Galera Cluster, con la sua replica (virtualmente) sincrona, è comunemente usato in molti diversi tipi di ambienti. Ridimensionarlo aggiungendo nuovi nodi non è difficile (o altrettanto semplice con un paio di clic quando usi ClusterControl).
Il problema principale con la replica sincrona è, beh, la parte sincrona che spesso fa sì che l'intero cluster sia veloce solo quanto il suo nodo più lento. Qualsiasi scrittura eseguita su un cluster deve essere replicata su tutti i nodi e certificata su di essi. Se, per qualsiasi motivo, questo processo rallenta, può influire seriamente sulla capacità del cluster di ospitare le scritture. Quindi entrerà in funzione il controllo del flusso, questo per garantire che il nodo più lento possa ancora tenere il passo con il carico. Questo lo rende piuttosto complicato per alcuni degli scenari comuni che si verificano in un ambiente del mondo reale.
Prima di tutto, discutiamo del ripristino di emergenza distribuito geograficamente. Certo, puoi eseguire cluster su una WAN, ma la maggiore latenza avrà un impatto significativo sulle prestazioni del cluster. Ciò limita seriamente la possibilità di utilizzare tale configurazione, soprattutto su distanze più lunghe quando la latenza è maggiore.
Un altro caso d'uso abbastanza comune:un ambiente di test per l'aggiornamento della versione principale. Non è una buona idea mescolare diverse versioni dei nodi MariaDB Galera Cluster nello stesso cluster, anche se è possibile. D'altra parte, la migrazione alla versione più recente richiede test dettagliati. Idealmente, sia le letture che le scritture sarebbero state testate. Un modo per ottenere ciò è creare un cluster Galera separato ed eseguire i test, ma si desidera eseguire i test in un ambiente il più vicino possibile alla produzione. Una volta eseguito il provisioning, un cluster può essere utilizzato per i test con query del mondo reale, ma sarebbe difficile generare un carico di lavoro simile a quello di produzione. Non puoi spostare parte del traffico di produzione su tale sistema di test, questo perché i dati non sono aggiornati.
Infine, la migrazione stessa. Ancora una volta, quello che abbiamo detto prima, anche se è possibile mescolare vecchie e nuove versioni dei nodi Galera nello stesso cluster, non è il modo più sicuro per farlo.
Fortunatamente, la soluzione più semplice per tutti questi tre problemi sarebbe connettere cluster Galera separati con una replica asincrona. Cosa lo rende una buona soluzione? Bene, è asincrono, il che non influisce sulla replica di Galera. Non c'è controllo di flusso, quindi le prestazioni del cluster "master" non saranno influenzate dalle prestazioni del cluster "slave". Come con ogni replica asincrona, può verificarsi un ritardo, ma finché rimane entro limiti accettabili, può funzionare perfettamente. Devi anche tenere presente che al giorno d'oggi la replica asincrona può essere parallelizzata (più thread possono lavorare insieme per aumentare la larghezza di banda) e ridurre ulteriormente il ritardo di replica.
In questo post del blog discuteremo quali sono i passaggi per distribuire la replica asincrona tra i cluster MariaDB Galera.
Come configurare la replica asincrona tra cluster MariaDB Galera?
Prima di tutto dobbiamo distribuire un cluster. Per i nostri scopi configuriamo un cluster a tre nodi. Manterremo la configurazione al minimo, quindi non discuteremo della complessità dell'applicazione e del livello proxy. Il livello proxy può essere molto utile per la gestione delle attività per le quali si desidera distribuire la replica asincrona, reindirizzando un sottoinsieme del traffico di sola lettura al cluster di test, aiutando nella situazione di ripristino di emergenza quando il cluster "principale" non è disponibile reindirizzando il traffico verso il cluster di ripristino di emergenza. Esistono numerosi proxy che puoi provare, a seconda delle tue preferenze - HAProxy, MaxScale o ProxySQL - tutti possono essere utilizzati in tali configurazioni e, a seconda dei casi, alcuni di essi potrebbero essere in grado di aiutarti a gestire il tuo traffico.
Configurazione del cluster di origine
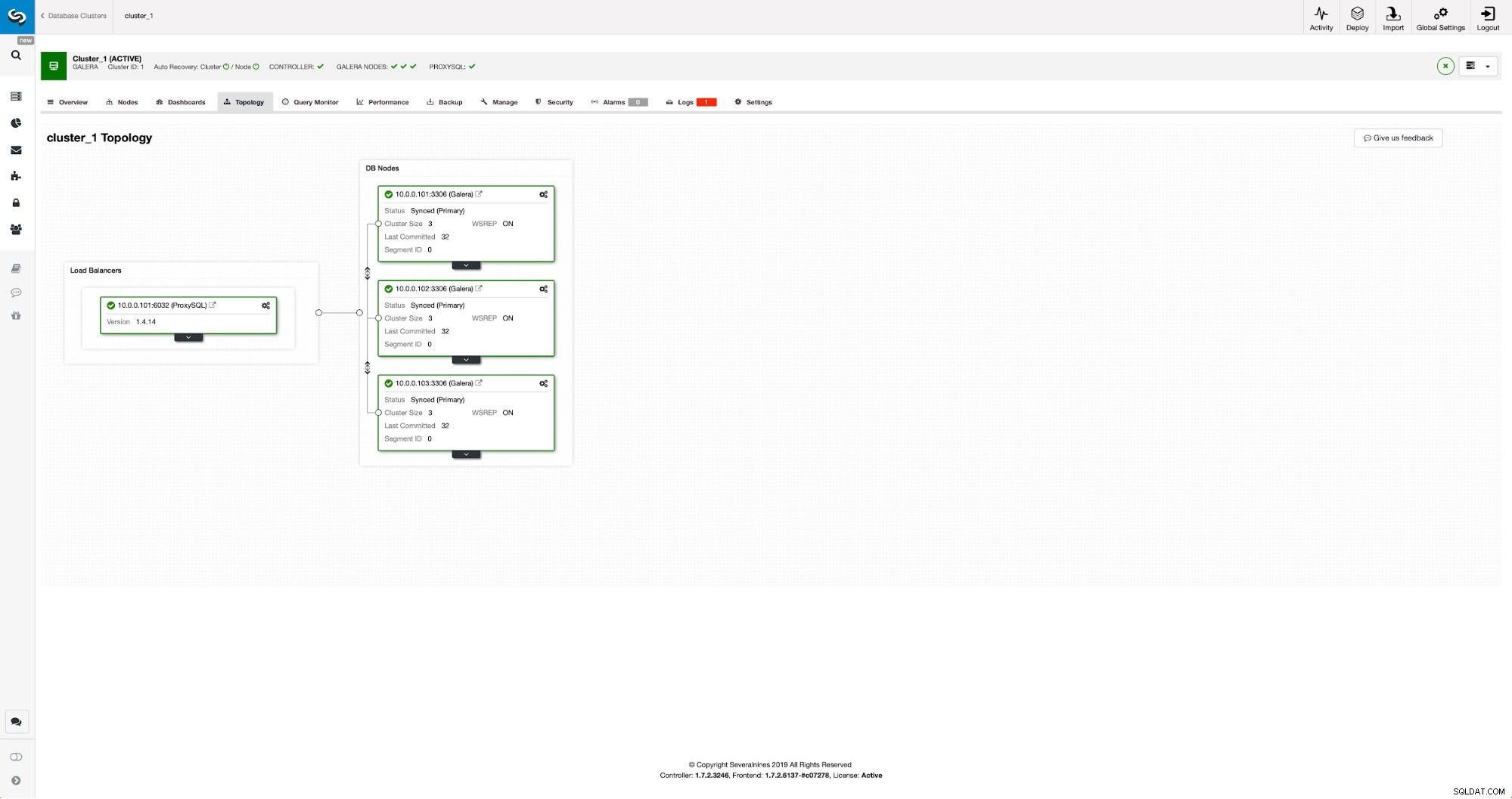
Il nostro cluster è composto da tre nodi MariaDB 10.3, abbiamo anche implementato ProxySQL per eseguire la suddivisione in lettura-scrittura e distribuire il traffico su tutti i nodi del cluster. Questa non è una distribuzione di livello di produzione, per questo dovremmo distribuire più nodi ProxySQL e un Keepalived su di essi. È ancora sufficiente per i nostri scopi. Per impostare la replica asincrona dovremo avere un log binario abilitato sul nostro cluster. Almeno un nodo, ma è meglio tenerlo abilitato su tutti loro nel caso in cui l'unico nodo con binlog abilitato vada inattivo, quindi desideri avere un altro nodo nel cluster attivo e funzionante che puoi disattivare.
