Per quanto riguarda i piani di esecuzione grafica, c'è solo un'icona per un ordinamento fisico in SQL Server:

Questa stessa icona viene utilizzata per i tre operatori di ordinamento logico:Ordina, Ordinamento in alto N e Ordinamento distinto:
Andando un livello più in profondità, ci sono quattro diverse implementazioni di Ordina nel motore di esecuzione (senza contare l'ordinamento batch per i join di ciclo ottimizzati, che non è un ordinamento completo e comunque non visibile nei piani). Se utilizzi SQL Server 2014, il numero di implementazioni di ordinamento del motore di esecuzione aumenta a sette:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (solo SQL Server 2014)
- CQScanInMemSortNew
- Procedura OLTP (Hekaton) in memoria compilata in modo nativo Ordinamento primi N (solo SQL Server 2014)
- Procedura in memoria OLTP (Hekaton) compilata in modo nativo Ordinamento generale (solo SQL Server 2014)
Questo articolo esamina queste implementazioni di ordinamento e quando ciascuna viene usata in SQL Server. La prima parte copre i primi quattro elementi dell'elenco.
1. CQScanSortNew
Questa è la classe di ordinamento più generale, utilizzata quando nessuna delle altre opzioni disponibili è applicabile. L'ordinamento generale utilizza una concessione di memoria dell'area di lavoro riservata appena prima dell'inizio dell'esecuzione della query. Questa concessione è proporzionale alle stime della cardinalità e alle aspettative sulla dimensione media delle righe e non può essere aumentata dopo l'inizio dell'esecuzione della query.
L'attuale implementazione sembra utilizzare una varietà di ordinamento di unione interno (forse ordinamento di unione binaria), passando all'ordinamento di unione esterno (con più passaggi se necessario) se la memoria riservata risulta essere insufficiente. L'ordinamento di unione esterno utilizza tempdb fisico spazio per le esecuzioni di ordinamento che non si adattano alla memoria (comunemente noto come sort spill). L'ordinamento generale può anche essere configurato per applicare la distinzione durante l'operazione di ordinamento.
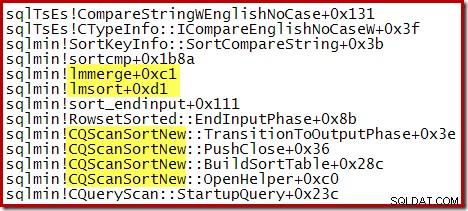
La seguente traccia dello stack parziale mostra un esempio di CQScanSortNew stringhe di ordinamento delle classi utilizzando un ordinamento di unione interno:
Nei piani di esecuzione, Ordina fornisce informazioni sulla frazione della concessione di memoria complessiva dell'area di lavoro della query disponibile per l'ordinamento durante la lettura dei record (la fase di input) e la frazione disponibile quando l'output ordinato viene consumato dagli operatori del piano padre (la fase di output ).
La frazione di concessione della memoria è un numero compreso tra 0 e 1 (dove 1 =100% della memoria concessa) ed è visibile in SSMS evidenziando l'ordinamento e guardando nella finestra Proprietà. L'esempio seguente è stato tratto da una query con un solo operatore di ordinamento, quindi dispone dell'intera concessione della memoria dell'area di lavoro della query durante le fasi di input e output:
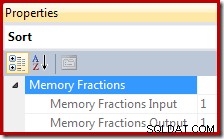
Le frazioni di memoria riflettono il fatto che durante la sua fase di input, Sort deve condividere la concessione di memoria complessiva della query con gli operatori che consumano memoria che eseguono contemporaneamente al di sotto di essa nel piano di esecuzione. Allo stesso modo, durante la fase di output, Sort deve condividere la memoria concessa con gli operatori che consumano memoria che eseguono contemporaneamente al di sopra di essa nel piano di esecuzione.
