PostgreSQL è uno dei database open source più avanzati al mondo con molte fantastiche funzionalità. Uno di questi è Streaming Replication (Physical Replication) che è stato introdotto in PostgreSQL 9.0. Si basa su record XLOG che vengono trasferiti al server di destinazione e lì applicati. Tuttavia, è basato su cluster e non possiamo eseguire una replica di un singolo database o di un singolo oggetto (replica selettiva). Nel corso degli anni, siamo stati dipendenti da strumenti esterni come Slony, Bucardo, BDR, ecc. per la replica selettiva o parziale poiché non esisteva alcuna funzionalità a livello di base fino a PostgreSQL 9.6. Tuttavia, PostgreSQL 10 ha creato una funzionalità chiamata Replicazione logica, attraverso la quale possiamo eseguire la replica a livello di database/oggetto.
La replica logica replica le modifiche degli oggetti in base alla loro identità di replica, che in genere è una chiave primaria. È diverso dalla replica fisica, in cui la replica si basa su blocchi e replica byte per byte. La replica logica non richiede una copia binaria esatta sul lato server di destinazione e abbiamo la possibilità di scrivere sul server di destinazione a differenza della replica fisica. Questa caratteristica ha origine dal modulo pglogical.
In questo post del blog parleremo di:
- Come funziona - Architettura
- Caratteristiche
- Casi d'uso - quando è utile
- Limitazioni
- Come raggiungerlo
Come funziona - Architettura di replica logica
La replica logica implementa un concetto di pubblicazione e sottoscrizione (Pubblicazione e sottoscrizione). Di seguito è riportato un diagramma architettonico di livello superiore su come funziona.
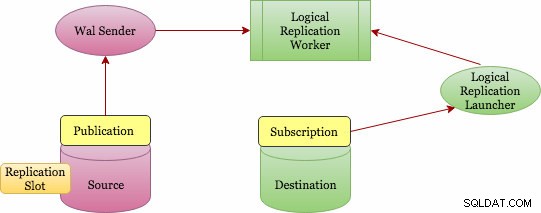
Architettura di replica logica di base
La pubblicazione può essere definita sul server master e il nodo su cui è definita è indicato come "editore". La pubblicazione è un insieme di modifiche da una singola tabella o gruppo di tabelle. È a livello di database e ogni pubblicazione esiste in un database. È possibile aggiungere più tabelle a una singola pubblicazione e una tabella può trovarsi in più pubblicazioni. Dovresti aggiungere oggetti in modo esplicito a una pubblicazione, a meno che tu non scelga l'opzione "TUTTE LE TABELLE" che richiede un privilegio di superutente.
È possibile limitare le modifiche degli oggetti (INSERT, UPDATE e DELETE) da replicare. Per impostazione predefinita, tutti i tipi di operazioni vengono replicati. È necessario disporre di un'identità di replica configurata per l'oggetto che si desidera aggiungere a una pubblicazione. Questo serve per replicare le operazioni UPDATE e DELETE. L'identità di replica può essere una chiave primaria o un indice univoco. Se la tabella non ha una chiave primaria o un indice univoco, può essere impostata per replicare l'identità "completa" in cui prende tutte le colonne come chiave (l'intera riga diventa chiave).
È possibile creare una pubblicazione utilizzando CREA PUBBLICAZIONE. Alcuni comandi pratici sono trattati nella sezione "Come ottenerlo".
La sottoscrizione può essere definita sul server di destinazione e il nodo su cui è definita è indicato come "abbonato". La connessione al database di origine è definita in sottoscrizione. Il nodo dell'abbonato è lo stesso di qualsiasi altro database postgres autonomo e puoi anche usarlo come pubblicazione per ulteriori abbonamenti.
L'abbonamento viene aggiunto utilizzando CREATE SUBSCRIPTION e può essere interrotto/riattivato in qualsiasi momento utilizzando il comando ALTER SUBSCRIPTION e rimosso utilizzando DROP SUBSCRIPTION.
Dopo aver creato una sottoscrizione, la replica logica copia uno snapshot dei dati nel database dell'editore. Una volta fatto, attende le modifiche delta e le invia al nodo di sottoscrizione non appena si verificano.
Tuttavia, come vengono raccolte le modifiche? Chi li manda al bersaglio? E chi li applica al bersaglio? Anche la replica logica si basa sulla stessa architettura della replica fisica. È implementato dai processi "walsender" e "applica". Poiché si basa sulla decodifica WAL, chi avvia la decodifica? Il processo walsender è responsabile dell'avvio della decodifica logica del WAL e del caricamento del plug-in di decodifica logica standard (pgoutput). Il plug-in trasforma le modifiche lette da WAL nel protocollo di replica logica e filtra i dati in base alle specifiche di pubblicazione. I dati vengono quindi trasferiti continuamente utilizzando il protocollo di replica in streaming all'application worker, che mappa i dati su tabelle locali e applica le singole modifiche man mano che vengono ricevute, nell'ordine transazionale corretto.