Quando si abilita il log binario, assicurati di configurare la rotazione del log binario in modo che i vecchi log vengano rimossi a un certo punto. Utilizzerai il formato di registro binario ROW. Dovresti anche assicurarti di avere GTID configurato e in uso:sarà molto utile quando dovrai riattivare il tuo cluster "slave" o se dovrai abilitare la replica multi-thread. Poiché si tratta di un cluster Galera, devi avere "wsrep_gtid_domain_id" configurato e "wsrep_gtid_mode" abilitato. Tali impostazioni garantiranno la generazione di GTID per il traffico proveniente dal cluster Galera. Maggiori informazioni possono essere trovate nella documentazione. Al termine, puoi procedere con la configurazione del secondo cluster.
Impostazione del cluster di destinazione
Dato che attualmente non esiste un cluster di destinazione, dobbiamo iniziare a distribuirlo. Non tratteremo questi passaggi in dettaglio, puoi trovare le istruzioni nella documentazione. In generale, il processo si compone di diversi passaggi:
- Configura i repository MariaDB
- Installa i pacchetti MariaDB 10.3
- Configura i nodi per formare un cluster
All'inizio inizieremo con un solo nodo. Puoi configurarli tutti per formare un cluster, ma poi dovresti interromperli e usarne solo uno per il passaggio successivo. Quel nodo diventerà uno schiavo del cluster originale. Useremo mariabackup per eseguirne il provisioning. Quindi configureremo la replica.
Innanzitutto, dobbiamo creare una directory in cui memorizzeremo il backup:
mkdir /mnt/mariabackupQuindi eseguiamo il backup e lo creiamo nella directory preparata nel passaggio precedente. Assicurati di utilizzare l'utente e la password corretti per la connessione al database:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Successivamente, dobbiamo copiare i file di backup sul primo nodo nel secondo cluster. Abbiamo usato scp per questo, puoi usare quello che vuoi:rsync, netcat, qualsiasi cosa funzioni.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Dopo che il backup è stato copiato, dobbiamo prepararlo applicando i file di registro:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!In caso di errore potrebbe essere necessario eseguire nuovamente il backup. Se tutto è andato bene, possiamo rimuovere i vecchi dati e sostituirli con le informazioni di backup
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Vogliamo anche impostare il corretto proprietario dei file:
chown -R mysql.mysql /var/lib/mysql/Faremo affidamento su GTID per mantenere la replica coerente, quindi dobbiamo vedere quale è stato l'ultimo GTID applicato in questo backup. Tali informazioni possono essere trovate nel file xtrabackup_info che fa parte del backup:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Dovremo anche assicurarci che il nodo slave abbia i log binari abilitati insieme a "log_slave_updates". Idealmente, questo sarà abilitato su tutti i nodi nel secondo cluster, nel caso in cui il nodo "slave" si guasta e dovresti configurare la replica utilizzando un altro nodo nel cluster slave.
L'ultimo passo che dobbiamo fare prima di poter impostare la replica è creare un utente che useremo per eseguire la replica:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Questo è tutto ciò di cui abbiamo bisogno. Ora possiamo avviare il primo nodo nel secondo cluster, il nostro futuro schiavo:
galera_new_clusterUna volta avviato, possiamo accedere alla CLI di MySQL e configurarlo per diventare uno slave, utilizzando la posizione GITD che abbiamo trovato un paio di passaggi prima:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Una volta fatto, possiamo finalmente impostare la replica e avviarla:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)A questo punto abbiamo un Cluster Galera costituito da un nodo. Quel nodo è anche uno slave del cluster originale (in particolare, il suo master è il nodo 10.0.0.101). Per unirci ad altri nodi useremo SST ma per farlo funzionare prima dobbiamo assicurarci che la configurazione SST sia corretta - tieni presente che abbiamo appena sostituito tutti gli utenti nel nostro secondo cluster con il contenuto del cluster di origine. Quello che devi fare ora è assicurarti che la configurazione "wsrep_sst_auth" del secondo cluster corrisponda a quella del primo cluster. Una volta fatto, puoi iniziare i nodi rimanenti uno per uno e dovrebbero unirsi al nodo esistente (10.0.0.104), ottenere i dati su SST e formare il cluster Galera. Alla fine, dovresti ritrovarti con due cluster, tre nodi ciascuno, con un collegamento di replica asincrono su di essi (da 10.0.0.101 a 10.0.0.104 nel nostro esempio). Puoi confermare che la replica funziona controllando il valore di:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Come configurare la replica asincrona tra cluster MariaDB Galera utilizzando ClusterControl?
Al momento di questo blog, ClusterControl non ha la funzionalità per configurare la replica asincrona su più cluster, ci stiamo lavorando mentre lo digito. Tuttavia ClusterControl può essere di grande aiuto in questo processo:ti mostreremo come accelerare i laboriosi passaggi manuali utilizzando l'automazione fornita da ClusterControl.
Da quanto mostrato in precedenza, possiamo concludere che questi sono i passaggi generali da intraprendere quando si imposta la replica tra due cluster Galera:
- Distribuisci un nuovo cluster Galera
- Esegui il provisioning di un nuovo cluster utilizzando i dati di quello precedente
- Configura nuovo cluster (configurazione SST, log binari)
- Imposta la replica tra il vecchio e il nuovo cluster
I primi tre punti sono qualcosa che puoi fare facilmente usando ClusterControl anche adesso. Ti mostreremo come farlo.
