Perché scegliere la replica MySQL?
Prima alcune nozioni di base sulla tecnologia di replica. La replica di MySQL non è complicata! È facile da implementare, monitorare e ottimizzare poiché ci sono varie risorse che puoi sfruttare:Google è una di queste. MySQL Replication non contiene molte variabili di configurazione da ottimizzare. Gli errori logici di SQL_THREAD e IO_THREAD non sono così difficili da capire e correggere. MySQL Replication è molto popolare al giorno d'oggi e offre un modo semplice per implementare l'elevata disponibilità del database. Funzionalità potenti come GTID (Global Transaction Identifier) invece della posizione del registro binario vecchio stile o la replica semi-sincrona senza perdita di dati lo rendono più robusto.
Come abbiamo visto in un post precedente, la latenza di rete è una grande sfida quando si seleziona una soluzione ad alta disponibilità. L'utilizzo di MySQL Replication offre il vantaggio di non essere così sensibile alla latenza. Non implementa alcuna replica basata sulla certificazione, a differenza di Galera Cluster utilizza tecniche di comunicazione di gruppo e ordinamento delle transazioni per ottenere la replica sincrona. Pertanto, non è necessario che tutti i nodi debbano certificare un writeset e non è necessario attendere prima di un commit sull'altro slave o replica.
La scelta della replica MySQL tradizionale con l'approccio primario-secondario asincrono fornisce velocità quando si tratta di gestire le transazioni dall'interno del proprio master; non è necessario attendere che gli slave sincronizzino o effettuino transazioni. La configurazione in genere ha un primario (master) e uno o più secondari (slave). Quindi, è un sistema di condivisione nulla, in cui tutti i server hanno una copia completa dei dati per impostazione predefinita. Ovviamente ci sono degli svantaggi. L'integrità dei dati può essere un problema se gli slave non sono riusciti a replicare a causa di errori di thread SQL e I/O o di arresti anomali. In alternativa, per risolvere i problemi di integrità dei dati, puoi scegliere di implementare la replica di MySQL in modo semi-sincrono (o chiamata replica semi-sincronizzazione senza perdita di dati in MySQL 5.7). Come funziona, il master deve attendere che una replica riconosca tutti gli eventi della transazione. Ciò significa che deve terminare le sue scritture su un registro di inoltro e svuotare il disco prima che venga rispedito al master con una risposta ACK. Con la replica semisincrona abilitata, i thread o le sessioni nel master devono attendere il riconoscimento da una replica. Una volta ottenuta una risposta ACK dalla replica, può quindi eseguire il commit della transazione. L'illustrazione seguente mostra come MySQL gestisce la replica semisincrona.
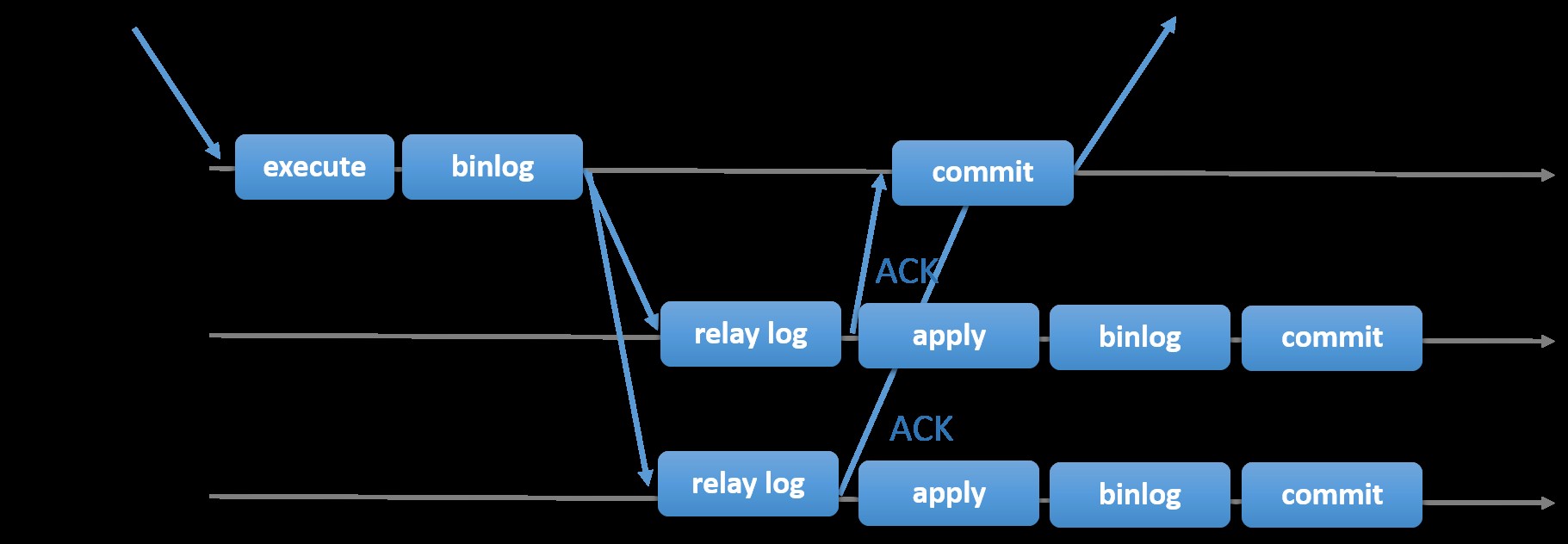 Immagine per gentile concessione della documentazione MySQL
Immagine per gentile concessione della documentazione MySQL Con questa implementazione, tutte le transazioni commesse vengono già replicate su almeno uno slave in caso di crash del master. Sebbene semi-sincrono non rappresenti di per sé una soluzione ad alta disponibilità, ma è un componente per la tua soluzione. È meglio che tu conosca le tue esigenze e metta a punto la tua implementazione di semi-sincronizzazione di conseguenza. Quindi, se una certa perdita di dati è accettabile, puoi invece utilizzare la tradizionale replica asincrona.
La replica basata su GTID è utile per il DBA in quanto semplifica l'attività di failover, soprattutto quando uno slave viene indirizzato a un altro master o nuovo master. Ciò significa che con un semplice MASTER_AUTO_POSITION=1 dopo aver impostato l'host corretto e le credenziali di replica, inizierà a replicare dal master senza la necessità di trovare e specificare le posizioni x e y del registro binario corrette. L'aggiunta del supporto della replica parallela aumenta anche i thread di replica poiché aggiunge velocità per elaborare gli eventi dal registro di inoltro.
Pertanto, MySQL Replication è un componente ideale rispetto ad altre soluzioni HA se soddisfa le tue esigenze.
Topologie per la replica MySQL
L'implementazione di MySQL Replication in un ambiente multicloud con GCP (Google Cloud Platform) e AWS è sempre lo stesso approccio se devi replicare in locale.
Esistono varie topologie che puoi configurare e implementare.
Master con replica slave (replica singola)
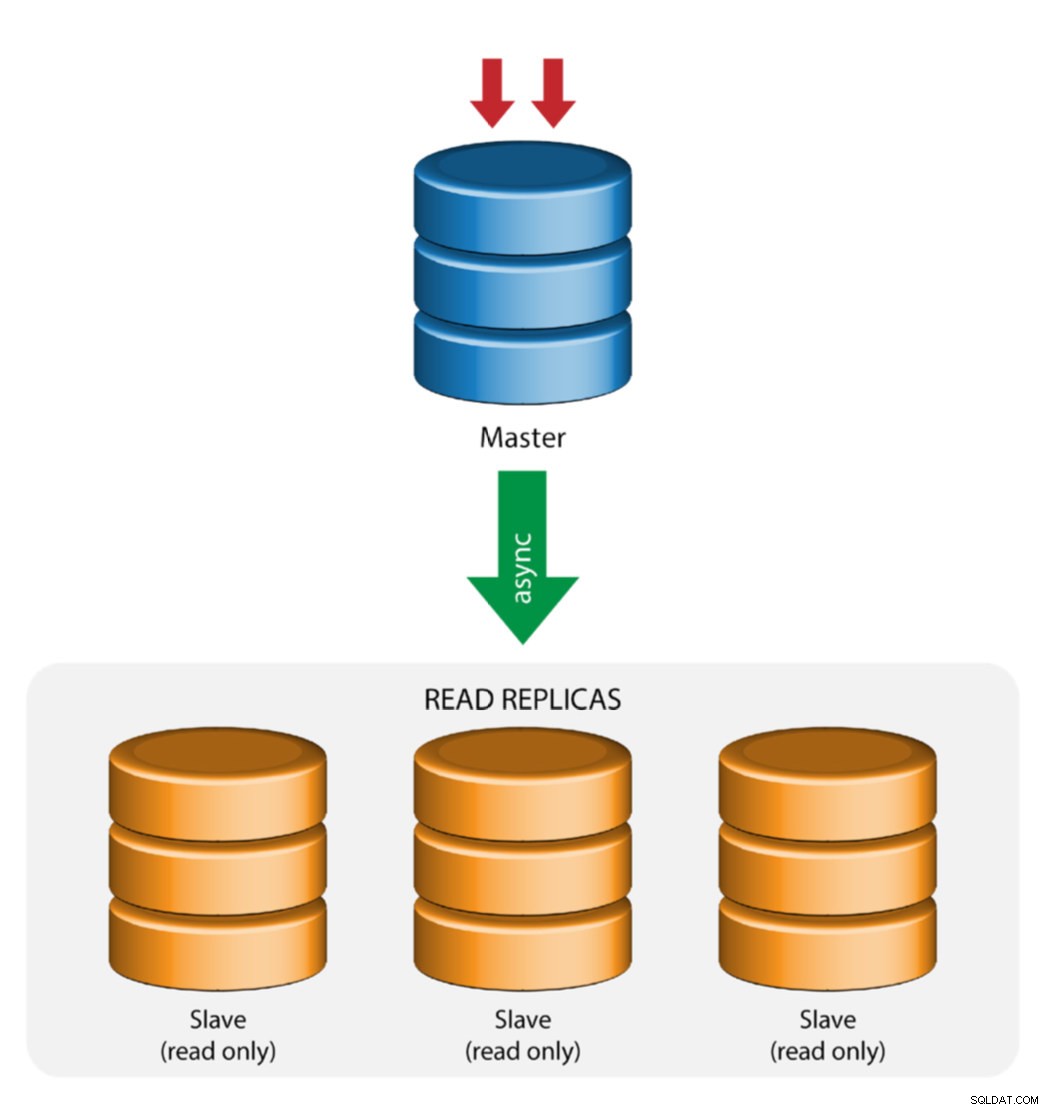
Questa è la topologia di replica MySQL più semplice. Un master riceve scritture, uno o più slave replicano dallo stesso master tramite replica asincrona o semisincrona. Se il master designato va giù, lo slave più aggiornato deve essere promosso come nuovo master. Gli slave rimanenti riprendono la replica dal nuovo master.
Master con Relè Slave (Replica a Catena)
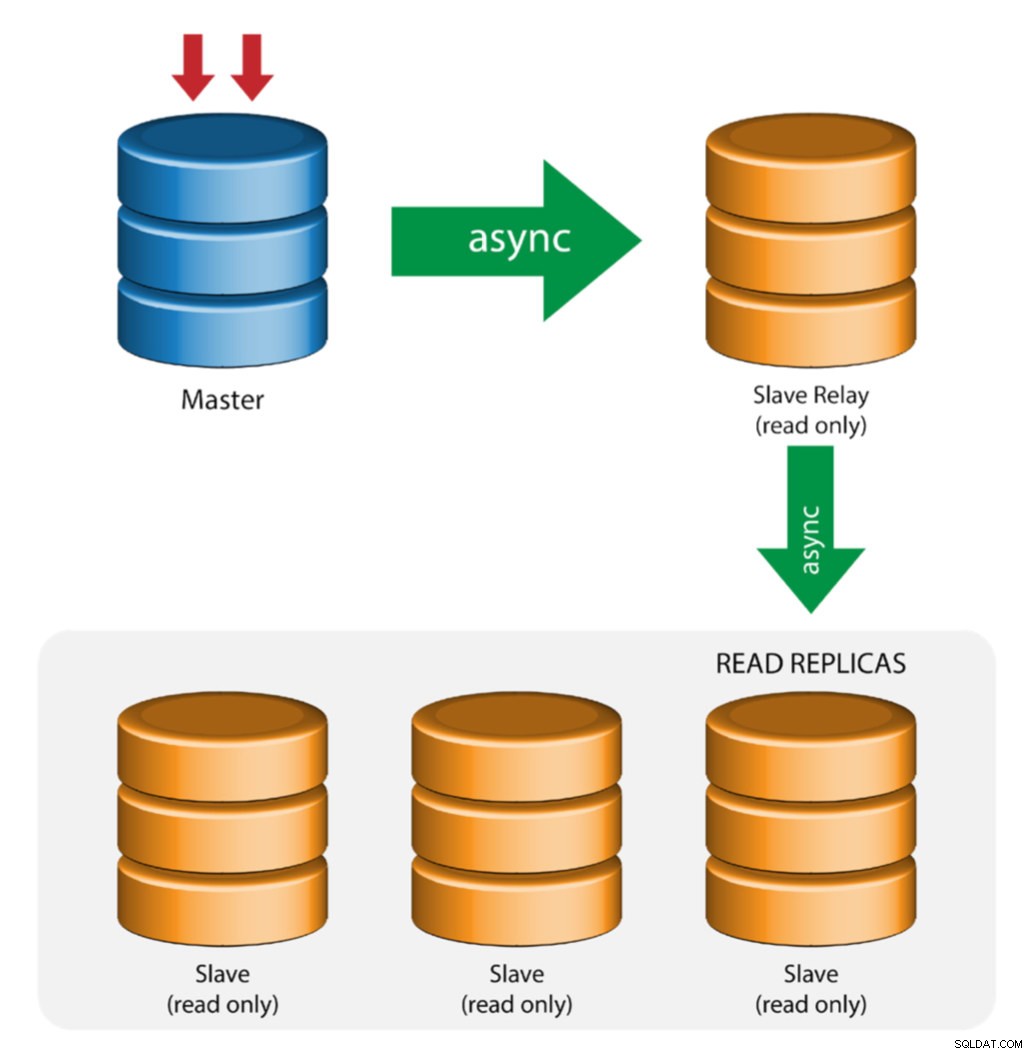
Questa configurazione utilizza un master intermedio che funge da relè per gli altri slave nella catena di replica. Quando ci sono molti slave collegati a un master, l'interfaccia di rete del master può sovraccaricarsi. Questa topologia consente alle repliche di lettura di eseguire il pull del flusso di replica dal server di inoltro per scaricare il server master. Sul server di inoltro slave, è necessario abilitare la registrazione binaria e log_slave_updates, per cui gli aggiornamenti ricevuti dal server slave dal server master vengono registrati nel registro binario dello slave.
