I gruppi di disponibilità, introdotti in SQL Server 2012, rappresentano un cambiamento fondamentale nel modo in cui pensiamo alla disponibilità elevata e al ripristino di emergenza per i nostri database. Una delle grandi cose rese possibili qui è l'offload delle operazioni di sola lettura su una replica secondaria, in modo che l'istanza di lettura/scrittura primaria non sia disturbata da cose fastidiose come la segnalazione dell'utente finale. L'impostazione non è semplice, ma è molto più semplice e gestibile rispetto alle soluzioni precedenti (alza la mano se ti è piaciuto configurare il mirroring e le istantanee e tutta la manutenzione perpetua che ne deriva).
Le persone si entusiasmano molto quando sentono parlare dei gruppi di disponibilità. Poi la realtà colpisce:la funzionalità richiede l'Enterprise Edition di SQL Server (a partire da SQL Server 2014, comunque). L'edizione Enterprise è costosa, soprattutto se si dispone di molti core, e soprattutto dopo l'eliminazione delle licenze basate su CAL (a meno che tu non sia stato sostituito dal 2008 R2, nel qual caso sei limitato ai primi 20 core). Richiede inoltre Windows Server Failover Clustering (WSFC), una complicazione non solo per la dimostrazione della tecnologia su un laptop, ma anche per l'Enterprise Edition di Windows, un controller di dominio e tutta una serie di configurazioni per supportare il clustering. E ci sono anche nuovi requisiti per Software Assurance; un costo aggiuntivo se desideri che le tue istanze di standby siano conformi.
Alcuni clienti non possono giustificare il prezzo. Altri vedono il valore, ma semplicemente non possono permetterselo. Allora, cosa devono fare questi utenti?
Il tuo nuovo eroe:spedizione log
La spedizione di tronchi è in circolazione da secoli. È semplice e funziona. Quasi sempre. E oltre a aggirare i costi di licenza e gli ostacoli alla configurazione presentati dai gruppi di disponibilità, può anche evitare la penalità di 14 byte di cui ha parlato Paul Randal (@PaulRandal) nella newsletter SQLskills Insider di questa settimana (13 ottobre 2014).
Una delle sfide che le persone devono affrontare nell'usare la copia del registro fornita come secondaria leggibile, tuttavia, è che devi espellere tutti gli utenti attuali per applicare eventuali nuovi registri, quindi o gli utenti si infastidiscono perché vengono ripetutamente interrotti dall'esecuzione di query o hai utenti infastiditi perché i loro dati non sono aggiornati. Questo perché le persone si limitano a un unico secondario leggibile.
Non deve essere così; Penso che qui ci sia una soluzione aggraziata e, sebbene possa richiedere molto più lavoro per le gambe in anticipo rispetto, ad esempio, all'attivazione dei gruppi di disponibilità, sarà sicuramente un'opzione interessante per alcuni.
Fondamentalmente, possiamo impostare un certo numero di secondarie, dove accelereremo la nave e ne renderemo solo una secondaria "attiva", usando un approccio round-robin. Il lavoro che spedisce i log sa quale è attualmente attivo, quindi ripristina solo i nuovi log sul server "successivo" usando il WITH STANDBY opzione. L'applicazione di creazione rapporti utilizza le stesse informazioni per determinare in fase di esecuzione quale dovrebbe essere la stringa di connessione per il rapporto successivo eseguito dall'utente. Quando il prossimo backup del log è pronto, tutto cambia di uno e l'istanza che ora diventerà il nuovo secondario leggibile viene ripristinata utilizzando WITH STANDBY .
Per mantenere il modello semplice, supponiamo di avere quattro istanze che fungono da secondarie leggibili e di eseguire backup dei log ogni 15 minuti. In qualsiasi momento, avremo un secondario attivo in modalità standby, con dati non più vecchi di 15 minuti e tre secondari in modalità standby che non gestiscono nuove query (ma potrebbero comunque restituire risultati per query precedenti).
Questo funzionerà meglio se non si prevede che le query durino più di 45 minuti. (Potrebbe essere necessario modificare questi cicli a seconda della natura delle operazioni di sola lettura, di quanti utenti simultanei eseguono query più lunghe e se è mai possibile interrompere gli utenti cacciando tutti fuori.)
Funzionerà meglio anche se le query consecutive eseguite dallo stesso utente possono modificare la stringa di connessione (questa è la logica che dovrà essere nell'applicazione, sebbene sia possibile utilizzare sinonimi o viste a seconda dell'architettura) e contenere dati diversi che hanno cambiato nel frattempo (proprio come se stessero interrogando il database live, in continua evoluzione).
