Le sette classi di implementazione dell'ordinamento di SQL Server sono:
- CQScanSortNew
- CQScanTopSortNew
- CQScanIndexSortNew
- CQScanPartitionSortNew (solo SQL Server 2014)
- CQScanInMemSortNew
- Procedura OLTP (Hekaton) in memoria compilata in modo nativo Ordinamento primi N (solo SQL Server 2014)
- Procedura in memoria OLTP (Hekaton) compilata in modo nativo Ordinamento generale (solo SQL Server 2014)
I primi quattro tipi sono stati trattati nella prima parte di questo articolo.
5. CQScanInMemSortNew
Questa classe di ordinamento ha una serie di caratteristiche interessanti, alcune delle quali uniche:
- Come suggerisce il nome, si ordina sempre interamente in memoria; non si riverserà mai su tempdb
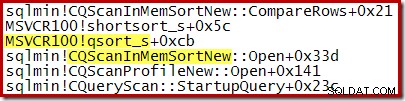
- L'ordinamento viene sempre eseguito utilizzando quicksort qsort_s nella libreria di runtime C standard MSVCR100
- Può eseguire tutti e tre i tipi di ordinamento logico:Generale, Primi N e Ordinamento distinto
- Può essere utilizzato per ordinamenti software per partizione in cluster columnstore (vedere la sezione 4 nella parte 1)
- La memoria che utilizza potrebbe essere memorizzata nella cache con il piano anziché essere riservata appena prima dell'esecuzione
- Può essere identificato come un ordinamento in memoria nei piani di esecuzione
- È possibile ordinare un massimo di 500 valori
- Non viene mai utilizzato per gli ordinamenti per la creazione di indici (vedere la sezione 3 nella parte 1)
CQScanInMemSortNew è una classe di ordinamento che non incontrerai spesso. Poiché esegue sempre l'ordinamento in memoria utilizzando un algoritmo di ordinamento rapido della libreria standard, non sarebbe una buona scelta per le attività di ordinamento generale del database. In effetti, questa classe di ordinamento viene utilizzata solo quando tutti i suoi input sono costanti di runtime (inclusi i riferimenti @variable). Dal punto di vista del piano di esecuzione, ciò significa che l'input per l'operatore di ordinamento deve essere una Scansione costante operatore, come dimostrano gli esempi seguenti:
-- Regular Sort on system scalar functions
SELECT X.i
FROM
(
SELECT @@TIMETICKS UNION ALL
SELECT @@TOTAL_ERRORS UNION ALL
SELECT @@TOTAL_READ UNION ALL
SELECT @@TOTAL_WRITE
) AS X (i)
ORDER BY X.i;
-- Distinct Sort on constant literals
WITH X (i) AS
(
SELECT 3 UNION ALL
SELECT 1 UNION ALL
SELECT 1 UNION ALL
SELECT 2
)
SELECT DISTINCT X.i
FROM X
ORDER BY X.i;
-- Top N Sort on variables, constants, and functions
DECLARE
@x integer = 1,
@y integer = 2;
SELECT TOP (1)
X.i
FROM
(
VALUES
(@x), (@y), (123),
(@@CONNECTIONS)
) AS X (i)
ORDER BY X.i; I piani di esecuzione sono:
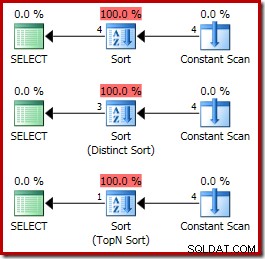
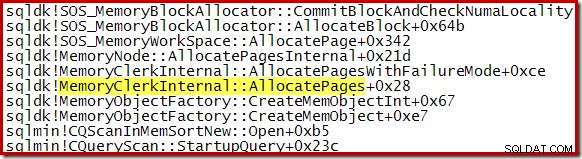
Di seguito è mostrato uno stack di chiamate tipico durante l'ordinamento. Notare la chiamata a qsort_s nella libreria MSVCR100:
Tutti e tre i piani di esecuzione mostrati sopra sono ordinamenti in memoria utilizzando CQScanInMemSortNew con input sufficientemente piccoli da consentire la memorizzazione nella cache della memoria di ordinamento. Queste informazioni non sono esposte per impostazione predefinita nei piani di esecuzione, ma possono essere rivelate utilizzando il flag di traccia non documentato 8666. Quando tale flag è attivo, vengono visualizzate proprietà aggiuntive per l'operatore di ordinamento:
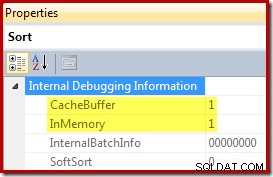
Il buffer della cache è limitato a 62 righe in questo esempio, come illustrato di seguito:
-- Cache buffer limited to 62 rows
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062)--, (063)
) AS X (i)
ORDER BY X.i; Decommenta l'elemento finale in quello script per vedere la proprietà Ordina buffer cache cambiare da 1 a 0:
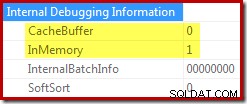
Quando il buffer non è memorizzato nella cache, l'ordinamento in memoria deve allocare memoria durante l'inizializzazione e come richiesto durante la lettura delle righe dal suo input. Quando è possibile utilizzare un buffer memorizzato nella cache, questo lavoro di allocazione della memoria viene evitato.