L'uso del relè slave ha i suoi problemi:
- log_slave_updates ha qualche penalizzazione delle prestazioni.
- Il ritardo di replica sul server di inoltro slave genererà un ritardo su tutti i suoi slave.
- Le transazioni non autorizzate sul server di inoltro slave infetteranno tutti i suoi slave.
- Se un server di inoltro slave si guasta e non stai utilizzando GTID, tutti i suoi slave smettono di replicarsi e devono essere reinizializzati.
Master con Master attivo (replica circolare)
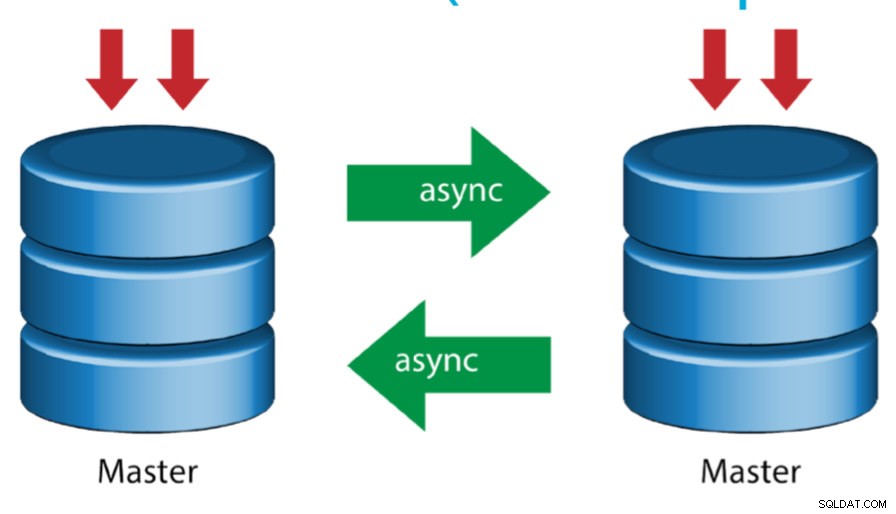
Conosciuta anche come topologia ad anello, questa configurazione richiede due o più server MySQL che fungono da master. Tutti i master ricevono scritture e generano binlog con alcuni avvertimenti:
- È necessario impostare l'offset di incremento automatico su ciascun server per evitare collisioni di chiavi primarie.
- Non esiste una risoluzione dei conflitti.
- La replica MySQL attualmente non supporta alcun protocollo di blocco tra master e slave per garantire l'atomicità di un aggiornamento distribuito su due server diversi.
- La pratica comune consiste nel scrivere solo su un master e l'altro master funge da nodo hot-standby. Tuttavia, se hai slave al di sotto di quel livello, devi passare manualmente al nuovo master se il master designato si guasta.
- ClusterControl supporta questa topologia (non consigliamo più writer in una configurazione di replica). Vedi questo blog precedente su come eseguire la distribuzione con ClusterControl.
Master con backup master (replica multipla)
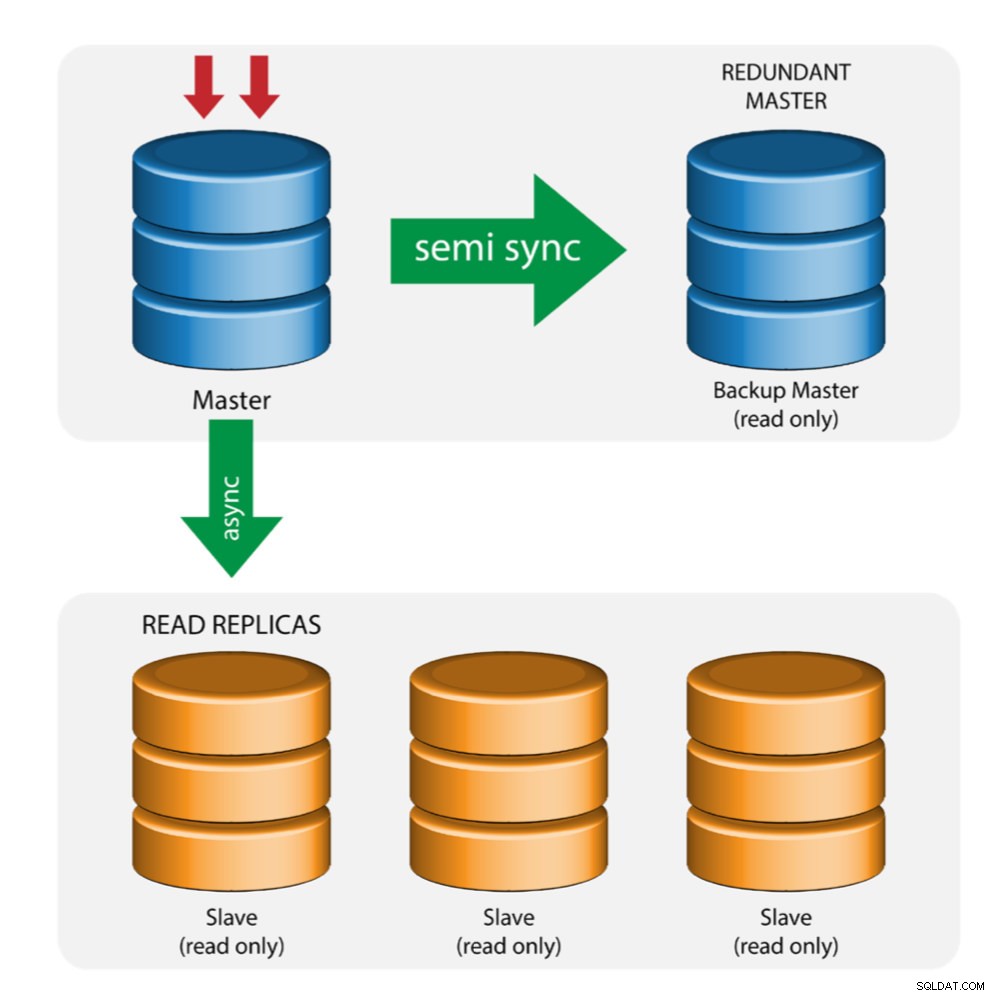
Il master invia le modifiche a un master di backup ea uno o più slave. La replica semisincrona viene utilizzata tra master e master di backup. Il master invia l'aggiornamento al master di backup e attende il commit della transazione. Il master di backup riceve gli aggiornamenti, scrive nel registro di inoltro e scarica su disco. Il master di backup conferma quindi la ricezione della transazione al master e procede con il commit della transazione. La replica semi-sincronizzazione ha un impatto sulle prestazioni, ma il rischio di perdita di dati è ridotto al minimo.
Questa topologia funziona bene quando si esegue il failover del master nel caso in cui il master si interrompa. Il master di backup funge da server warm-standby in quanto ha la più alta probabilità di avere dati aggiornati rispetto ad altri slave.
Più master a singolo slave (replica multi-sorgente)
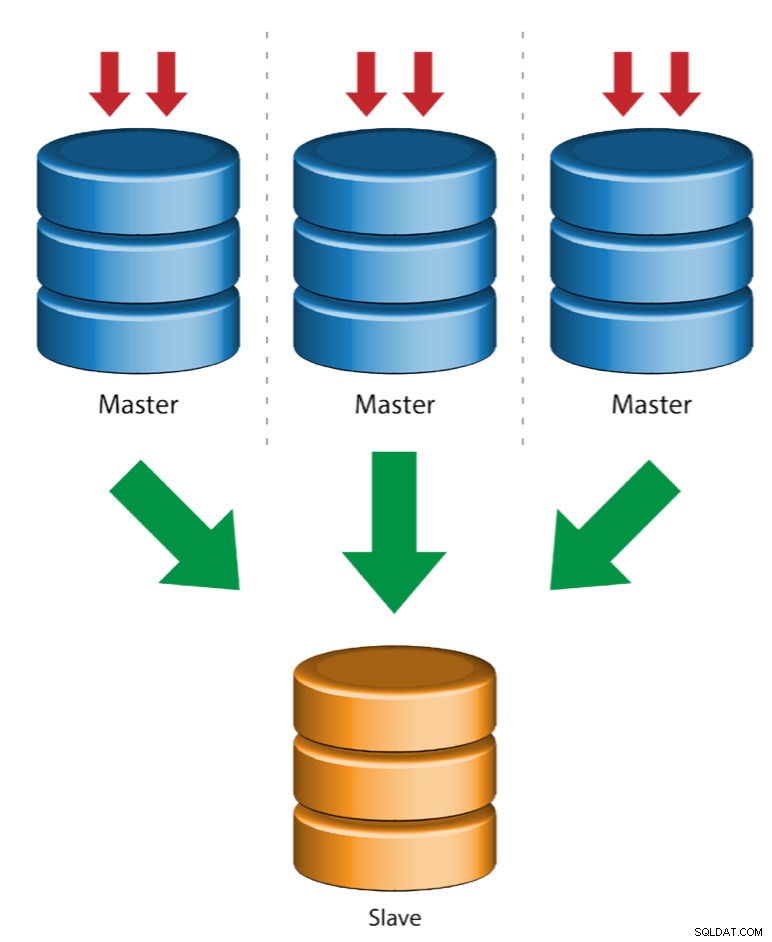
La replica multi-origine consente a uno slave di replica di ricevere transazioni da più origini contemporaneamente. La replica multi-origine può essere utilizzata per eseguire il backup di più server su un unico server, per unire frammenti di tabelle e consolidare i dati da più server in un unico server.
MySQL e MariaDB hanno implementazioni diverse della replica multi-sorgente, in cui MariaDB deve avere GTID con gtid-domain-id configurato per distinguere le transazioni di origine mentre MySQL utilizza un canale di replica separato per ogni master da cui lo slave replica. In MySQL, i master in una topologia di replica multi-sorgente possono essere configurati per utilizzare la replica basata sull'identificatore di transazione globale (GTID) o la replica basata sulla posizione del log binario.
Maggiori informazioni sulla replica multi-sorgente di MariaDB sono disponibili in questo post del blog. Per MySQL, fare riferimento alla documentazione di MySQL.
Galera con replica slave (replica ibrida)
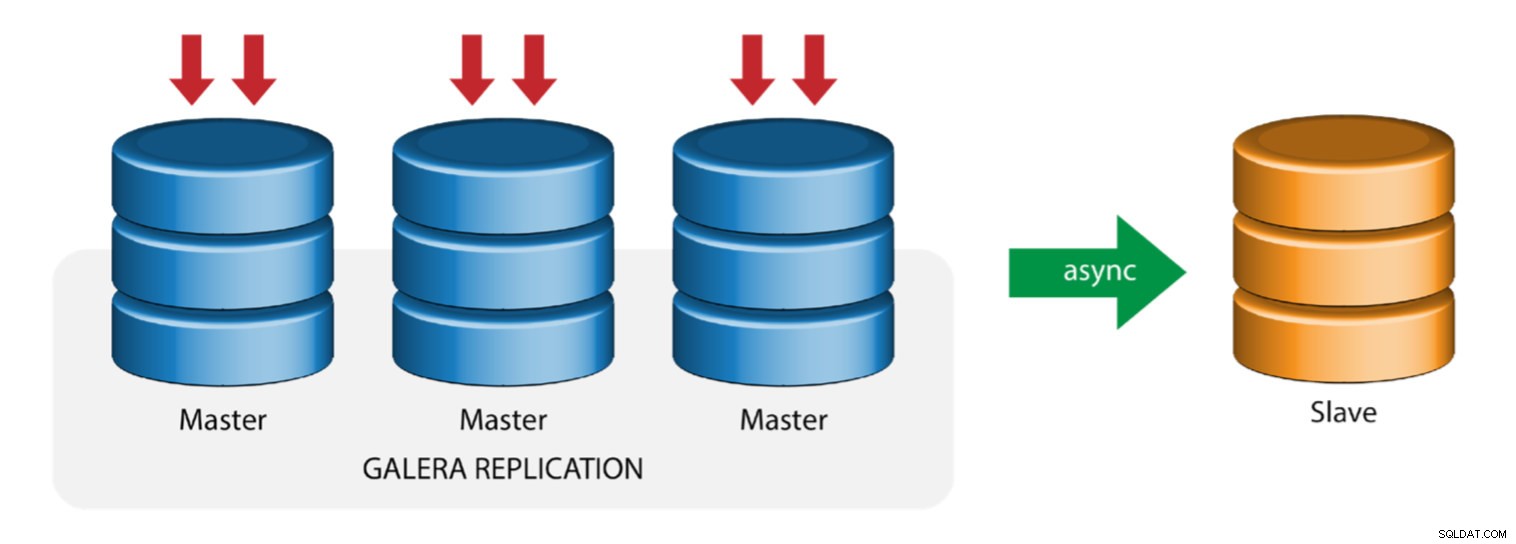
La replica ibrida è una combinazione di replica asincrona MySQL e replica virtualmente sincrona fornita da Galera. L'implementazione è ora semplificata con l'implementazione di GTID nella replica MySQL, dove la configurazione e l'esecuzione del failover principale sono diventate un processo semplice sul lato slave.