Tenendo presente tutte queste ipotesi, ecco una sequenza illustrativa di eventi per i primi 75 minuti della nostra implementazione:
| tempo | eventi | visivo |
|---|---|---|
| 12:00 (t0) |
| 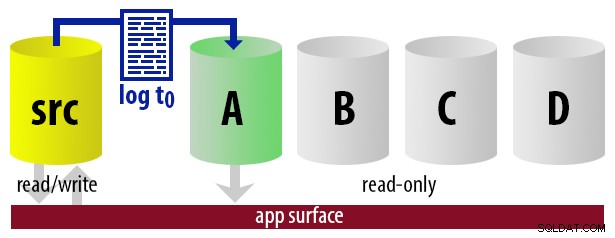 |
| 12:15 (t1) |
| 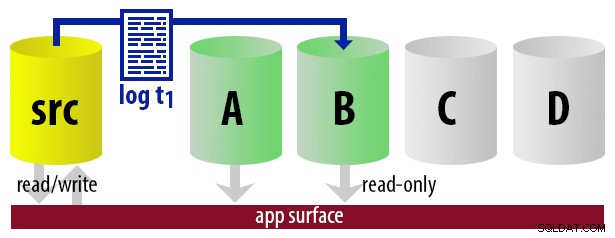 |
| 12:30 (t2) |
| 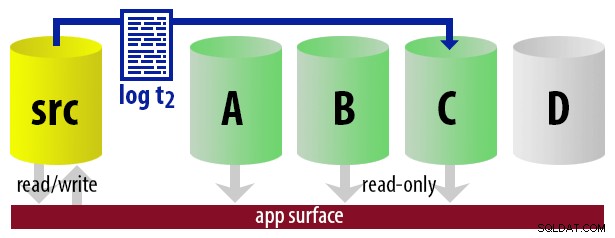 |
| 12:45 (t3) |
| 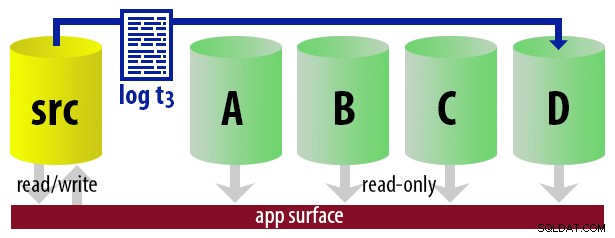 |
| 13:00 (t4) |
| 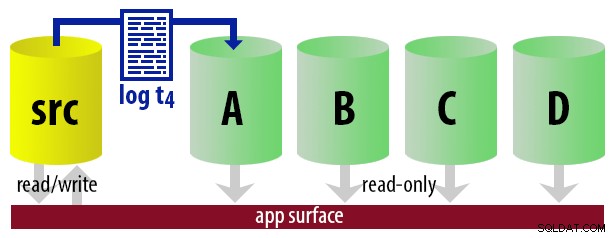 |
Può sembrare abbastanza semplice; scrivere il codice per gestire tutto ciò che è un po' più scoraggiante. Uno schema di massima:
- Sul server primario (lo chiamerò
BOSS), creare un database. Prima ancora di pensare di andare oltre, attiva il flag di traccia 3226 per evitare che i messaggi di backup riusciti sporchino il registro degli errori di SQL Server. - Su
BOSS, aggiungi un server collegato per ogni secondario (li chiameròPEON1->PEON4). - Da qualche parte accessibile a tutti i server, crea una condivisione file per archiviare i backup di database/registri e assicurati che gli account di servizio per ogni istanza abbiano accesso in lettura/scrittura. Inoltre, ogni istanza secondaria deve avere una posizione specificata per il file di standby.
- In un database di utilità separato (o MSDB, se preferisci), crea tabelle che conterranno le informazioni di configurazione sui database, tutti i database secondari e registri la cronologia di backup e ripristino.
- Crea stored procedure che eseguiranno il backup del database e il ripristino sui secondari
WITH NORECOVERY, quindi applica un logWITH STANDBYe contrassegnare un'istanza come secondaria di standby corrente. Queste procedure possono essere utilizzate anche per reinizializzare l'intera configurazione del log shipping nel caso qualcosa vada storto. - Crea un processo che verrà eseguito ogni 15 minuti, per eseguire le attività descritte sopra:
- esegui il backup del registro
- determinare a quale secondario applicare eventuali backup dei log non applicati
- ripristina quei registri con le impostazioni appropriate
- Crea una procedura memorizzata (e/o una vista?) che indicherà alle applicazioni chiamanti quale secondaria utilizzare per qualsiasi nuova query di sola lettura.
