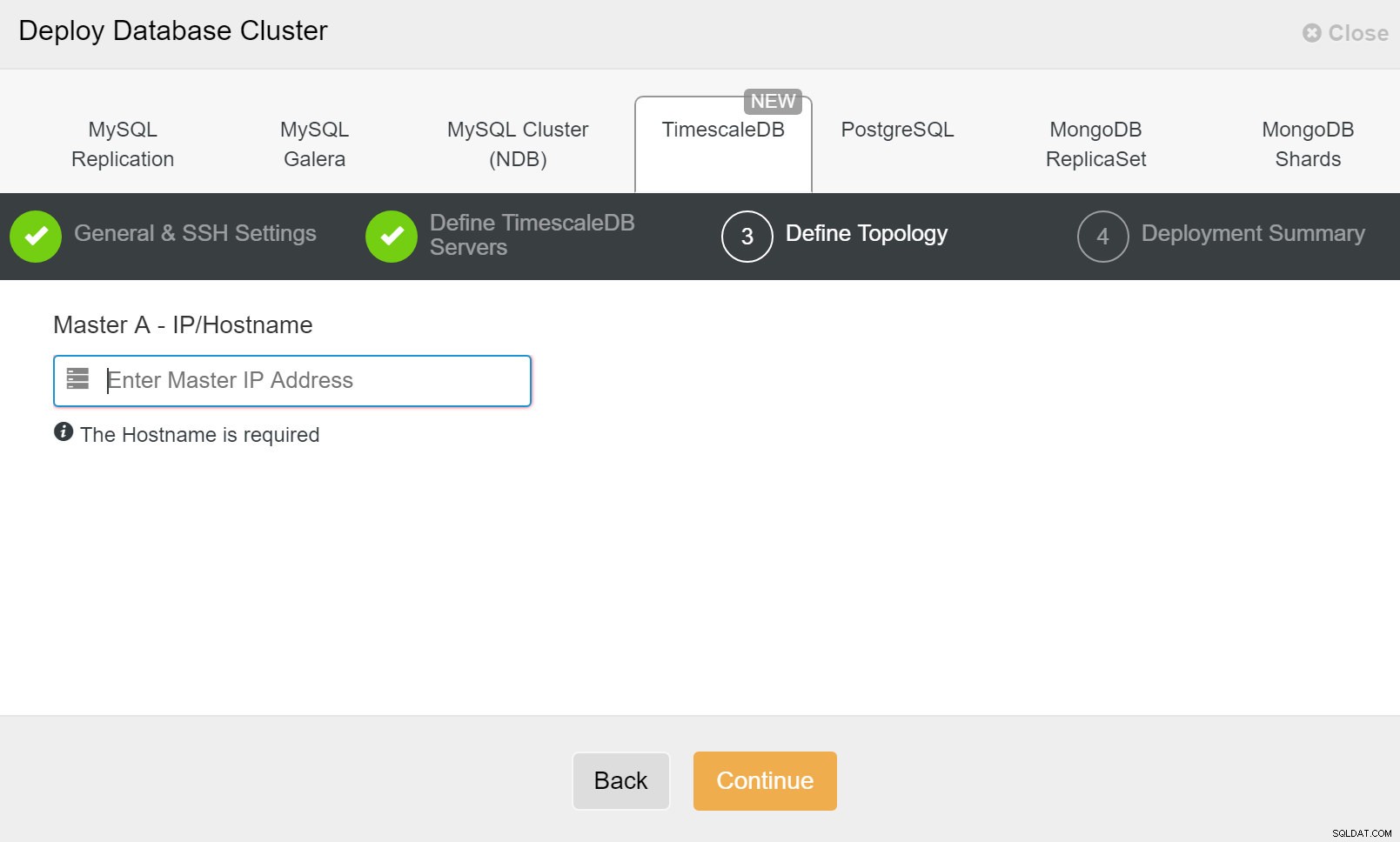 ClusterControl:definizione della topologia per il cluster TimescleDb
ClusterControl:definizione della topologia per il cluster TimescleDb Al termine, vedrai la configurazione della topologia con i ruoli nel cluster. Tieni presente che abbiamo anche aggiunto un sistema di bilanciamento del carico (HAProxy) davanti alle istanze del database in modo che il failover automatico non richieda modifiche alle impostazioni di connessione al database.