Le prestazioni del cluster Galera sono veloci quanto il nodo più lento. La presenza di uno slave di replica asincrono può ridurre al minimo l'impatto sul cluster se si inviano query di tipo OLAP/di reporting a esecuzione prolungata allo slave o se si eseguono lavori pesanti che richiedono blocchi come mysqldump. Lo slave può anche fungere da backup live per il ripristino di emergenza in loco e fuori sede.
La replica ibrida è supportata da ClusterControl ed è possibile distribuirla direttamente dall'interfaccia utente di ClusterControl. Per ulteriori informazioni su come eseguire questa operazione, leggere i post del blog:Replica ibrida con MySQL 5.6 e Replica ibrida con MariaDB 10.x.
Preparazione delle piattaforme GCP e AWS
Il problema del "mondo reale"
In questo blog, dimostreremo e utilizzeremo la topologia "Replica multipla" in cui le istanze su due diverse piattaforme di cloud pubblico comunicheranno utilizzando la replica MySQL in diverse regioni e in diverse zone di disponibilità. Questo scenario si basa su un problema del mondo reale in cui un'organizzazione desidera architettare la propria infrastruttura su più piattaforme cloud per scalabilità, ridondanza, resilienza/tolleranza ai guasti. Concetti simili si applicherebbero a MongoDB o PostgreSQL.
Consideriamo un'organizzazione statunitense, con una filiale all'estero nel sud est asiatico. Il nostro traffico è elevato all'interno della regione asiatica. La latenza deve essere bassa quando si occupa di scritture e letture, ma allo stesso tempo la regione con sede negli Stati Uniti può anche recuperare i record provenienti dal traffico con sede in Asia.
Il flusso dell'architettura cloud
In questa sezione parlerò della progettazione architettonica. In primo luogo, vogliamo offrire un livello altamente sicuro per il quale i nostri nodi Google Compute e AWS EC2 possono comunicare, aggiornare o installare pacchetti da Internet, sicuro, altamente disponibile nel caso in cui una AZ (Availability Zone) si interrompa, possono replicare e comunicare con un'altra piattaforma cloud su un livello protetto. Vedi l'immagine qui sotto per l'illustrazione:

Sulla base dell'illustrazione sopra, sotto la piattaforma AWS, tutti i nodi sono in esecuzione su diverse zone di disponibilità. Dispone di una sottorete privata e pubblica per la quale tutti i nodi di calcolo si trovano su una sottorete privata. Quindi, può uscire da Internet per estrarre e aggiornare i suoi pacchetti di sistema quando necessario. Ha un gateway VPN per il quale deve interagire con GCP in quel canale, bypassando Internet ma attraverso un canale sicuro e privato. Come per GCP, tutti i nodi di calcolo si trovano in zone di disponibilità diverse, utilizzano NAT Gateway per aggiornare i pacchetti di sistema quando necessario e utilizzano la connessione VPN per interagire con i nodi AWS che sono ospitati in una regione diversa, ad esempio Asia Pacifico (Singapore). D'altra parte, la regione con sede negli Stati Uniti è ospitata sotto us-east1. Per accedere ai nodi, un nodo nell'architettura funge da bastion-node per il quale lo utilizzeremo come jump host e installeremo ClusterControl. Questo sarà affrontato più avanti in questo blog.
Configurazione di ambienti GCP e AWS
Quando registri il tuo primo account GCP, Google fornisce un account VPC (Virtual Private Cloud) predefinito. Pertanto, è meglio creare un VPC separato rispetto a quello predefinito e personalizzarlo in base alle proprie esigenze.
Il nostro obiettivo qui è posizionare i nodi di calcolo in sottoreti private o i nodi non verranno configurati con IPv4 pubblico. Pertanto, entrambi i cloud pubblici devono essere in grado di comunicare tra loro. I nodi di calcolo AWS e GCP funzionano con CIDR diversi come accennato in precedenza. Quindi, ecco i seguenti CIDR:
Nodi di calcolo AWS: 172.21.0.0/16
Nodi di calcolo GCP: 10.142.0.0/20
In questa configurazione AWS, abbiamo allocato tre sottoreti che non hanno gateway Internet ma gateway NAT; e una sottorete che dispone di un gateway Internet. Ognuna di queste sottoreti è ospitata individualmente in diverse zone di disponibilità (AZ).
ap-southeast-1a =172.21.1.0/24
ap-southeast-1b =172.21.8.0/24
ap-southeast-1c =172.21.24.0/24
In GCP, viene utilizzata la sottorete predefinita creata in un VPC in us-east1 che è 10.142.0.0/20 CIDR. Quindi, questi sono i passaggi che puoi seguire per configurare la tua piattaforma cloud multi-pubblico.
-
Per questo esercizio, ho creato un VPC nella regione us-east1 con la seguente sottorete di 10.142.0.0/20. Vedi sotto:

-
Riserva un IP statico. Questo è l'IP che imposteremo come gateway del cliente in AWS
-
Poiché disponiamo di sottoreti (fornite come subnet-us-east1 ), vai a GCP -> Rete VPC -> Reti VPC e seleziona il VPC che hai creato e vai a Regole firewall . In questa sezione, aggiungi le regole specificando il tuo ingresso e uscita. Fondamentalmente, queste sono le regole in entrata/in uscita in AWS o nel tuo firewall per le connessioni in entrata e in uscita. In questa configurazione, ho aperto tutti i protocolli TCP dall'intervallo CIDR impostato nel mio AWS e GCP VPC per renderlo più semplice ai fini di questo blog. Quindi, questo non è il modo ottimale per la sicurezza. Vedi immagine sotto:
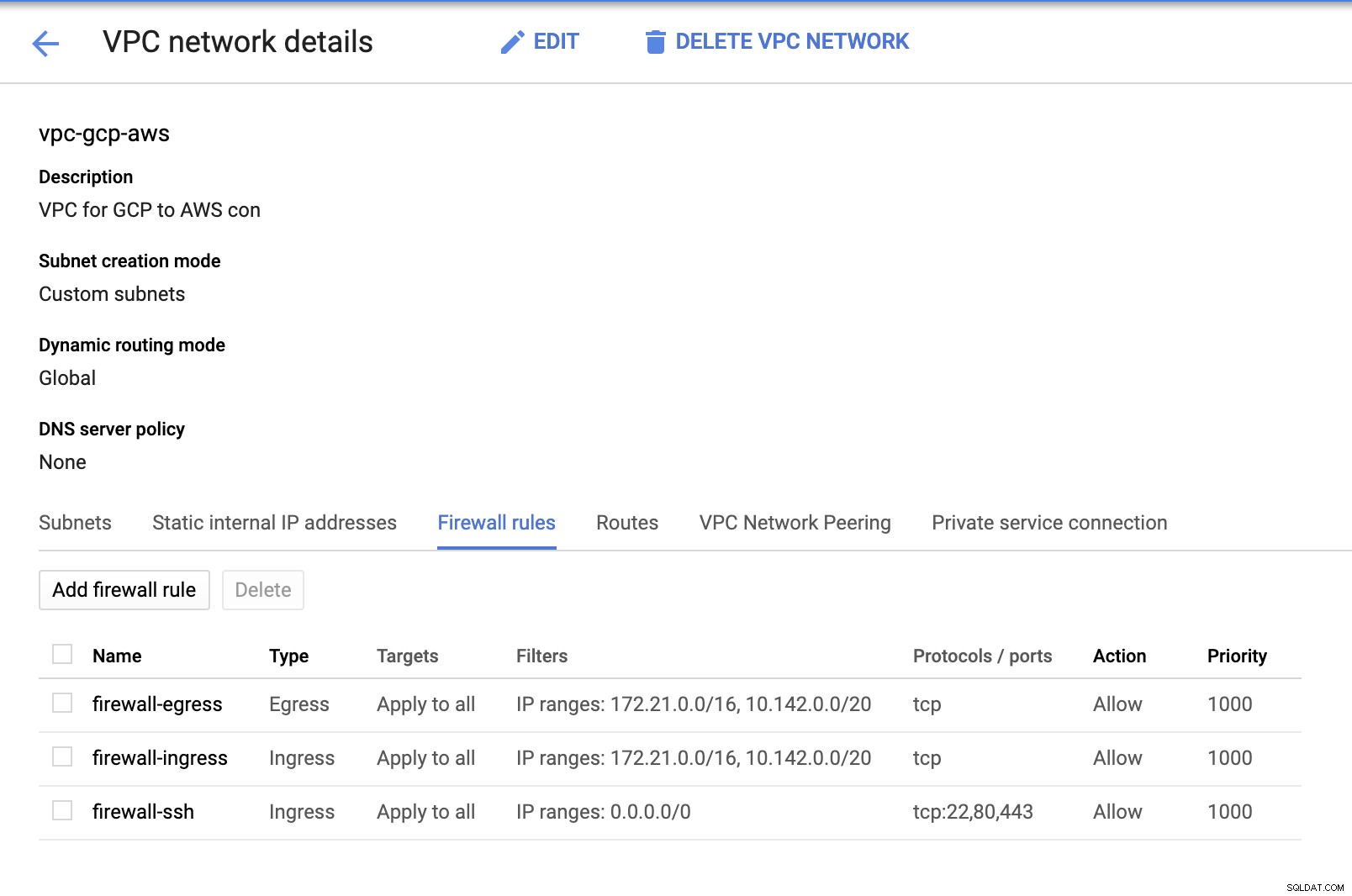
Il firewall-ssh qui verrà utilizzato per consentire connessioni in entrata ssh, HTTP e HTTPS.
-
Ora passa ad AWS e crea un VPC. Per questo blog ho utilizzato CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Crea le sottoreti per le quali devi assegnarle in ciascuna AZ (Availability Zone); e almeno riservare una sottorete per una sottorete pubblica che gestirà il gateway NAT, e il resto è per i nodi EC2.

-
Quindi, crea la tua tabella di percorso e assicurati che "Destinazione" e "Obiettivi" siano impostati correttamente. Per questo blog ho creato 2 tabelle di percorso. Uno che gestirà le 3 AZ che i miei nodi di calcolo verranno assegnati individualmente e verrà assegnato senza un gateway Internet poiché non avrà IP pubblico. Quindi l'altro gestirà il gateway NAT e avrà un gateway Internet che sarà nella sottorete pubblica. Vedi immagine sotto:

e come accennato, la mia destinazione di esempio per il percorso privato che gestisce 3 sottoreti mostra di avere una destinazione gateway NAT più una destinazione gateway virtuale che menzionerò più avanti nei passaggi in arrivo.

-
Quindi, crea un "gateway Internet" e assegnalo al VPC precedentemente creato nella sezione AWS VPC. Questo gateway Internet deve essere impostato solo come destinazione per la sottorete pubblica poiché sarà il servizio che deve connettersi a Internet. Ovviamente, il nome sta per servizio di gateway Internet.
-
Quindi, crea un "Gateway NAT". Quando crei un "Gateway NAT", assicurati di aver assegnato il tuo NAT a una sottorete pubblica. Il gateway NAT è il tuo canale per accedere a Internet dalla tua sottorete privata o dai nodi EC2 a cui non è assegnato IPv4 pubblico. Quindi crea o assegna un EIP (Elastic IP) poiché, in AWS, solo i nodi di calcolo a cui è assegnato un IPv4 pubblico possono connettersi direttamente a Internet.
-
Ora, in VPC -> Sicurezza -> Gruppi di sicurezza (SG) , il VPC creato avrà un SG predefinito. Per questa configurazione, ho creato "Regole in entrata" con le origini assegnate per ogni CIDR, ovvero 10.142.0.0/20 in GCP e 172.21.0.0/16 in AWS. Vedi sotto:

Per "Regole in uscita", puoi lasciarlo così com'è poiché l'assegnazione di regole a "Regole in entrata" è bilaterale, il che significa che si aprirà anche per "Regole in uscita". Tieni presente che questo non è il modo ottimale per impostare il tuo gruppo di sicurezza; ma per rendere più facile questa configurazione, ho anche ampliato la portata dell'intervallo di porte e della sorgente. Inoltre, il protocollo è specifico solo per le connessioni TCP poiché non ci occuperemo dell'UDP per questo blog.
