Di tanto in tanto vedo persone che cercano di "ottimizzare" le loro dichiarazioni di aggiornamento per evitare di scrivere lo stesso valore in una particolare colonna. La mia comprensione è sempre stata che se intendi aggiornare una riga, supponendo che tutti i valori siano nella riga, i costi per bloccare la riga sono molto più alti del costo incrementale dell'aggiornamento di una, due o tutte le colonne in quella riga .
Quindi, ho creato una semplice tabella per testare questo:
CREATE TABLE dbo.whatever ( ID INT IDENTITY(1,1) PRIMARY KEY, v1 NVARCHAR(50) NOT NULL, v2 NVARCHAR(50) NOT NULL, v3 NVARCHAR(50) NOT NULL, v4 NVARCHAR(50) NOT NULL, v5 NVARCHAR(50) NOT NULL, v6 NVARCHAR(50) NOT NULL );
Quindi ho creato una procedura memorizzata per popolare la tabella con 50.000 righe con una varietà di piccole stringhe:
CREATE PROCEDURE dbo.clean
AS
BEGIN
SET NOCOUNT ON;
TRUNCATE TABLE dbo.whatever;
;WITH x(d) AS
(
SELECT d FROM
(
VALUES (N'abc'),(N'def'),(N'ghi'),
(N'jkl'),(N'mno'),(N'pqr')
) AS y(d)
)
INSERT dbo.whatever(v1, v2, v3, v4, v5, v6)
SELECT TOP (50000) x1.d, x2.d, x3.d, x4.d, x5.d, x6.d
FROM x AS x1, x AS x2, x AS x3, x AS x4,
x AS x5, x AS x6, x AS x7;
END
GO Quindi ho scritto dichiarazioni di aggiornamento formulate in due modi che potresti "evitare" di scrivere in una colonna specifica, data questa assegnazione di variabile:
DECLARE @v1 NVARCHAR(50) = N'abc', @v2 NVARCHAR(50) = N'def', @v3 NVARCHAR(50) = N'ghi', @v4 NVARCHAR(50) = N'jkl', @v5 NVARCHAR(50) = N'mno', @v6 NVARCHAR(50) = N'pqr';
Innanzitutto, utilizzando un'espressione CASE per verificare se il valore nella colonna è uguale al valore nella variabile:
UPDATE dbo.whatever SET
v1 = CASE WHEN v1 <> @v1 THEN @v1 ELSE v1 END,
v2 = CASE WHEN v2 <> @v2 THEN @v2 ELSE v2 END,
v3 = CASE WHEN v3 <> @v3 THEN @v3 ELSE v3 END,
v4 = CASE WHEN v4 <> @v4 THEN @v4 ELSE v4 END,
v5 = CASE WHEN v5 <> @v5 THEN @v5 ELSE v5 END,
v6 = CASE WHEN v6 <> @v6 THEN @v6 ELSE v6 END
WHERE
(
v1 <> @v1 OR v2 <> @v2 OR v3 <> @v3
OR v4 <> @v4 OR v5 <> @v5 OR v6 <> @v6
); E in secondo luogo emettendo un UPDATE indipendente per ogni colonna (ciascuna indirizzata solo alle righe in cui quel valore era, di fatto, cambiato):
UPDATE dbo.whatever SET v1 = @v1 WHERE v1 <> @v1; UPDATE dbo.whatever SET v2 = @v2 WHERE v2 <> @v2; UPDATE dbo.whatever SET v3 = @v3 WHERE v3 <> @v3; UPDATE dbo.whatever SET v4 = @v4 WHERE v4 <> @v4; UPDATE dbo.whatever SET v5 = @v5 WHERE v5 <> @v5; UPDATE dbo.whatever SET v6 = @v6 WHERE v6 <> @v6;
Quindi lo paragonerei al modo in cui la maggior parte di noi lo farebbe oggi:AGGIORNA semplicemente tutte le colonne senza preoccuparti se quello fosse il valore preesistente per quella particolare colonna:
UPDATE dbo.whatever SET
v1 = @v1, v2 = @v2, v3 = @v3,
v4 = @v4, v5 = @v5, v6 = @v6
WHERE
(
v1 <> @v1 OR v2 <> @v2 OR v3 <> @v3
OR v4 <> @v4 OR v5 <> @v5 OR v6 <> @v6
); (Tutti presuppongono che le colonne e i parametri/variabili non siano NULLable - dovrebbero usare COALESCE per tenere conto del confronto dei NULL su entrambi i lati in tal caso. Presumono anche che tu abbia una clausola WHERE aggiuntiva per indirizzare righe specifiche:in questo esempio è possibile eseguire la prima e la terza query senza la clausola WHERE onnicomprensiva e visualizzare risultati quasi identici. L'ho mantenuto semplice per brevità.)