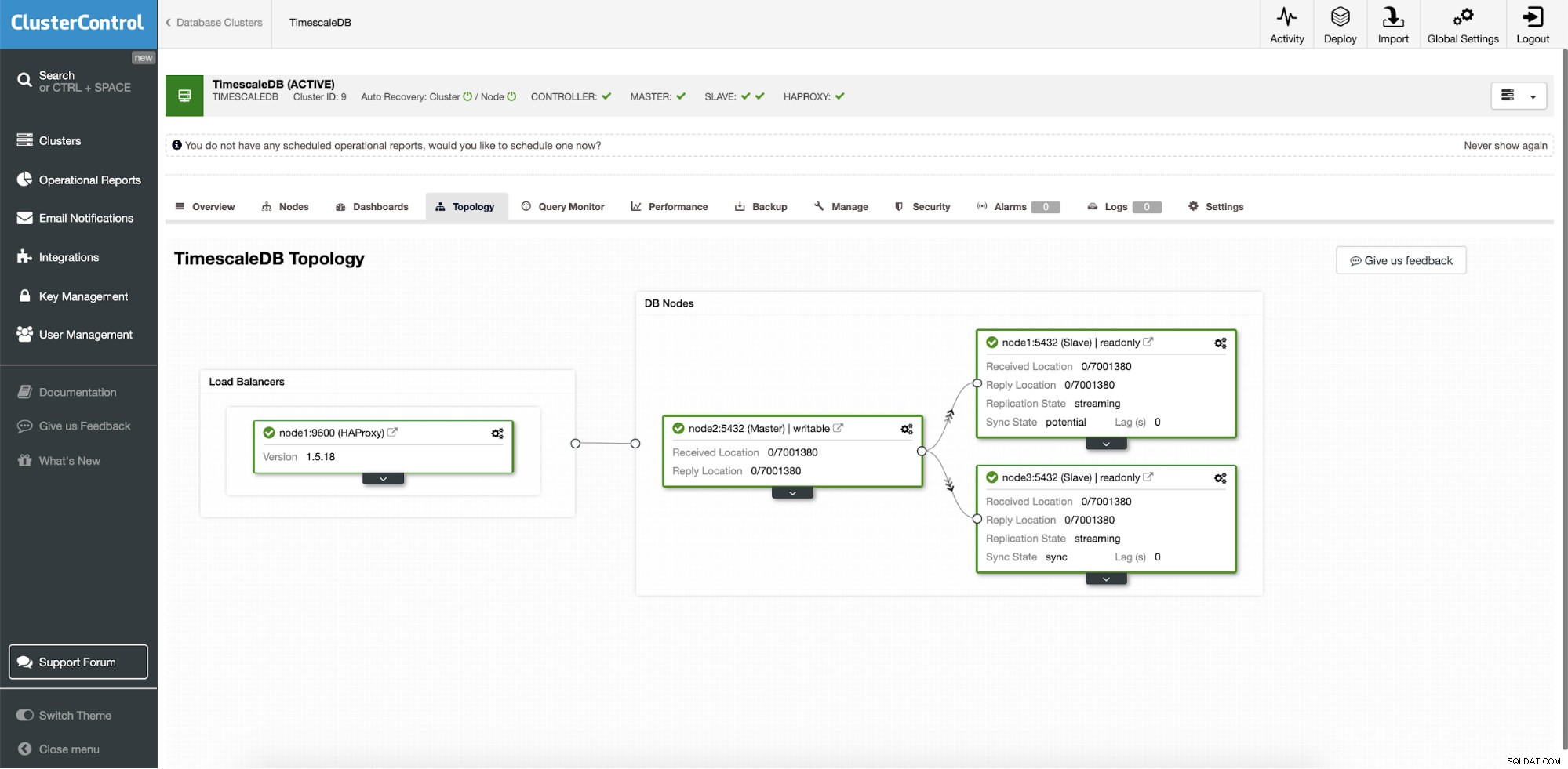 ClusterControl:Topologia
ClusterControl:Topologia Quando Timescale viene distribuito da ClusterControl, il ripristino automatico è abilitato per impostazione predefinita. Lo stato può essere verificato nella barra del cluster.