Inoltre, puoi lasciare il tuo VPC -> Sicurezza -> ACL di rete intatto purché non neghi alcuna connessione TCP dal CIDR indicato nella tua fonte. -
Successivamente, configureremo la configurazione VPN che sarà ospitata sulla piattaforma AWS. Sotto il VPC -> Gateway clienti , creare il gateway utilizzando l'indirizzo IP statico creato in precedenza nel passaggio precedente. Dai un'occhiata all'immagine qui sotto:
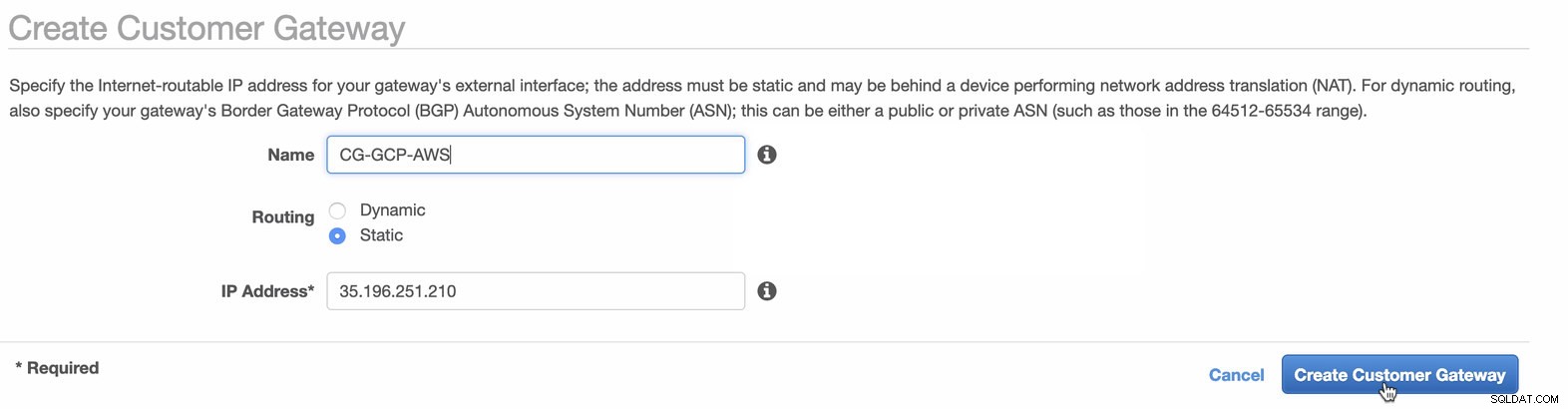
-
Quindi, crea un gateway virtuale privato e collegalo al VPC corrente che abbiamo creato in precedenza nel passaggio precedente. Vedi immagine sotto:

-
Ora crea una connessione VPN che verrà utilizzata per la connessione da sito a sito tra AWS e GCP. Quando crei una connessione VPN, assicurati di aver selezionato il gateway privato virtuale corretto e il gateway del cliente che abbiamo creato nei passaggi precedenti. Vedi immagine sotto:
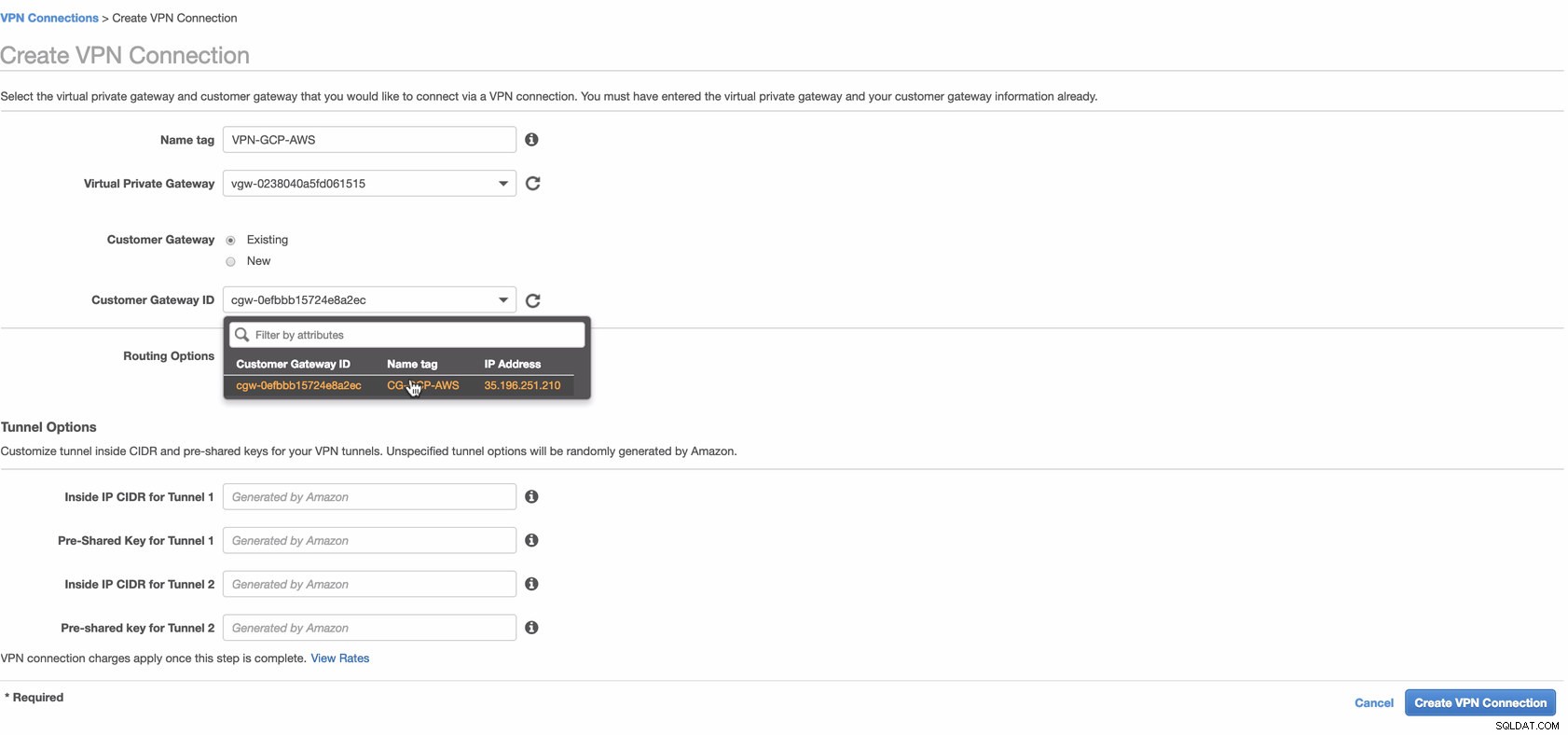
Questa operazione potrebbe richiedere del tempo mentre AWS sta creando la tua connessione VPN. Quando viene eseguito il provisioning della tua connessione VPN, potresti chiederti perché nella scheda Tunnel (dopo aver selezionato la tua connessione VPN), mostrerà che l'Indirizzo IP esterno è giù. Questo è normale in quanto non è stata ancora stabilita alcuna connessione dal client. Dai un'occhiata all'immagine di esempio qui sotto:

Una volta che la connessione VPN è pronta, seleziona la tua connessione VPN creata e scarica la configurazione. Contiene le credenziali necessarie per i seguenti passaggi per creare una connessione VPN da sito a sito con il client.
Nota: Nel caso in cui tu abbia impostato la tua VPN dove IPSEC IS UP ma Stato è GIU' proprio come l'immagine qui sotto

ciò è probabilmente dovuto a valori errati impostati sui parametri specifici durante l'impostazione della sessione BGP o del router cloud. Dai un'occhiata qui per la risoluzione dei problemi della tua VPN.
-
Poiché disponiamo di una connessione VPN già ospitata in AWS, creiamo una connessione VPN in GCP. Ora torniamo a GCP e configuriamo lì la connessione client. In GCP, vai a GCP -> Connettività ibrida -> VPN . Assicurati di scegliere la regione corretta, che è su questo blog, stiamo usando us-east1 . Quindi selezionare l'indirizzo IP statico creato nei passaggi precedenti. Vedi immagine sotto:
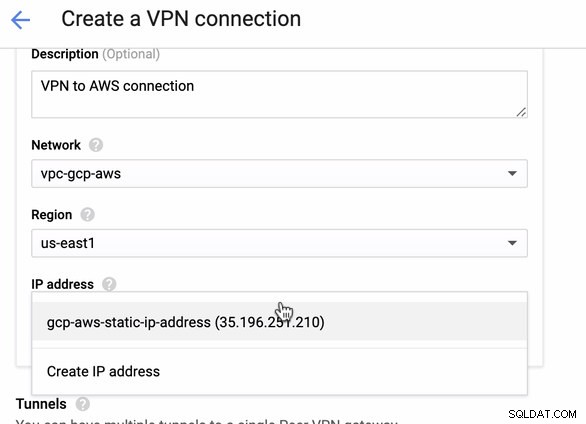
Poi nei Tunnel sezione, è qui che dovrai eseguire la configurazione in base alle credenziali scaricate dalla connessione VPN AWS che hai creato in precedenza. Suggerisco di dare un'occhiata a questa utile guida di Google. Ad esempio, uno dei tunnel in fase di configurazione è mostrato nell'immagine seguente:
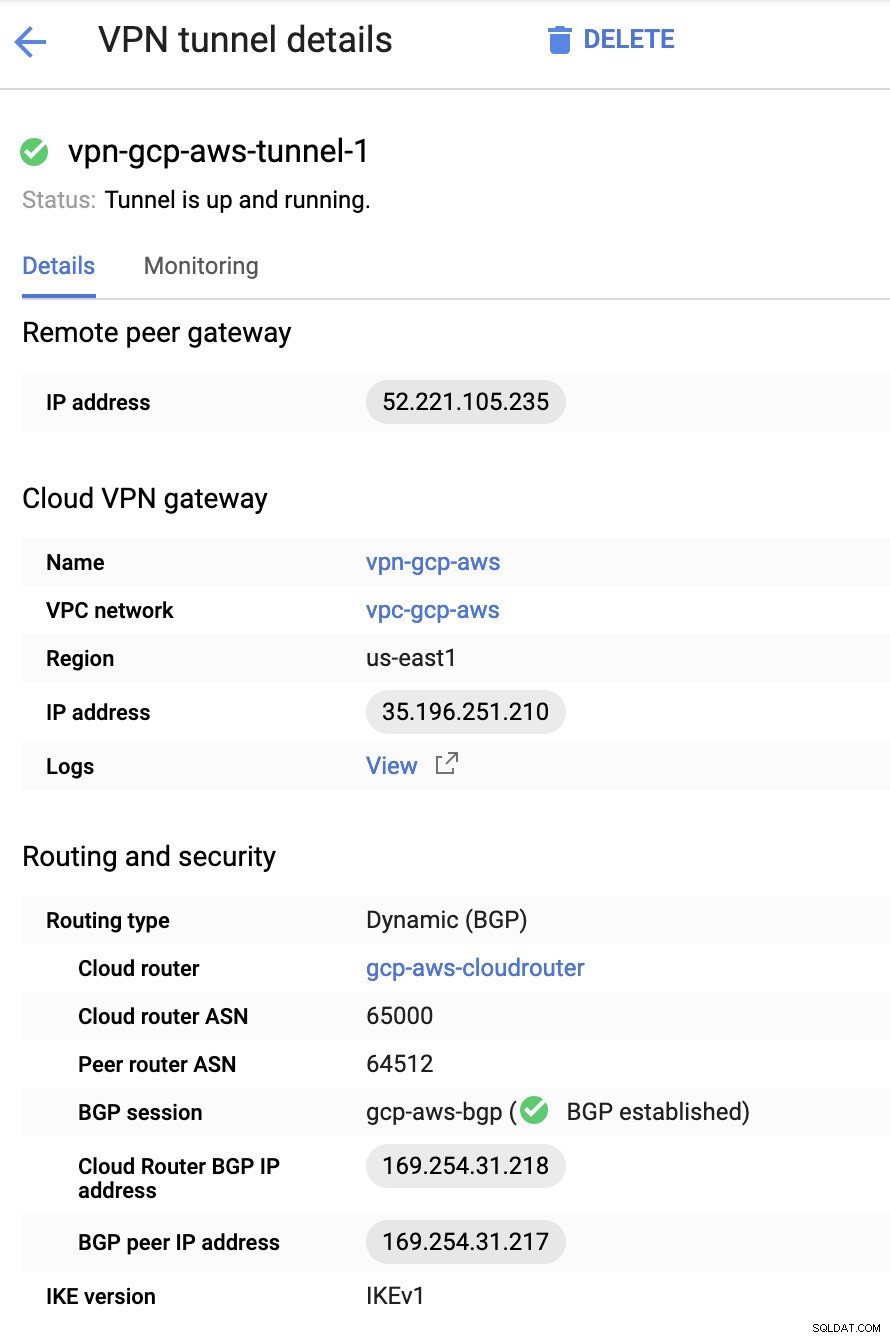
Fondamentalmente, le cose più importanti qui sono le seguenti:
- Gateway peer remoto:indirizzo IP:questo è l'IP del server VPN indicato in Dettagli tunnel -> Indirizzo IP esterno . Questo non deve essere confuso con l'IP statico che abbiamo creato in GCP. Questo è il gateway Cloud VPN -> indirizzo IP però.
- ASN router cloud:per impostazione predefinita, AWS utilizza 65000. Ma probabilmente otterrai queste informazioni dal file di configurazione scaricato.
- ASN router peer - Questo è l'ASN gateway virtuale privato che si trova nel file di configurazione scaricato.
- Indirizzo IP BGP del router cloud - Questo è il Customer Gateway trovato nel file di configurazione scaricato.
- Indirizzo IP peer BGP - Questo è il Virtual Private Gateway trovato nel file di configurazione scaricato.
