Autore ospite:Monica Rathbun (@SQLEspresso)
A volte i problemi di prestazioni hardware, come la latenza di I/O del disco, si riducono a un carico di lavoro non ottimizzato piuttosto che a prestazioni hardware inferiori. Molti amministratori di database, me incluso, vogliono immediatamente incolpare lo storage per la lentezza. Prima di spendere un sacco di soldi per un nuovo hardware, dovresti sempre esaminare il tuo carico di lavoro per I/O non necessari.
Cose da esaminare
| Articolo | I/O Impact | Possibili soluzioni |
|---|---|---|
| Indici non utilizzati | Scritture extra | Rimuovi / Disattiva Indice |
| Indici mancanti | Letture extra | Aggiungi indice/indici di copertura |
| Conversioni implicite | Letture e scritture extra | Campo nascosto o cast alla fonte prima di valutare il valore |
| Funzioni | Letture e scritture extra | Rimossi, converti i dati prima della valutazione |
| ETL | Letture e scritture extra | Usa SSIS, Replica, Change Data Capture, Gruppi di disponibilità |
| Ordina e raggruppa per | Letture e scritture extra | Rimuoverli ove possibile |
Indici non utilizzati
Conosciamo tutti il potere di un indice. Avere gli indici appropriati può fare anni luce di differenza nella velocità delle query. Tuttavia, quanti di noi mantengono continuamente i propri indici al di là della ricostruzione e delle riorganizzazioni degli indici? È importante eseguire regolarmente uno script di indicizzazione per valutare quali indici vengono effettivamente utilizzati. Personalmente utilizzo le query diagnostiche di Glenn Berry per farlo.
Sarai sorpreso di scoprire che alcuni dei tuoi indici non sono stati affatto letti. Questi indici mettono a dura prova le risorse, specialmente su una tabella altamente transazionale. Quando osservi i risultati, presta attenzione a quegli indici che hanno un numero elevato di scritture combinato con un numero basso di letture. In questo esempio, puoi vedere che sto sprecando scritture. L'indice non cluster è stato scritto 11 milioni di volte, ma letto solo due volte.

Comincio disabilitando gli indici che rientrano in questa categoria, quindi li elimino dopo aver confermato che non si sono verificati problemi. L'esecuzione di questo esercizio di routine può ridurre notevolmente le scritture I/O non necessarie sul sistema, ma tieni presente che le statistiche di utilizzo sui tuoi indici sono valide solo quanto l'ultimo riavvio, quindi assicurati di aver raccolto i dati per un intero ciclo aziendale prima di cancellare un indice come "inutile".
Indici mancanti
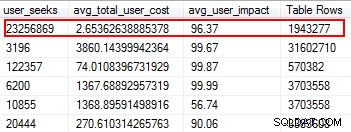
Gli indici mancanti sono una delle cose più facili da correggere; dopotutto, quando esegui un piano di esecuzione, ti dirà se non sono stati trovati indici, ma sarebbe stato utile. Ma aspetta, spero che tu non stia semplicemente aggiungendo arbitrariamente indici sulla base di questo suggerimento. In questo modo è possibile creare indici duplicati e indici che potrebbero avere un utilizzo minimo e quindi sprecare I/O. Ancora una volta, tornando agli script di Glenn, ci fornisce un ottimo strumento per valutare l'utilità di un indice fornendo ricerche degli utenti, impatto sull'utente e numero di righe. Presta attenzione a quelli con letture elevate insieme a basso costo e impatto. Questo è un ottimo punto di partenza e ti aiuterà a ridurre l'I/O in lettura.