 ClusterControl:Cluster di ripristino automatico e stato del nodo
ClusterControl:Cluster di ripristino automatico e stato del nodo Configurazione failover
Una volta distribuita la configurazione della replica, ClusterControl è in grado di monitorare la configurazione e ripristinare automaticamente eventuali server guasti. Può anche orchestrare modifiche alla topologia.
Il failover automatico di ClusterControl è stato progettato con i seguenti principi:
- Assicurati che il master sia davvero morto prima di eseguire il failover
- Failover solo una volta
- Non eseguire il failover su uno slave incoerente
- Scrivi solo al maestro
- Non recuperare automaticamente il master guasto
Con gli algoritmi integrati, il failover può spesso essere eseguito abbastanza rapidamente in modo da poter garantire gli SLA più elevati per il tuo ambiente di database.
Il processo è configurabile. Viene fornito con più parametri che puoi utilizzare per adottare il ripristino in base alle specifiche del tuo ambiente.
| max_replication_lag | Massimo ritardo di replica consentito in secondi prima di |
| replication_stop_on_error | Le procedure di failover/switchover non riusciranno se si verificano errori che possono causare la perdita di dati. Abilitato per impostazione predefinita. 0 significa disabilita, |
| replica_auto_rebuild_slave | Se SQL THREAD viene interrotto e il codice di errore è diverso da zero, lo slave verrà ricostruito automaticamente. 1 significa abilitato, 0 significa disabilita (predefinito). |
| replication_failover_blacklist | Elenco separato da virgole di hostname:coppie di porte. I server inseriti nella lista nera non saranno considerati candidati durante il failover. replication_failover_blacklist viene ignorato se è impostata replication_failover_whitelist. |
| replication_failover_whitelist | Elenco separato da virgole di hostname:coppie di porte. Solo i server autorizzati verranno considerati candidati durante il failover. Se nessun server nella whitelist è disponibile (attivo/connesso), il failover avrà esito negativo. replication_failover_blacklist viene ignorato se è impostata replication_failover_whitelist. |
Gestione failover
Quando viene rilevato un errore master, viene creato un elenco di candidati master e uno di essi viene scelto come nuovo master. È possibile avere una whitelist di server da promuovere a primari, nonché una blacklist di server che non possono essere promossi a primari. Gli slave rimanenti ora vengono rimossi dal nuovo primario e il vecchio primario non viene riavviato.
Di seguito possiamo vedere una simulazione di guasto del nodo.
