Nella parte 1 e nella parte 2 di questa serie, ho trattato gli aspetti logici o concettuali delle espressioni di tabelle con nome in generale e le tabelle derivate in modo specifico. Questo mese e il prossimo tratterò gli aspetti dell'elaborazione fisica delle tabelle derivate. Ricordiamo dalla Parte 1 l'indipendenza dei dati fisici Principio della teoria relazionale. Il modello relazionale e il linguaggio di interrogazione standard su cui si basa dovrebbero trattare solo gli aspetti concettuali dei dati e lasciare i dettagli fisici di implementazione come archiviazione, ottimizzazione, accesso ed elaborazione dei dati alla piattaforma di database (il implementazione ). A differenza del trattamento concettuale dei dati che si basa su un modello matematico e su un linguaggio standard, e quindi è molto simile nei vari sistemi di gestione di database relazionali in circolazione, il trattamento fisico dei dati non si basa su alcuno standard, e quindi tende a essere molto specifico per la piattaforma. Nella mia trattazione del trattamento fisico delle espressioni di tabelle con nome nella serie, mi concentro sul trattamento in Microsoft SQL Server e Database SQL di Azure. Il trattamento fisico in altre piattaforme di database può essere molto diverso.
Ricordiamo che ciò che ha attivato questa serie è una certa confusione che esiste nella comunità di SQL Server intorno alle espressioni di tabelle denominate. Sia in termini di terminologia che di ottimizzazione. Ho affrontato alcune considerazioni terminologiche nelle prime due parti della serie e ne parlerò di più in articoli futuri quando discuterò di CTE, visualizzazioni e TVF inline. Per quanto riguarda l'ottimizzazione delle espressioni di tabelle con nome, c'è confusione intorno ai seguenti elementi (menziono qui le tabelle derivate poiché questo è l'obiettivo di questo articolo):
- Persistenza: Una tabella derivata è persistente da qualche parte? Viene persistente su disco e in che modo SQL Server gestisce la memoria per esso?
- Proiezione della colonna: Come funziona la corrispondenza degli indici con le tabelle derivate? Ad esempio, se una tabella derivata proietta un determinato sottoinsieme di colonne da una tabella sottostante e la query più esterna proietta un sottoinsieme di colonne dalla tabella derivata, SQL Server è abbastanza intelligente da determinare l'indicizzazione ottimale in base al sottoinsieme finale di colonne è effettivamente necessario? E per quanto riguarda i permessi; l'utente ha bisogno di autorizzazioni per tutte le colonne a cui si fa riferimento nelle query interne o solo per quelle finali effettivamente necessarie?
- Riferimenti multipli ad alias di colonna: Se la tabella derivata ha una colonna dei risultati basata su un calcolo non deterministico, ad esempio una chiamata alla funzione SYSDATETIME, e la query esterna ha più riferimenti a quella colonna, il calcolo verrà eseguito solo una volta o separatamente per ogni riferimento esterno ?
- Disnestamento/sostituzione/inserimento: SQL Server annulla o incorpora in linea la query della tabella derivata? Cioè, SQL Server esegue un processo di sostituzione in base al quale converte il codice nidificato originale in una query che va direttamente sulle tabelle di base? E in tal caso, c'è un modo per istruire SQL Server per evitare questo processo di disinnesto?
Queste sono tutte domande importanti e le risposte a queste domande hanno implicazioni significative sulle prestazioni, quindi è una buona idea avere una chiara comprensione di come questi elementi vengono gestiti in SQL Server. Questo mese affronterò i primi tre punti. C'è molto da dire sul quarto elemento, quindi gli dedicherò un articolo separato il mese prossimo (parte 4).
Nei miei esempi userò un database di esempio chiamato TSQLV5. Puoi trovare lo script che crea e popola TSQLV5 qui e il suo diagramma ER qui.