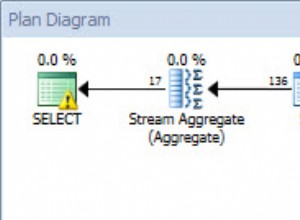
Conversioni implicite
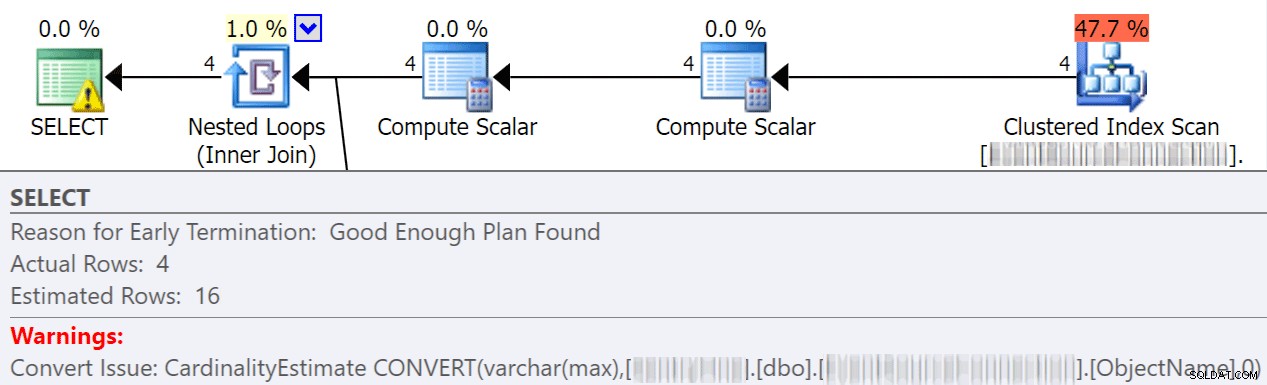
Le conversioni implicite spesso si verificano quando una query confronta due o più colonne con tipi di dati diversi. Nell'esempio seguente, il sistema deve eseguire ulteriori operazioni di I/O per confrontare una colonna varchar(max) con una colonna nvarchar(4000), che porta a una conversione implicita e, in definitiva, a una scansione anziché a una ricerca. Correggendo le tabelle in modo che abbiano tipi di dati corrispondenti o semplicemente convertendo questo valore prima della valutazione, puoi ridurre notevolmente l'I/O e migliorare la cardinalità (le righe stimate che l'ottimizzatore dovrebbe aspettarsi).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias entra molto più nel dettaglio in questo fantastico post:" Quanto sono costose le conversioni implicite a lato della colonna?"
Funzioni
Una delle cose più evitabili e facili da risolvere che ho incontrato che consente di risparmiare sulle spese di I/O è la rimozione delle funzioni da dove clausole. Un esempio perfetto è un confronto di date, come mostrato di seguito.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Che si tratti di un'istruzione JOIN o di una clausola WHERE, ciò fa sì che ogni colonna venga convertita prima che venga valutata. Semplicemente convertendo queste colonne prima della valutazione in una tabella temporanea puoi eliminare un sacco di I/O non necessari.
O, ancora meglio, non eseguire alcuna conversione (per questo caso specifico, Aaron Bertrand parla qui di evitare le funzioni nella clausola where e nota che questo può comunque essere negativo anche se la conversione a data è sargable).
ETL
Prenditi del tempo per esaminare come vengono caricati i tuoi dati. Stai troncando e ricaricando le tabelle? È possibile invece implementare la replica, una replica AG di sola lettura o la spedizione dei log? Tutte le tabelle vengono scritte per essere effettivamente lette? Come stai caricando i dati? È tramite stored procedure o SSIS? Esaminare cose come questa può ridurre drasticamente l'I/O.
Nel mio ambiente, ho scoperto che troncavamo 48 tabelle al giorno con oltre 120 milioni di righe ogni mattina. Inoltre, caricavamo 9,6 milioni di righe all'ora. Puoi immaginare quanto I/O non necessario ha creato. Nel mio caso, l'implementazione della replica transazionale è stata la mia soluzione preferita. Una volta implementato, abbiamo avuto molti meno reclami da parte degli utenti per rallentamenti durante i nostri tempi di caricamento, che inizialmente erano stati attribuiti allo storage lento.
Ordina per e raggruppa per
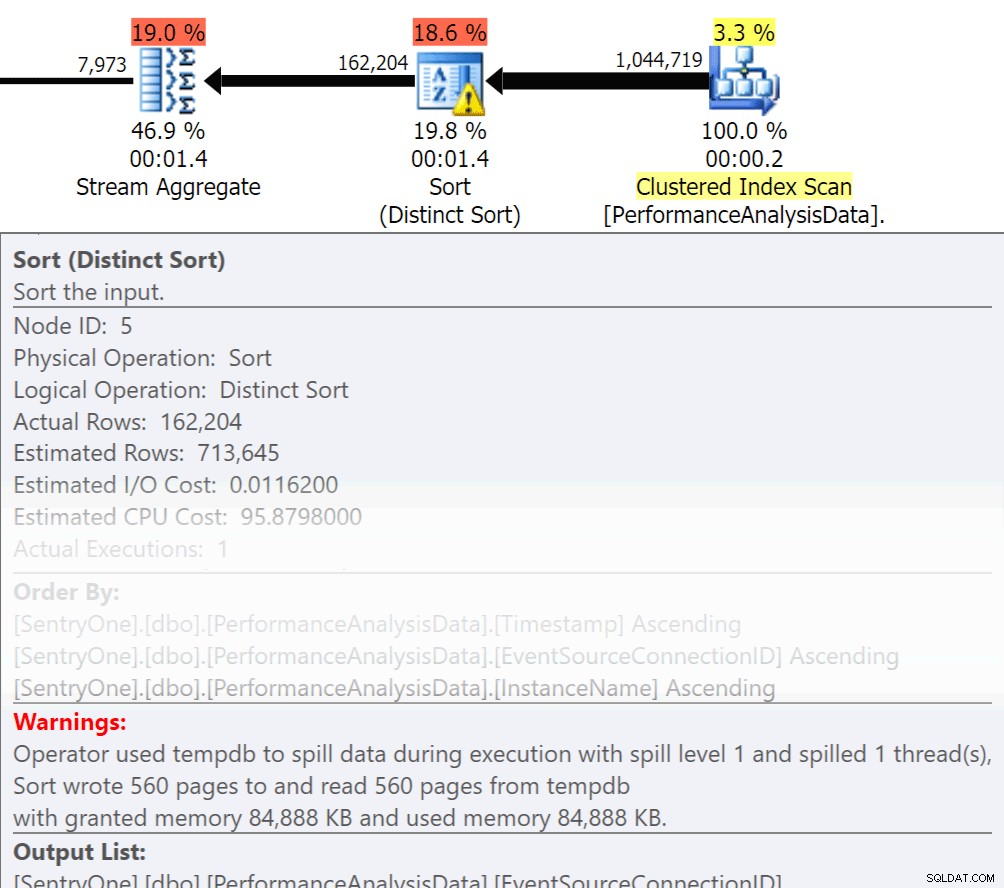 Chiediti, quei dati devono essere restituiti in ordine? Abbiamo davvero bisogno di raggrupparci nella procedura o possiamo gestirlo in un rapporto o in un'applicazione? Le operazioni Ordina per e Raggruppa per possono causare il riversamento delle letture sul disco, causando I/O su disco aggiuntivo. Se queste azioni sono garantite, assicurati di disporre di indici di supporto e nuove statistiche sulle colonne ordinate o raggruppate. Ciò aiuterà l'ottimizzatore durante la creazione del piano. Dal momento che a volte utilizziamo Order By e Group By nelle tabelle temporanee. assicurati di aver attivato la creazione automatica delle statistiche per TEMPDB e i database degli utenti. Più aggiornate sono le statistiche, migliore è la cardinalità che l'ottimizzatore può ottenere, con conseguenti piani migliori, meno spill over e meno I/O.