Lo script seguente può essere utilizzato per dimostrare che il numero massimo di elementi per un CQScanInMemSortNew Quicksort in memoria è 500:
SELECT X.i
FROM
(
VALUES
(001),(002),(003),(004),(005),(006),(007),(008),(009),(010),
(011),(012),(013),(014),(015),(016),(017),(018),(019),(020),
(021),(022),(023),(024),(025),(026),(027),(028),(029),(030),
(031),(032),(033),(034),(035),(036),(037),(038),(039),(040),
(041),(042),(043),(044),(045),(046),(047),(048),(049),(050),
(051),(052),(053),(054),(055),(056),(057),(058),(059),(060),
(061),(062),(063),(064),(065),(066),(067),(068),(069),(070),
(071),(072),(073),(074),(075),(076),(077),(078),(079),(080),
(081),(082),(083),(084),(085),(086),(087),(088),(089),(090),
(091),(092),(093),(094),(095),(096),(097),(098),(099),(100),
(101),(102),(103),(104),(105),(106),(107),(108),(109),(110),
(111),(112),(113),(114),(115),(116),(117),(118),(119),(120),
(121),(122),(123),(124),(125),(126),(127),(128),(129),(130),
(131),(132),(133),(134),(135),(136),(137),(138),(139),(140),
(141),(142),(143),(144),(145),(146),(147),(148),(149),(150),
(151),(152),(153),(154),(155),(156),(157),(158),(159),(160),
(161),(162),(163),(164),(165),(166),(167),(168),(169),(170),
(171),(172),(173),(174),(175),(176),(177),(178),(179),(180),
(181),(182),(183),(184),(185),(186),(187),(188),(189),(190),
(191),(192),(193),(194),(195),(196),(197),(198),(199),(200),
(201),(202),(203),(204),(205),(206),(207),(208),(209),(210),
(211),(212),(213),(214),(215),(216),(217),(218),(219),(220),
(221),(222),(223),(224),(225),(226),(227),(228),(229),(230),
(231),(232),(233),(234),(235),(236),(237),(238),(239),(240),
(241),(242),(243),(244),(245),(246),(247),(248),(249),(250),
(251),(252),(253),(254),(255),(256),(257),(258),(259),(260),
(261),(262),(263),(264),(265),(266),(267),(268),(269),(270),
(271),(272),(273),(274),(275),(276),(277),(278),(279),(280),
(281),(282),(283),(284),(285),(286),(287),(288),(289),(290),
(291),(292),(293),(294),(295),(296),(297),(298),(299),(300),
(301),(302),(303),(304),(305),(306),(307),(308),(309),(310),
(311),(312),(313),(314),(315),(316),(317),(318),(319),(320),
(321),(322),(323),(324),(325),(326),(327),(328),(329),(330),
(331),(332),(333),(334),(335),(336),(337),(338),(339),(340),
(341),(342),(343),(344),(345),(346),(347),(348),(349),(350),
(351),(352),(353),(354),(355),(356),(357),(358),(359),(360),
(361),(362),(363),(364),(365),(366),(367),(368),(369),(370),
(371),(372),(373),(374),(375),(376),(377),(378),(379),(380),
(381),(382),(383),(384),(385),(386),(387),(388),(389),(390),
(391),(392),(393),(394),(395),(396),(397),(398),(399),(400),
(401),(402),(403),(404),(405),(406),(407),(408),(409),(410),
(411),(412),(413),(414),(415),(416),(417),(418),(419),(420),
(421),(422),(423),(424),(425),(426),(427),(428),(429),(430),
(431),(432),(433),(434),(435),(436),(437),(438),(439),(440),
(441),(442),(443),(444),(445),(446),(447),(448),(449),(450),
(451),(452),(453),(454),(455),(456),(457),(458),(459),(460),
(461),(462),(463),(464),(465),(466),(467),(468),(469),(470),
(471),(472),(473),(474),(475),(476),(477),(478),(479),(480),