Persistenza
Alcune persone presumono intuitivamente che SQL Server persista il risultato della parte dell'espressione della tabella della tabella derivata (il risultato della query interna) in un tavolo di lavoro. Alla data in cui scrivo non è così; tuttavia, poiché le considerazioni sulla persistenza sono una scelta del fornitore, Microsoft potrebbe decidere di cambiarlo in futuro. In effetti, SQL Server è in grado di mantenere i risultati di query intermedi nelle tabelle di lavoro (in genere in tempdb) come parte dell'elaborazione della query. Se sceglie di farlo, nel piano viene visualizzata una forma di operatore di spool (Spool, Spool desideroso, Spool pigro, Spool tabella, Spool indice, Spool finestra, Spool conteggio righe). Tuttavia, la scelta di SQL Server se eseguire lo spooling di qualcosa in un tavolo di lavoro o meno attualmente non ha nulla a che fare con l'uso delle espressioni di tabella con nome nella query. SQL Server a volte esegue lo spooling dei risultati intermedi per motivi di prestazioni, come evitare il lavoro ripetuto (sebbene attualmente non correlato all'uso di espressioni di tabelle con nome) e talvolta per altri motivi, come la protezione di Halloween.
Come accennato, il mese prossimo arriverò ai dettagli dell'annullamento dell'annidamento delle tabelle derivate. Per ora, è sufficiente dire che SQL Server normalmente applica un processo di annullamento dell'annidamento/integrazione alle tabelle derivate, in cui sostituisce le query nidificate con una query rispetto alle tabelle di base sottostanti. Bene, sto semplificando un po'. Non è che SQL Server converta letteralmente la stringa di query T-SQL originale con le tabelle derivate in una nuova stringa di query senza quelle; piuttosto SQL Server applica le trasformazioni a un albero logico interno di operatori e il risultato è che in genere le tabelle derivate non vengono nidificate. Quando guardi un piano di esecuzione per una query che coinvolge tabelle derivate, non ne vedi alcuna menzione perché per la maggior parte degli scopi di ottimizzazione non esistono. Viene visualizzato l'accesso alle strutture fisiche che contengono i dati per le tabelle di base sottostanti (heap, indici B-tree rowstore e indici columnstore per tabelle basate su disco e indici ad albero e hash per tabelle ottimizzate per la memoria).
Ci sono casi che impediscono a SQL Server di annullare l'annidamento di una tabella derivata, ma anche in questi casi SQL Server non mantiene il risultato dell'espressione di tabella in una tabella di lavoro. Il mese prossimo fornirò i dettagli insieme agli esempi.
Poiché SQL Server non mantiene le tabelle derivate, ma interagisce direttamente con le strutture fisiche che contengono i dati per le tabelle di base sottostanti, la domanda su come viene gestita la memoria per le tabelle derivate è discutibile. Se le tabelle di base sottostanti sono basate su disco, le relative pagine devono essere elaborate nel pool di buffer. Se le tabelle sottostanti sono ottimizzate per la memoria, è necessario elaborare le relative righe in memoria. Ma non è diverso da quando esegui query direttamente sulle tabelle sottostanti senza utilizzare tabelle derivate. Quindi non c'è niente di speciale qui. Quando si utilizzano tabelle derivate, non è necessario che SQL Server applichi considerazioni di memoria speciali per quelle. Per la maggior parte degli scopi di ottimizzazione delle query, non esistono.
Se hai un caso in cui devi mantenere il risultato di alcuni passaggi intermedi in un tavolo di lavoro, devi utilizzare tabelle temporanee o variabili di tabella, non espressioni di tabella con nome.
Proiezione della colonna e una parola su SELECT *
La proiezione è uno degli operatori originali dell'algebra relazionale. Supponiamo di avere una relazione R1 con attributi x, yez. La proiezione di R1 su qualche sottoinsieme dei suoi attributi, ad esempio xez, è una nuova relazione R2, la cui intestazione è il sottoinsieme degli attributi proiettati da R1 (xez nel nostro caso), e il cui corpo è l'insieme delle tuple formato dalla combinazione originale dei valori degli attributi previsti dalle tuple di R1.
Ricordiamo che il corpo di una relazione, essendo un insieme di tuple, per definizione non ha duplicati. Quindi è ovvio che le tuple della relazione di risultato sono la combinazione distinta di valori di attributo proiettati dalla relazione originale. Tuttavia, ricorda che il corpo di una tabella in SQL è un multiset di righe e non un set e, normalmente, SQL non eliminerà le righe duplicate a meno che tu non lo istruisca. Data una tabella R1 con le colonne x, yez, la query seguente può potenzialmente restituire righe duplicate e quindi non segue la semantica dell'operatore di proiezione dell'algebra relazionale di restituire un insieme:
SELECT x, z FROM R1;
Aggiungendo una clausola DISTINCT, elimini le righe duplicate e segui più da vicino la semantica della proiezione relazionale:
SELECT DISTINCT x, z FROM R1;
Naturalmente, ci sono alcuni casi in cui sai che il risultato della tua query ha righe distinte senza la necessità di una clausola DISTINCT, ad esempio, quando un sottoinsieme delle colonne che stai restituendo include una chiave dalla tabella interrogata. Ad esempio, se x è una chiave in R1, le due query precedenti sono logicamente equivalenti.