Il Query Processor è abbastanza intelligente da sapere che alcuni operatori stanno bloccando (stop-and-go), segnando efficacemente i limiti in cui la concessione di memoria può essere riciclata e riutilizzata. Nei piani paralleli, la frazione di concessione di memoria disponibile per un ordinamento generale viene suddivisa in modo uniforme tra i thread e non può essere ribilanciata in fase di esecuzione in caso di skew (una causa comune di versamento nei piani di ordinamento parallelo).
SQL Server 2012 e versioni successive includono informazioni aggiuntive sulla concessione di memoria minima per l'area di lavoro richiesta per inizializzare gli operatori del piano che consumano memoria e il desiderato concessione di memoria (la quantità "ideale" di memoria stimata necessaria per completare l'intera operazione in memoria). In un piano di esecuzione successivo all'esecuzione ("effettivo"), ci sono anche nuove informazioni su eventuali ritardi nell'acquisizione della concessione di memoria, sulla quantità massima di memoria effettivamente utilizzata e su come la prenotazione di memoria è stata distribuita tra i nodi NUMA.
I seguenti esempi di AdventureWorks utilizzano tutti un CQScanSortNew ordinamento generale:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; La prima query (un ordinamento non distinto) produce il seguente piano di esecuzione:
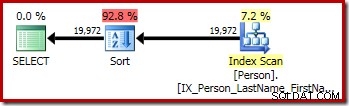
La seconda e la terza query (equivalenti) producono questo piano:
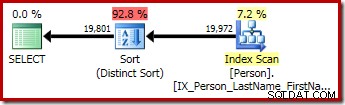
CQScanSortNew può essere utilizzato sia per l'ordinamento generale logico che per l'ordinamento distinto logico.
2. CQScanTopSortNew
CQScanTopSortNew è una sottoclasse di CQScanSortNew utilizzato per implementare un Top N Sort (come suggerisce il nome). CQScanTopSortNew delega gran parte del lavoro principale a CQScanSortNew , ma modifica il comportamento dettagliato in modi diversi, a seconda del valore di N.
Per N> 100, CQScanTopSortNew è essenzialmente solo un normale CQScanSortNew sort che interrompe automaticamente la produzione di righe ordinate dopo N righe. Per N <=100, CQScanTopSortNew conserva solo i primi N risultati correnti durante l'operazione di ordinamento e tiene traccia del valore di chiave più basso attualmente idoneo.
Ad esempio, durante un ordinamento Top N ottimizzato (dove N <=100) lo stack di chiamate presenta RowsetTopN mentre con l'ordinamento generale nella sezione 1 abbiamo visto RowsetSorted :
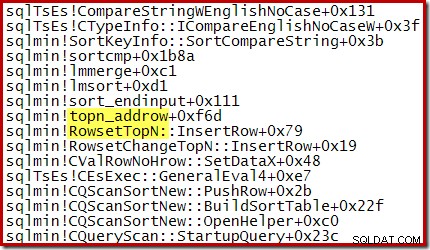
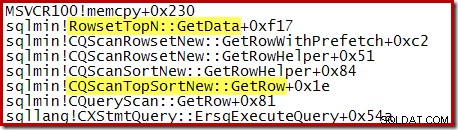
Per un ordinamento Primi N in cui N> 100, lo stack di chiamate nella stessa fase di esecuzione è lo stesso dell'ordinamento generale visto in precedenza:
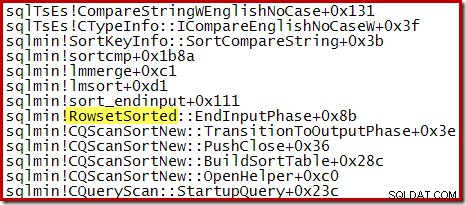
Si noti che CQScanTopSortNew il nome della classe non appare in nessuna di queste tracce dello stack. Ciò è semplicemente dovuto al modo in cui funziona la sottoclasse. In altri punti durante l'esecuzione di queste query, CQScanTopSortNew i metodi (ad esempio Open, GetRow e CreateTopNTable) vengono visualizzati in modo esplicito nello stack di chiamate. Ad esempio, quanto segue è stato preso in un momento successivo nell'esecuzione della query e mostra il CQScanTopSortNew nome della classe:
Ordinamento Top N e Query Optimizer
Query Optimizer non sa nulla di Top N Sort, che è solo un operatore del motore di esecuzione. Quando l'ottimizzatore produce un albero di output con un operatore fisico Top immediatamente sopra un ordinamento fisico (non distinto), una riscrittura post-ottimizzazione può comprimere le due operazioni fisiche in un unico operatore Top N Ordina. Anche nel caso N> 100, ciò rappresenta un risparmio sul passaggio di righe in modo iterativo tra un output di ordinamento e un input superiore.