Chiediti, quei dati devono essere restituiti in ordine? Abbiamo davvero bisogno di raggrupparci nella procedura o possiamo gestirlo in un rapporto o in un'applicazione? Le operazioni Ordina per e Raggruppa per possono causare il riversamento delle letture sul disco, causando I/O su disco aggiuntivo. Se queste azioni sono garantite, assicurati di disporre di indici di supporto e nuove statistiche sulle colonne ordinate o raggruppate. Ciò aiuterà l'ottimizzatore durante la creazione del piano. Dal momento che a volte utilizziamo Order By e Group By nelle tabelle temporanee. assicurati di aver attivato la creazione automatica delle statistiche per TEMPDB e i database degli utenti. Più aggiornate sono le statistiche, migliore è la cardinalità che l'ottimizzatore può ottenere, con conseguenti piani migliori, meno spill over e meno I/O.
Ora Group By ha sicuramente il suo posto quando si tratta di aggregare i dati invece di restituire un sacco di righe. Ma la chiave qui è ridurre l'I/O, l'aggiunta dell'aggregazione si aggiunge all'I/O.
Riepilogo
Queste sono solo le cose da fare sulla punta dell'iceberg, ma un ottimo punto di partenza per ridurre l'I/O. Prima di incolpare l'hardware dei tuoi problemi di latenza, dai un'occhiata a cosa puoi fare per ridurre al minimo la pressione del disco.
Informazioni sull'autore
 Monica Rathbun è attualmente consulente presso Denny Cherry &Associates Consulting e MVP di Microsoft Data Platform. È stata un DBA Lone per 15 anni, lavorando con tutti gli aspetti di SQL Server e Oracle. Viaggia parlando a SQLSaturdays aiutando altri DBA Lone con tecniche su come si può fare il lavoro di molti. Monica è il leader del gruppo utenti SQL Server di Hampton Roads ed è un mentore regionale del Mid-Atlantic Pass. Puoi sempre trovare Monica su Twitter (@SQLEspresso) che distribuisce suggerimenti e trucchi utili ai suoi follower. Quando non è impegnata con il lavoro, la troverai a fare il tassista per le sue due figlie avanti e indietro alle lezioni di ballo.
Monica Rathbun è attualmente consulente presso Denny Cherry &Associates Consulting e MVP di Microsoft Data Platform. È stata un DBA Lone per 15 anni, lavorando con tutti gli aspetti di SQL Server e Oracle. Viaggia parlando a SQLSaturdays aiutando altri DBA Lone con tecniche su come si può fare il lavoro di molti. Monica è il leader del gruppo utenti SQL Server di Hampton Roads ed è un mentore regionale del Mid-Atlantic Pass. Puoi sempre trovare Monica su Twitter (@SQLEspresso) che distribuisce suggerimenti e trucchi utili ai suoi follower. Quando non è impegnata con il lavoro, la troverai a fare il tassista per le sue due figlie avanti e indietro alle lezioni di ballo.