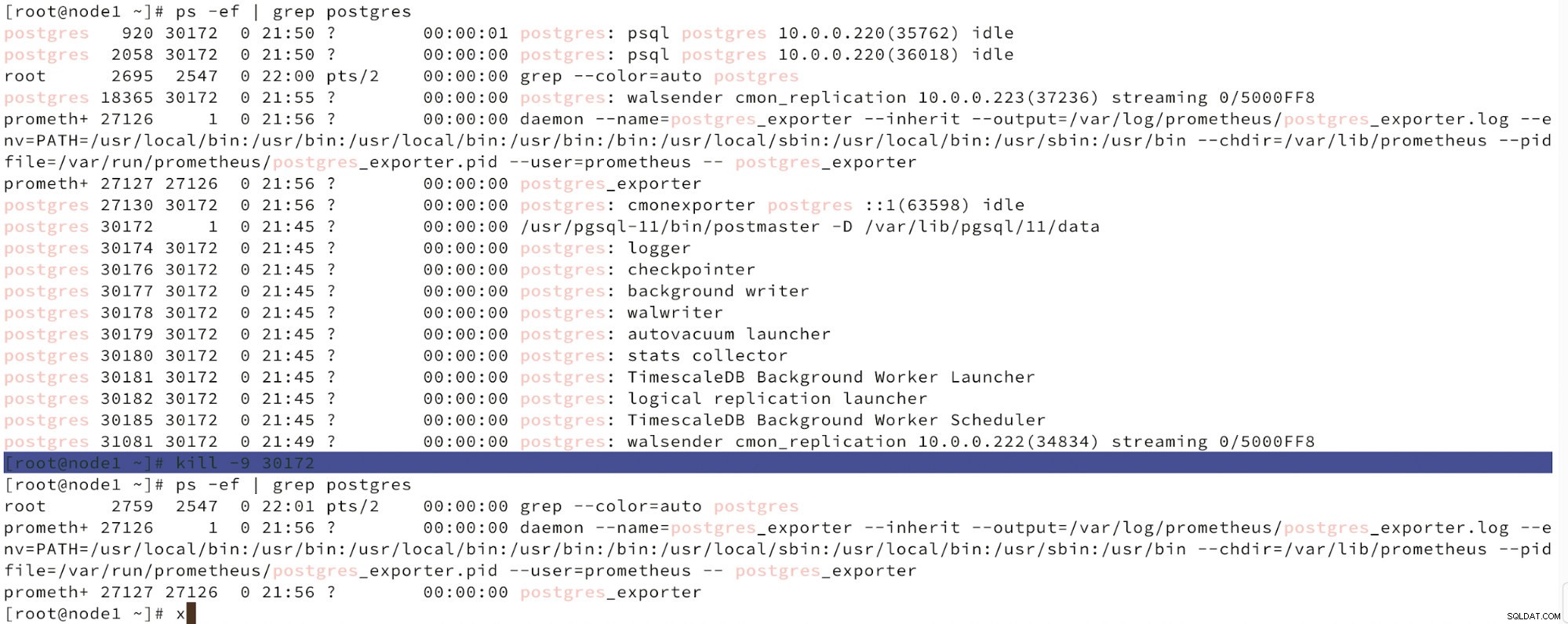 Simula l'errore del nodo master con kill
Simula l'errore del nodo master con kill Quando viene rilevato un malfunzionamento dei nodi e viene rilevato il ripristino automatico, ClusterControl attiva il processo per eseguire il failover. Di seguito possiamo vedere le azioni intraprese per ripristinare il cluster.
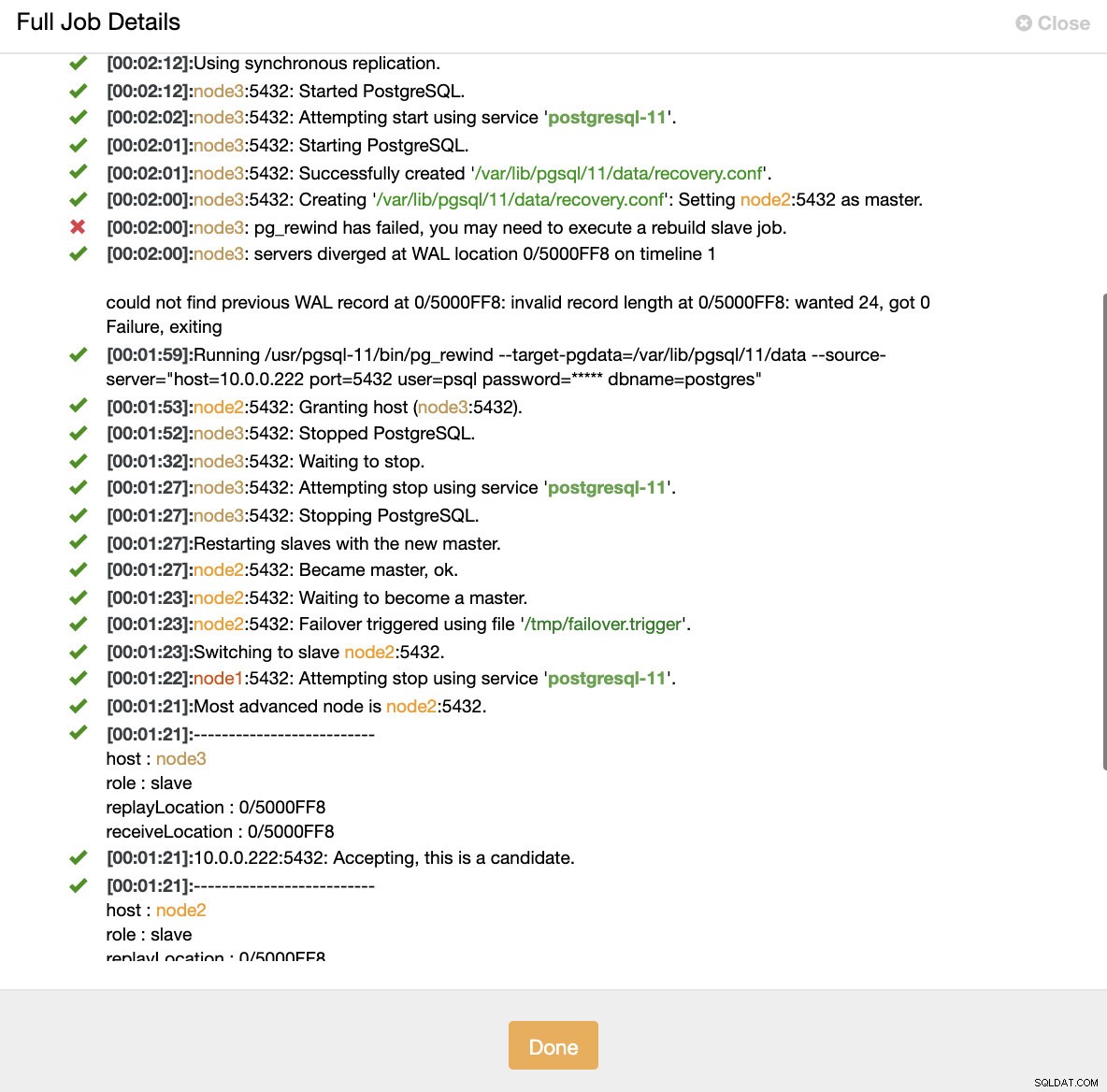 ClusterControl:processo attivato per ricostruire il cluster
ClusterControl:processo attivato per ricostruire il cluster ClusterControl mantiene intenzionalmente offline il vecchio primario perché può accadere che alcuni dati non siano stati trasferiti ai server di standby. In tal caso, l'host primario è l'unico host che contiene questi dati e potresti voler recuperare i dati mancanti manualmente. Per coloro che desiderano ricostruire automaticamente la primaria non riuscita, è disponibile un'opzione nel file di configurazione cmon:replication_auto_rebuild_slave. Per impostazione predefinita, è disabilitato ma quando l'utente lo abilita, il primario guasto verrà ricostruito come slave del nuovo primario. Ovviamente, se ci sono dati mancanti che esistono solo sul primario guasto, quei dati andranno persi.
Ricostruire i server in standby
Una caratteristica diversa è il lavoro "Rebuild Replication Slave" che è disponibile per tutti gli slave (o server in standby) nell'impostazione della replica. Questo deve essere utilizzato, ad esempio, quando si desidera cancellare i dati in standby e ricostruirli di nuovo con una nuova copia dei dati del primario. Può essere utile se un server di standby non è in grado di connettersi e replicarsi dal primario per qualche motivo.