-
Dai un'occhiata al file di configurazione di esempio che ho qui sotto:
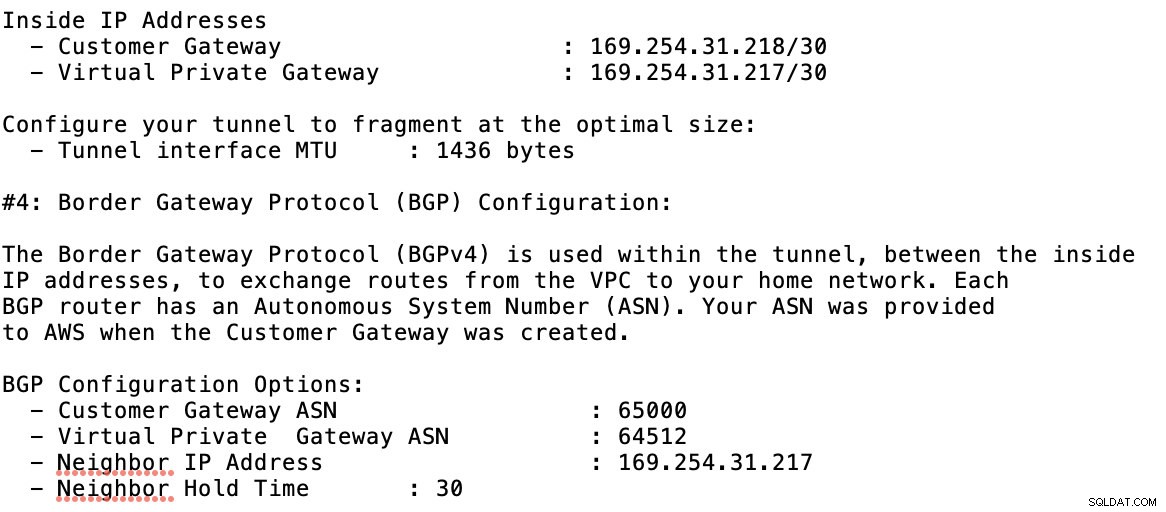
per cui devi abbinare questo durante l'aggiunta del tuo Tunnel in GCP -> Connettività ibrida -> VPN configurazione della connettività. Guarda l'immagine qui sotto per la quale ho creato un router cloud e una sessione BGP durante la creazione di un tunnel di esempio:
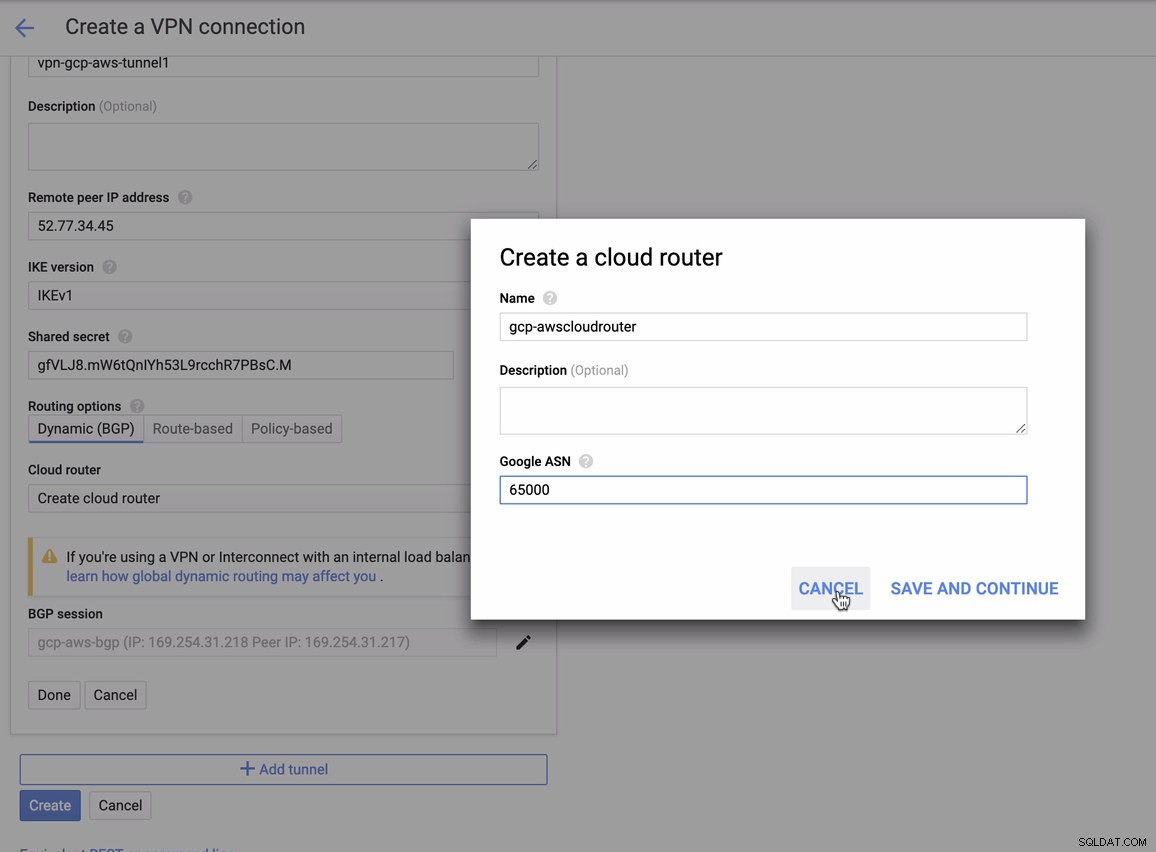
Quindi sessione BGP come,

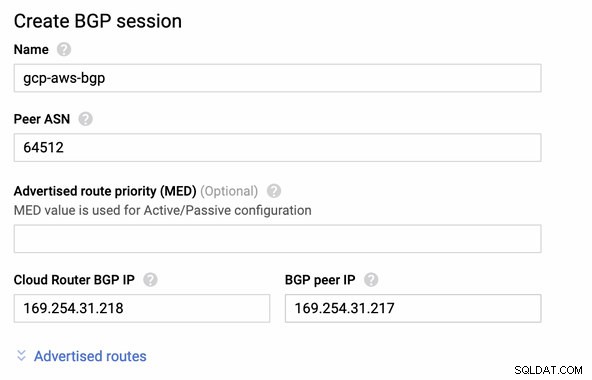
Nota: Il file di configurazione scaricato contiene il tunnel di configurazione IPSec per il quale anche AWS contiene due (2) server VPN pronti per la tua connessione. Devi configurarli entrambi in modo da avere una configurazione a disponibilità elevata. Una volta configurata correttamente per entrambi i tunnel, la connessione VPN AWS nella scheda Tunnel mostrerà che entrambi Indirizzo IP esterno Sono finiti. Vedi immagine sotto:

-
Infine, poiché abbiamo creato un gateway Internet e un gateway NAT, popolare correttamente le sottoreti pubbliche e private con la Destinazione corretta e Obiettivo come notato nello screenshot dei passaggi precedenti. Questo può essere configurato andando su Servizi -> Rete e distribuzione di contenuti -> VPC -> Tabelle di instradamento e selezionare le tabelle di percorso create menzionate nei passaggi precedenti. Vedi l'immagine qui sotto:
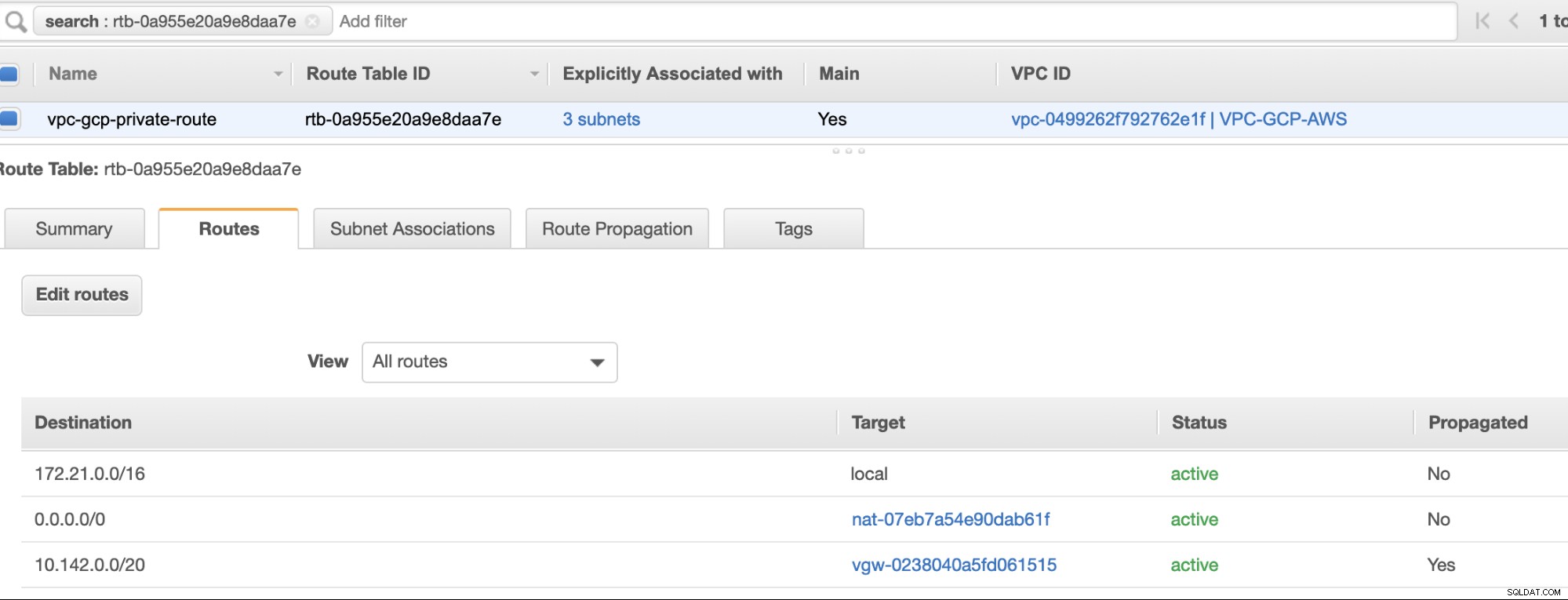
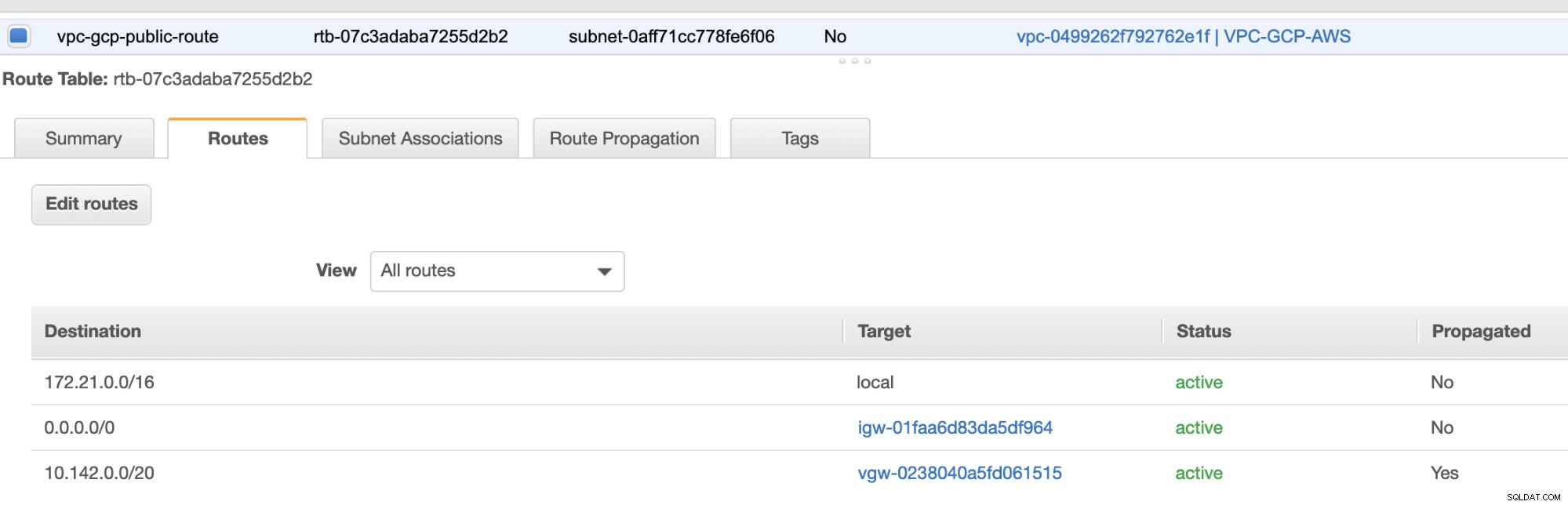
Come hai notato, igw-01faa6d83da5df964 è l'Internet Gateway che abbiamo creato e viene utilizzato dal percorso pubblico. Mentre la tabella del percorso privato ha la destinazione e il target impostati su nat-07eb7a54e90dab61f ed entrambi hanno Destinazione impostato su 0.0.0.0/0 poiché consentirà da diverse connessioni IPv4. Inoltre, non dimenticare di impostare la Propagazione del percorso correttamente per il gateway virtuale come mostrato nello screenshot che ha un target vgw-0238040a5fd061515 . Basta fare clic su Route Propagation e impostarlo su Sì, proprio come nello screenshot qui sotto:
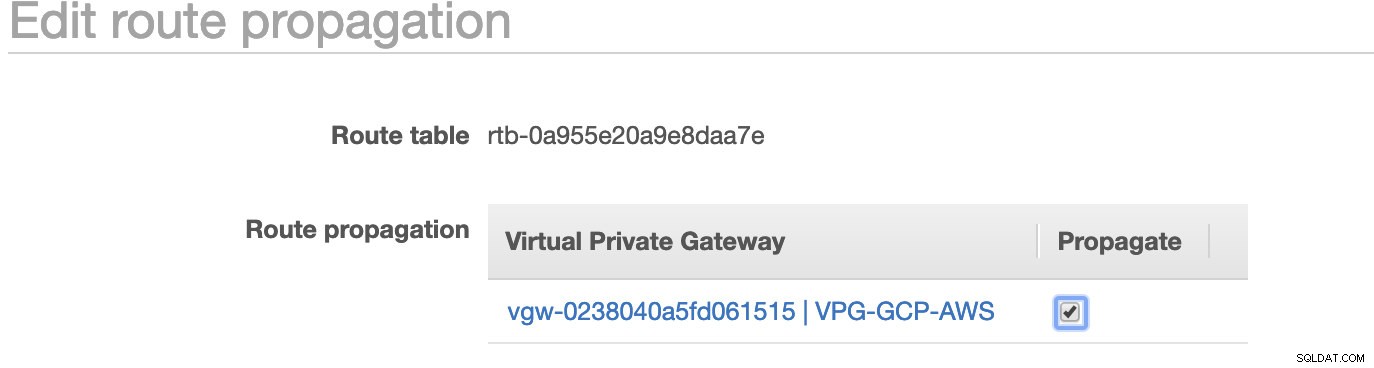
Questo è molto importante in modo che la connessione dalle connessioni GCP esterne venga instradata alle tabelle di routing in AWS e non siano necessari ulteriori lavori manuali. In caso contrario, il tuo GCP non può stabilire una connessione ad AWS.