In ogni caso, ricorda le domande che ho menzionato in precedenza sull'ottimizzazione delle query che coinvolgono tabelle derivate e proiezione di colonne. Come funziona la corrispondenza degli indici? Se una tabella derivata proietta un determinato sottoinsieme di colonne da una tabella sottostante e la query più esterna proietta un sottoinsieme di colonne dalla tabella derivata, SQL Server è abbastanza intelligente da determinare l'indicizzazione ottimale in base al sottoinsieme finale di colonne che è effettivamente necessario? E per quanto riguarda i permessi; l'utente ha bisogno di autorizzazioni per tutte le colonne a cui si fa riferimento nelle query interne o solo per quelle finali effettivamente necessarie? Si supponga inoltre che la query dell'espressione di tabella definisca una colonna di risultati basata su un calcolo, ma la query esterna non proietta quella colonna. Il calcolo viene valutato?
Partendo dall'ultima domanda, proviamo. Considera la seguente query:
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
Come ci si aspetterebbe, questa query non riesce con un errore di divisione per zero:
Msg 8134, livello 16, stato 1Si è verificato un errore di divisione per zero.
Quindi, definisci una tabella derivata chiamata D in base alla query precedente e nella query esterna progetto D solo su custid e città, in questo modo:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; Come accennato, SQL Server normalmente applica l'annullamento dell'annidamento/sostituzione e poiché non c'è nulla in questa query che inibisca l'annullamento dell'annidamento (ulteriori informazioni nel prossimo mese), la query precedente equivale alla query seguente:
SELECT custid, city FROM Sales.Customers;
Ancora una volta, sto semplificando un po 'qui. La realtà è un po' più complessa di come queste due domande siano considerate veramente identiche, ma arriverò a queste complessità il mese prossimo. Il punto è che l'espressione 1/0 non viene nemmeno visualizzata nel piano di esecuzione della query e non viene valutata affatto, quindi la query precedente viene eseguita correttamente senza errori.
Tuttavia, l'espressione della tabella deve essere valida. Ad esempio, considera la seguente query:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Anche se la query esterna proietta solo una colonna dal set di raggruppamento della query interna, la query interna non è valida poiché tenta di restituire colonne che non fanno parte del set di raggruppamento né contenute in una funzione di aggregazione. Questa query non riesce con il seguente errore:
Msg 8120, livello 16, stato 1La colonna 'Sales.Customers.custid' non è valida nell'elenco di selezione perché non è contenuta né in una funzione aggregata né nella clausola GROUP BY.
Quindi, affrontiamo la domanda di corrispondenza dell'indice. Se la query esterna proietta solo un sottoinsieme delle colonne dalla tabella derivata, SQL Server sarà abbastanza intelligente da eseguire la corrispondenza degli indici in base solo alle colonne restituite (e ovviamente a qualsiasi altra colonna che svolge un ruolo significativo in caso contrario, come il filtraggio, raggruppamento e così via)? Ma prima di affrontare questa domanda, potresti chiederti perché ci stiamo anche preoccupando. Perché dovresti avere le colonne di ritorno della query interna di cui la query esterna non ha bisogno?
La risposta è semplice, per abbreviare il codice facendo in modo che la query interna utilizzi il famigerato SELECT *. Sappiamo tutti che l'uso di SELECT * è una cattiva pratica, ma questo è il caso principalmente quando viene utilizzato nella query più esterna. Cosa succede se si interroga una tabella con una determinata intestazione e in seguito tale intestazione viene modificata? L'applicazione potrebbe finire con dei bug. Anche se non si riscontrano bug, si potrebbe finire per generare traffico di rete non necessario restituendo colonne di cui l'applicazione non ha realmente bisogno. Inoltre, in questo caso, utilizzi l'indicizzazione in modo meno ottimale poiché riduci le possibilità di abbinare gli indici di copertura basati sulle colonne veramente necessarie.
