L'evidenziazione dei colpi è una funzionalità che molte persone desiderano che la ricerca full-text di SQL Server supporti in modo nativo. Qui è dove puoi restituire l'intero documento (o un estratto) e indicare le parole o le frasi che hanno aiutato ad abbinare quel documento alla ricerca. Farlo in modo efficiente e accurato non è un compito facile, come ho scoperto in prima persona.
Come esempio di hit-highlighting:quando esegui una ricerca in Google o Bing, ottieni le parole chiave in grassetto sia nel titolo che nell'estratto (fai clic su una delle immagini per ingrandire):

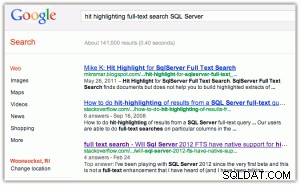
[Per inciso, trovo due cose divertenti qui:(1) che Bing favorisce le proprietà di Microsoft molto più di Google e (2) che Bing si preoccupa di restituire 2,2 milioni di risultati, molti dei quali sono probabilmente irrilevanti.]
Questi estratti sono comunemente chiamati "snippet" o "riassunti basati su query". È da tempo che chiediamo questa funzionalità in SQL Server, ma non abbiamo ancora ricevuto buone notizie da Microsoft:
- Connect #295100:riepiloghi di ricerca full-text (hit-evidenziazione)
- Connetti #722324:Sarebbe bello se la ricerca di testo completo SQL fornisse supporto per snippet/evidenziazione
La domanda compare di tanto in tanto anche su Stack Overflow:
- Come eseguire l'evidenziazione dei risultati da una query full-text di SQL Server
- Sql Server 2012 FTS avrà il supporto nativo per l'evidenziazione dei risultati?
Ci sono alcune soluzioni parziali. Questo script di Mike Kramar, ad esempio, produrrà un estratto evidenziato, ma non applica la stessa logica (come i word breaker specifici della lingua) al documento stesso. Utilizza anche un conteggio assoluto dei caratteri, quindi l'estratto può iniziare e terminare con parole parziali (come dimostrerò tra breve). Quest'ultimo è abbastanza facile da risolvere, ma un altro problema è che carica l'intero documento in memoria, invece di eseguire qualsiasi tipo di streaming. Sospetto che negli indici full-text con documenti di grandi dimensioni, questo sarà un notevole calo delle prestazioni. Per ora mi concentrerò su una dimensione media del documento relativamente piccola (35 KB).
Un semplice esempio
Diciamo quindi di avere una tabella molto semplice, con un indice full-text definito:
CREATE FULLTEXT CATALOG [FTSDemo]; GO CREATE TABLE [dbo].[Document] ( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL, [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID) ); GO CREATE FULLTEXT INDEX ON [dbo].[Document] ( [Content] LANGUAGE [English], [Title] LANGUAGE [English] ) KEY INDEX [PK_Document] ON ([FTSDemo]);
Questa tabella è popolata da alcuni documenti (nello specifico, 7), come la Dichiarazione di Indipendenza e il discorso "Sono pronto a morire" di Nelson Mandela. Una tipica ricerca full-text in questa tabella potrebbe essere:
SELECT d.Title, d.[Content] FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
Il risultato restituisce 4 righe su 7:

Ora utilizzando una funzione UDF come quella di Mike Kramar:
SELECT d.Title, Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80) FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
I risultati mostrano come funziona l'estratto:a <SPAN> tag viene inserito nella prima parola chiave e l'estratto viene ritagliato in base a un offset da quella posizione (senza considerare l'utilizzo di parole complete):

(Ancora una volta, questo è qualcosa che può essere risolto, ma voglio essere sicuro di rappresentare correttamente ciò che è là fuori ora.)
ThinkHighlight
Eran Meyuchas di Interactive Thoughts ha sviluppato un componente che risolve molti di questi problemi. ThinkHighlight è implementato come un assembly CLR con due funzioni a valori scalari CLR:
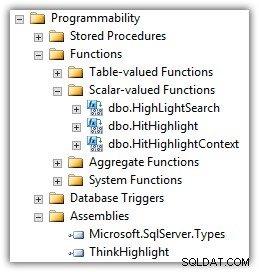
(Vedrai anche l'UDF di Mike Kramar nell'elenco delle funzioni.)
Ora, senza entrare in tutti i dettagli sull'installazione e l'attivazione dell'assieme sul tuo sistema, ecco come sarebbe rappresentata la query precedente con ThinkHighlight:
SELECT d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC; I risultati mostrano come vengono evidenziate le parole chiave più rilevanti e ne viene ricavato un estratto basato su parole complete e un offset dal termine evidenziato:

Alcuni vantaggi aggiuntivi che non ho dimostrato qui includono la possibilità di scegliere diverse strategie di riepilogo, controllare la presentazione di ogni parola chiave (piuttosto che tutte) utilizzando CSS univoci, nonché il supporto per più lingue e persino documenti in formato binario (la maggior parte degli IFilter sono supportati).
Risultati delle prestazioni
Inizialmente ho testato le metriche di runtime per le tre query utilizzando SQL Sentry Plan Explorer, rispetto alla tabella a 7 righe. I risultati sono stati:

Successivamente volevo vedere come si sarebbero confrontati su una dimensione dei dati molto più grande. Ho inserito la tabella in se stessa fino a raggiungere 4.000 righe, quindi ho eseguito la seguente query:
SET STATISTICS TIME ON;
GO
SELECT /* FTS */ d.Title, d.[Content]
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* UDF */ d.Title,
Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* ThinkHighlight */ d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC;
GO
SET STATISTICS TIME OFF;
GO Ho anche monitorato sys.dm_exec_memory_grants mentre le query erano in esecuzione, per rilevare eventuali discrepanze nelle concessioni di memoria. Risultati in media su 10 esecuzioni:
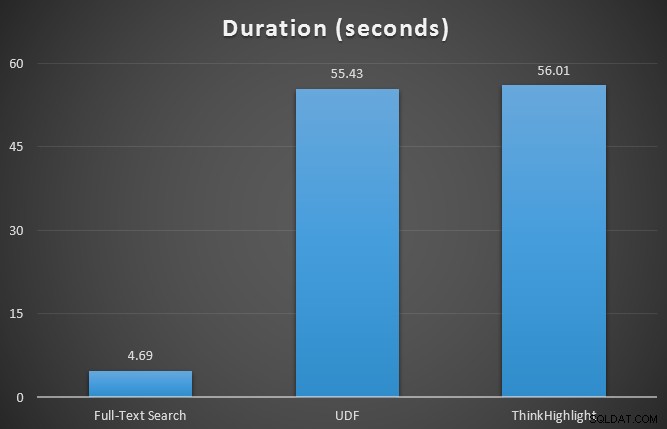
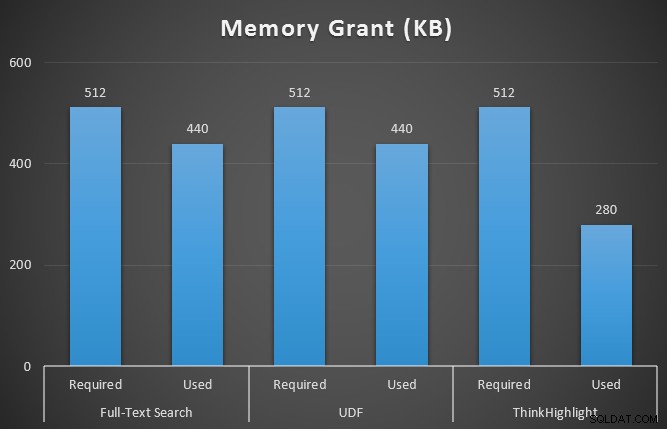
Mentre entrambe le opzioni di evidenziazione dei colpi comportano una penalità significativa per non essere evidenziate affatto, la soluzione ThinkHighlight, con opzioni più flessibili, rappresenta un costo incrementale molto marginale in termini di durata (~1%), mentre utilizza una quantità significativamente inferiore di memoria (36%) rispetto alla variante UDF.
Conclusione
Non dovrebbe sorprendere il fatto che l'evidenziazione dei risultati sia un'operazione costosa e, in base alla complessità di ciò che deve essere supportato (pensate a più lingue), esistono pochissime soluzioni disponibili. Penso che Mike Kramar abbia fatto un ottimo lavoro producendo un UDF di base che ti offre un buon modo per risolvere il problema, ma sono stato piacevolmente sorpreso di trovare un'offerta commerciale più solida e l'ho trovata molto stabile, anche in versione beta. Ho intenzione di eseguire test più approfonditi utilizzando una gamma più ampia di formati e tipi di documenti. Nel frattempo, se l'evidenziazione dei risultati fa parte dei requisiti dell'applicazione, dovresti provare l'UDF di Mike Kramar e prendere in considerazione l'idea di portare ThinkHighlight per un giro di prova.