(481),(482),(483),(484),(485),(486),(487),(488),(489),(490),
(491),(492),(493),(494),(495),(496),(497),(498),(499),(500)
--, (501)
) AS X (i)
ORDER BY X.i; Ancora una volta, decommenta l'ultimo elemento per vedere InMemory Ordina la modifica della proprietà da 1 a 0. Quando ciò accade, CQScanInMemSortNew viene sostituito da CQScanSortNew (vedere la sezione 1) o CQScanTopSortNew (sezione 2). Un non CQScanInMemSortNew sort può ancora essere eseguito in memoria, ovviamente usa solo un algoritmo diverso ed è autorizzato a riversarsi su tempdb se necessario.
6. OLTP in memoria stored procedure compilate in modo nativo Top N Ordina
L'attuale implementazione delle stored procedure OLTP in memoria (precedentemente con nome in codice Hekaton) compilate in modo nativo utilizza una coda di priorità seguita da qsort_s per i primi N ordinamenti, quando vengono soddisfatte le seguenti condizioni:
- La query contiene TOP (N) con una clausola ORDER BY
- Il valore di N è una costante letterale (non una variabile)
- N ha un valore massimo di 8192; Sebbene
- La presenza di join o aggregazioni può ridurre il valore 8192 come documentato qui
Il codice seguente crea una tabella Hekaton contenente 4000 righe:
CREATE DATABASE InMemoryOLTP;
GO
-- Add memory optimized filegroup
ALTER DATABASE InMemoryOLTP
ADD FILEGROUP InMemoryOLTPFileGroup
CONTAINS MEMORY_OPTIMIZED_DATA;
GO
-- Add file (adjust path if necessary)
ALTER DATABASE InMemoryOLTP
ADD FILE
(
NAME = N'IMOLTP',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\IMOLTP.hkf'
)
TO FILEGROUP InMemoryOLTPFileGroup;
GO
USE InMemoryOLTP;
GO
CREATE TABLE dbo.Test
(
col1 integer NOT NULL,
col2 integer NOT NULL,
col3 integer NOT NULL,
CONSTRAINT PK_dbo_Test
PRIMARY KEY NONCLUSTERED HASH (col1)
WITH (BUCKET_COUNT = 8192)
)
WITH
(
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_ONLY
);
GO
-- Add numbers from 1-4000 using
-- Itzik Ben-Gan's number generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 1 AND 4000; Lo script successivo crea un ordinamento Top N adatto in una stored procedure compilata in modo nativo:
-- Natively-compiled Top N Sort stored procedure
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT TOP (2) T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; Il piano di esecuzione stimato è:

Uno stack di chiamate acquisito durante l'esecuzione mostra l'inserimento nella coda di priorità in corso:

Dopo che la compilazione della coda di priorità è stata completata, lo stack di chiamate successivo mostra un passaggio finale attraverso il quicksort della libreria standard:
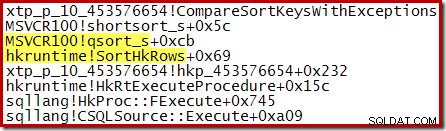
Il xtp_p_* la libreria mostrata in quegli stack di chiamate è la dll compilata in modo nativo per la stored procedure, con il codice sorgente salvato nell'istanza locale di SQL Server. Il codice sorgente viene generato automaticamente dalla definizione della stored procedure. Ad esempio, il file C per questa stored procedure nativa contiene il frammento seguente:
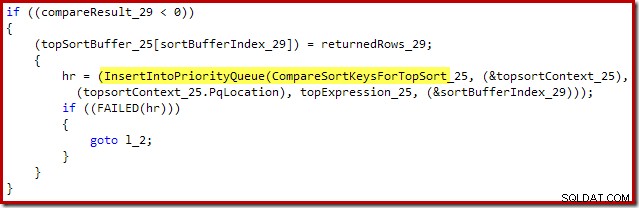
Questo è il più vicino possibile all'accesso al codice sorgente di SQL Server.