La query seguente utilizza un paio di flag di traccia non documentati per mostrare l'output dell'ottimizzatore e la riscrittura post-ottimizzazione in azione:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
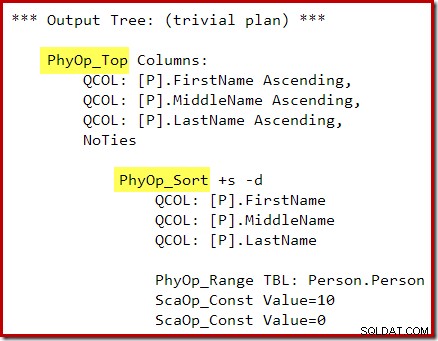
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); L'albero di output dell'ottimizzatore mostra gli operatori fisici Top e Ordina separati:
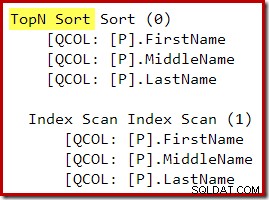
Dopo la riscrittura post-ottimizzazione, Top e Ordina sono stati compressi in un unico Top N Ordina:
Il piano di esecuzione grafico per la query T-SQL sopra mostra il singolo operatore Top N Sort:
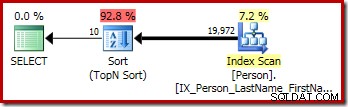
Rompere la riscrittura dell'ordinamento Top N
La riscrittura post-ottimizzazione Top N Sort può comprimere solo un Top N adiacente e un ordinamento non distinto in un Top N Sort. L'aggiunta di DISTINCT (o della clausola GROUP BY equivalente) alla query precedente impedirà la riscrittura dell'ordinamento Top N:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Il piano di esecuzione finale per questa query include operatori Top e Ordina (Ordinamento distinto) separati:
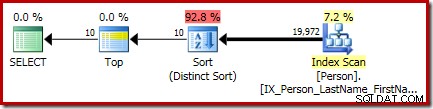
L'ordinamento è il generale CQScanSortNew classe in esecuzione in modalità distinta come visto nella sezione 1 in precedenza.
Un secondo modo per impedire la riscrittura in un Top N Sort consiste nell'introdurre uno o più operatori aggiuntivi tra Top e Sort. Ad esempio:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; L'output di Query Optimizer ora ha un'operazione tra l'inizio e l'ordinamento, quindi non viene generato un ordinamento primi N durante la fase di riscrittura post-ottimizzazione:
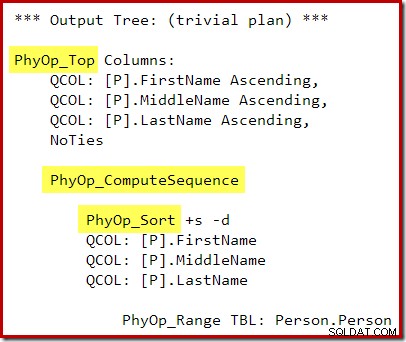
Il piano di esecuzione è:

La sequenza di calcolo (implementata come due segmenti e un progetto di sequenza) tra Top e Ordina impedisce la compressione di Top e Ordina in un singolo operatore Top N Sort. Naturalmente si otterranno risultati corretti da questo piano, ma l'esecuzione potrebbe essere un po' meno efficiente di quanto avrebbe potuto essere con l'operatore combinato Top N Sort.
