La rimozione e la prevenzione della frammentazione degli indici fanno da tempo parte delle normali operazioni di manutenzione del database, non solo in SQL Server, ma su molte piattaforme. La frammentazione dell'indice influisce sulle prestazioni per molte ragioni e la maggior parte delle persone parla degli effetti di piccoli blocchi casuali di I/O che possono verificarsi fisicamente nell'archiviazione basata su disco come qualcosa da evitare. La preoccupazione generale relativa alla frammentazione dell'indice è che influisce sulle prestazioni delle scansioni limitando le dimensioni degli I/O read-ahead. Si basa su questa comprensione limitata dei problemi causati dalla frammentazione dell'indice che alcune persone hanno iniziato a far circolare l'idea che la frammentazione dell'indice non ha importanza con i dispositivi di archiviazione a stato solido (SSD) e che puoi semplicemente ignorare la frammentazione dell'indice in futuro.
Tuttavia, questo non è il caso per una serie di motivi. Questo articolo spiegherà e dimostrerà uno di questi motivi:la frammentazione dell'indice può influire negativamente sulla scelta del piano di esecuzione per le query. Ciò si verifica perché la frammentazione dell'indice generalmente porta un indice con più pagine (queste pagine extra provengono da divisione di pagine operazioni, come descritto in questo post su questo sito), e quindi l'utilizzo di tale indice è ritenuto avere un costo maggiore da Query Optimizer di SQL Server.
Diamo un'occhiata a un esempio.