7. Procedura memorizzata OLTP in memoria compilata in modo nativo Ordina
Le procedure compilate in modo nativo non supportano attualmente l'ordinamento distinto, ma è supportato l'ordinamento generale non distinto, senza alcuna restrizione sulla dimensione del set. Per dimostrare, aggiungeremo prima 6.000 righe alla tabella di test, per un totale di 10.000 righe:
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
INSERT dbo.Test
(col1, col2, col3)
SELECT
N.n,
ABS(CHECKSUM(NEWID())),
ABS(CHECKSUM(NEWID()))
FROM Nums AS N
WHERE N.n BETWEEN 4001 AND 10000; Ora possiamo eliminare la procedura di test precedente (le procedure compilate in modo nativo non possono attualmente essere modificate) e crearne una nuova che esegua un ordinamento ordinario (non top-n) delle 10.000 righe:
DROP PROCEDURE dbo.TestP;
GO
CREATE PROCEDURE dbo.TestP
WITH EXECUTE AS OWNER, SCHEMABINDING, NATIVE_COMPILATION
AS
BEGIN ATOMIC
WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english'
)
SELECT T.col2
FROM dbo.Test AS T
ORDER BY T.col2
END;
GO
EXECUTE dbo.TestP; Il piano di esecuzione stimato è:

Il tracciamento dell'esecuzione di questo ordinamento mostra che inizia generando più piccole esecuzioni ordinate utilizzando di nuovo Quicksort della libreria standard:
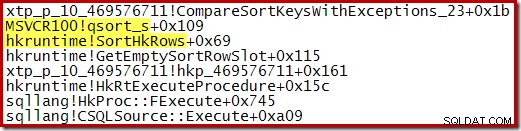
Una volta completato il processo, le esecuzioni ordinate vengono unite, utilizzando uno schema di coda prioritaria:
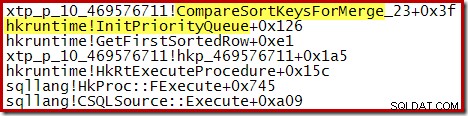
Anche in questo caso, il codice sorgente C per la procedura mostra alcuni dettagli:
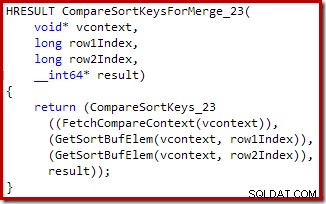
Riepilogo della parte 2
- CQScanInMemSortNew è sempre un quicksort in memoria. È limitato a 500 righe da una scansione costante e può memorizzare nella cache la sua memoria di ordinamento per piccoli input. Un ordinamento può essere identificato come CQScanInMemSortNew ordina utilizzando le proprietà del piano di esecuzione esposte dal flag di traccia 8666.
- L'ordinamento Top N compilato nativo di Hekaton richiede un valore letterale costante per N <=8192 e ordina utilizzando una coda di priorità seguita da un Quicksort standard
- L'ordinamento generale compilato nativo di Hekaton può ordinare un numero qualsiasi di righe, utilizzando l'ordinamento rapido della libreria standard per generare esecuzioni di ordinamento e un ordinamento di unione della coda prioritaria per combinare le esecuzioni. Non supporta l'ordinamento distinto.