3. CQScanIndexSortNew
CQScanIndexSortNew viene utilizzato solo per l'ordinamento nei piani di costruzione dell'indice DDL. Riutilizza alcune delle strutture di ordinamento generali che abbiamo già visto, ma aggiunge ottimizzazioni specifiche per gli inserimenti di indici. È anche l'unica classe di ordinamento che può richiedere dinamicamente più memoria dopo l'inizio dell'esecuzione.
La stima della cardinalità è spesso accurata per un piano di costruzione di indici poiché il numero totale di righe nella tabella è in genere una quantità nota. Questo non vuol dire che le concessioni di memoria per gli ordinamenti dei piani di costruzione dell'indice saranno sempre accurate; rende solo un po' meno facile la demo. Quindi, l'esempio seguente utilizza un'estensione non documentata, ma ragionevolmente nota, del comando UPDATE STATISTICS per ingannare l'ottimizzatore facendogli pensare che la tabella su cui stiamo costruendo un indice abbia una sola riga:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Il piano di esecuzione post-esecuzione ("effettivo") per la compilazione dell'indice non mostra un avviso per un ordinamento rovesciato (se eseguito su SQL Server 2012 o versioni successive) nonostante la stima di 1 riga e le 19.972 righe effettivamente ordinate:
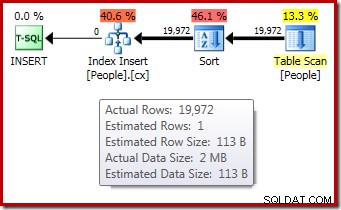
La conferma che la concessione di memoria iniziale è stata espansa dinamicamente viene dall'esame delle proprietà dell'iteratore radice. Inizialmente alla query sono stati concessi 1024 KB di memoria, ma alla fine ha consumato 1576 KB:
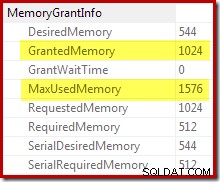
L'aumento dinamico della memoria concessa può anche essere monitorato utilizzando l'evento esteso del canale di debug sort_memory_grant_adjustment. Questo evento viene generato ogni volta che l'allocazione di memoria viene aumentata dinamicamente. Se questo evento viene monitorato, possiamo acquisire una traccia dello stack quando viene pubblicato, tramite eventi estesi (con qualche configurazione scomoda e un flag di traccia) o da un debugger allegato, come di seguito:
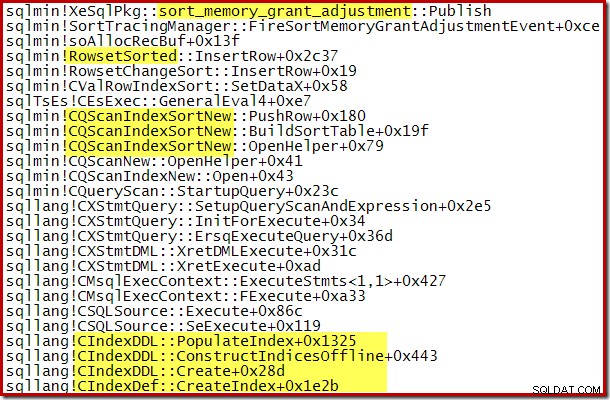
L'espansione dinamica della concessione della memoria può anche aiutare con piani di creazione di indici paralleli in cui la distribuzione delle righe tra i thread non è uniforme. Tuttavia, la quantità di memoria che può essere consumata in questo modo non è illimitata. SQL Server verifica ogni volta che è necessaria un'espansione per vedere se la richiesta è ragionevole date le risorse disponibili in quel momento.