Ora che la nostra VPN è attiva, continueremo a configurare i nostri nodi privati, incluso il bastion host.
Configurazione dei nodi Compute Engine
La configurazione dei nodi Compute Engine/EC2 sarà facile e veloce poiché abbiamo tutte le impostazioni a posto. Non entrerò nei dettagli, ma controlla gli screenshot qui sotto in quanto spiega l'installazione.
Nodi AWS EC2 :

Nodi di calcolo GCP :
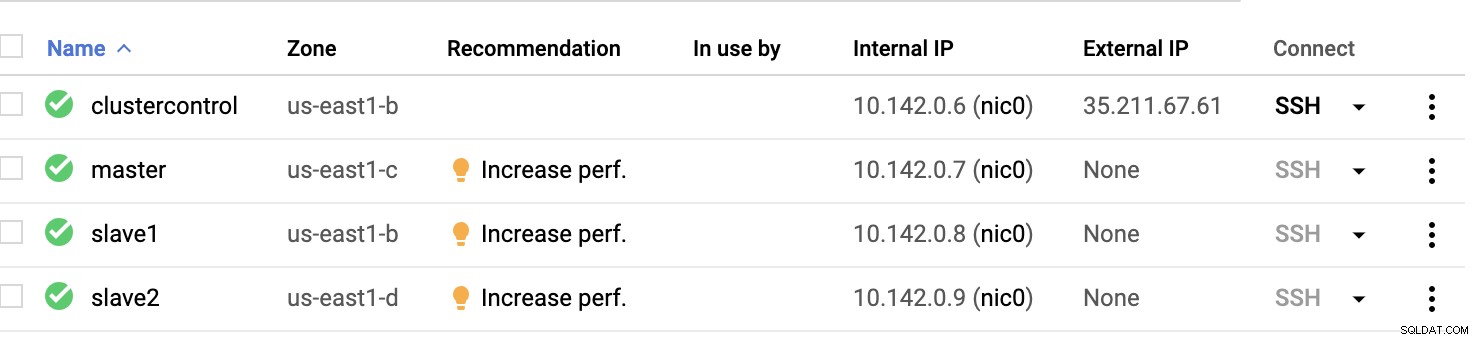
Fondamentalmente, su questa configurazione. L'host controllo cluster sarà il bastion o jump host e per il quale verrà installato ClusterControl. Ovviamente, tutti i nodi qui non sono accessibili a Internet. Non hanno IPv4 esterno assegnato e i nodi comunicano attraverso un canale molto sicuro tramite VPN.
Infine, tutti questi nodi da AWS a GCP sono configurati con un utente di sistema uniforme con accesso sudo, necessario nella nostra prossima sezione. Scopri come ClusterControl può semplificarti la vita in multicloud e multiregione.
ClusterControl in soccorso!!!
La gestione di più nodi e su diverse piattaforme di cloud pubblico, oltre a una "regione" diversa può essere un'attività "veramente dolorosa e scoraggiante". Come lo monitori in modo efficace? ClusterControl funge non solo da coltellino svizzero, ma anche da Virtual DBA. Ora, vediamo come ClusterControl può semplificarti la vita.
Creazione di un cluster a replica multipla utilizzando ClusterControl
Proviamo ora a creare un cluster di replica master-slave MariaDB seguendo la topologia "Replica multipla".
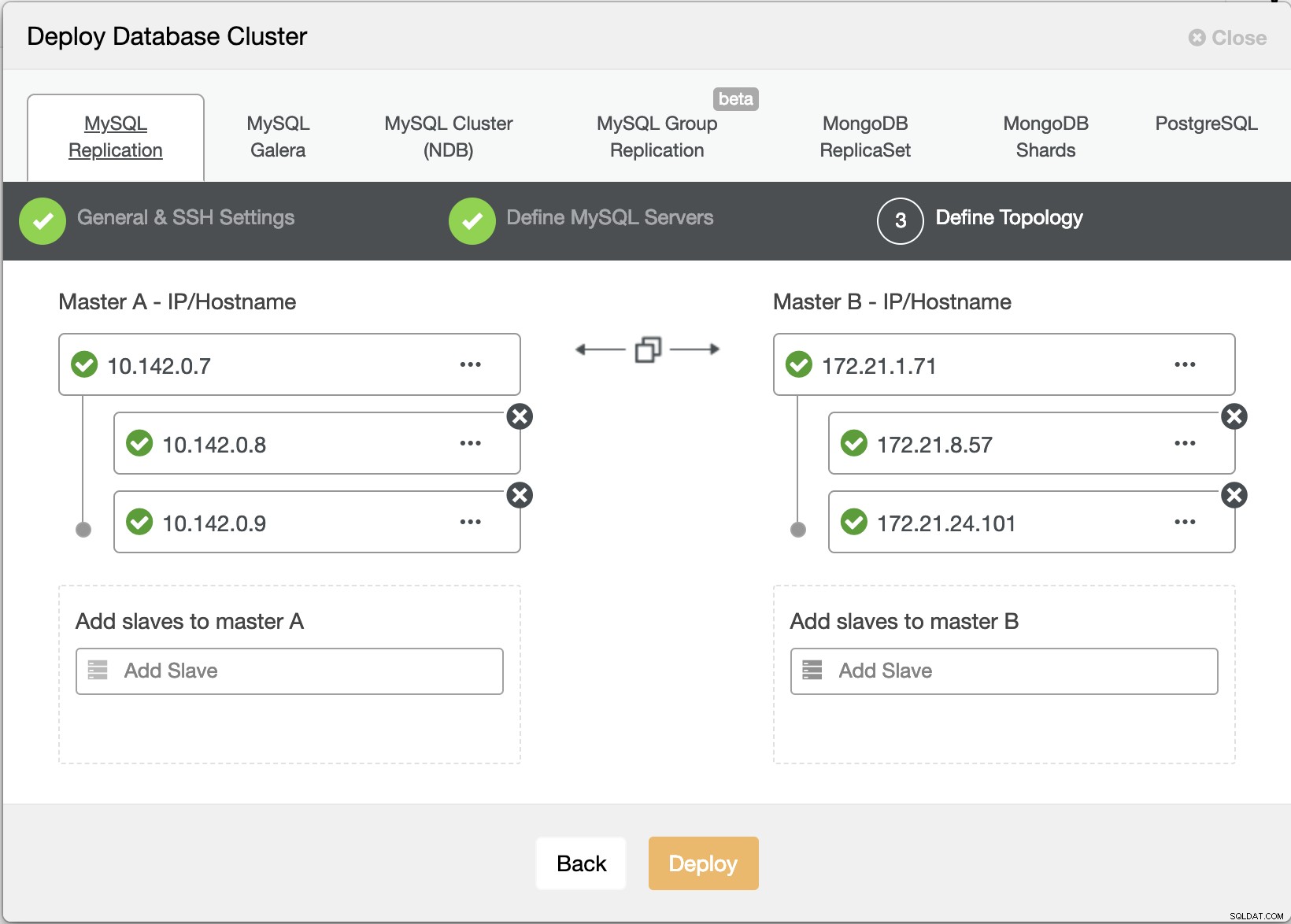 Distribuzione guidata ClusterControl
Distribuzione guidata ClusterControl Colpire Distribuisci il pulsante installerà i pacchetti e configurerà i nodi di conseguenza. Quindi, una vista logica di come sarebbe la topologia:
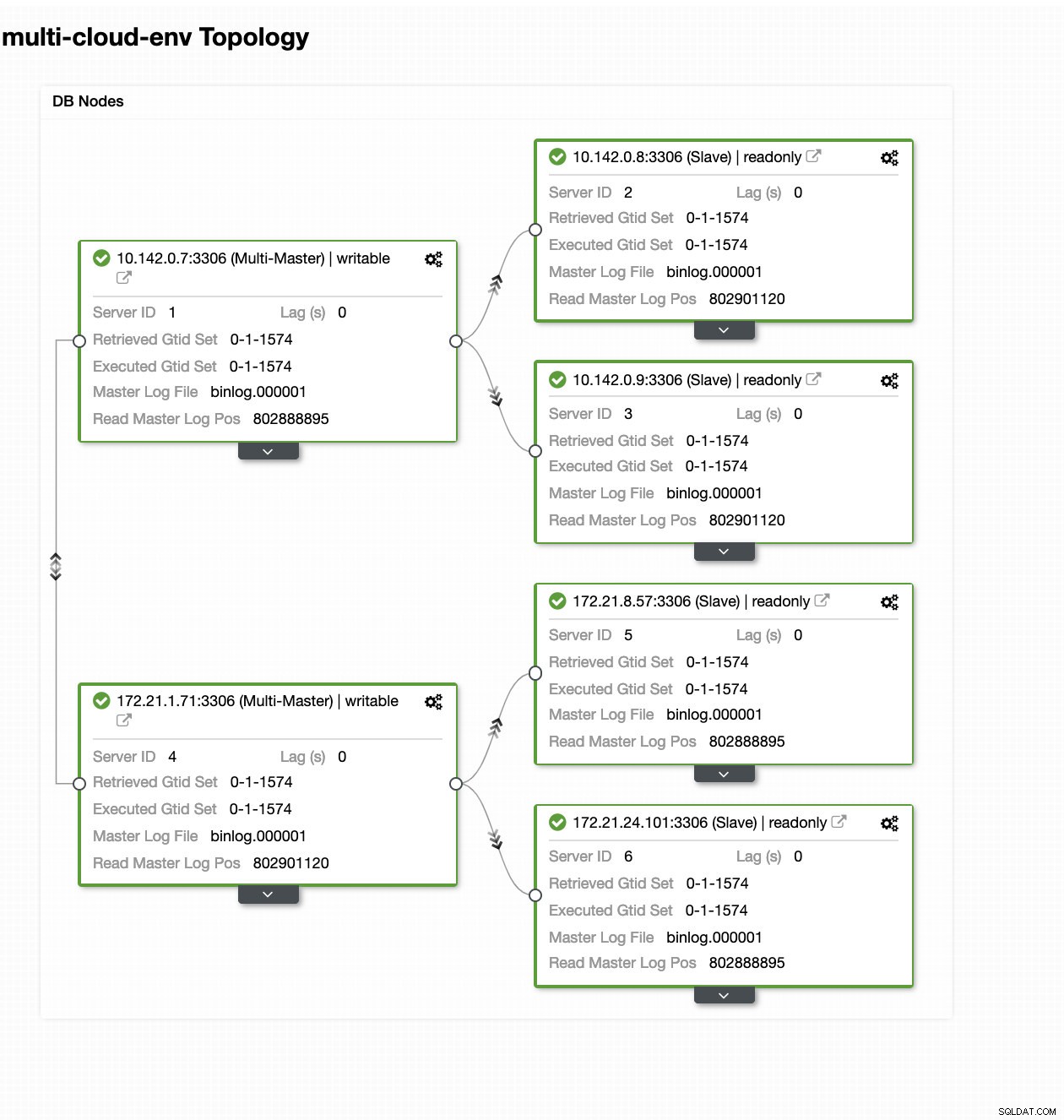 ClusterControl - Vista topologia
ClusterControl - Vista topologia Gli IP dell'intervallo 172.21.0.0/16 dei nodi vengono replicati dal master in esecuzione su GCP.