Distribuire e fornire un nuovo cluster MariaDB Galera utilizzando ClusterControl
La situazione iniziale è simile:abbiamo un cluster attivo e funzionante. Dobbiamo allestire il secondo. Una delle funzionalità più recenti di ClusterControl è un'opzione per distribuire un nuovo cluster ed eseguirne il provisioning utilizzando i dati del backup. Questo è molto utile per creare ambienti di test, è anche un'opzione che useremo per eseguire il provisioning del nostro nuovo cluster per la configurazione della replica. Pertanto il primo passo che faremo è creare un backup utilizzando mariabackup:
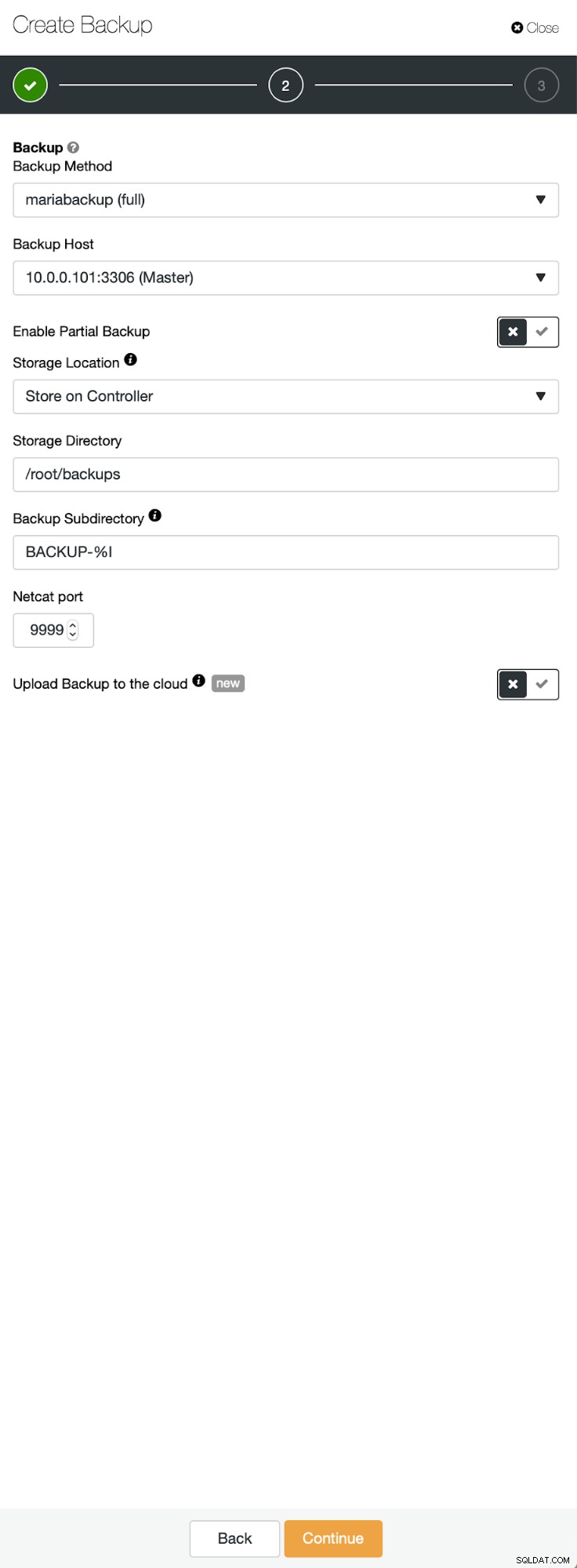
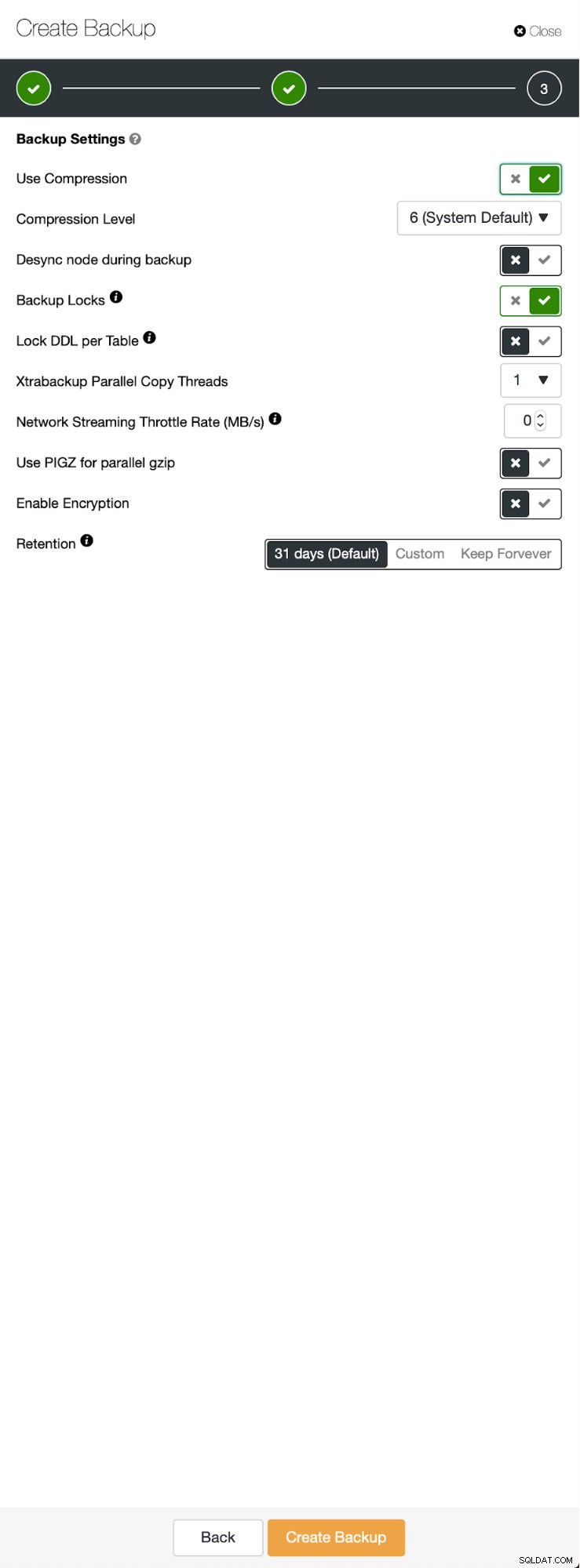
Tre passaggi in cui abbiamo scelto il nodo per rimuovere il backup. Questo nodo (10.0.0.101) diventerà un master. Deve avere i log binari abilitati. Nel nostro caso tutti i nodi hanno binlog abilitato ma in caso contrario è molto facile abilitarlo da ClusterControl - mostreremo i passaggi più avanti, quando lo faremo per il secondo cluster.
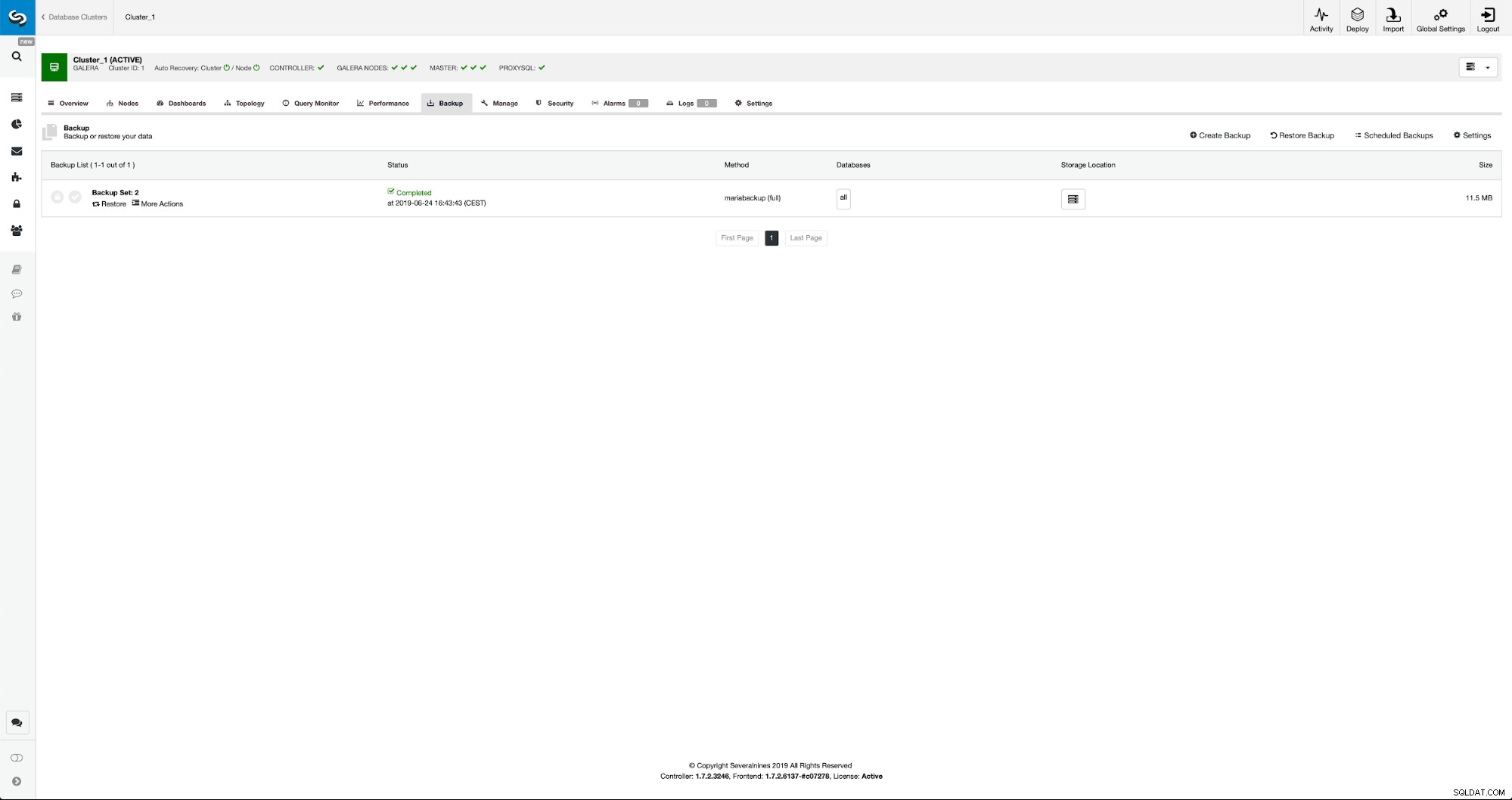
Una volta completato il backup, diventerà visibile nell'elenco. Possiamo quindi procedere e ripristinarlo:

Se lo volessimo, potremmo anche eseguire il Point-In-Time Recovery, ma nel nostro caso non ha molta importanza:una volta configurata la replica, tutte le transazioni richieste dai binlog verranno applicate al nuovo cluster.