È possibile ottenere informazioni dettagliate su questo processo abilitando il flag di traccia non documentato 1504, insieme a 3604 (per l'output del messaggio nella console) o 3605 (output nel log degli errori di SQL Server). Se il piano di compilazione dell'indice è parallelo, solo 3605 è efficace perché i lavoratori paralleli non possono inviare messaggi di traccia cross-thread alla console.
La sezione seguente dell'output di traccia è stata acquisita durante la creazione di un indice di dimensioni moderate su un'istanza di SQL Server 2014 con memoria limitata:
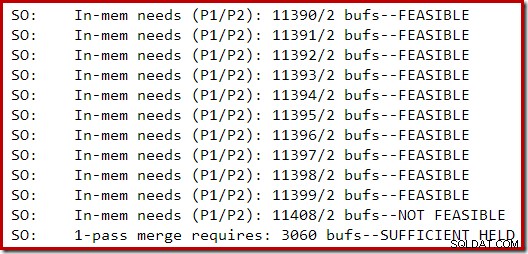
L'espansione della memoria per l'ordinamento è proseguita fino a quando la richiesta non è stata considerata fattibile, a quel punto è stato stabilito che era già disponibile memoria sufficiente per il completamento di uno spill di ordinamento a passaggio singolo.
4. CQScanPartitionSortNew
Questo nome di classe potrebbe suggerire che questo tipo di ordinamento viene utilizzato per i dati di tabelle partizionate o durante la creazione di indici su tabelle partizionate, ma nessuno di questi è effettivamente il caso. L'ordinamento dei dati partizionati utilizza CQScanSortNew o CQScanTopSortNew come normale; l'ordinamento delle righe per l'inserimento in un indice partizionato generalmente utilizza CQScanIndexSortNew come visto nella sezione 3.
Il CQScanPartitionSortNew la classe sort è presente solo in SQL Server 2014. Viene utilizzata solo quando si ordinano le righe in base all'ID della partizione, prima dell'inserimento in un indice columnstore cluster partizionato . Nota che viene utilizzato solo per partizionati archivio di colonne in cluster; i piani di inserimento columnstore cluster regolari (non partizionati) non traggono vantaggio da un ordinamento.
Gli inserimenti in un indice columnstore cluster partizionato non presenteranno sempre un ordinamento. È una decisione basata sui costi che dipende dal numero stimato di righe da inserire. Se l'ottimizzatore stima che valga la pena ordinare gli inserimenti per partizione per ottimizzare l'I/O, l'operatore di inserimento columnstore avrà il DMLRequestSort proprietà impostata su true e un CQScanPartitionSortNew sort potrebbe apparire nel piano di esecuzione.
La demo in questa sezione utilizza una tabella permanente di numeri sequenziali. Se non ne possiedi uno, puoi utilizzare il seguente script per crearne uno:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); La demo stessa prevede la creazione di una tabella indicizzata columnstore cluster partizionata e l'inserimento di righe sufficienti (dalla tabella Numbers sopra) per convincere l'ottimizzatore a utilizzare un ordinamento di partizione pre-inserimento:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Il piano di esecuzione per l'inserimento mostra l'ordinamento utilizzato per garantire che le righe arrivino all'iteratore di inserimento del columnstore cluster nell'ordine dell'ID della partizione:

Uno stack di chiamate acquisito durante CQScanPartitionSortNew l'ordinamento era in corso è mostrato di seguito:
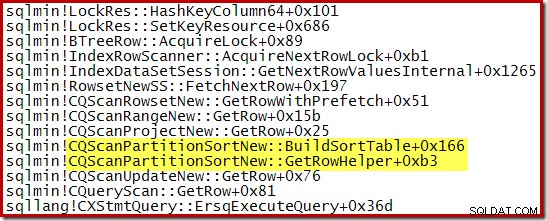
C'è qualcos'altro di interessante in questa classe di ordinamento. Gli ordinamenti normalmente consumano l'intero input nella chiamata al metodo Open. Dopo l'ordinamento, restituiscono il controllo all'operatore padre. Successivamente, l'ordinamento inizia a produrre righe di output ordinate una alla volta nel solito modo tramite le chiamate GetRow. CQScanPartitionSortNew è diverso, come puoi vedere nello stack di chiamate sopra:non consuma il suo input durante il suo metodo Open, attende fino a quando GetRow non viene chiamato dal suo genitore per la prima volta.