Detto questo, in realtà mi sento abbastanza a mio agio nell'usare SELECT * in un'espressione di tabella, sapendo che comunque proietterò solo le colonne veramente necessarie nella query più esterna. Da un punto di vista logico, è abbastanza sicuro con alcuni avvertimenti minori che arriverò a breve. A condizione che la corrispondenza dell'indice sia eseguita in modo ottimale in questo caso, e la buona notizia lo è.
Per dimostrarlo, supponiamo di dover interrogare la tabella Sales.Orders, restituendo i tre ordini più recenti per ciascun cliente. Stai pianificando di definire una tabella derivata chiamata D basata su una query che calcola i numeri di riga (colonna dei risultati rownum) che sono partizionati per custid e ordinati per orderdate DESC, orderid DESC. La query esterna filtrerà da D (relazionale restrizione ) solo le righe in cui rownum è minore o uguale a 3 e proiettano D su custid, orderdate, orderid e rownum. Ora, Sales.Orders ha più colonne di quelle che devi proiettare, ma per brevità, vuoi che la query interna utilizzi SELECT *, più il calcolo del numero di riga. È sicuro e verrà gestito in modo ottimale in termini di corrispondenza dell'indice.
Usa il codice seguente per creare l'indice di copertura ottimale per supportare la tua query:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Ecco la query che archivia l'attività in questione (la chiameremo Query 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Notare SELECT * della query interna e l'elenco di colonne esplicite della query esterna.
Il piano per questa query, reso da SentryOne Plan Explorer, è mostrato nella Figura 1.
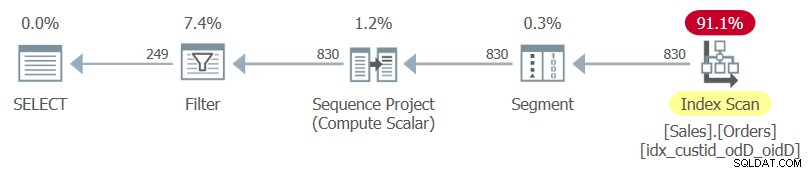 Figura 1:piano per la query 1
Figura 1:piano per la query 1
Osserva che l'unico indice utilizzato in questo piano è l'indice di copertura ottimale che hai appena creato.
Se evidenzi solo la query interna ed esamini il suo piano di esecuzione, vedrai l'indice cluster della tabella utilizzato seguito da un'operazione di ordinamento.
Quindi questa è una buona notizia.
Per quanto riguarda i permessi, questa è un'altra storia. A differenza della corrispondenza dell'indice, in cui non è necessario che l'indice includa colonne a cui fanno riferimento le query interne purché non siano necessarie, è necessario disporre delle autorizzazioni per tutte le colonne a cui si fa riferimento.
A dimostrazione di ciò, utilizzare il codice seguente per creare un utente chiamato utente1 e assegnare alcune autorizzazioni (SELEZIONARE autorizzazioni su tutte le colonne di Sales.Customers e solo sulle tre colonne di Sales.Orders che sono in definitiva rilevanti nella query precedente):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Esegui il codice seguente per impersonare utente1:
EXECUTE AS USER = 'user1';
Prova a selezionare tutte le colonne da Sales.Orders:
SELECT * FROM Sales.Orders;
Come previsto, ricevi i seguenti errori a causa della mancanza di autorizzazioni su alcune colonne:
Msg 230, livello 14, stato 1L'autorizzazione SELECT è stata negata nella colonna 'empid' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230 , Livello 14, Stato 1
L'autorizzazione SELECT è stata negata nella colonna 'requireddate' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, Livello 14, Stato 1
L'autorizzazione SELECT è stata negata nella colonna 'shippeddate' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Stato 1
L'autorizzazione SELECT è stata negata sulla colonna 'shipperid' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, livello 14, stato 1
L'autorizzazione SELECT è stata negata sulla colonna 'trasporto' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, livello 14, stato 1
/>L'autorizzazione SELECT è stata negata sulla colonna 'shipname' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
/>L'autorizzazione SELECT è stata negata sulla colonna 'shipaddress' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
L'autorizzazione SELECT è stata negata sulla colonna 'shipcity' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT l'autorizzazione è stata negata nella colonna 'shipregion' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
