Durante la modifica di postgresql.conf , potresti aver notato che esiste un'opzione chiamata full_page_writes . Il commento accanto dice qualcosa sulle scritture parziali della pagina e le persone generalmente lo lasciano impostato su on – che è una buona cosa, come spiegherò più avanti in questo post. È comunque utile capire cosa fanno le scritture a pagina intera, perché l'impatto sulle prestazioni potrebbe essere piuttosto significativo.
A differenza del mio precedente post sull'ottimizzazione del checkpoint, questa non è una guida su come ottimizzare il server. Non c'è molto che puoi modificare, in realtà, ma ti mostrerò come alcune decisioni a livello di applicazione (ad esempio la scelta dei tipi di dati) possono interagire con le scritture a pagina intera.
Scritture parziali/Pagine strappate
Allora, di cosa sono scritti a pagina intera? Come il commento in postgresql.conf dice che è un modo per recuperare da scritture di pagine parziali:PostgreSQL utilizza pagine da 8 kB (per impostazione predefinita), ma altre parti dello stack utilizzano dimensioni dei blocchi diverse. I filesystem Linux utilizzano in genere pagine da 4kB (è possibile utilizzare pagine più piccole, ma 4kB è il massimo su x86) e a livello hardware le vecchie unità utilizzavano settori da 512B mentre i nuovi dispositivi spesso scrivono dati in blocchi più grandi (spesso 4kB o anche 8kB) .
Quindi, quando PostgreSQL scrive la pagina da 8kB, gli altri livelli dello stack di archiviazione possono suddividerla in blocchi più piccoli, gestiti separatamente. Ciò presenta un problema per quanto riguarda l'atomicità di scrittura. La pagina PostgreSQL da 8kB può essere divisa in due pagine del filesystem da 4kB e quindi in settori da 512B. Ora, cosa succede se il server si arresta in modo anomalo (interruzione di corrente, bug del kernel, ...)?
Anche se il server utilizza un sistema di archiviazione progettato per gestire tali guasti (SSD con condensatori, controller RAID con batterie, ...), il kernel ha già suddiviso i dati in pagine da 4kB. Quindi è possibile che il database abbia scritto una pagina di dati da 8kB, ma solo una parte di quella è arrivata su disco prima dell'arresto anomalo.
A questo punto probabilmente stai pensando che questo è esattamente il motivo per cui abbiamo il registro delle transazioni (WAL), e hai ragione! Quindi, dopo aver avviato il server, il database leggerà WAL (dall'ultimo checkpoint completato) e applicherà nuovamente le modifiche per assicurarsi che i file di dati siano completi. Semplice.
Ma c'è un problema:il ripristino non applica le modifiche alla cieca, spesso ha bisogno di leggere le pagine di dati ecc. Il che presuppone che la pagina non sia già bloccata in qualche modo, ad esempio a causa di una scrittura parziale. Il che sembra un po' contraddittorio, perché per correggere il danneggiamento dei dati assumiamo che non vi sia alcun danneggiamento dei dati.
Le scritture a pagina intera sono un modo per aggirare questo enigma:quando si modifica una pagina per la prima volta dopo un checkpoint, l'intera pagina viene scritta in WAL. Ciò garantisce che durante il ripristino, il primo record WAL che tocca una pagina contenga l'intera pagina, eliminando la necessità di leggere la pagina, eventualmente interrotta, dal file di dati.
Amplificazione della scrittura
Naturalmente, la conseguenza negativa di ciò è l'aumento della dimensione WAL:la modifica di un singolo byte nella pagina da 8kB registrerà l'intero in WAL. La scrittura a pagina intera avviene solo alla prima scrittura dopo un checkpoint, quindi rendere i checkpoint meno frequenti è un modo per migliorare la situazione:in genere, c'è una breve "esplosione" di scritture a pagina intera dopo un checkpoint, e quindi relativamente poche scritture a pagina intera fino alla fine di un checkpoint.