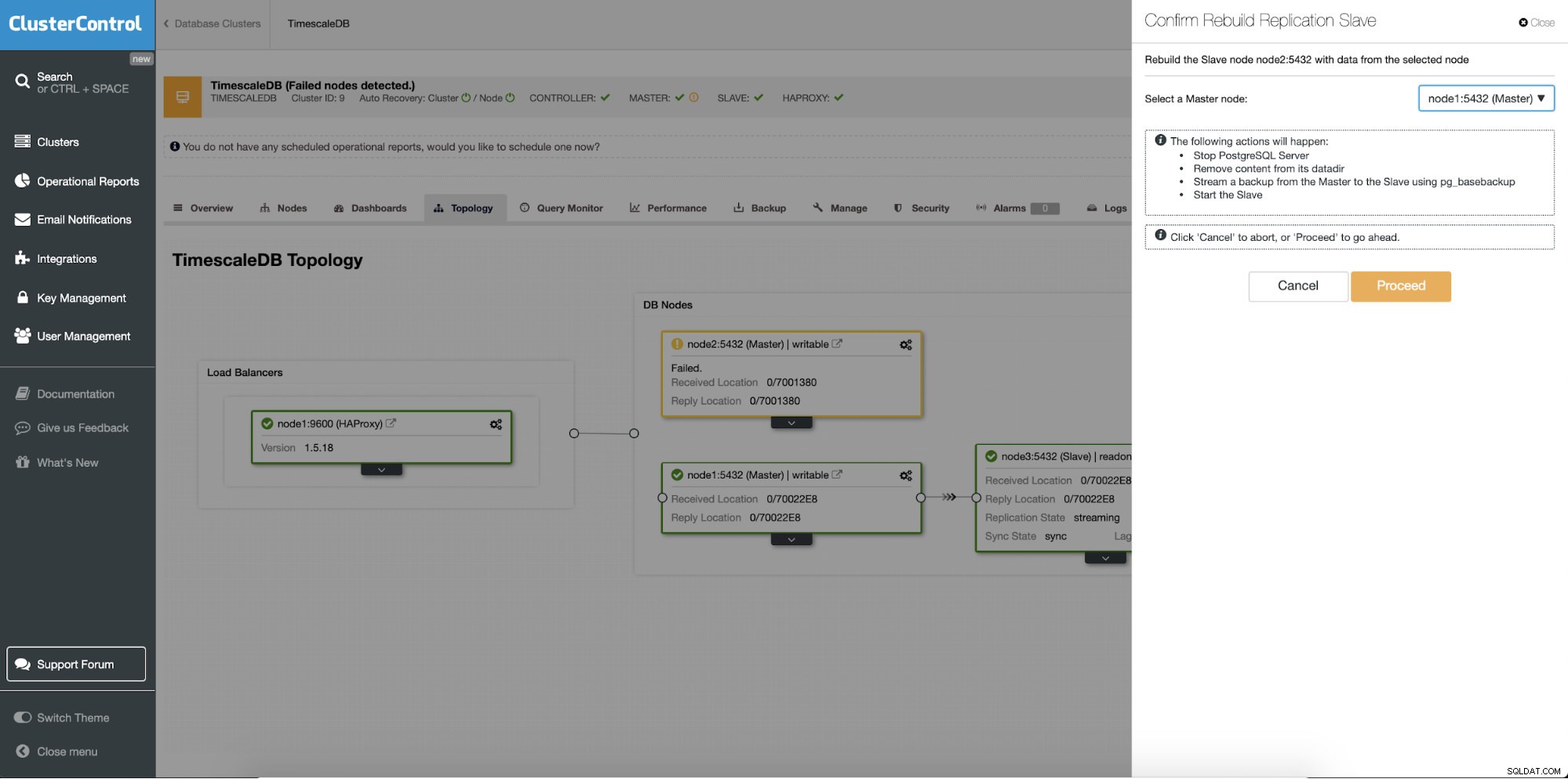 ClusterControl:Ricostruisci replica slave
ClusterControl:Ricostruisci replica