L'autorizzazione SELECT era negato nella colonna 'codice postale' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, Livello 14, Stato 1
L'autorizzazione SELECT è stata negata il la colonna 'shipcountry' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Prova la seguente query, proiettando e interagendo solo con le colonne per le quali l'utente1 dispone delle autorizzazioni:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Tuttavia, ottieni errori di autorizzazione delle colonne a causa della mancanza di autorizzazioni su alcune delle colonne a cui fa riferimento la query interna tramite il suo SELECT *:
Msg 230, livello 14, stato 1L'autorizzazione SELECT è stata negata nella colonna 'empid' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230 , Livello 14, Stato 1
L'autorizzazione SELECT è stata negata nella colonna 'requireddate' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, Livello 14, Stato 1
L'autorizzazione SELECT è stata negata nella colonna 'shippeddate' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Stato 1
L'autorizzazione SELECT è stata negata sulla colonna 'shipperid' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, livello 14, stato 1
L'autorizzazione SELECT è stata negata sulla colonna 'trasporto' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, livello 14, stato 1
/>L'autorizzazione SELECT è stata negata sulla colonna 'shipname' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
/>L'autorizzazione SELECT è stata negata sulla colonna 'shipaddress' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
L'autorizzazione SELECT è stata negata sulla colonna 'shipcity' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
The SELECT l'autorizzazione è stata negata nella colonna 'shipregion' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
L'autorizzazione SELECT era negato nella colonna 'codice postale' dell'oggetto 'Ordini', database 'TSQLV5', schema 'Vendite'.
Msg 230, Livello 14, Stato 1
L'autorizzazione SELECT è stata negata il la colonna 'shipcountry' dell'oggetto 'Orders', database 'TSQLV5', schema 'Sales'.
Se davvero nella tua azienda è una pratica assegnare agli utenti le autorizzazioni solo sulle colonne pertinenti con cui devono interagire, avrebbe senso utilizzare un codice un po' più lungo ed essere esplicito sull'elenco delle colonne sia nelle query interne che in quelle esterne, così:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Questa volta, la query viene eseguita senza errori.
Un'altra variazione che richiede all'utente di disporre delle autorizzazioni solo sulle colonne pertinenti è di essere esplicito sui nomi delle colonne nell'elenco SELECT della query interna e utilizzare SELECT * nella query esterna, in questo modo:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Anche questa query viene eseguita senza errori. Tuttavia, vedo questa versione come una versione soggetta a bug nel caso in cui in seguito vengano apportate modifiche a un livello interno di annidamento. Come accennato in precedenza, per me la migliore pratica è essere espliciti sull'elenco di colonne nella query più esterna. Quindi, finché non hai dubbi sulla mancanza di autorizzazione su alcune colonne, mi sento a mio agio con SELECT * nelle query interne, ma un elenco di colonne esplicito nella query più esterna. Se l'applicazione di autorizzazioni di colonna specifiche è una pratica comune nell'azienda, è meglio essere semplicemente espliciti sui nomi delle colonne in tutti i livelli di annidamento. Intendiamoci, essere espliciti sui nomi delle colonne in tutti i livelli di nidificazione è in realtà obbligatorio se la tua query viene utilizzata in un oggetto associato allo schema, poiché il binding dello schema non consente l'uso di SELECT * in qualsiasi punto della query.
A questo punto, esegui il codice seguente per rimuovere l'indice che hai creato in precedenza su Sales.Orders:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
C'è un altro caso con un dilemma simile riguardante la legittimità dell'uso di SELECT *; nella query interna del predicato EXISTS.
Considera la seguente query (la chiameremo Query 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); Il piano per questa query è mostrato nella Figura 2.