Quindi scegliamo l'opzione per creare un cluster dal backup. Si apre un'altra finestra di dialogo:
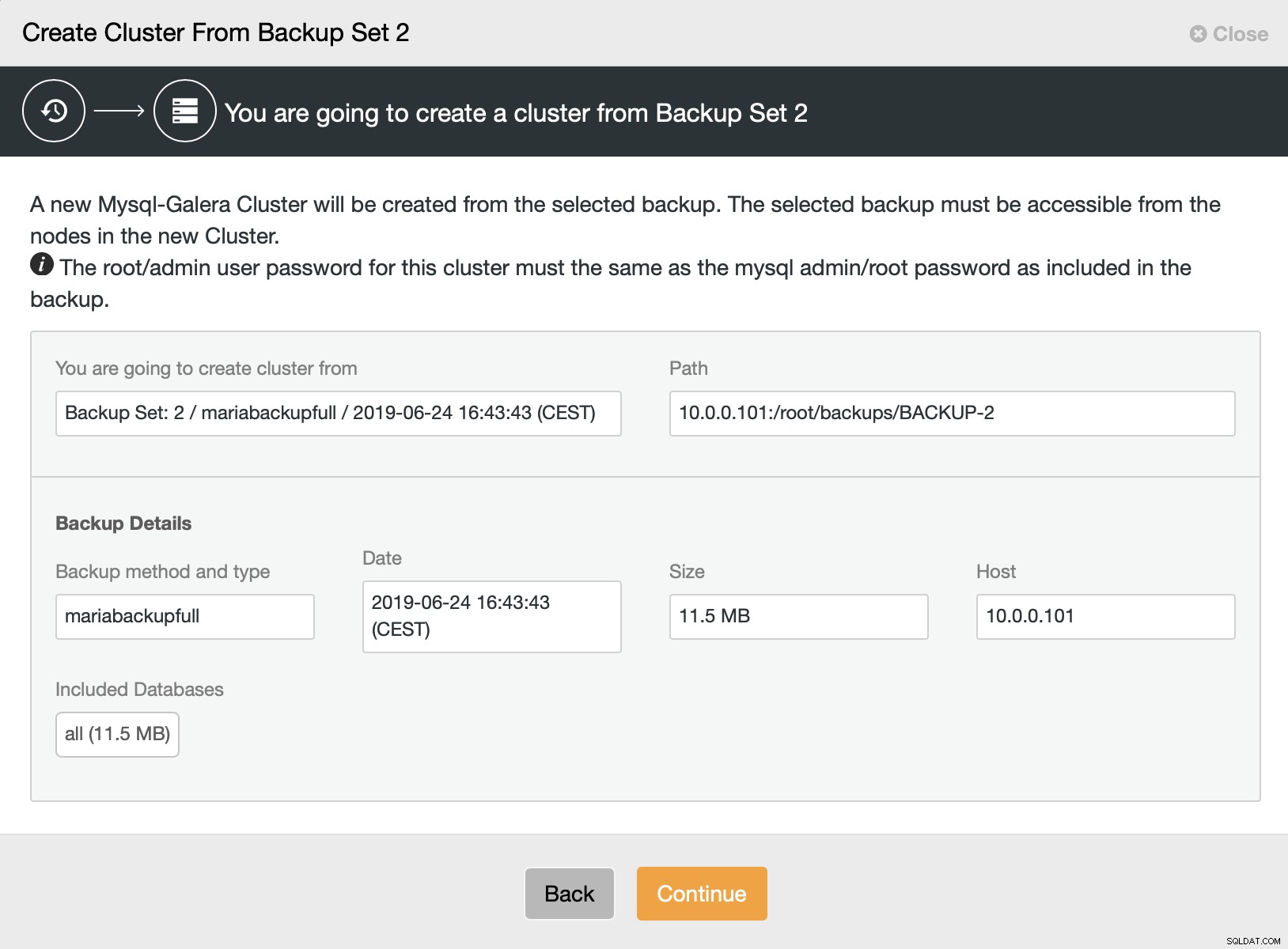
È una conferma quale backup verrà utilizzato, da quale host è stato prelevato il backup, quale metodo è stato utilizzato per crearlo e alcuni metadati per verificare se il backup sembra corretto.
