Da quando ClusterControl 1.2.11 è stato rilasciato nel 2015, MariaDB MaxScale è stato supportato come bilanciatore del carico del database. Nel corso degli anni MaxScale è cresciuto e maturato, aggiungendo diverse funzionalità avanzate. Di recente è stato rilasciato MariaDB MaxScale 2.2 che introduce diverse nuove funzionalità, inclusa la gestione del failover del cluster di replica.
MariaDB MaxScale consente implementazioni master/slave con disponibilità elevata, failover automatico, passaggio manuale e rejoin automatico. Se il master si guasta, MariaDB MaxScale può promuovere automaticamente lo slave più aggiornato a master. Se il master guasto viene ripristinato, MariaDB MaxScale può riconfigurarlo automaticamente come slave del nuovo master. Inoltre, gli amministratori possono eseguire un passaggio manuale per modificare il master su richiesta.
Nei nostri blog precedenti abbiamo discusso su come distribuire MaxScale utilizzando ClusterControl e come distribuire MariaDB MaxScale su Docker. Per coloro che non hanno ancora familiarità con MariaDB MaxScale, è un proxy di database avanzato, plug-in per server di database MariaDB. Maxscale si trova tra le applicazioni client e i server di database, instradando le query dei client e le risposte del server. Monitora inoltre i server, rilevando rapidamente eventuali modifiche allo stato del server o alla topologia di replica.
Sebbene Maxscale condivida alcune delle caratteristiche di altre tecnologie di bilanciamento del carico come ProxySQL, questa nuova funzionalità di failover (che fa parte del suo meccanismo di monitoraggio e rilevamento automatico) si distingue. In questo blog parleremo di questa nuova entusiasmante funzione di Maxscale.
Panoramica del meccanismo di failover MariaDB MaxScale
Rilevamento principale
È meno probabile che il monitor cambi improvvisamente il server master, anche se un altro server ha più slave rispetto al master corrente. Il DBA può forzare una riselezione del master impostando il master corrente in sola lettura o rimuovendo tutti i suoi slave se il master è inattivo.
Solo un server alla volta può avere il flag di stato Master, anche in una configurazione multimaster. Ad altri server nel gruppo multimaster vengono assegnati i flag di stato Relay Master e Slave.
Selezione automatica del nuovo master di commutazione
Il comando di commutazione ora può essere richiamato con solo il nome dell'istanza di monitoraggio come parametro. In questo caso il monitor selezionerà automaticamente un server per la promozione.
Rilevamento del ritardo di replica
La misurazione del ritardo di replica ora legge semplicemente Seconds_Behind_Master -campo dell'uscita dello stato slave degli slave. Lo slave calcola questo valore confrontando il timestamp nell'evento binlog che lo slave sta attualmente elaborando con l'orologio dello slave. Se uno slave ha più connessioni slave, viene utilizzato il ritardo più piccolo.
Commutazione automatica dopo il rilevamento di spazio su disco insufficiente
Con le recenti versioni di MariaDB Server, il monitor ora può controllare lo spazio su disco sul back-end e rilevare se il server sta per esaurirsi. Quando ciò accade, il monitor può essere impostato per passare automaticamente da un master con poco spazio su disco. Gli slave possono anche essere impostati in modalità di manutenzione. Lo spazio su disco è anche un fattore da considerare quando si seleziona quale nuovo master promuovere.
Per ulteriori informazioni, vedere switchover_on_low_disk_space e Maintenance_on_low_disk_space.
Funzione di ripristino della replica
La replica-reset il comando monitor elimina tutte le connessioni slave e i registri binari, quindi imposta la replica. Utile quando i dati sono sincronizzati ma i gtid no.
Gestione degli eventi pianificati in Failover/Switchover/Rejoin
Gli eventi del server avviati dal thread dell'utilità di pianificazione degli eventi vengono ora gestiti durante le operazioni di modifica del cluster. Vedi handle_server_events per ulteriori informazioni.
Supporto master esterno
Il monitor può rilevare se un server nel cluster sta eseguendo la replica da un master esterno (un server che non viene monitorato dal monitor MaxScale). Se il server di replica è il server master del cluster, si considera che il cluster stesso disponga di un master esterno.