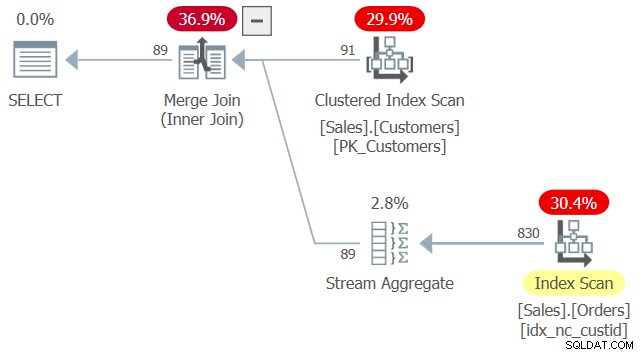 Figura 2:piano per la query 2
Figura 2:piano per la query 2
Quando si applica la corrispondenza dell'indice, l'ottimizzatore ha calcolato che l'indice idx_nc_custid è un indice di copertura su Sales.Orders poiché contiene la colonna custid, l'unica colonna realmente rilevante in questa query. Questo nonostante il fatto che questo indice non contenga altre colonne oltre a custid e che la query interna nel predicato EXISTS indichi SELECT *. Finora, il comportamento sembra simile all'uso di SELECT * nelle tabelle derivate.
La differenza con questa query è che viene eseguita senza errori, nonostante il fatto che utente1 non disponga delle autorizzazioni su alcune delle colonne di Sales.Orders. C'è un argomento per giustificare la non richiesta di autorizzazioni su tutte le colonne qui. Dopotutto, il predicato EXISTS deve solo verificare l'esistenza di righe corrispondenti, quindi l'elenco SELECT della query interna è davvero privo di significato. Probabilmente sarebbe stato meglio se SQL non avesse richiesto affatto un elenco SELECT in un caso del genere, ma quella nave è già salpata. La buona notizia è che l'elenco SELECT viene effettivamente ignorato, sia in termini di corrispondenza dell'indice che in termini di autorizzazioni richieste.
Sembrerebbe anche che ci sia un'altra differenza tra tabelle derivate ed EXISTS quando si utilizza SELECT * nella query interna. Ricorda questa query di prima nell'articolo:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Se ricordi, questo codice ha generato un errore poiché la query interna non è valida.
Prova la stessa query interna, solo questa volta nel predicato EXISTS (chiameremo questa affermazione 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; Stranamente, SQL Server considera questo codice valido e viene eseguito correttamente. Il piano per questo codice è mostrato nella Figura 3.
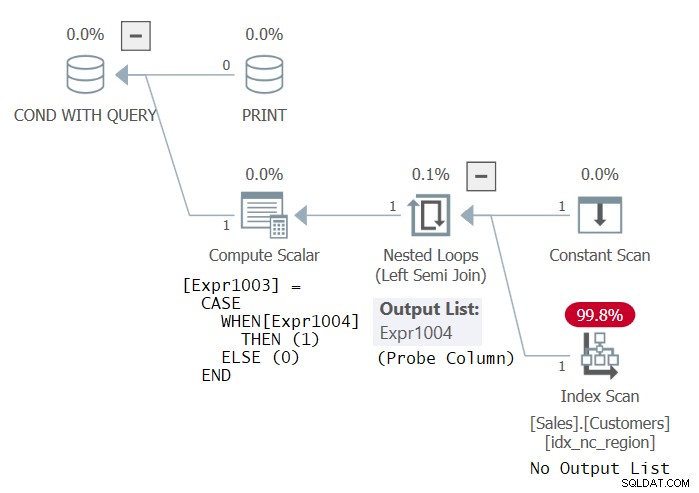 Figura 3:Piano per la dichiarazione 3
Figura 3:Piano per la dichiarazione 3
Questo piano è identico al piano che otterresti se la query interna fosse solo SELECT * FROM Sales.Customers (senza GROUP BY). Dopotutto, stai controllando l'esistenza di gruppi e, se ci sono righe, ci sono naturalmente gruppi. Ad ogni modo, penso che il fatto che SQL Server consideri valida questa query sia un bug. Sicuramente il codice SQL dovrebbe essere valido! Ma posso capire perché alcuni potrebbero sostenere che l'elenco SELECT nella query EXISTS dovrebbe essere ignorato. In ogni caso, il piano utilizza un semi join sinistro sondato, che non deve restituire alcuna colonna, ma semplicemente sondare una tabella per verificare l'esistenza di righe. L'indice sui Clienti potrebbe essere qualsiasi indice.