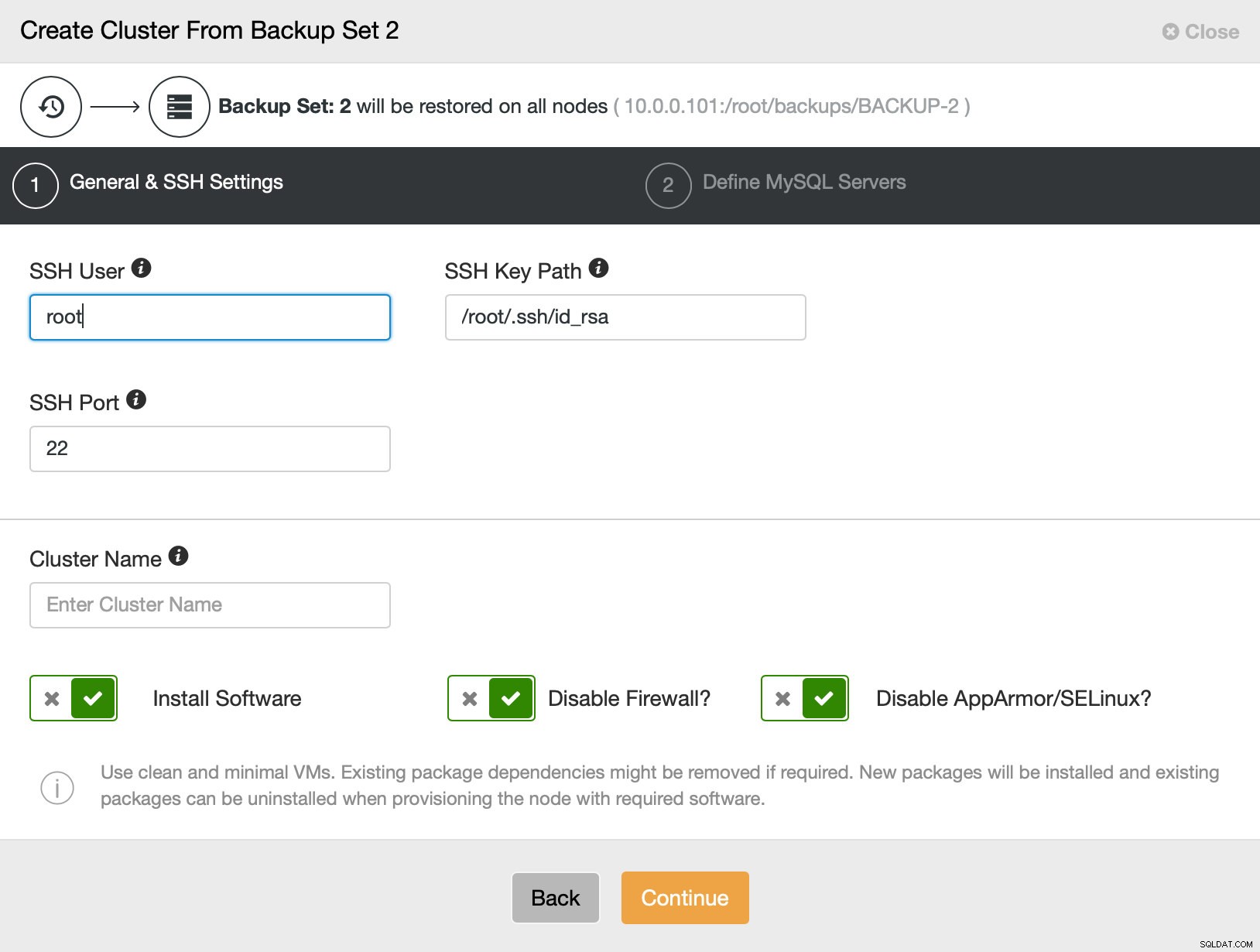
Quindi passiamo sostanzialmente alla normale procedura guidata di distribuzione in cui dobbiamo definire la connettività SSH tra l'host ClusterControl e i nodi su cui distribuire il cluster (requisito per ClusterControl) e, nel secondo passaggio, fornitore, versione, password e nodi su cui distribuire su:
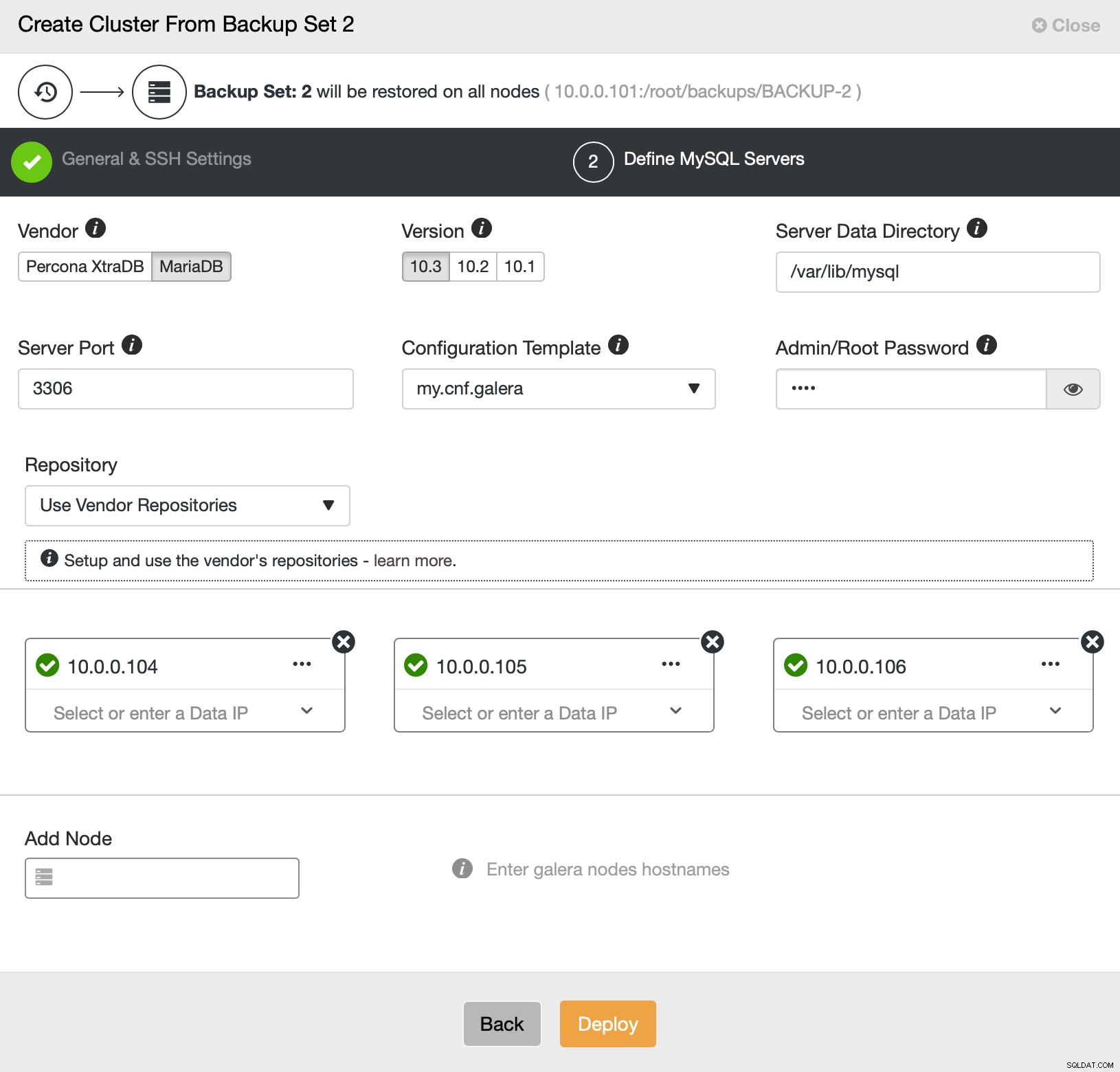
Questo è tutto per quanto riguarda la distribuzione e il provisioning. ClusterControl imposterà il nuovo cluster e ne eseguirà il provisioning utilizzando i dati di quello precedente.