Chiavi UUID e BIGSERIAL
Ma ci sono alcune interazioni inaspettate con le decisioni di progettazione prese a livello di applicazione. Supponiamo di avere una tabella semplice con chiave primaria, o un BIGSERIAL o UUID e inseriamo i dati al suo interno. Ci sarà una differenza nella quantità di WAL generata (supponendo di inserire lo stesso numero di righe)?
Sembra ragionevole aspettarsi che entrambi i casi producano all'incirca la stessa quantità di WAL, ma come illustrano i seguenti grafici, nella pratica c'è un'enorme differenza.
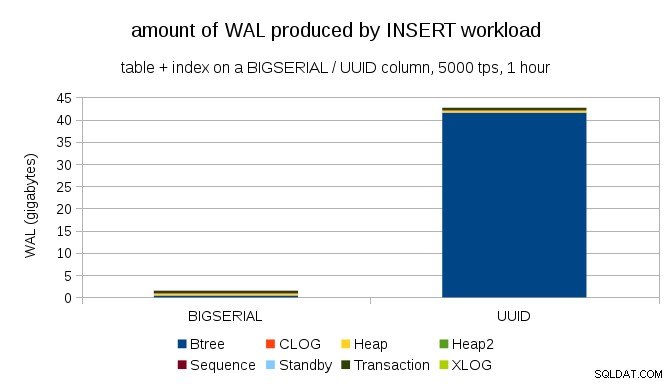
Questo mostra la quantità di WAL prodotta durante un benchmark di 1 ora, ridotta a 5000 inserti al secondo. Con BIGSERIAL chiave primaria questo produce ~2GB di WAL, mentre con UUID è più di 40 GB. Questa è una differenza piuttosto significativa e chiaramente la maggior parte del WAL è associata all'indice che supporta la chiave primaria. Diamo un'occhiata ai tipi di record WAL.
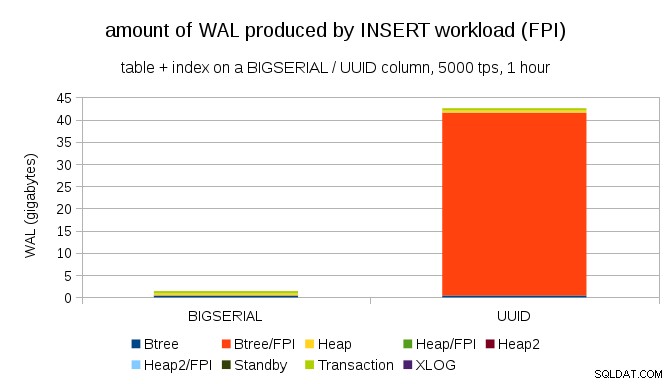
Chiaramente, la stragrande maggioranza dei record sono immagini a pagina intera (FPI), ovvero il risultato di scritture a pagina intera. Ma perché sta succedendo questo?
Ovviamente, ciò è dovuto all'intrinseco UUID casualità. Con BIGSERIAL new sono sequenziali, quindi vengono inseriti nelle stesse pagine foglia nell'indice btree. Poiché solo la prima modifica a una pagina attiva la scrittura a pagina intera, solo una piccola parte dei record WAL sono FPI. Con UUID è un caso completamente diverso, ovviamente:i valori non sono affatto sequenziali, infatti è probabile che ogni inserto tocchi una pagina foglia indice completamente nuova (supponendo che l'indice sia abbastanza grande).
Non c'è molto che il database possa fare:il carico di lavoro è semplicemente di natura casuale, innescando molte scritture a pagina intera.