Se si verifica un failover/switchover, il nuovo server master viene impostato per la replica dal server master esterno del cluster. Il nome utente e la password per la replica sono definiti in replication_user e replication_password. L'indirizzo e la porta utilizzati sono quelli mostrati da SHOW ALL SLAVES STATUS sul vecchio server master del cluster. In caso di switchover, il vecchio master interrompe anche la replica dal server esterno per preservare la topologia.
Dopo il failover, il nuovo master viene replicato dal master esterno. Se il vecchio master fallito torna online, si sta replicando anche dal server esterno. Per normalizzare la situazione, attivare auto_rejoin o eseguire manualmente un rejoin. Questo reindirizzerà il vecchio master al master del cluster corrente.
In che modo il failover è utile e applicabile?
Il failover consente di ridurre al minimo i tempi di inattività, eseguire la manutenzione quotidiana o gestire la manutenzione disastrosa e indesiderata che a volte può verificarsi in momenti sfortunati. Con la capacità di MaxScale di isolare le applicazioni client dai server di database back-end, aggiunge preziose funzionalità che aiutano a ridurre al minimo i tempi di inattività.
Il plug-in di monitoraggio MaxScale monitora continuamente lo stato dei server di database back-end. Il plug-in di routing di MaxScale utilizza quindi queste informazioni sullo stato per instradare sempre le query ai server di database back-end in servizio. È quindi in grado di inviare query ai cluster di database di back-end, anche se alcuni dei server di un cluster sono sottoposti a manutenzione o si verificano guasti.
L'elevata configurabilità di MaxScale consente alle modifiche nella configurazione del cluster di rimanere trasparenti per le applicazioni client. Ad esempio, se è necessario aggiungere o rimuovere amministrativamente un nuovo server da un cluster master-slave, è possibile semplicemente aggiungere la configurazione MaxScale all'elenco dei server di plug-in per monitor e router tramite la console CLI maxadmin. L'applicazione client non sarà completamente a conoscenza di questa modifica e continuerà a inviare query di database alla porta di ascolto di MaxScale.
Impostare un server di database in manutenzione è semplice e facile. Basta eseguire il comando seguente utilizzando maxctrl e MaxScale interromperà l'invio di query a questo server. Ad esempio,
maxctrl: set server DB_785 maintenance
OKQuindi controlla lo stato dei server come segue,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Una volta in modalità di manutenzione, MaxScale interromperà l'instradamento di eventuali nuove richieste al server. Per le richieste correnti, MaxScale non interromperà queste sessioni, ma consentirà piuttosto di completare la sua esecuzione e non interromperà le query in esecuzione durante la modalità di manutenzione. Inoltre, prendi nota che la modalità di manutenzione non è persistente. Se MaxScale si riavvia quando un nodo è in modalità di manutenzione, una nuova istanza di MariaDB MaxScale non rispetterà questa modalità. Se più istanze MariaDB MaxScale sono configurate per utilizzare il nodo, è necessario impostare la modalità di manutenzione all'interno di ciascuna istanza MariaDB MaxScale. Tuttavia, se più servizi all'interno di un'istanza MariaDB MaxScale utilizzano il server, devi solo impostare la modalità di manutenzione una volta sul server affinché tutti i servizi prendano nota del cambio di modalità.
Una volta terminata la manutenzione, cancella il server con il seguente comando. Ad esempio,
maxctrl: clear server DB_785 maintenance
OKVerificando se è tornato alla normalità, esegui il comando list server .