Ora, che ne dici di provare a caricare alcune scritture sul master? Eventuali problemi di connettività o latenza potrebbero generare slave lag, sarai in grado di individuarlo con ClusterControl. Vedi lo screenshot qui sotto:
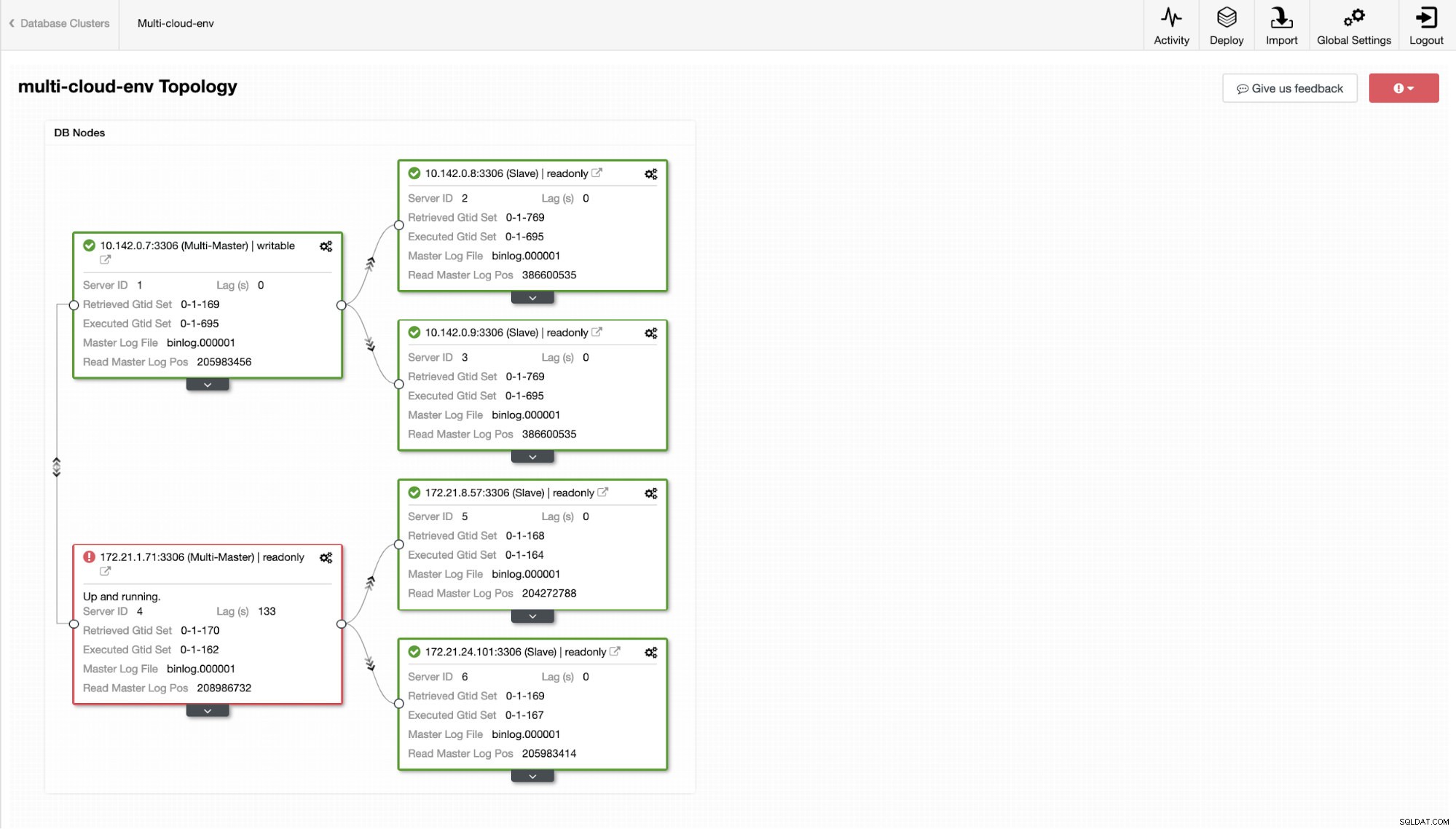
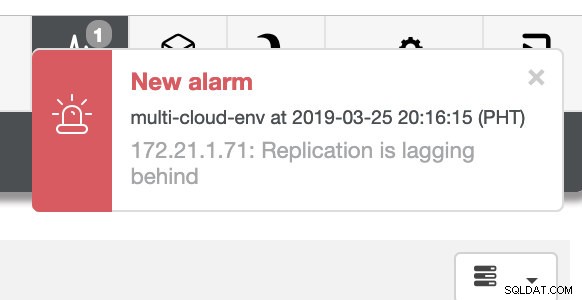
e come vedi nell'angolo in alto a destra dello screenshot, diventa rosso perché indica che sono stati rilevati problemi. Pertanto, è stato inviato un allarme mentre è stato rilevato questo problema. Vedi sotto:
Dobbiamo approfondire questo. Per un monitoraggio dettagliato, abbiamo abilitato gli agenti sulle istanze del database. Diamo un'occhiata alla Dashboard.
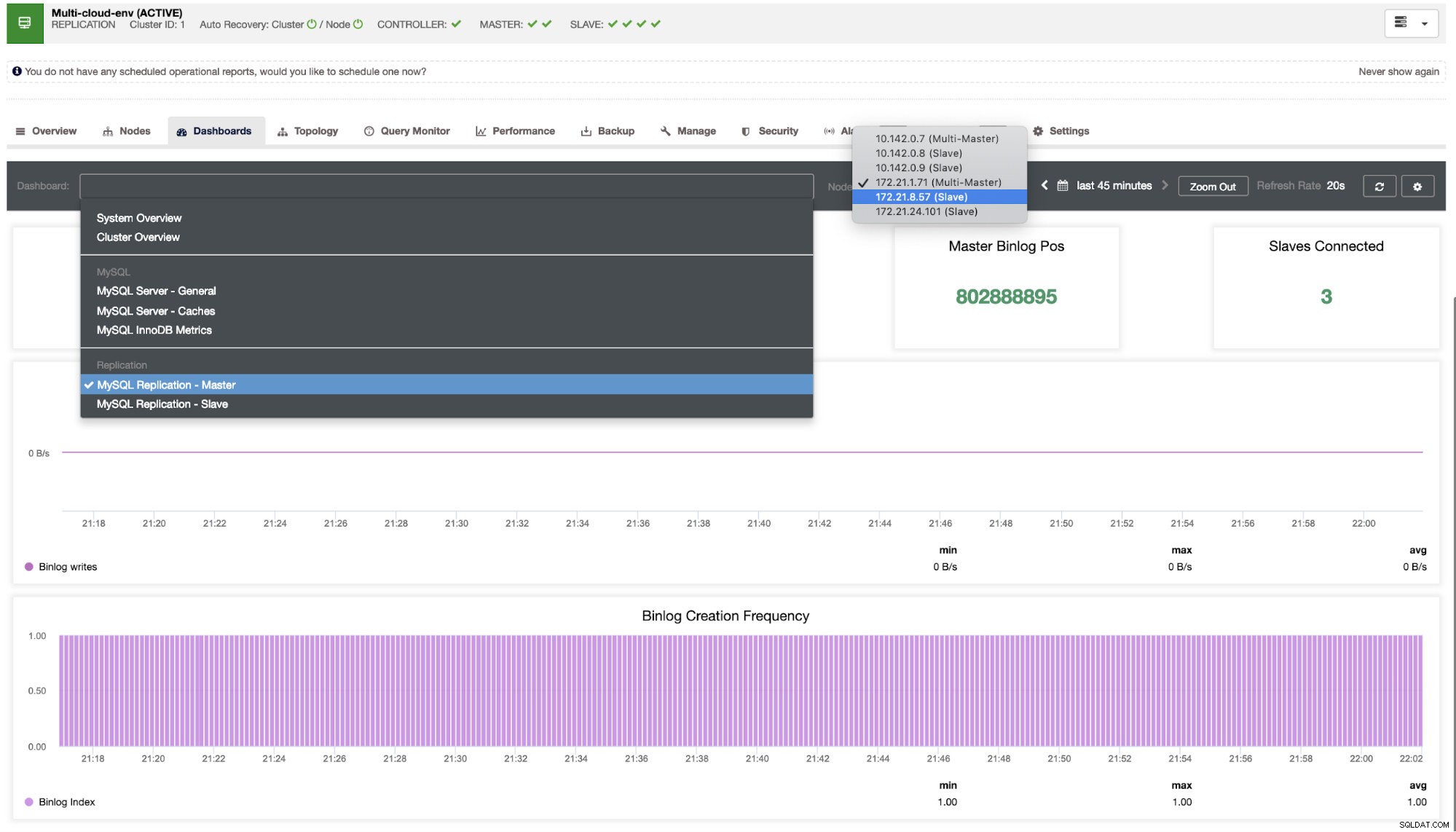
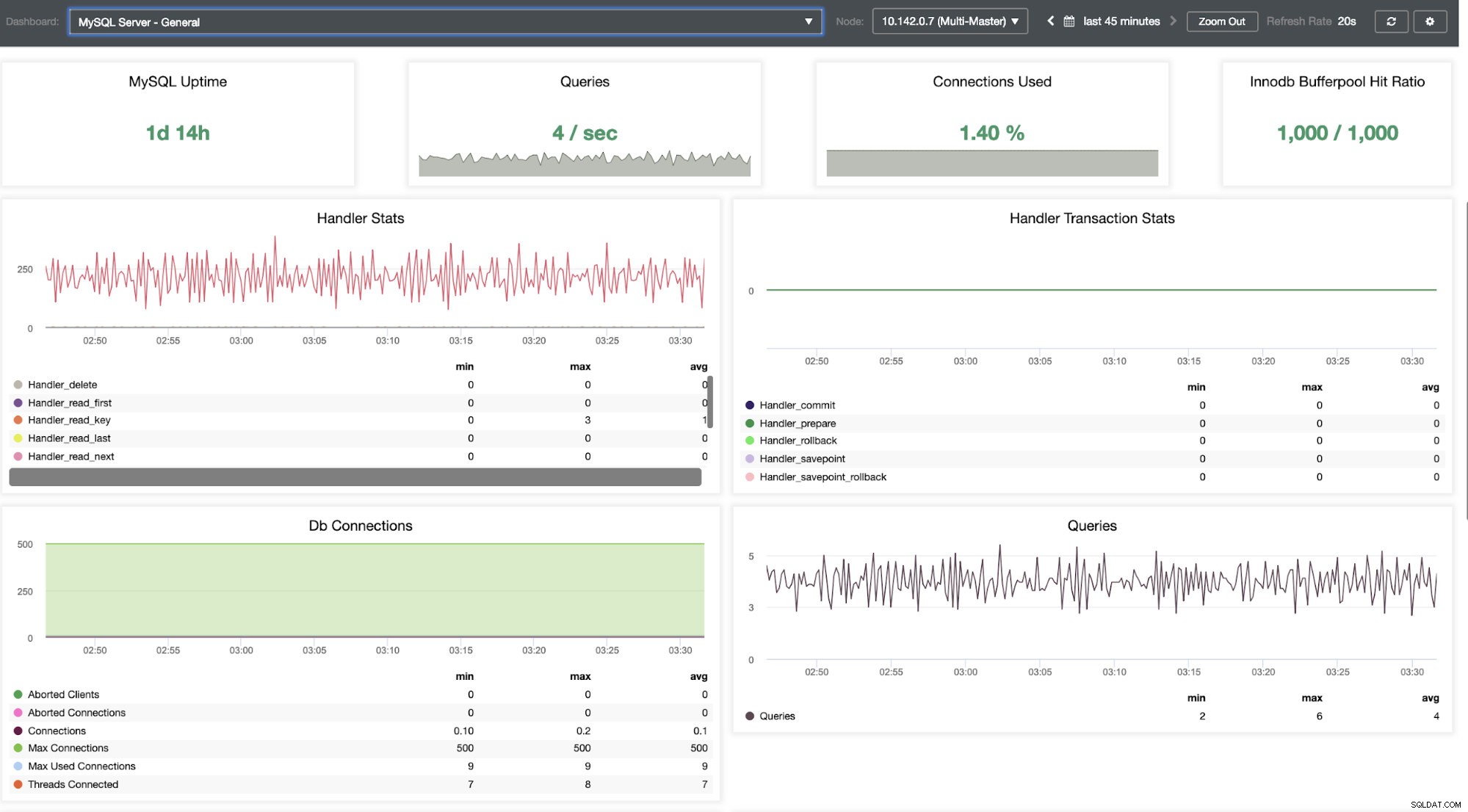
Offre un'esperienza super fluida in termini di monitoraggio dei tuoi nodi.
