Tutti i miei post di quest'anno riguardavano reazioni istintive alle statistiche di attesa, ma in questo post sto deviando da quel tema per parlare di un mio particolare bug bear:il contatore delle prestazioni dell'aspettativa di vita della pagina (che chiamerò PLE ).
Cosa significa PLE?
Ci sono tutti i tipi di affermazioni errate sull'aspettativa di vita delle pagine su Internet e le più eclatanti sono quelle che specificano che il valore 300 è la soglia per cui dovresti essere preoccupato.
Per capire perché questa affermazione è così fuorviante, è necessario capire che cos'è effettivamente PLE.
La definizione di PLE è il tempo previsto, in secondi, in cui una pagina di file di dati letta nel buffer pool (la cache in memoria delle pagine di file di dati) rimarrà in memoria prima di essere espulsa dalla memoria per fare spazio a dati diversi pagina del file. Un altro modo di pensare a PLE è una misura istantanea della pressione sul pool di buffer per liberare spazio per le pagine lette dal disco. Per entrambe queste definizioni, è meglio un numero più alto.
Che cos'è una buona soglia PLE?
Un PLE di 300 significa che l'intero pool di buffer viene effettivamente svuotato e riletto ogni cinque minuti. Quando la guida alla soglia per PLE di 300 è stata fornita per la prima volta da Microsoft, intorno al 2005/2006, quel numero potrebbe aver avuto più senso poiché la quantità media di memoria su un server era molto più bassa.
Al giorno d'oggi, dove i server dispongono abitualmente di 64 GB, 128 GB e quantità di memoria superiori, avere all'incirca la stessa quantità di dati letti dal disco ogni cinque minuti sarebbe probabilmente la causa di un paralizzante problema di prestazioni
In realtà quindi, quando PLE è in bilico a 300 o meno, il tuo server è già in gravi difficoltà. Inizierai a essere molto preoccupato, molto prima che il PLE sia così basso.
Allora, qual è la soglia da utilizzare quando dovresti essere preoccupato?
Bene, questo è solo il punto. Non posso darti una soglia, poiché quel numero varierà per tutti. Se vuoi davvero usare un numero, il mio collega Jonathan Kehayias ha escogitato una formula:
(Memoria del pool di buffer in GB/4) x 300Anche quel numero è alquanto arbitrario e il tuo chilometraggio varierà.
Non mi piace consigliare alcun numero. Il mio consiglio è di misurare il tuo PLE quando le prestazioni sono al livello desiderato – questo è la soglia che utilizzi.
Quindi inizi a preoccuparti non appena il PLE scende al di sotto di quella soglia? No. Inizi a preoccuparti quando il PLE scende al di sotto di tale soglia e rimane al di sotto di tale soglia, o se scende precipitosamente e non sai perché.
Questo perché ci sono alcune operazioni che causeranno un calo di PLE (ad esempio l'esecuzione di DBCC CHECKDB o le ricostruzioni dell'indice possono farlo a volte) e non sono motivo di preoccupazione. Ma se vedi un grande calo di PLE e non sai cosa lo sta causando, allora dovresti preoccuparti.
Ti starai chiedendo come DBCC CHECKDB può causare un calo di PLE quando lo sfavorisce e si sforza di evitare di svuotare il pool di buffer con i dati che utilizza (vedi questo post sul blog per una spiegazione). È perché la concessione della memoria di esecuzione della query per DBCC CHECKDB viene calcolato in modo errato da Query Optimizer e può causare una notevole riduzione delle dimensioni del pool di buffer (la memoria per la concessione viene sottratta al pool di buffer) e un conseguente calo di PLE.
Come monitori PLE?
Questa è la parte difficile. La maggior parte delle persone andrà direttamente a Buffer Manager oggetto prestazioni in PerfMon e monitorare l'Page life expectancy contatore. È questo l'approccio giusto? Molto probabilmente no.
Direi che la grande maggioranza dei server oggi utilizza l'architettura NUMA e questo ha un profondo effetto sul modo in cui monitori PLE.
Quando è coinvolto NUMA, il pool di buffer viene suddiviso in nodi buffer, con un nodo buffer per nodo NUMA che SQL Server può "vedere". Ciascun nodo buffer tiene traccia di PLE separatamente e di Buffer Manager:Page life expectancy counter è la media dei PLE del nodo buffer. Se stai solo monitorando il pool di buffer complessivo PLE, la pressione su uno dei nodi buffer potrebbe essere mascherata dalla media (ne parlo in un post sul blog qui).