- Crea una procedura di pulizia per cancellare la cronologia dei backup dei log per i log che sono stati applicati a tutte le secondarie (e forse anche per spostare o eliminare i file stessi).
- Aumenta la soluzione con una solida gestione degli errori e notifiche.
Fase 1:crea un database
La mia istanza principale è Standard Edition, denominata .\BOSS . Su quell'istanza creo un semplice database con una tabella:
USE [master]; GO CREATE DATABASE UserData; GO ALTER DATABASE UserData SET RECOVERY FULL; GO USE UserData; GO CREATE TABLE dbo.LastUpdate(EventTime DATETIME2); INSERT dbo.LastUpdate(EventTime) SELECT SYSDATETIME();
Quindi creo un processo di SQL Server Agent che aggiorna semplicemente quel timestamp ogni minuto:
UPDATE UserData.dbo.LastUpdate SET EventTime = SYSDATETIME();
Ciò crea semplicemente il database iniziale e simula l'attività, consentendoci di convalidare il modo in cui l'attività di spedizione dei registri ruota attraverso ciascuno dei secondari leggibili. Voglio affermare esplicitamente che lo scopo di questo esercizio non è stressare la spedizione dei log di test o dimostrare quanto volume possiamo perforare; questo è un esercizio completamente diverso.
Passaggio 2:aggiungi server collegati
Ho quattro istanze secondarie Express Edition denominate .\PEON1 , .\PEON2 , .\PEON3 e .\PEON4 . Quindi ho eseguito questo codice quattro volte, cambiando @s ogni volta:
USE [master];
GO
DECLARE @s NVARCHAR(128) = N'.\PEON1', -- repeat for .\PEON2, .\PEON3, .\PEON4
@t NVARCHAR(128) = N'true';
EXEC [master].dbo.sp_addlinkedserver @server = @s, @srvproduct = N'SQL Server';
EXEC [master].dbo.sp_addlinkedsrvlogin @rmtsrvname = @s, @useself = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'collation compatible', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'data access', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc out', @optvalue = @t; Fase 3:convalida delle condivisioni file
Nel mio caso, tutte e 5 le istanze si trovano sullo stesso server, quindi ho appena creato una cartella per ciascuna istanza:C:\temp\Peon1\ , C:\temp\Peon2\ , e così via. Ricorda che se i tuoi secondari si trovano su server diversi, la posizione dovrebbe essere relativa a quel server, ma essere comunque accessibile dal primario (quindi in genere verrebbe utilizzato un percorso UNC). Dovresti convalidare che ogni istanza può scrivere su quella condivisione e dovresti anche convalidare che ogni istanza può scrivere nella posizione specificata per il file di standby (ho usato le stesse cartelle per lo standby). Puoi convalidarlo eseguendo il backup di un piccolo database da ciascuna istanza in ciascuna delle posizioni specificate:non procedere finché non funziona.
Fase 4:crea tabelle
Ho deciso di inserire questi dati in msdb , ma non ho davvero forti sentimenti a favore o contro la creazione di un database separato. La prima tabella di cui ho bisogno è quella che contiene le informazioni sui database che sto per log shipping:
CREATE TABLE dbo.PMAG_Databases ( DatabaseName SYSNAME, LogBackupFrequency_Minutes SMALLINT NOT NULL DEFAULT (15), CONSTRAINT PK_DBS PRIMARY KEY(DatabaseName) ); GO INSERT dbo.PMAG_Databases(DatabaseName) SELECT N'UserData';
(Se sei curioso dello schema di denominazione, PMAG sta per "Poor Man's Availability Groups.")
Un'altra tabella richiesta è quella per contenere le informazioni sui secondari, comprese le loro singole cartelle e il loro stato corrente nella sequenza di spedizione dei log.
CREATE TABLE dbo.PMAG_Secondaries
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
CommonFolder VARCHAR(512) NOT NULL,
DataFolder VARCHAR(512) NOT NULL,
LogFolder VARCHAR(512) NOT NULL,
StandByLocation VARCHAR(512) NOT NULL,
IsCurrentStandby BIT NOT NULL DEFAULT 0,
CONSTRAINT PK_Sec PRIMARY KEY(DatabaseName, ServerInstance),
CONSTRAINT FK_Sec_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName)
);
Se desideri eseguire il backup dal server di origine in locale e fare in modo che i secondari vengano ripristinati in remoto o viceversa, puoi dividere CommonFolder in due colonne (BackupFolder e RestoreFolder ) e apporta le modifiche pertinenti al codice (non ce ne saranno molte).