La prima cosa da fare è creare un database di test e un set di dati appropriati da usare per esaminare in che modo la frammentazione dell'indice può influire sulla scelta del piano di query in SQL Server. Lo script seguente creerà un database con due tabelle con dati identici, una molto frammentata e una minimamente frammentata.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Dopo aver ricostruito l'indice, possiamo esaminare i livelli di frammentazione con la seguente query:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Risultati:

Qui possiamo vedere che la nostra GuidHighFragmentation la tabella è frammentata al 99% e utilizza il 31% in più di spazio sulla pagina rispetto a GuidLowFragmentation tabella nel database, nonostante abbiano le stesse 7.000.000 di righe di dati. Se eseguiamo una query di aggregazione di base su ciascuna delle tabelle e confrontiamo i piani di esecuzione su un'installazione predefinita (con opzioni e valori di configurazione predefiniti) di SQL Server utilizzando SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


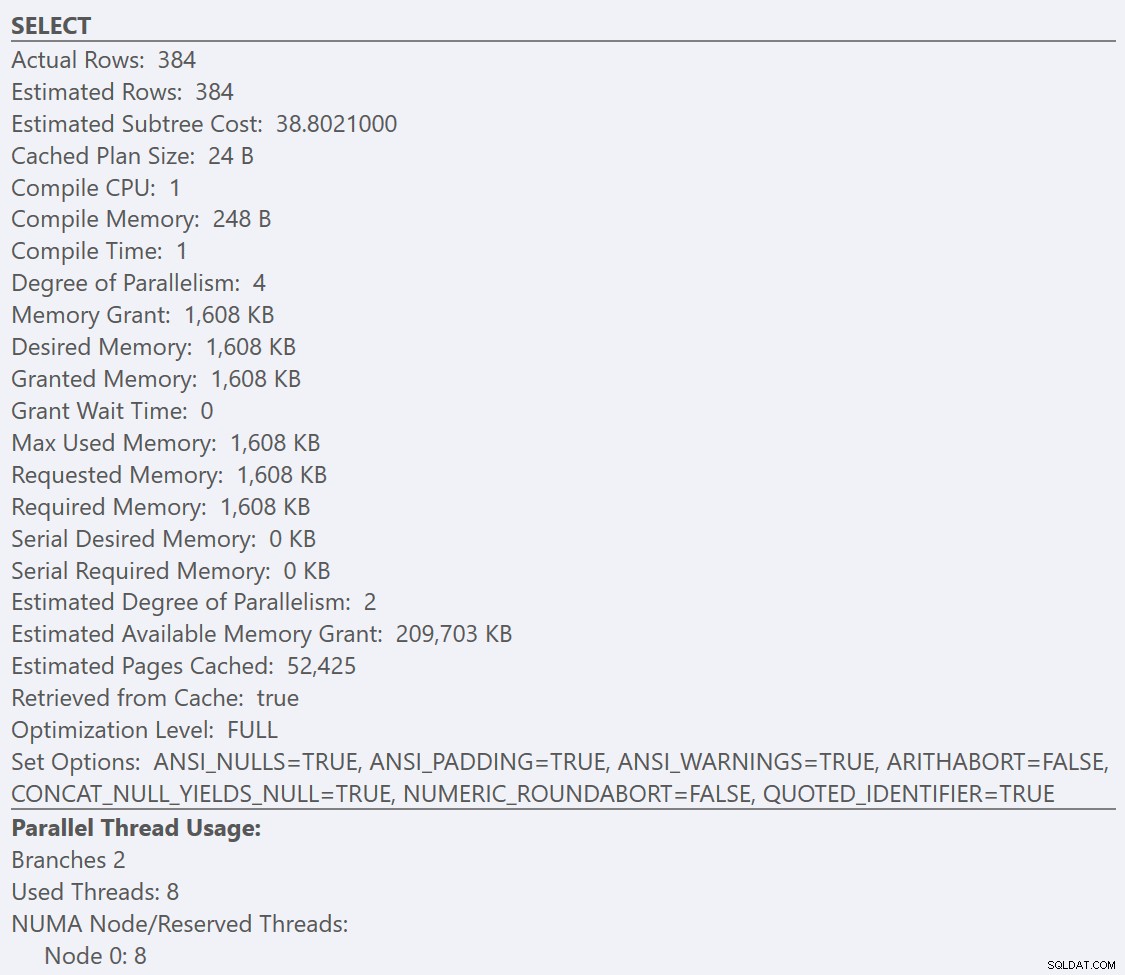

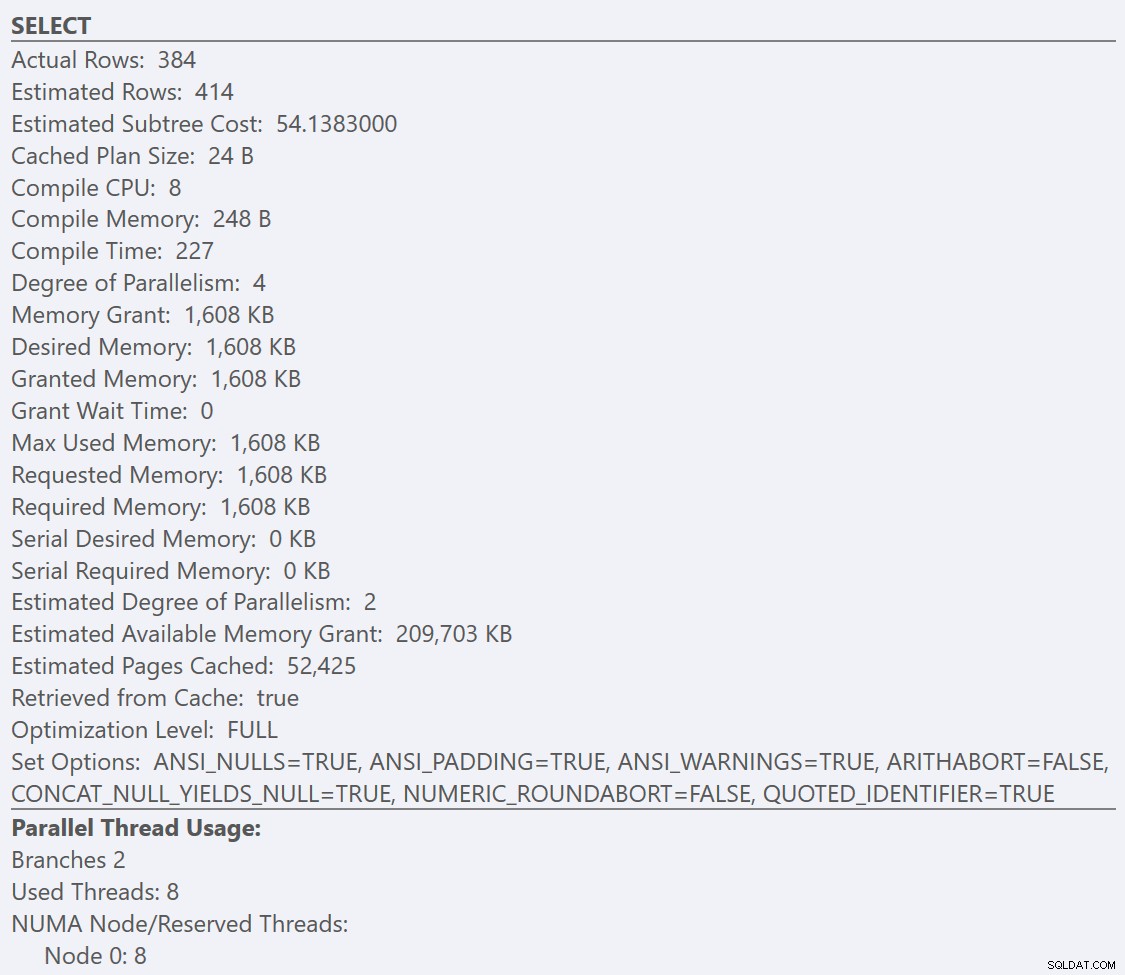
Se osserviamo i suggerimenti di SELECT operatore per ogni piano, il piano per la GuidLowFragmentation table ha un costo della query di 38,80 (la terza riga in basso dalla parte superiore della descrizione comando) rispetto a un costo della query di 54,14 per il piano per il piano GuidHighFragmentation.
In una configurazione predefinita per SQL Server, entrambe queste query finiscono per generare un piano di esecuzione parallela poiché il costo stimato della query è superiore alla "soglia di costo per il parallelismo" dell'opzione sp_configure predefinita di 5. Questo perché Query Optimizer produce prima un seriale plan (che può essere eseguito solo da un singolo thread) durante la compilazione del piano per una query. Se il costo stimato di quel piano seriale supera il valore configurato della "soglia di costo per il parallelismo", viene invece generato e memorizzato nella cache un piano parallelo.