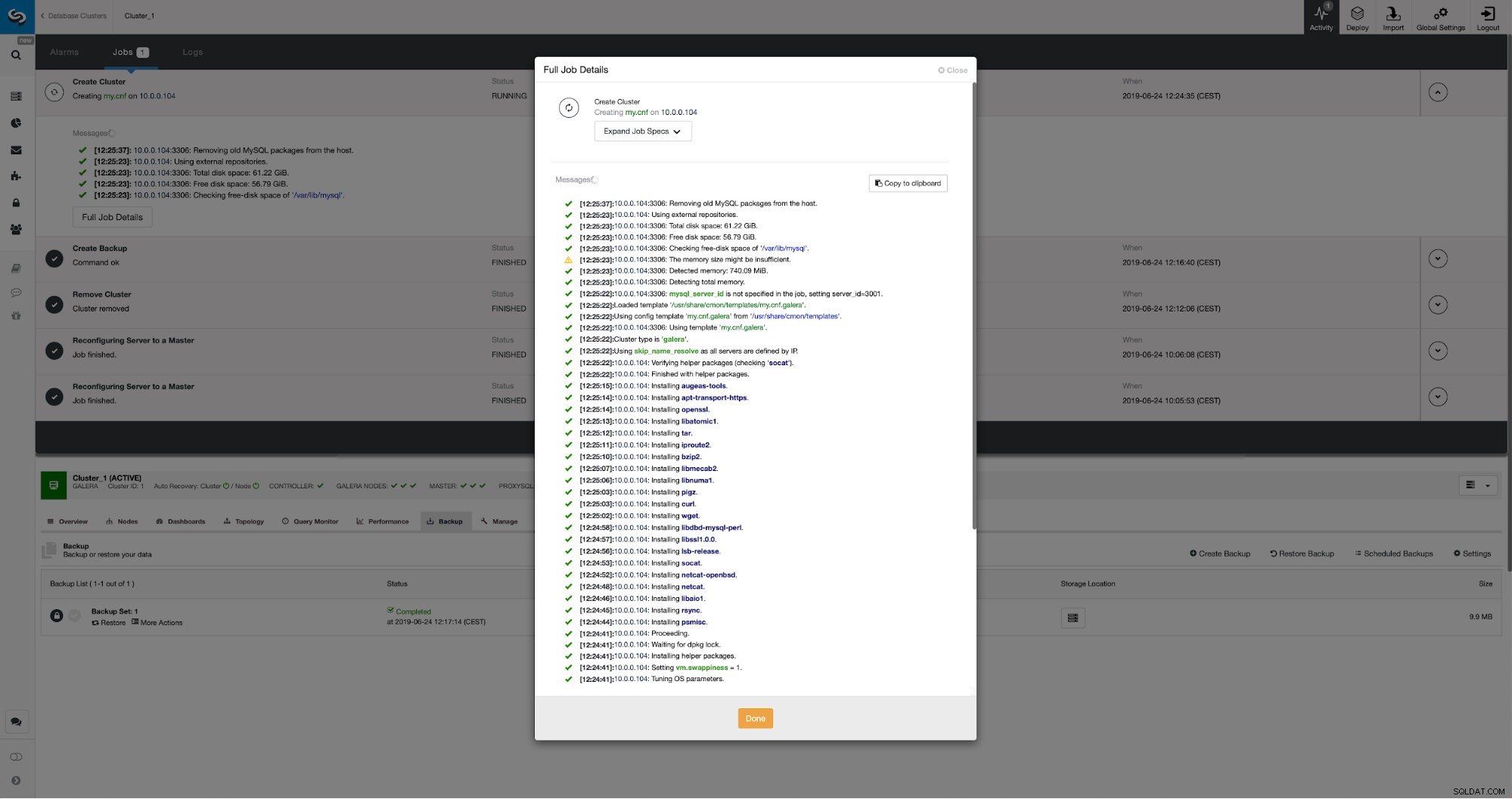
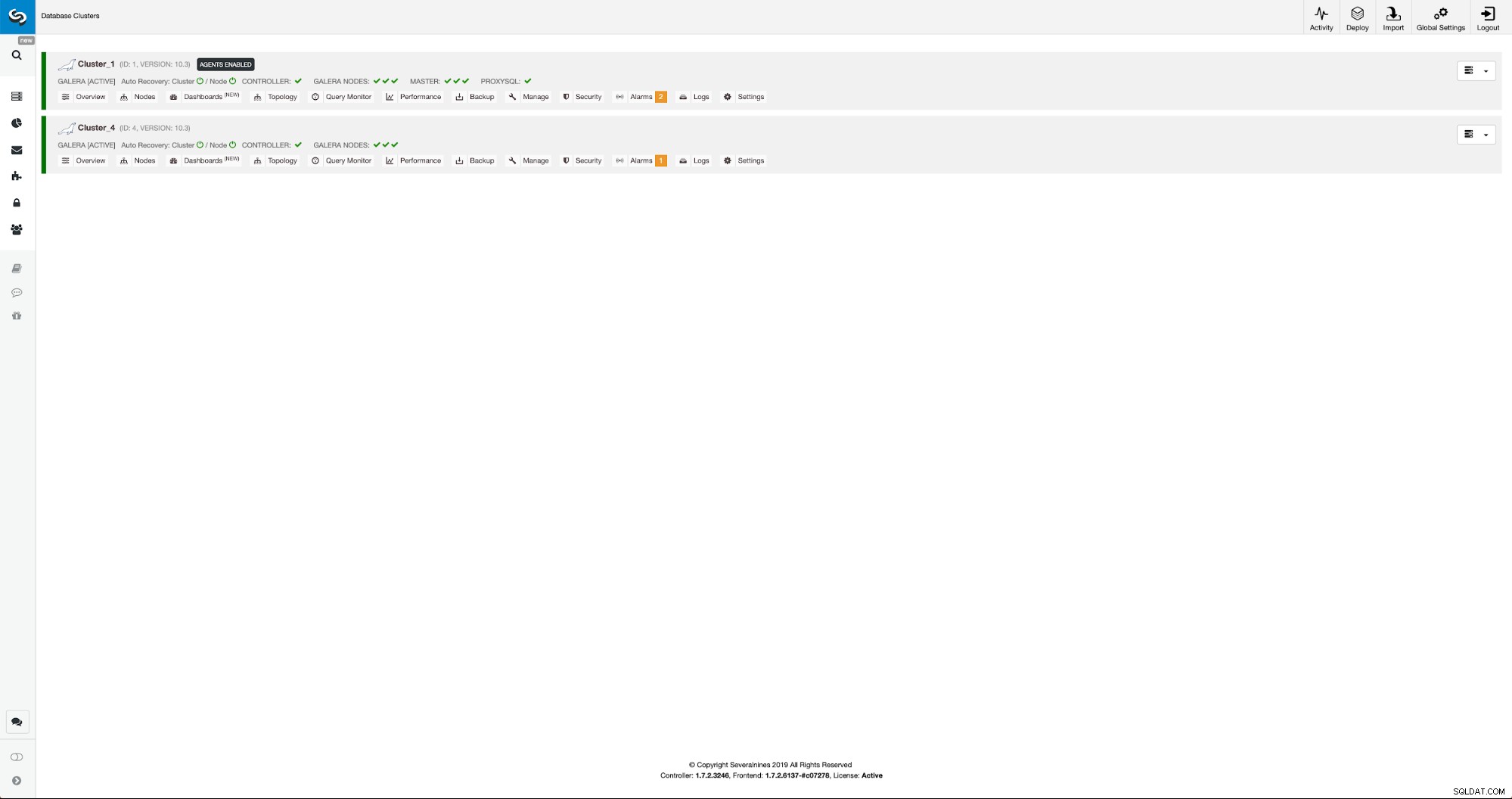
Possiamo monitorare i progressi nella scheda attività. Una volta completato, il secondo cluster verrà visualizzato nell'elenco dei cluster in ClusterControl.
Riconfigurazione del Nuovo Cluster tramite ClusterControl
Ora dobbiamo riconfigurare il cluster:abiliteremo i log binari. Nel processo manuale abbiamo dovuto apportare modifiche alla configurazione wsrep_sst_auth e anche le voci di configurazione nelle sezioni [mysqldump] e [xtrabackup] della configurazione. Tali impostazioni possono essere trovate nel file secrets-backup.cnf. Questa volta non è necessario poiché ClusterControl ha generato nuove password per il cluster e configurato correttamente i file. Ciò che è importante tenere a mente, tuttavia, se dovessi modificare la password dell'utente 'backupuser'@'127.0.0.1' nel cluster originale, dovrai apportare modifiche alla configurazione anche nel secondo cluster per rispecchiarlo come modifiche in il primo cluster verrà replicato nel secondo cluster.