Non è difficile ottenere un'amplificazione di scrittura simile anche con BIGSERIAL chiavi, ovviamente. Richiede solo un carico di lavoro diverso, ad esempio con UPDATE carico di lavoro, aggiornando casualmente i record con distribuzione uniforme, il grafico si presenta così:
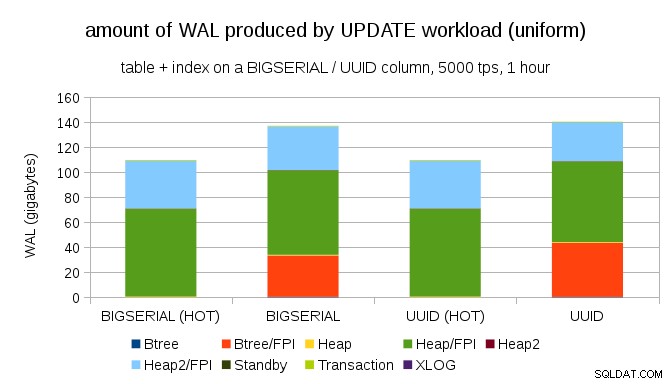
Improvvisamente, le differenze tra i tipi di dati sono scomparse:l'accesso è casuale in entrambi i casi, risultando quasi esattamente la stessa quantità di WAL prodotta. Un'altra differenza è che la maggior parte del WAL è associata a "heap", ovvero tabelle e non indici. I casi "HOT" sono stati progettati per consentire l'ottimizzazione HOT UPDATE (ovvero aggiornare senza dover toccare un indice), che elimina praticamente tutto il traffico WAL relativo all'indice.
Ma potresti obiettare che la maggior parte delle applicazioni non aggiorna l'intero set di dati. Di solito, solo un piccolo sottoinsieme di dati è "attivo":le persone accedono solo ai post degli ultimi giorni su un forum di discussione, ordini irrisolti in un e-shop, ecc. Come cambia i risultati?
Per fortuna, pgbench supporta le distribuzioni non uniformi e, ad esempio, con la distribuzione esponenziale che tocca l'1% di un sottoinsieme di dati nel 25% circa del tempo, il grafico si presenta così:
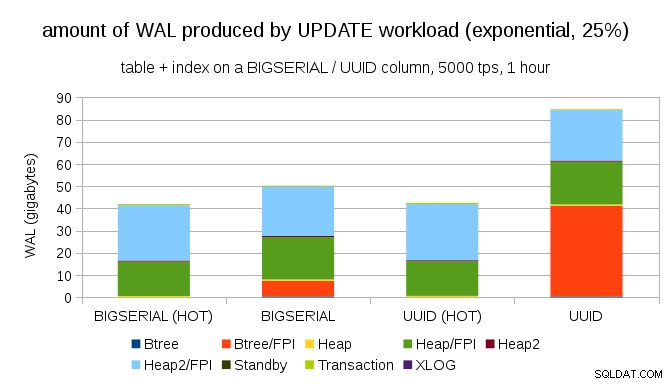
E dopo aver reso la distribuzione ancora più asimmetrica, toccando il sottoinsieme dell'1% circa il 75% delle volte:
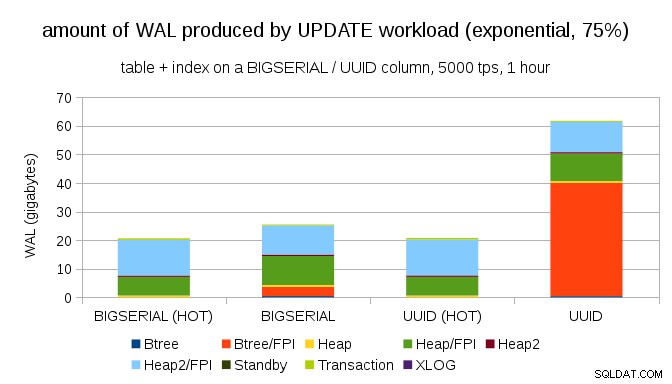
Questo mostra ancora una volta la grande differenza che può fare la scelta dei tipi di dati e anche l'importanza dell'ottimizzazione per gli aggiornamenti HOT.