Tuttavia, cosa succede se l'opzione sp_configure "soglia di costo per il parallelismo" non è impostata sul valore predefinito di 5 ed è impostata su un valore superiore? È una procedura consigliata (e corretta) aumentare questa opzione dal valore predefinito basso di 5 a un valore compreso tra 25 e 50 (o anche molto più alto) per evitare che le query di piccole dimensioni incorrano nell'overhead aggiuntivo di andare in parallelo.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Dopo aver seguito le linee guida sulle migliori pratiche e aver aumentato la "soglia di costo per il parallelismo" a 50, rieseguendo le query si ottiene lo stesso piano di esecuzione per GuidHighFragmentation tabella, ma la GuidLowFragmentation il costo seriale della query, 44,68, è ora al di sotto del valore della "soglia di costo per il parallelismo" (ricorda che il suo costo parallelo stimato era 38,80), quindi otteniamo un piano di esecuzione seriale:
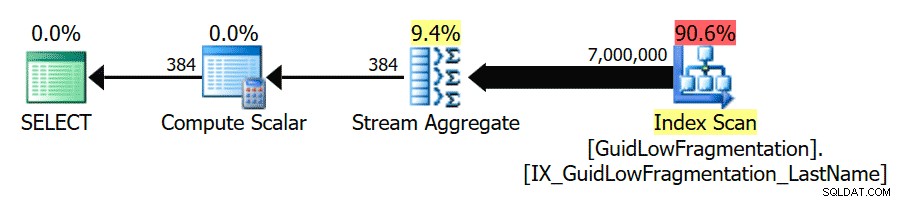
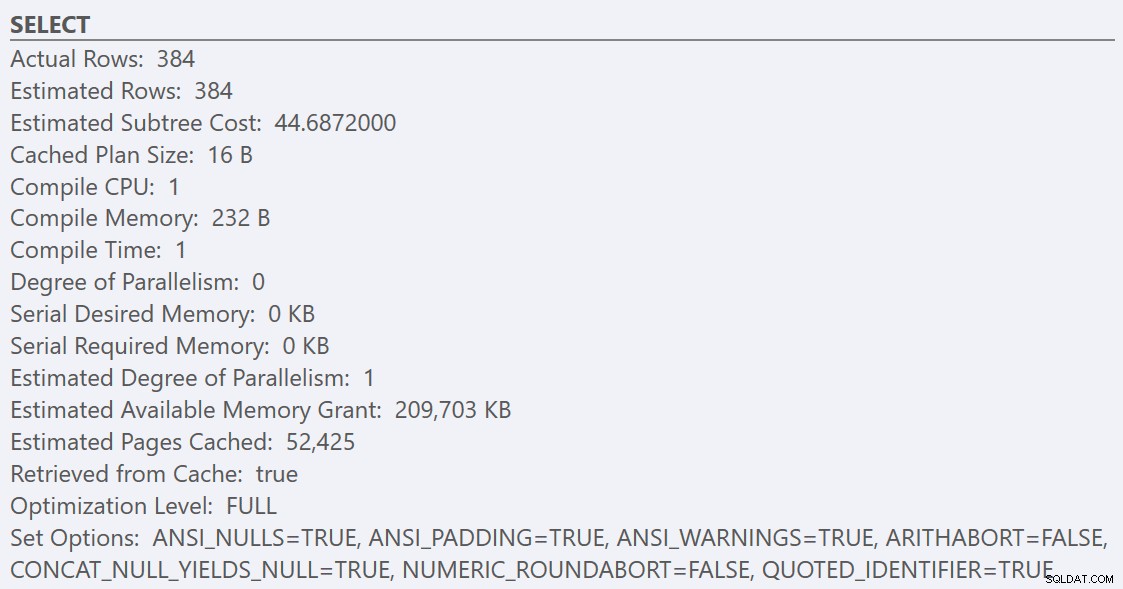
Lo spazio di pagina aggiuntivo nella GuidHighFragmentation l'indice cluster ha mantenuto il costo al di sopra dell'impostazione delle migliori pratiche per la "soglia di costo per il parallelismo" e ha portato a un piano parallelo.
Ora immagina che questo fosse un sistema in cui hai seguito la guida delle migliori pratiche e inizialmente configurato la "soglia di costo per il parallelismo" su un valore di 50. Poi in seguito hai seguito il consiglio fuorviante di ignorare del tutto la frammentazione dell'indice.