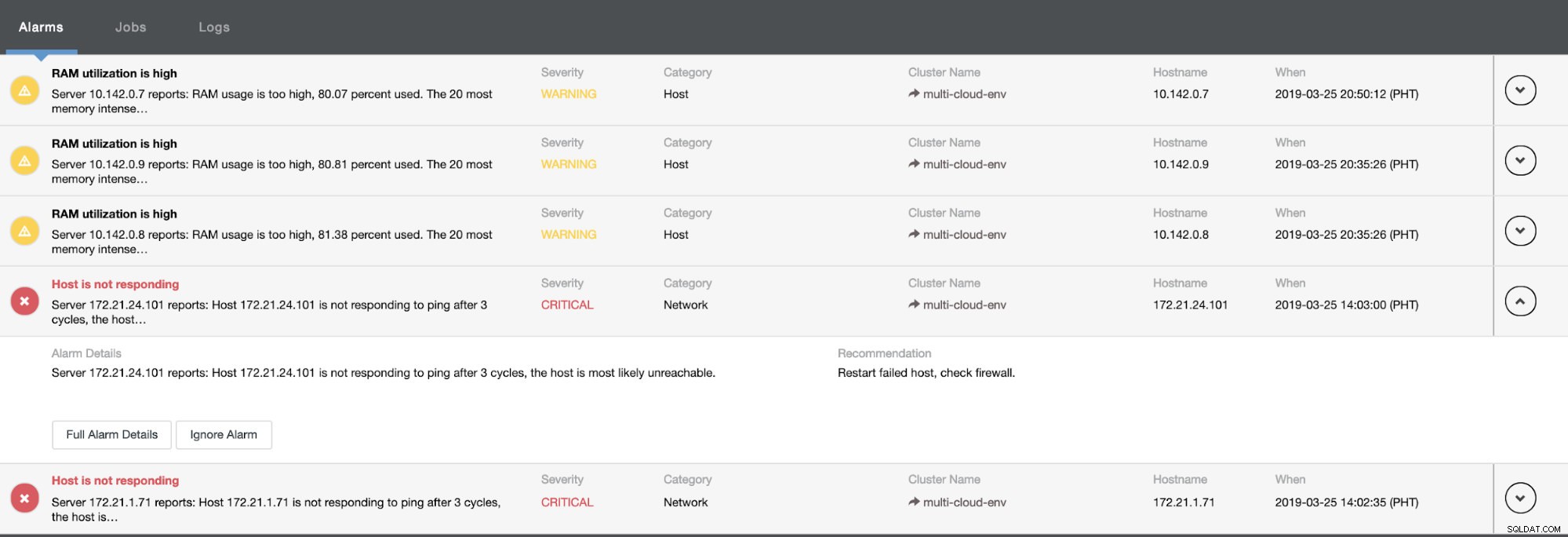
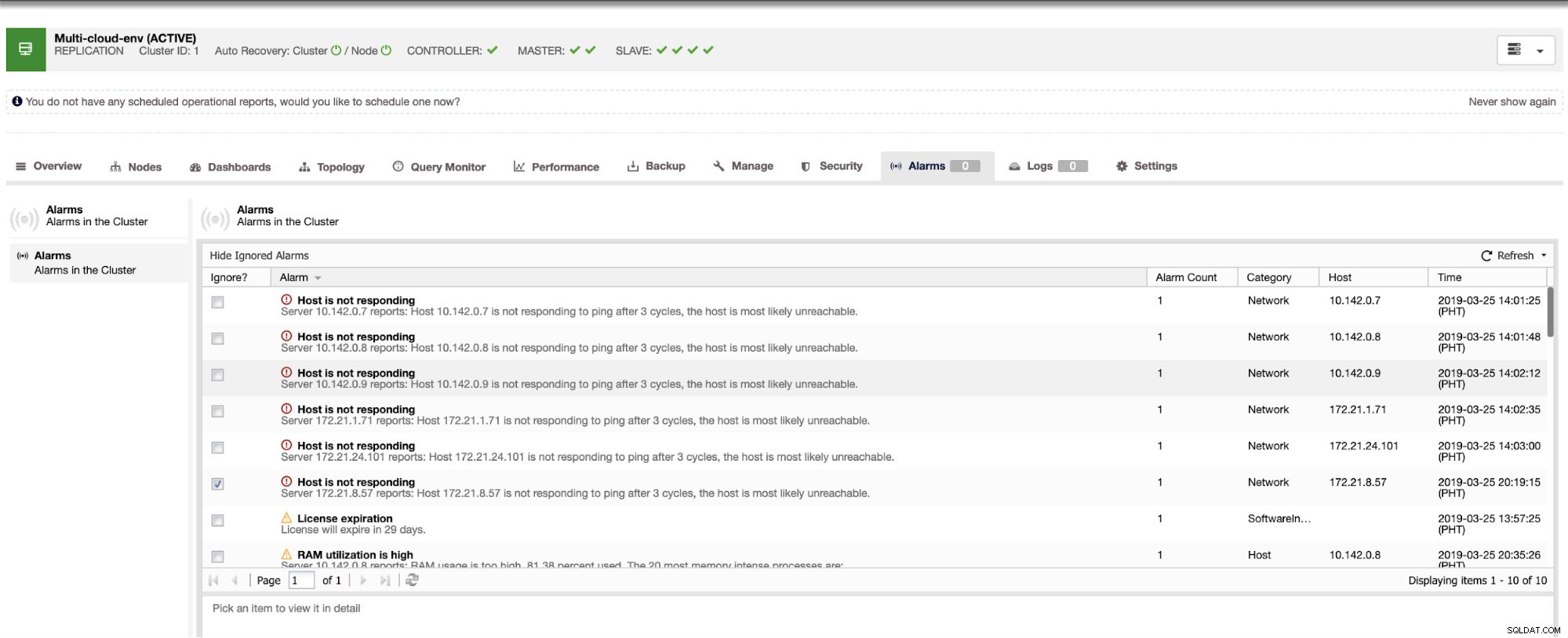
Ci dice che l'utilizzo è elevato o che l'host non risponde. Anche se questo era solo un ping mancata risposta, puoi ignorare l'avviso per impedirti di bombardarlo. Quindi, puoi "annullarlo" se necessario andando su Cluster -> Allarmi in Clustercontrol. Vedi sotto:
Gestione degli errori ed esecuzione del failover
Diciamo che il nodo master us-east1 si è guastato o richiede un'importante revisione a causa dell'aggiornamento del sistema o dell'hardware. Diciamo che questa è la topologia in questo momento (vedi immagine sotto):
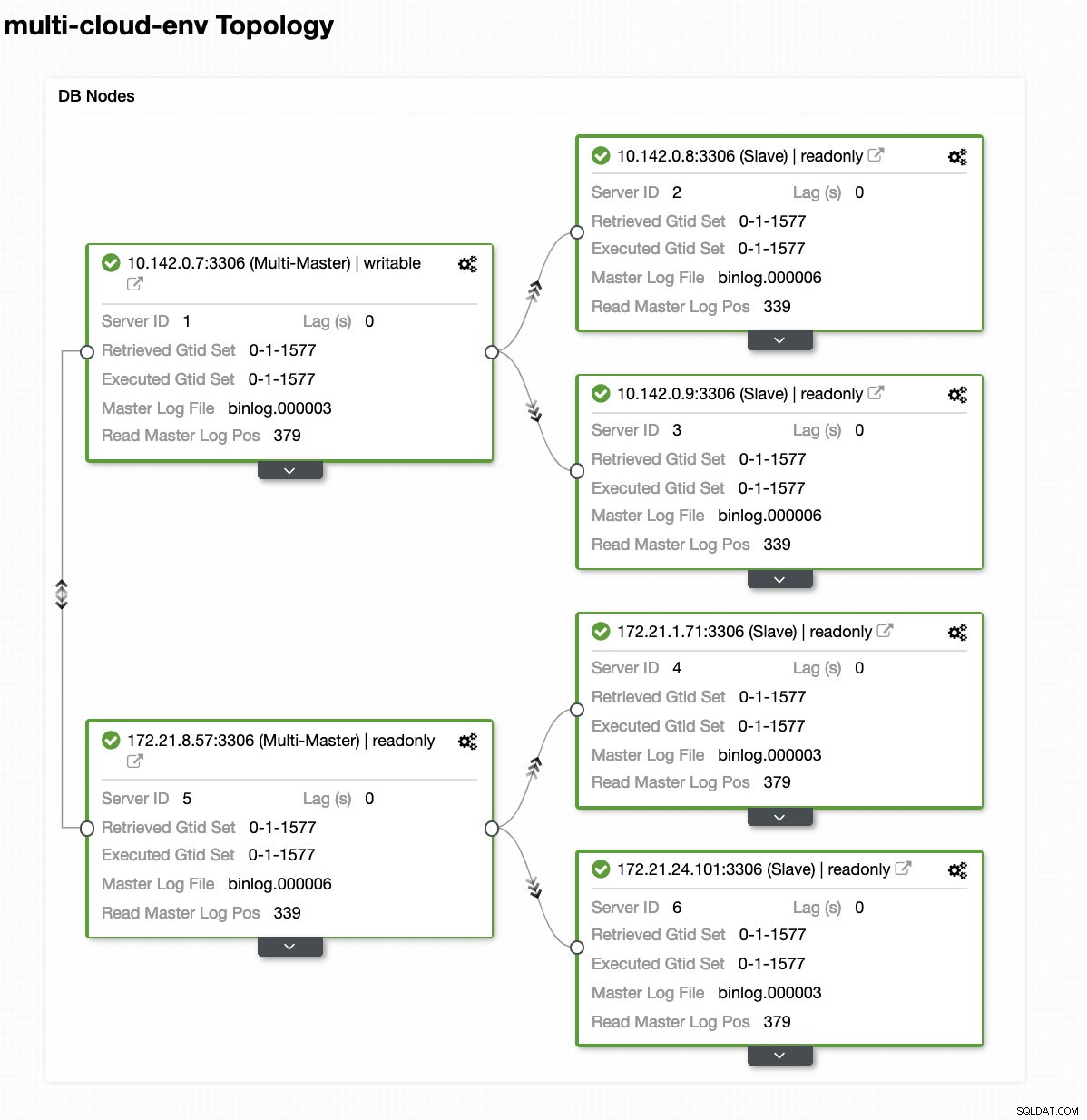
Proviamo a spegnere l'host 10.142.0.7 che è il master nella regione us-east1. Guarda gli screenshot qui sotto come ClusterControl reagisce a questo:
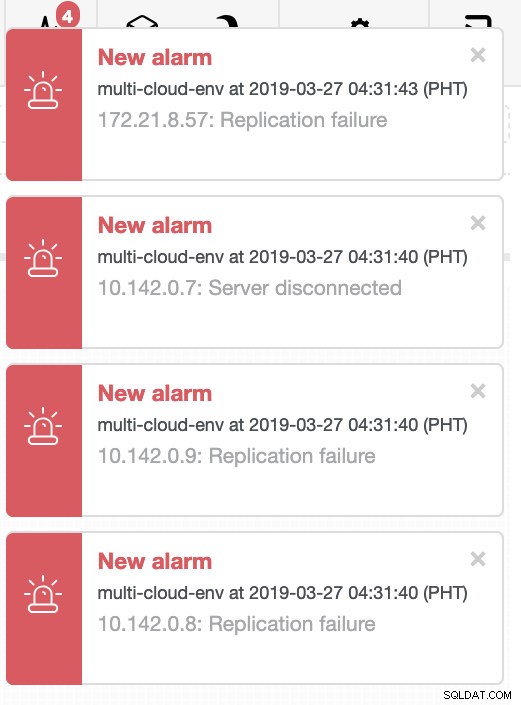
ClusterControl invia allarmi una volta rilevate anomalie nel cluster. Quindi prova a eseguire un failover su un nuovo master scegliendo il candidato giusto (vedi immagine sotto):

Quindi, ha messo da parte il master guasto che è già stato rimosso dal cluster (vedi immagine sotto):
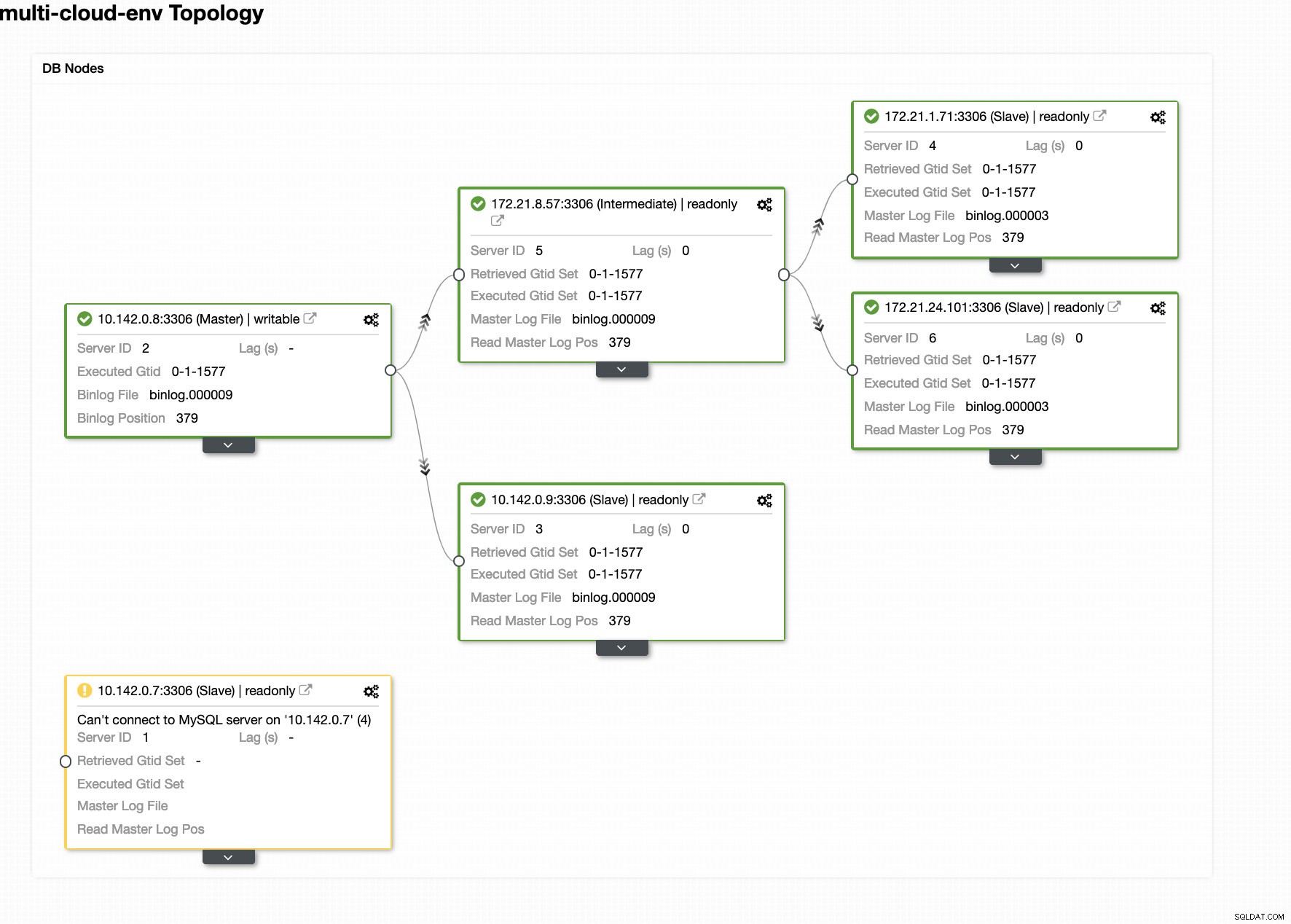
Questo è solo un assaggio di ciò che ClusterControl può fare, ci sono altre fantastiche funzionalità come backup, monitoraggio delle query, distribuzione/gestione dei bilanciatori del carico e molto altro!
Conclusione
Gestire la configurazione della replica MySQL in un multicloud può essere complicato. È necessario prestare molta attenzione per proteggere la nostra configurazione, quindi si spera che questo blog dia un'idea su come definire le sottoreti e proteggere i nodi del database. Dopo la sicurezza, ci sono una serie di cose da gestire ed è qui che ClusterControl può essere molto utile.
Provalo ora e facci sapere come va. Puoi contattarci qui in qualsiasi momento.