Dal momento che posso popolare questa tabella in base almeno in parte alle informazioni in sys.servers – sfruttando il fatto che i dati / log e altre cartelle prendono il nome dai nomi delle istanze:
INSERT dbo.PMAG_Secondaries
(
DatabaseName,
ServerInstance,
CommonFolder,
DataFolder,
LogFolder,
StandByLocation
)
SELECT
DatabaseName = N'UserData',
ServerInstance = name,
CommonFolder = 'C:\temp\Peon' + RIGHT(name, 1) + '\',
DataFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
LogFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
StandByLocation = 'C:\temp\Peon' + RIGHT(name, 1) + '\'
FROM sys.servers
WHERE name LIKE N'.\PEON[1-4]';
Ho anche bisogno di una tabella per tenere traccia dei singoli backup del registro (non solo dell'ultimo), perché in molti casi dovrò ripristinare più file di registro in sequenza. Posso ottenere queste informazioni da msdb.dbo.backupset , ma è molto più complicato ottenere cose come la posizione e potrei non avere il controllo su altri lavori che potrebbero ripulire la cronologia dei backup.
CREATE TABLE dbo.PMAG_LogBackupHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT NOT NULL,
Location VARCHAR(2000) NOT NULL,
BackupTime DATETIME NOT NULL DEFAULT SYSDATETIME(),
CONSTRAINT PK_LBH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LBH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LBH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Potresti pensare che sia uno spreco archiviare una riga per ogni secondario e archiviare la posizione di ogni backup, ma questo è a prova di futuro, per gestire il caso in cui sposti CommonFolder per qualsiasi secondario.
E infine una cronologia dei ripristini dei registri, così, in qualsiasi momento, posso vedere quali registri sono stati ripristinati e dove, e il processo di ripristino può essere sicuro di ripristinare solo i registri che non sono già stati ripristinati:
CREATE TABLE dbo.PMAG_LogRestoreHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT,
RestoreTime DATETIME,
CONSTRAINT PK_LRH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LRH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LRH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Fase 5:inizializza i secondari
Abbiamo bisogno di una procedura memorizzata che generi un file di backup (e lo rispecchi in qualsiasi posizione richiesta da diverse istanze) e ripristineremo anche un registro su ogni secondario per metterli tutti in standby. A questo punto saranno tutti disponibili per le query di sola lettura, ma solo uno sarà lo standby "corrente" alla volta. Questa è la procedura memorizzata che gestirà i backup completi e del registro delle transazioni; quando viene richiesto un backup completo e @init è impostato su 1, reinizializza automaticamente il log shipping.
CREATE PROCEDURE [dbo].[PMAG_Backup]
@dbname SYSNAME,
@type CHAR(3) = 'bak', -- or 'trn'
@init BIT = 0 -- only used with 'bak'
AS
BEGIN
SET NOCOUNT ON;
-- generate a filename pattern
DECLARE @now DATETIME = SYSDATETIME();
DECLARE @fn NVARCHAR(256) = @dbname + N'_' + CONVERT(CHAR(8), @now, 112)
+ RIGHT(REPLICATE('0',6) + CONVERT(VARCHAR(32), DATEDIFF(SECOND,
CONVERT(DATE, @now), @now)), 6) + N'.' + @type;
-- generate a backup command with MIRROR TO for each distinct CommonFolder
DECLARE @sql NVARCHAR(MAX) = N'BACKUP'
+ CASE @type WHEN 'bak' THEN N' DATABASE ' ELSE N' LOG ' END
+ QUOTENAME(@dbname) + '
' + STUFF(
(SELECT DISTINCT CHAR(13) + CHAR(10) + N' MIRROR TO DISK = '''
+ s.CommonFolder + @fn + ''''
FROM dbo.PMAG_Secondaries AS s
WHERE s.DatabaseName = @dbname
FOR XML PATH(''), TYPE).value(N'.[1]',N'nvarchar(max)'),1,9,N'') + N'
WITH NAME = N''' + @dbname + CASE @type
WHEN 'bak' THEN N'_PMAGFull' ELSE N'_PMAGLog' END