A questo punto puoi eseguire il codice seguente per smettere di impersonare utente1 e rimuoverlo:
REVERT; DROP USER IF EXISTS user1;
Tornando al fatto che trovo che sia una pratica conveniente usare SELECT * nei livelli interni di nidificazione, più livelli hai, più questa pratica accorcia e semplifica il tuo codice. Ecco un esempio con due livelli di annidamento:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; Ci sono casi in cui questa pratica non può essere utilizzata. Ad esempio, quando la query interna unisce tabelle con nomi di colonna comuni, come nell'esempio seguente:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Sia Sales.Customers che Sales.Orders hanno una colonna chiamata custid. Stai utilizzando un'espressione di tabella basata su un join tra le due tabelle per definire la tabella derivata D. Ricorda che l'intestazione di una tabella è un insieme di colonne e, come insieme, non puoi avere nomi di colonna duplicati. Pertanto, questa query non riesce con il seguente errore:
Msg 8156, livello 16, stato 1La colonna 'custid' è stata specificata più volte per 'D'.
Qui, devi essere esplicito sui nomi delle colonne nella query interna e assicurarti di restituire custid solo da una delle tabelle o di assegnare nomi di colonna univoci alle colonne dei risultati nel caso in cui desideri restituire entrambi. Più spesso utilizzeresti il primo approccio, in questo modo:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Ancora una volta, potresti essere esplicito con i nomi delle colonne nella query interna e utilizzare SELECT * nella query esterna, in questo modo:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Ma come ho detto prima, ritengo una cattiva pratica non essere espliciti sui nomi delle colonne nella query più esterna.
Riferimenti multipli ad alias di colonna
Procediamo con l'elemento successivo:più riferimenti a colonne di tabelle derivate. Se la tabella derivata ha una colonna dei risultati basata su un calcolo non deterministico e la query esterna ha più riferimenti a quella colonna, il calcolo verrà valutato solo una volta o separatamente per ogni riferimento?
Iniziamo con il fatto che più riferimenti alla stessa funzione non deterministica in una query dovrebbero essere valutati in modo indipendente. Considera la seguente query come esempio:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Questo codice genera il seguente output che mostra due diversi GUID:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Al contrario, se hai una tabella derivata con una colonna basata su un calcolo non deterministico e la query esterna ha più riferimenti a quella colonna, il calcolo dovrebbe essere valutato solo una volta. Considera la seguente query (che chiameremo Query 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
Il piano per questa query è mostrato nella Figura 4.
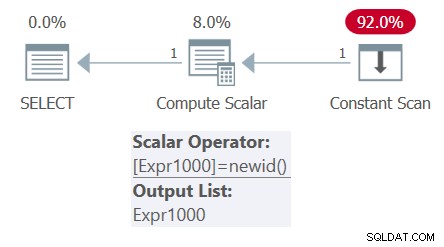 Figura 4:piano per la query 4
Figura 4:piano per la query 4
Osservare che c'è solo una chiamata della funzione NEWID nel piano. Di conseguenza, l'output mostra lo stesso GUID due volte:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
Quindi, le due query precedenti non sono logicamente equivalenti e ci sono casi in cui l'integrazione/sostituzione non ha luogo.
Con alcune funzioni non deterministiche è un po' più complicato dimostrare che più chiamate in una query vengono gestite separatamente. Prendi la funzione SYSDATETIME come esempio. Ha una precisione di 100 nanosecondi. Quali sono le possibilità che una query come la seguente mostri effettivamente due valori diversi?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Se sei annoiato, potresti premere F5 ripetutamente finché non succede. Se hai cose più importanti da fare con il tuo tempo, potresti preferire eseguire un ciclo, in questo modo:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; Ad esempio, quando ho eseguito questo codice, ho ottenuto 1971.
Se vuoi assicurarti che la funzione non deterministica venga invocata solo una volta e fare affidamento sullo stesso valore in più riferimenti a query, assicurati di definire un'espressione di tabella con una colonna basata sulla chiamata della funzione e di avere più riferimenti a quella colonna dalla query esterna, in questo modo (chiameremo questa query 5):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
Il piano per questa query è mostrato nella Figura 5.
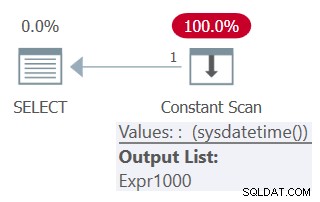 Figura 5:piano per la query 5
Figura 5:piano per la query 5
Nota nel piano che la funzione viene invocata solo una volta.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; Riepilogo
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.