Poi ho voluto vedere cosa succede in questi tre casi quando qualsiasi valore potrebbe essere modificato, quando determinati valori potrebbero essere modificati, quando nessun valore sarebbe cambiato e quando tutti i valori sarebbero stati modificati. Potrei influire su questo modificando la procedura memorizzata per inserire costanti in colonne particolari o modificando il modo in cui sono state assegnate le variabili.
-- to show when any value might change in a row, the procedure uses the full cross join: SELECT TOP (50000) x1.d, x2.d, x3.d, x4.d, x5.d, x6.d -- to show when particular values will change on many rows, we can hard-code constants: -- two values exempt: SELECT TOP (50000) N'abc', N'def', x3.d, x4.d, x5.d, x6.d -- four values exempt: SELECT TOP (50000) N'abc', N'def', N'ghi', N'jkl', x5.d, x6.d -- to show when no values will change, we hard-code all six values: SELECT TOP (50000) N'abc', N'def', N'ghi', N'jkl', N'mno', N'pqr' -- and to show when all values will change, a different variable assignment would take place: DECLARE @v1 NVARCHAR(50) = N'zzz', @v2 NVARCHAR(50) = N'zzz', @v3 NVARCHAR(50) = N'zzz', @v4 NVARCHAR(50) = N'zzz', @v5 NVARCHAR(50) = N'zzz', @v6 NVARCHAR(50) = N'zzz';
Risultati
Dopo aver eseguito questi test, l'"aggiornamento cieco" ha vinto in ogni singolo scenario. Ora, stai pensando, quanto sono duecento millisecondi? Estrapolare. Se stai eseguendo molti aggiornamenti nel tuo sistema, questo può davvero iniziare a farsi sentire.
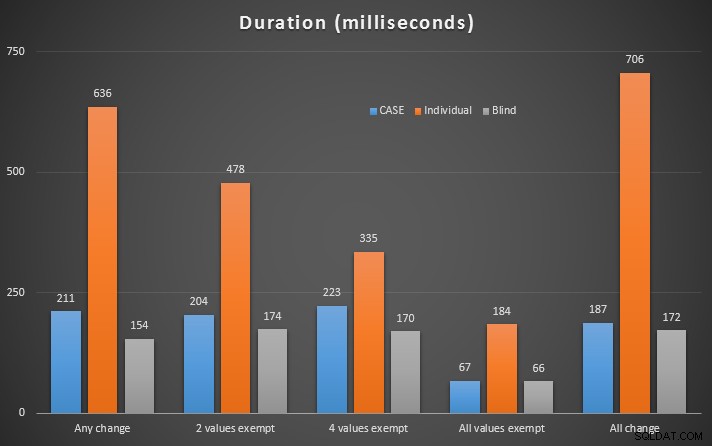
Risultati dettagliati in Plan Explorer:qualsiasi modifica | 2 valori esenti | 4 valori esenti | Tutti i valori esenti | Tutto cambia
Sulla base del feedback di Roji, ho deciso di testare anche questo con alcuni indici:
CREATE INDEX x1 ON dbo.whatever(v1); CREATE INDEX x2 ON dbo.whatever(v2); CREATE INDEX x3 ON dbo.whatever(v3) INCLUDE(v4,v5,v6);
Le durate sono state notevolmente aumentate con questi indici:
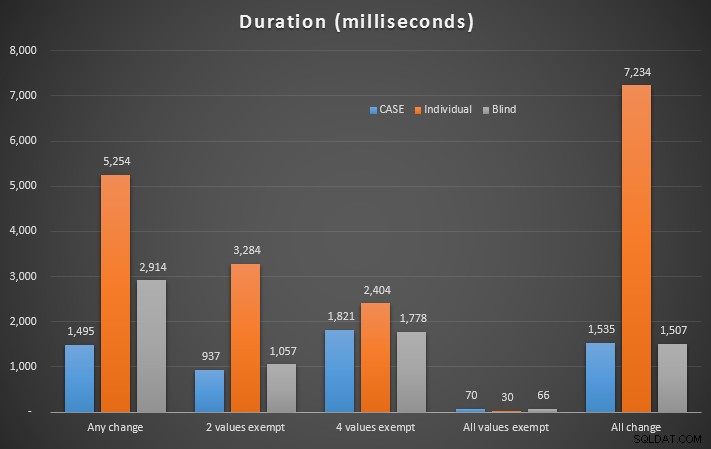
Risultati dettagliati in Plan Explorer:qualsiasi modifica | 2 valori esenti | 4 valori esenti | Tutti i valori esenti | Tutto cambia
Conclusione
Da questo test, mi sembra che di solito non valga la pena controllare se un valore deve essere aggiornato. Se la tua istruzione UPDATE interessa più colonne, è quasi sempre più economico scansionare tutte le colonne in cui qualsiasi valore potrebbe essere cambiato piuttosto che controllare ogni colonna singolarmente. In un prossimo post, esaminerò se questo scenario è parallelo per le colonne LOB.