slave 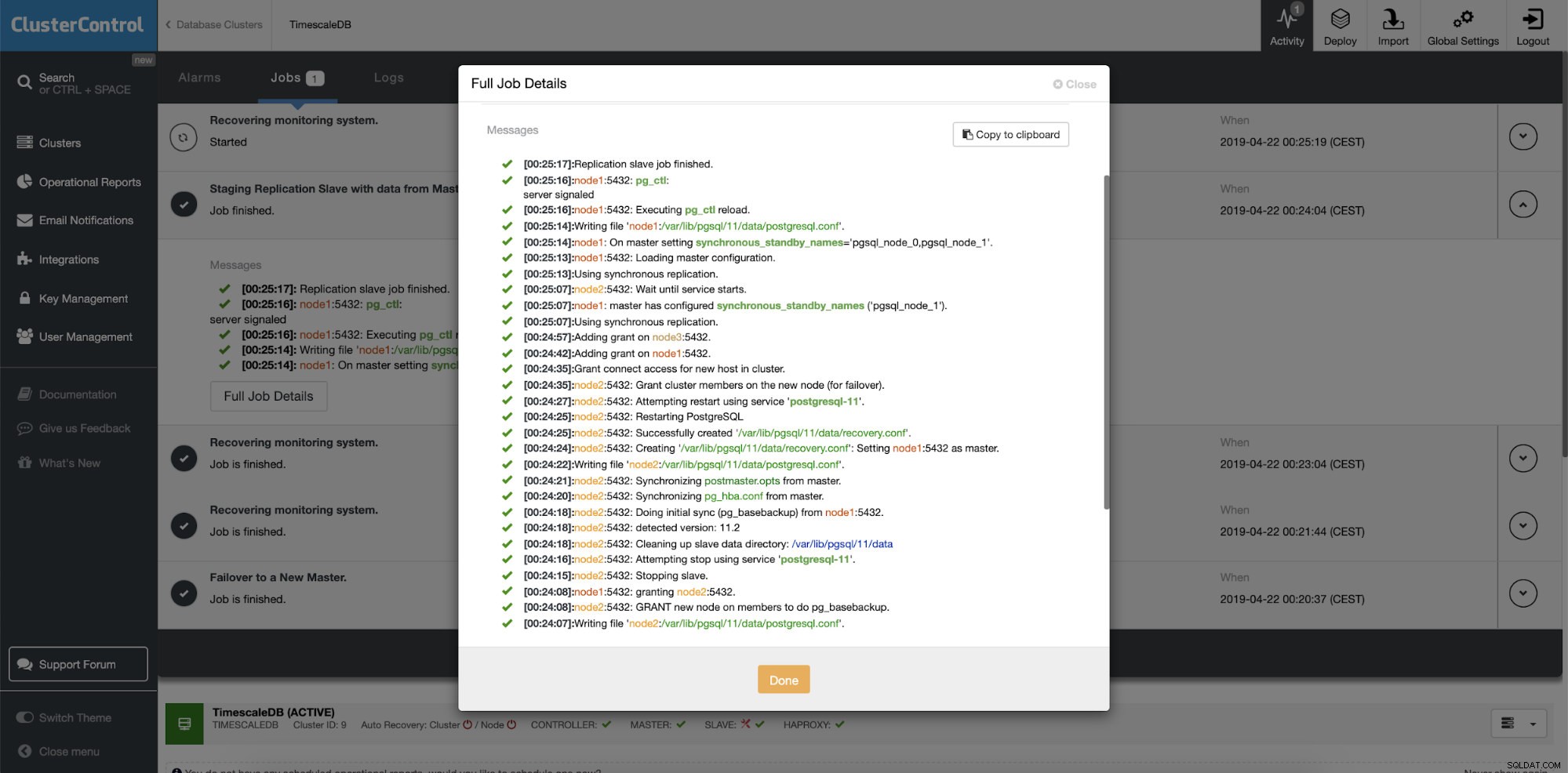 ClusterControl:Ricostruisci slave
ClusterControl:Ricostruisci slave