Non tutti gli ordinamenti sull'ID partizione che appaiono in un piano di esecuzione che inserisce righe in un indice columnstore cluster partizionato saranno CQScanPartitionSortNew ordinare. Se l'ordinamento viene visualizzato immediatamente a destra dell'operatore di inserimento dell'indice columnstore, è molto probabile che si tratti di un CQScanPartitionSortNew ordina.
Infine, CQScanPartitionSortNew è una delle sole due classi di ordinamento che imposta la proprietà Ordinamento graduale esposta quando le proprietà del piano di esecuzione dell'operatore di ordinamento vengono generate con il flag di traccia non documentato 8666 abilitato:
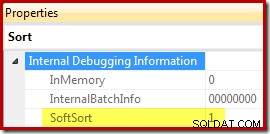
Il significato di "tipo morbido" in questo contesto non è chiaro. Viene monitorato come una proprietà nel framework di Query Optimizer e sembra essere correlato a inserimenti di dati partizionati ottimizzati, ma determinare esattamente cosa significa richiede ulteriori ricerche. Nel frattempo, questa proprietà può essere utilizzata per dedurre che un ordinamento è implementato con CQScanPartitionSortNew senza allegare un debugger. Il significato del flag della proprietà InMemory mostrato sopra sarà trattato nella parte 2. non indicare se è stato eseguito o meno un ordinamento regolare in memoria.
Riepilogo della prima parte
- CQScanSortNew è la classe di ordinamento generale utilizzata quando nessun'altra opzione è applicabile. Sembra che utilizzi una varietà di ordinamento di unione interno in memoria, passando all'ordinamento di unione esterno usando tempdb se lo spazio di lavoro della memoria concesso risulta essere insufficiente. Questa classe può essere utilizzata per l'ordinamento generale e l'ordinamento distinto.
- CQScanTopSortNew implementa Top N Ordina. Dove N <=100, viene eseguito un ordinamento di unione interno in memoria e non si riversa mai su tempdb . Solo i primi n elementi correnti vengono mantenuti in memoria durante l'ordinamento. Per N> 100 CQScanTopSortNew è equivalente a CQScanSortNew ordinamento che si interrompe automaticamente dopo l'output di N righe. Un ordinamento N> 100 può riversarsi su tempdb se necessario.
- Il Top N Sort visualizzato nei piani di esecuzione è una riscrittura successiva all'ottimizzazione delle query. Se Query Optimizer produce un albero di output con un Top adiacente e un ordinamento non distinto, questa riscrittura può comprimere i due operatori fisici in un unico operatore di ordinamento Top N.
- CQScanIndexSortNew viene utilizzato solo nei piani DDL per la creazione di indici. È l'unica classe di ordinamento standard che può acquisire dinamicamente più memoria durante l'esecuzione. In alcune circostanze, gli ordinamenti per la creazione di indici possono ancora riversarsi su disco, anche quando SQL Server decide che un aumento di memoria richiesto non è compatibile con il carico di lavoro corrente.
- CQScanPartitionSortNew è presente solo in SQL Server 2014 e viene utilizzato solo per ottimizzare gli inserimenti in un indice columnstore cluster partizionato. Offre un "ordinamento morbido".
La seconda parte di questo articolo esaminerà CQScanInMemSortNew e i due tipi di stored procedure compilati in modo nativo OLTP in memoria.