Invece di essere una query di base, è più complessa, ma se viene eseguita anche molto frequentemente sul tuo sistema e, a causa della frammentazione dell'indice, il conteggio delle pagine sposta il costo su un piano parallelo, utilizzerà più CPU e di conseguenza, influiscono sulle prestazioni complessive del carico di lavoro.
Cosa fai? Aumentate la "soglia di costo per il parallelismo" in modo che la query mantenga un piano di esecuzione seriale? Indichi la query con OPTION(MAXDOP 1) e la forzi semplicemente a un piano di esecuzione seriale?
Tieni presente che è probabile che la frammentazione dell'indice non influisca solo su una tabella nel database, ora che la stai ignorando completamente; è probabile che molti indici cluster e non cluster siano frammentati e abbiano un numero di pagine superiore al necessario, quindi i costi di molte operazioni di I/O stanno aumentando a causa della diffusa frammentazione dell'indice, portando potenzialmente a molte query inefficienti piani.
Riepilogo
Non puoi semplicemente ignorare completamente la frammentazione dell'indice come alcuni potrebbero voler farti credere. Tra gli altri aspetti negativi di questa operazione, i costi accumulati per l'esecuzione delle query ti raggiungeranno, con cambiamenti del piano delle query perché Query Optimizer è un ottimizzatore basato sui costi e quindi considera giustamente quegli indici frammentati più costosi da utilizzare.
Le query e lo scenario qui sono ovviamente inventati, ma abbiamo visto modifiche al piano di esecuzione causate dalla frammentazione nella vita reale sui sistemi client.
Devi assicurarti di affrontare la frammentazione degli indici per quegli indici in cui la frammentazione causa problemi di prestazioni del carico di lavoro, indipendentemente dall'hardware che stai utilizzando.