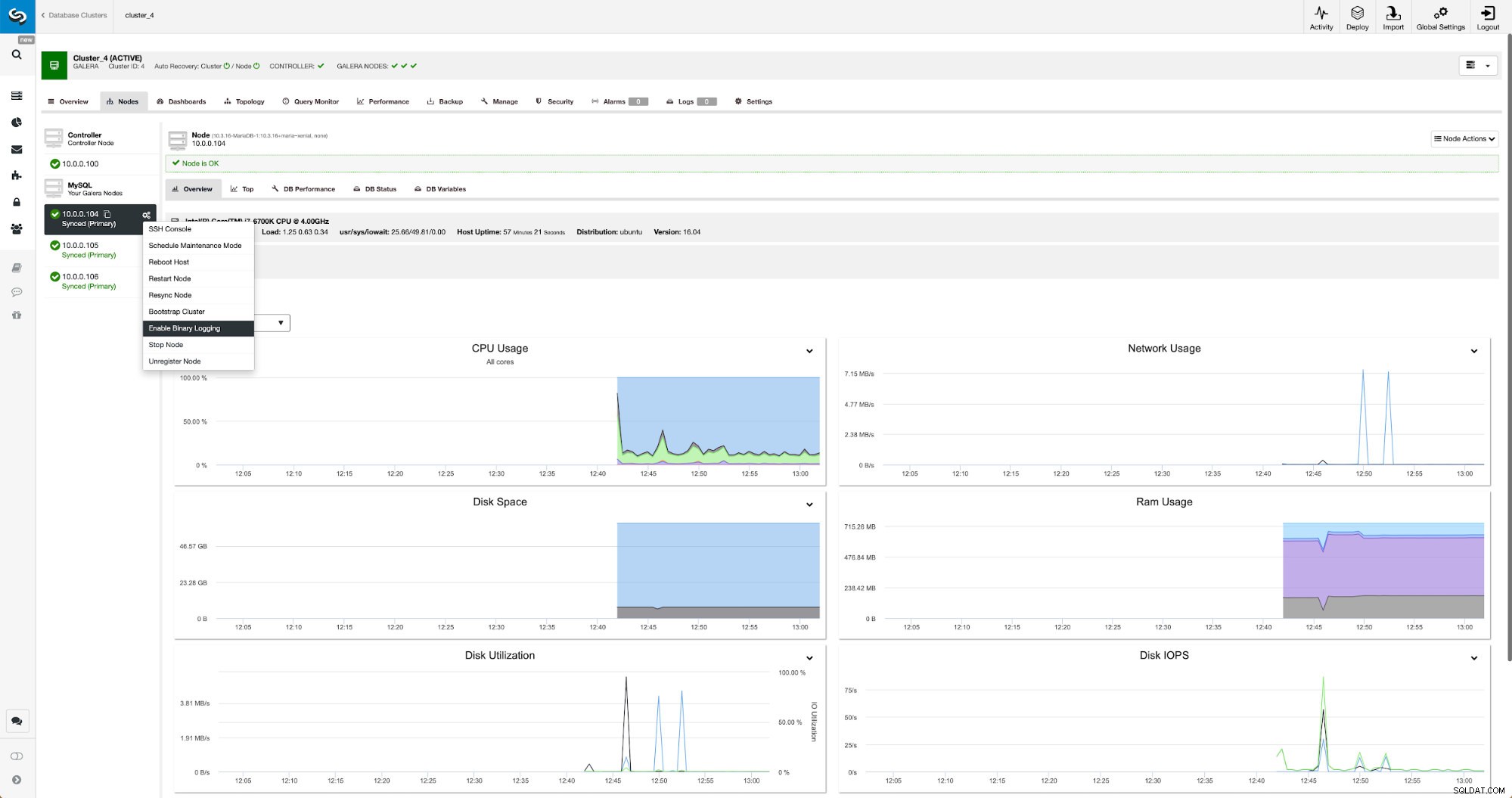
I log binari possono essere abilitati dalla sezione Nodi. Devi selezionare nodo per nodo ed eseguire il lavoro "Abilita registrazione binaria". Ti verrà presentata una finestra di dialogo:
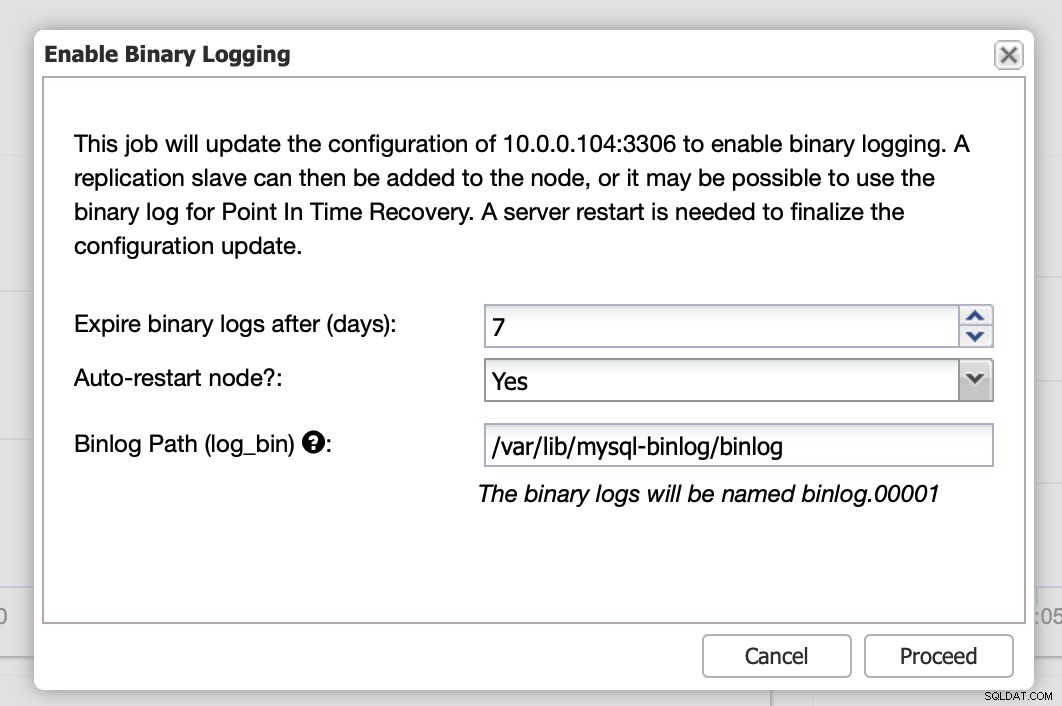
Qui puoi definire per quanto tempo desideri conservare i log, dove devono essere archiviati e se ClusterControl deve riavviare il nodo per poter applicare le modifiche:la configurazione del log binario non è dinamica e MariaDB deve essere riavviato per applicare tali modifiche.
Quando le modifiche saranno completate, vedrai tutti i nodi contrassegnati come "master", il che significa che quei nodi hanno il log binario abilitato e possono agire come master.