Pagine da 8kB e 4kB
Una domanda interessante è quanto traffico WAL potremmo risparmiare utilizzando pagine più piccole in PostgreSQL (che richiede la compilazione di un pacchetto personalizzato). Nel migliore dei casi, potrebbe risparmiare fino al 50% WAL, grazie alla registrazione di solo 4kB invece di 8kB di pagine. Per il carico di lavoro con AGGIORNAMENTI distribuiti uniformemente si presenta così:
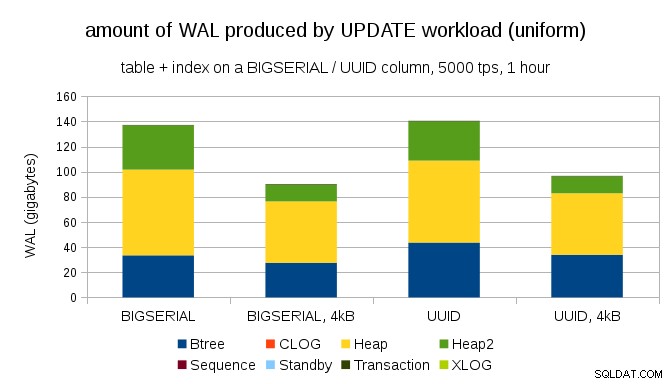
Quindi il risparmio non è esattamente del 50%, ma la riduzione da ~140GB a ~90GB è ancora abbastanza significativa.
Abbiamo ancora bisogno di scritture a pagina intera?
Potrebbe sembrare ridicolo dopo aver spiegato il pericolo di scritture parziali, ma forse disabilitare le scritture a pagina intera potrebbe essere un'opzione praticabile, almeno in alcuni casi.
In primo luogo, mi chiedo se i moderni filesystem Linux siano ancora vulnerabili alle scritture parziali? Il parametro è stato introdotto in PostgreSQL 8.1 rilasciato nel 2005, quindi forse alcuni dei numerosi miglioramenti del filesystem introdotti da allora non lo rendono un problema. Probabilmente non universalmente per carichi di lavoro arbitrari, ma forse l'assunzione di alcune condizioni aggiuntive (ad esempio utilizzando una dimensione della pagina di 4kB in PostgreSQL) sarebbe sufficiente? Inoltre, PostgreSQL non sovrascrive mai solo un sottoinsieme della pagina da 8kB:l'intera pagina viene sempre scritta.
Di recente ho fatto molti test cercando di attivare una scrittura parziale e non sono riuscito a causare ancora un singolo caso. Naturalmente, questa non è davvero una prova che il problema non esiste. Ma anche se il problema persiste, i checksum dei dati potrebbero essere una protezione sufficiente (non risolveranno il problema, ma almeno ti faranno sapere che c'è una pagina rotta).
In secondo luogo, molti sistemi oggigiorno si affidano a repliche di replica in streaming:invece di attendere il riavvio del server dopo un problema hardware (che può richiedere molto tempo) e quindi dedicare più tempo all'esecuzione del ripristino, i sistemi passano semplicemente a uno standby caldo. Se il database sul database primario guasto viene rimosso (e quindi clonato dal nuovo database primario), le scritture parziali non costituiscono un problema.
Ma immagino che se iniziassimo a consigliarlo, allora "Non so come i dati siano stati danneggiati, ho appena impostato full_page_writes=off sui sistemi!" diventerebbe una delle frasi più comuni subito prima della morte per i DBA (insieme al "Ho visto questo serpente su reddit, non è velenoso.").
Riepilogo
Non c'è molto che puoi fare per ottimizzare direttamente le scritture a pagina intera. Per la maggior parte dei carichi di lavoro, la maggior parte delle scritture a pagina intera avviene subito dopo un checkpoint, quindi scompare fino al checkpoint successivo. Quindi è importante ottimizzare i checkpoint in modo che non accadano troppo spesso.
Alcune decisioni a livello di applicazione possono aumentare la casualità delle scritture su tabelle e indici, ad esempio i valori UUID sono intrinsecamente casuali, trasformando anche il semplice carico di lavoro INSERT in aggiornamenti casuali dell'indice. Lo schema utilizzato negli esempi era piuttosto banale:in pratica ci saranno indici secondari, chiavi esterne ecc. Ma l'utilizzo di chiavi primarie BIGSERIAL internamente (e mantenendo l'UUID come chiavi surrogate) ridurrebbe almeno l'amplificazione della scrittura.
Sono davvero interessato alla discussione sulla necessità di scritture a pagina intera sui kernel/filesystem attuali. Purtroppo non ho trovato molte risorse, quindi se hai informazioni rilevanti, fammi sapere.