È anche possibile applicare determinate azioni amministrative tramite l'interfaccia utente di ClusterControl. Vedi lo screenshot di esempio qui sotto:
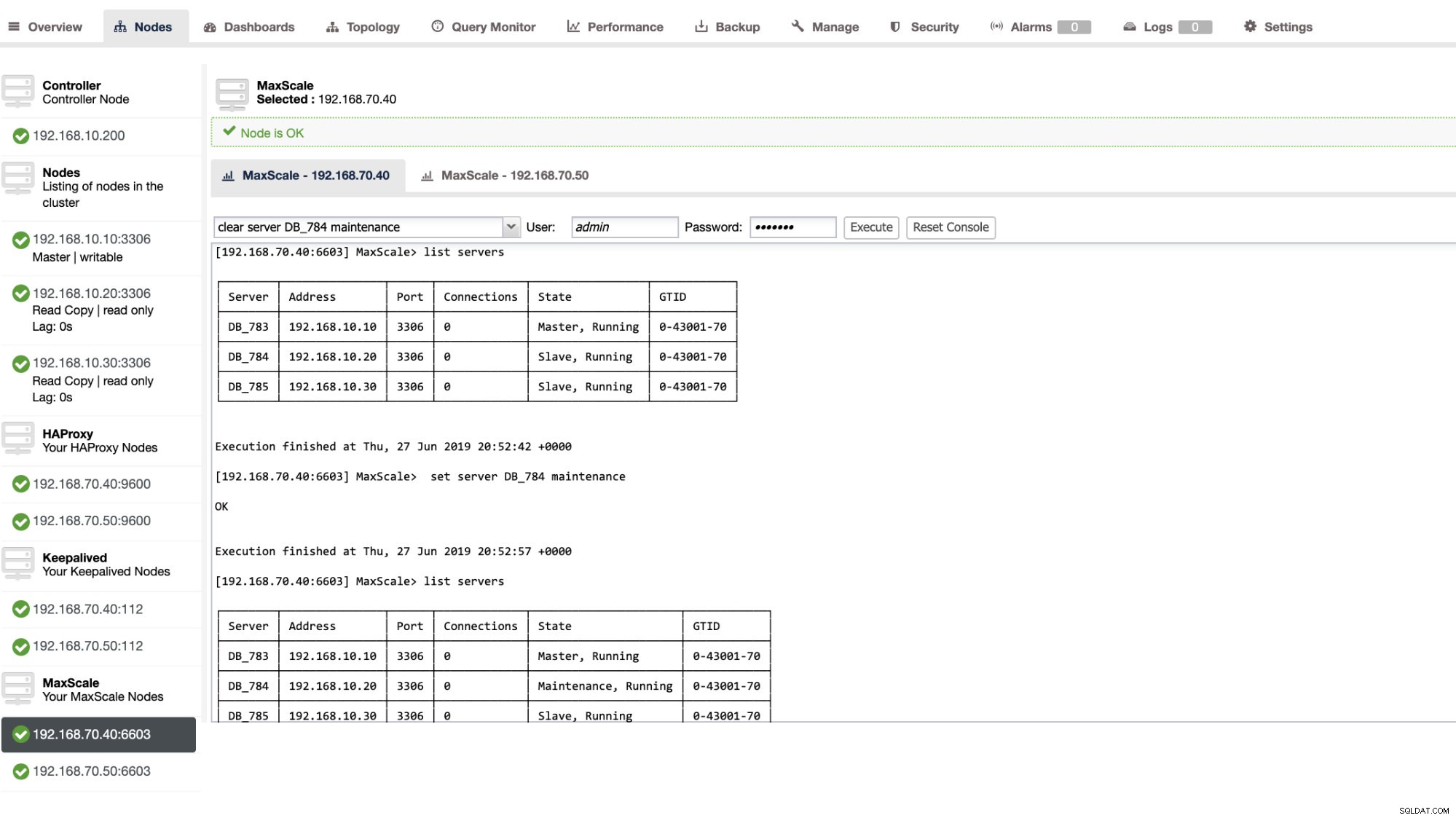
Failover MaxScale in azione
Il failover automatico
Il failover MaxScale di MariaDB funziona in modo molto efficiente e riconfigura lo slave di conseguenza come previsto. In questo test, abbiamo il seguente set di file di configurazione che è stato creato e gestito da ClusterControl. Vedi sotto:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonTieni presente che solo auto_failover e auto_rejoin sono le variabili che ho aggiunto poiché ClusterControl non lo aggiungerà per impostazione predefinita dopo aver configurato un servizio di bilanciamento del carico MaxScale (consulta questo blog su come configurare MaxScale utilizzando ClusterControl). Non dimenticare che è necessario riavviare MariaDB MaxScale dopo aver applicato le modifiche nel file di configurazione. Corri,
systemctl restart maxscalee sei a posto.
Prima di procedere con il test di failover, controlliamo prima lo stato del cluster:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Sembra fantastico!
Ho ucciso il master solo con il comando killer puro KILL -9 $(pidof mysqld) nel mio nodo master e vedo, senza alcuna sorpresa, il monitor si è accorto rapidamente di questo e attiva il failover. Vedi i log come segue:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Ora diamo un'occhiata allo stato di salute del suo cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Il nodo 192.168.10.10 che in precedenza era il master è inattivo. Ho provato a riavviare e vedere se si attivava il rejoin automatico e, come hai notato nel registro al momento 2019-06-28 06:39:20.165, è stato così veloce rilevare lo stato del nodo e quindi impostare automaticamente la configurazione senza problemi per l'attivazione del DBA.