Pertanto, se il tuo server utilizza NUMA, devi monitorare il singolo Buffer Node:Page life expectancy contatori (ci sarà un oggetto prestazioni Buffer Node per ogni nodo NUMA), altrimenti è opportuno monitorare il Buffer Manager:Page life expectancy contatore.
Ancora meglio è utilizzare uno strumento di monitoraggio come SQL Sentry Performance Advisor, che mostrerà questo contatore come parte della dashboard, tenendo conto dei nodi NUMA sul server, e ti consentirà di configurare facilmente gli avvisi.
Esempi di utilizzo di Performance Advisor
Di seguito è riportato un esempio di una schermata di Performance Advisor per un sistema con un singolo nodo NUMA:
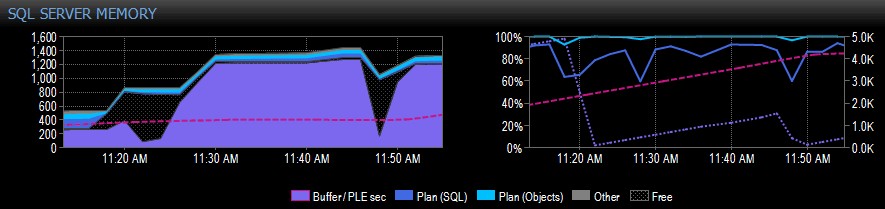
Sul lato destro della cattura, la linea tratteggiata in rosa è il PLE tra le 10:30 e le 11:20 circa:sta salendo costantemente fino a 5.000 circa, un numero davvero salutare. Poco prima delle 11:20 c'è un enorme dislivello, poi ricomincia a salire fino alle 11:45, dove scende di nuovo.
Questo è in genere ciò che vedresti se il pool di buffer è pieno, con tutte le pagine utilizzate, e quindi viene eseguita una query che causa la lettura di un'enorme quantità di dati diversi dal disco, spostando gran parte di ciò che è già in memoria e causando un precipitoso calo del PLE. Se non sapessi cosa ha causato qualcosa del genere, vorresti indagare, come descrivo più avanti.
Come secondo esempio, l'acquisizione della schermata seguente proviene da uno dei nostri client DBA remoti in cui il server ha due nodi NUMA (puoi vedere che ci sono due linee PLE viola) e dove utilizziamo ampiamente Performance Advisor:

Sul server di questo client, ogni mattina intorno alle 5 del mattino, viene avviato un processo di manutenzione dell'indice e controllo della coerenza che causa la caduta del PLE in entrambi i nodi del buffer. Si tratta di un comportamento previsto, quindi non è necessario indagare finché PLE si ripresenta durante il giorno.
Cosa puoi fare per eliminare PLE?
Se la causa del calo di PLE non è nota, puoi fare una serie di cose:
- Se il problema si verifica ora, esamina quali query stanno causando letture utilizzando
sys.dm_os_waiting_tasksDMV per vedere quali thread sono in attesa di lettura delle pagine dal disco (ovvero quelli in attesa diPAGEIOLATCH_SH), quindi correggi le query. - Se il problema si è verificato in passato, cerca nella DMV sys.dm_exec_query_stats query con un numero elevato di letture fisiche oppure utilizza uno strumento di monitoraggio in grado di fornirti tali informazioni (ad es. la visualizzazione SQL superiore in Performance Advisor) e quindi risolvi queste domande.
- Correlare l'eliminazione PLE con i lavori dell'agente pianificati che eseguono la manutenzione del database.
- Cerca query con assegnazioni di memoria di esecuzione di query molto grandi utilizzando
sys.dm_exec_query_memory_grantsDMV, quindi correggi le query.
Il mio precedente post qui spiega di più su #1 e #2, e uno script per indagare sulle attese che si verificano su un server e collegarsi ai loro piani di query è qui.
Il "risolvere queste domande" va oltre lo scopo di questo post, quindi lo lascerò per un'altra volta o come esercizio per il lettore ☺
Riepilogo
Non cadere nella trappola di credere a qualsiasi soglia PLE consigliata che potresti leggere online. Il modo migliore per reagire alle modifiche PLE è quando PLE scende al di sotto di qualsiasi tuo il livello di comfort è e rimane lì – questo è l'indicazione di un problema di prestazioni su cui dovresti indagare.
Nel prossimo articolo della serie, discuterò un'altra causa comune dell'ottimizzazione delle prestazioni istintiva. Fino ad allora, buona risoluzione dei problemi!