Registra tutti questi passaggi nei file di registro durante la configurazione. Possiamo vedere i messaggi nella sezione "Come raggiungerlo" più avanti nel post.
Caratteristiche della replica logica
- La replica logica replica gli oggetti dati in base alla loro identità di replica (generalmente a
- chiave primaria o indice univoco).
- Il server di destinazione può essere utilizzato per le scritture. Puoi avere indici e definizioni di sicurezza diversi.
- La replica logica ha il supporto per versioni incrociate. A differenza della replica in streaming, la replica logica può essere impostata tra diverse versioni di PostgreSQL (> 9.4, però)
- La replica logica esegue il filtraggio basato sugli eventi
- Se confrontata, la replica logica ha un'amplificazione in scrittura inferiore rispetto alla replica in streaming
- Le pubblicazioni possono avere più abbonamenti
- La replica logica offre flessibilità di archiviazione attraverso la replica di set più piccoli (anche tabelle partizionate)
- Carico minimo del server rispetto alle soluzioni basate su trigger
- Consente lo streaming parallelo tra i publisher
- La replica logica può essere utilizzata per migrazioni e aggiornamenti
- La trasformazione dei dati può essere eseguita durante la configurazione.
Casi d'uso - Quando è utile la replica logica?
È molto importante sapere quando utilizzare la replica logica. Altrimenti, non otterrai molti vantaggi se il tuo caso d'uso non corrisponde. Quindi, ecco alcuni casi d'uso su quando utilizzare la replica logica:
- Se desideri consolidare più database in un unico database per scopi analitici.
- Se la tua esigenza è replicare i dati tra diverse versioni principali di PostgreSQL.
- Se desideri inviare modifiche incrementali in un singolo database o in un sottoinsieme di un database ad altri database.
- Se si concede l'accesso ai dati replicati a diversi gruppi di utenti.
- Se si condivide un sottoinsieme del database tra più database.
Limiti della replica logica
La replica logica presenta alcune limitazioni su cui la community lavora continuamente per superare:
- Le tabelle devono avere lo stesso nome completo tra pubblicazione e sottoscrizione.
- Le tabelle devono avere una chiave primaria o una chiave univoca
- La replica reciproca (bidirezionale) non è supportata
- Non replica lo schema/DDL
- Non replica le sequenze
- Non replica TRUNCATE
- Non replica oggetti di grandi dimensioni
- Gli abbonamenti possono avere più colonne o un diverso ordine di colonne, ma i tipi e i nomi delle colonne devono corrispondere tra Pubblicazione e Abbonamento.
- Privilegi di superutente per aggiungere tutte le tabelle
- Non puoi trasmettere in streaming sullo stesso host (l'abbonamento verrà bloccato).
Come ottenere la replica logica
Di seguito sono riportati i passaggi per ottenere la replica logica di base. Possiamo discutere di scenari più complessi in seguito.
-
Inizializza due diverse istanze per la pubblicazione e la sottoscrizione e inizia.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Parametri da modificare prima di avviare le istanze (sia per la pubblicazione che per le istanze di sottoscrizione).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server startedAltri parametri possono essere predefiniti per l'impostazione di base.
-
Modificare il file pg_hba.conf per consentire la replica. Tieni presente che questi valori dipendono dal tuo ambiente, tuttavia, questo è solo un esempio di base (sia per le istanze di pubblicazione che di sottoscrizione).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Crea un paio di tabelle di test per replicare e inserire alcuni dati nell'istanza di pubblicazione.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Crea la struttura delle tabelle sull'istanza di sottoscrizione poiché la replica logica non replica la struttura.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Crea pubblicazione sull'istanza di pubblicazione (porta 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Crea la sottoscrizione sull'istanza di sottoscrizione (porta 5556) alla pubblicazione creata nel passaggio 6.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msDal registro:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedCome puoi vedere nel messaggio AVVISO, ha creato uno slot di replica che assicura che la pulizia WAL non debba essere eseguita fino a quando lo snapshot iniziale o le modifiche delta non vengono trasferite al database di destinazione. Quindi il mittente WAL ha iniziato a decodificare le modifiche e l'applicazione della replica logica ha funzionato quando vengono avviati sia pub che sub. Quindi avvia la sincronizzazione della tabella.
-
Verifica i dati sull'istanza di abbonamento.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#Come puoi vedere, i dati sono stati replicati tramite lo snapshot iniziale.
-
Verifica le modifiche delta.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
Questi sono i passaggi per una configurazione di base della replica logica.