Ora, controllando infine il suo stato, sembra perfettamente funzionante come previsto. Vedi sotto:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Il mio ex maestro è stato riparato e recuperato e voglio passare dall'altra parte
Anche il passaggio al tuo precedente master non è un problema. Puoi operare con maxctrl (o maxadmin nelle versioni precedenti di MaxScale) o tramite ClusterControl UI (come dimostrato in precedenza).
Facciamo solo riferimento allo stato precedente dell'integrità del cluster di replica in precedenza e volevamo riportare 192.168.10.10 (attualmente slave) al suo stato master. Prima di procedere, potrebbe essere necessario identificare prima il monitor che utilizzerai. Puoi verificarlo con il seguente comando di seguito:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Una volta che lo hai, puoi eseguire il seguente comando di seguito per passare:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKQuindi controlla di nuovo lo stato del cluster,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Sembra perfetto!
I registri ti mostreranno dettagliatamente come è andata e la sua serie di azioni durante il passaggio. Vedi i dettagli di seguito:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]In caso di commutazione errata, non procederà e quindi genererà un errore come mostrato nel log sopra. Così sarai al sicuro e senza sorprese spaventose.
Rendere il tuo MaxScale altamente disponibile
Anche se è un po' fuori tema per quanto riguarda il failover, volevo aggiungere qui alcuni punti preziosi in merito all'elevata disponibilità e al modo in cui è correlato al failover MariaDB MaxScale.
Rendere il tuo MaxScale altamente disponibile è una parte importante nel caso in cui il tuo sistema si arresti in modo anomalo, si verifichi il danneggiamento del disco o il danneggiamento della macchina virtuale. Queste situazioni sono inevitabili e possono influire sullo stato della configurazione del failover automatico quando si verificano questi cicli di manutenzione imprevisti.
Per un ambiente di tipo cluster di replica, questo è molto vantaggioso e altamente consigliato per una specifica configurazione di MaxScale. Lo scopo è che solo un'istanza MaxScale dovrebbe essere autorizzata a modificare il cluster in un dato momento. Se hai impostato con Keepalived, qui sono le istanze con lo stato di MASTER. MaxScale stesso non conosce il suo stato, ma con maxctrl (o maxadmin nelle versioni precedenti) può impostare un'istanza MaxScale in modalità passiva. A partire dalla versione 2.2.2, un MaxScale passivo si comporta in modo simile a uno attivo con la particolarità che non eseguirà failover, switchover o rejoin. Anche le versioni manuali di questi comandi finiranno per errore. Le differenze di modalità passiva/attiva potrebbero essere ampliate in futuro, quindi resta aggiornato su tali modifiche in MaxScale. Per fare ciò, procedi come segue:
maxctrl: alter maxscale passive true
OKPuoi verificarlo in seguito eseguendo il comando seguente:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Se vuoi vedere come configurare l'alta disponibilità con Keepalived, controlla questo post di MariaDB.
Gestione VIP
Inoltre, poiché MaxScale non ha la gestione VIP integrata, puoi utilizzare Keepalived per gestirlo per te. Puoi semplicemente usare il virtual_ipaddress assegnato al nodo di stato MASTER. È probabile che ciò avvenga con la gestione dell'IP virtuale proprio come fa MHA con la variabile master_failover_script. Come accennato in precedenza, dai un'occhiata a questo post sul blog di installazione di Keepalived con MaxScale di MariaDB.
Conclusione
MariaDB MaxScale è ricco di funzionalità e ha molte capacità, non solo come proxy e bilanciamento del carico, ma offre anche il meccanismo di failover che le grandi organizzazioni stanno cercando. È quasi un software valido per tutti, ma ovviamente presenta limitazioni di cui una determinata applicazione potrebbe aver bisogno in contrasto con altri sistemi di bilanciamento del carico come ProxySQL.
ClusterControl offre anche un meccanismo di failover automatico e rilevamento automatico principale, oltre al ripristino di cluster e nodi con la possibilità di implementare Maxscale e altre tecnologie di bilanciamento del carico.
Ognuno di questi strumenti ha le sue diverse caratteristiche e funzionalità, ma MariaDB MaxScale è ben supportato in ClusterControl e può essere implementato in modo fattibile insieme a Keepalived, HAProxy per aiutarti a velocizzare le tue attività di routine quotidiane.