Se non abbiamo già creato un utente di replica, dobbiamo farlo. Nel primo cluster dobbiamo andare su Gestisci -> Schemi e Utenti:
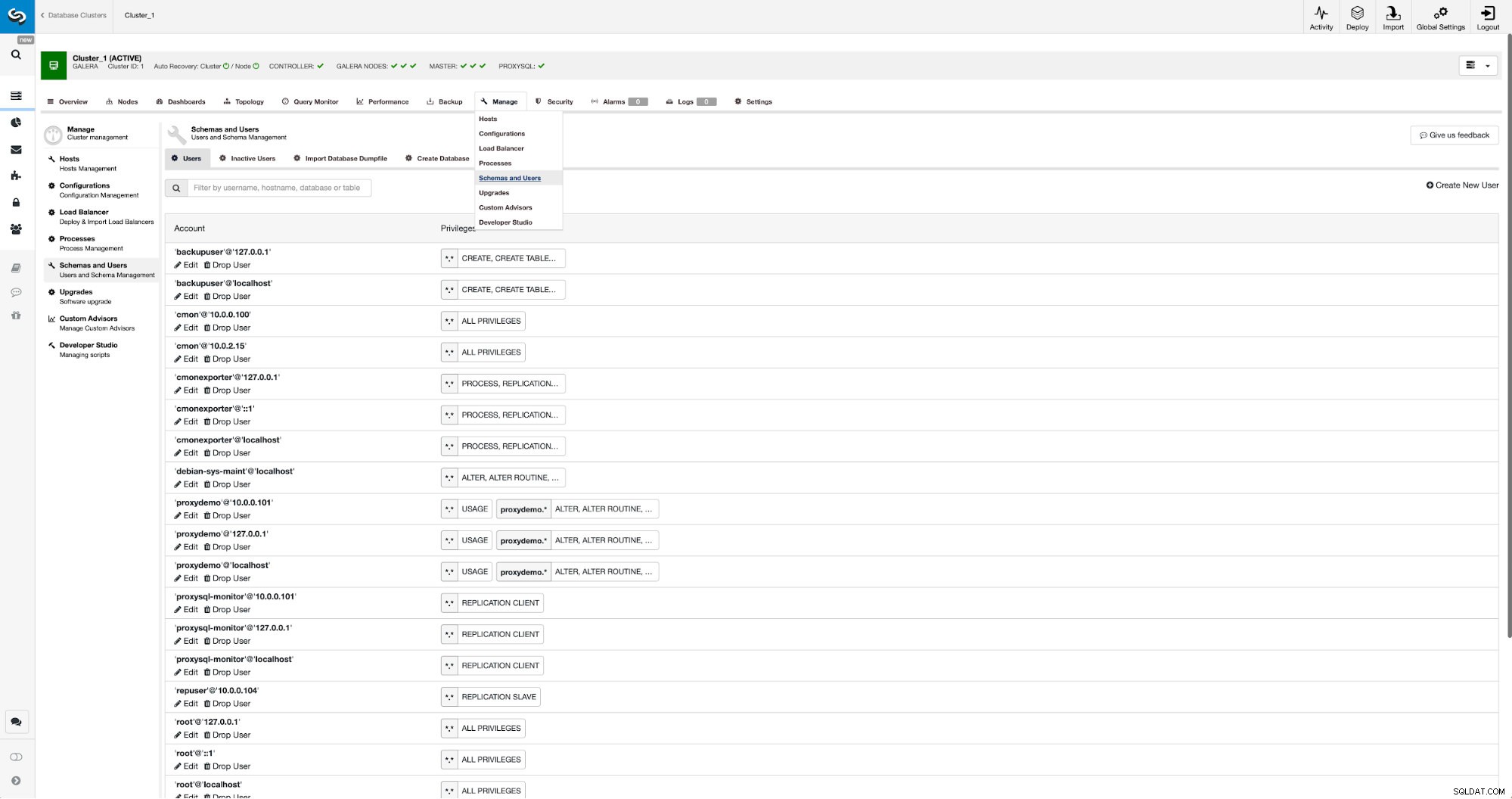
Sul lato destro abbiamo un'opzione per creare un nuovo utente:
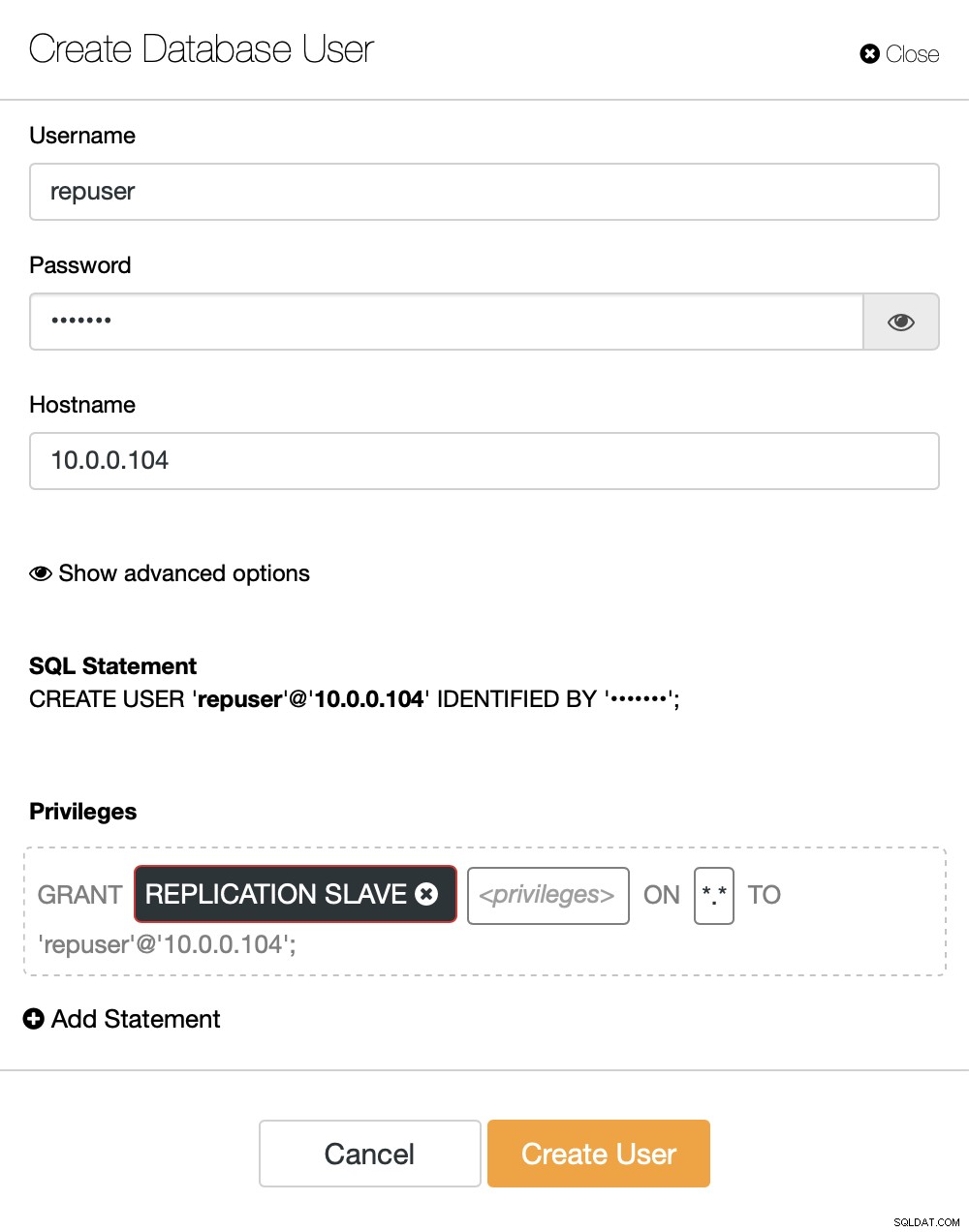
Questo conclude la configurazione richiesta per impostare la replica.
Configurazione della replica tra cluster utilizzando ClusterControl
Come abbiamo affermato, stiamo lavorando per automatizzare questa parte. Attualmente deve essere fatto manualmente. Come forse ricorderai, abbiamo bisogno della posizione GITD del nostro backup e quindi eseguiamo un paio di comandi usando MySQL CLI. I dati GTID sono disponibili nel backup. ClusterControl crea il backup utilizzando xbstream/mbstream e lo comprime in seguito. Il nostro backup è archiviato sull'host ClusterControl dove non abbiamo accesso al binario mbstream. Puoi provare a installarlo o puoi copiare il file di backup nella posizione in cui è disponibile tale binario:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Fatto ciò, su 10.0.0.104 vogliamo controllare il contenuto del file xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Infine, configuriamo la replica e la avviamo:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Questo è tutto:abbiamo appena configurato la replica asincrona tra due cluster MariaDB Galera utilizzando ClusterControl. Come avrai potuto vedere, ClusterControl è stato in grado di automatizzare la maggior parte dei passaggi necessari per configurare questo ambiente.