+ ''', INIT, FORMAT' + CASE WHEN LEFT(CONVERT(NVARCHAR(128),
SERVERPROPERTY(N'Edition')), 3) IN (N'Dev', N'Ent')
THEN N', COMPRESSION;' ELSE N';' END;
EXEC [master].sys.sp_executesql @sql;
IF @type = 'bak' AND @init = 1 -- initialize log shipping
BEGIN
EXEC dbo.PMAG_InitializeSecondaries @dbname = @dbname, @fn = @fn;
END
IF @type = 'trn'
BEGIN
-- record the fact that we backed up a log
INSERT dbo.PMAG_LogBackupHistory
(
DatabaseName,
ServerInstance,
BackupSetID,
Location
)
SELECT
DatabaseName = @dbname,
ServerInstance = s.ServerInstance,
BackupSetID = MAX(b.backup_set_id),
Location = s.CommonFolder + @fn
FROM msdb.dbo.backupset AS b
CROSS JOIN dbo.PMAG_Secondaries AS s
WHERE b.name = @dbname + N'_PMAGLog'
AND s.DatabaseName = @dbname
GROUP BY s.ServerInstance, s.CommonFolder + @fn;
-- once we've backed up logs,
-- restore them on the next secondary
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname;
END
END Questo a sua volta chiama due procedure che potresti chiamare separatamente (ma molto probabilmente non lo farà). Innanzitutto, la procedura che inizializzerà i secondari alla prima esecuzione:
ALTER PROCEDURE dbo.PMAG_InitializeSecondaries
@dbname SYSNAME,
@fn VARCHAR(512)
AS
BEGIN
SET NOCOUNT ON;
-- clear out existing history/settings (since this may be a re-init)
DELETE dbo.PMAG_LogBackupHistory WHERE DatabaseName = @dbname;
DELETE dbo.PMAG_LogRestoreHistory WHERE DatabaseName = @dbname;
UPDATE dbo.PMAG_Secondaries SET IsCurrentStandby = 0
WHERE DatabaseName = @dbname;
DECLARE @sql NVARCHAR(MAX) = N'',
@files NVARCHAR(MAX) = N'';
-- need to know the logical file names - may be more than two
SET @sql = N'SELECT @files = (SELECT N'', MOVE N'''''' + name
+ '''''' TO N''''$'' + CASE [type] WHEN 0 THEN N''df''
WHEN 1 THEN N''lf'' END + ''$''''''
FROM ' + QUOTENAME(@dbname) + '.sys.database_files
WHERE [type] IN (0,1)
FOR XML PATH, TYPE).value(N''.[1]'',N''nvarchar(max)'');';
EXEC master.sys.sp_executesql @sql,
N'@files NVARCHAR(MAX) OUTPUT',
@files = @files OUTPUT;
SET @sql = N'';
-- restore - need physical paths of data/log files for WITH MOVE
-- this can fail, obviously, if those path+names already exist for another db
SELECT @sql += N'EXEC ' + QUOTENAME(ServerInstance)
+ N'.master.sys.sp_executesql N''RESTORE DATABASE ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + CommonFolder + @fn + N'''''' + N' WITH REPLACE,
NORECOVERY' + REPLACE(REPLACE(REPLACE(@files, N'$df$', DataFolder
+ @dbname + N'.mdf'), N'$lf$', LogFolder + @dbname + N'.ldf'), N'''', N'''''')
+ N';'';' + CHAR(13) + CHAR(10)
FROM dbo.PMAG_Secondaries
WHERE DatabaseName = @dbname;
EXEC [master].sys.sp_executesql @sql;
-- backup a log for this database
EXEC dbo.PMAG_Backup @dbname = @dbname, @type = 'trn';
-- restore logs
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname, @PrepareAll = 1;
END E poi la procedura che ripristinerà i log:
CREATE PROCEDURE dbo.PMAG_RestoreLogs
@dbname SYSNAME,
@PrepareAll BIT = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StandbyInstance SYSNAME,
@CurrentInstance SYSNAME,
@BackupSetID INT,
@Location VARCHAR(512),
@StandByLocation VARCHAR(512),
@sql NVARCHAR(MAX),
@rn INT;
-- get the "next" standby instance
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 0
AND ServerInstance > (SELECT ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandBy = 1);
IF @StandbyInstance IS NULL -- either it was last or a re-init
BEGIN
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries;
END
-- get that instance up and into STANDBY
-- for each log in logbackuphistory not in logrestorehistory:
-- restore, and insert it into logrestorehistory
-- mark the last one as STANDBY
-- if @prepareAll is true, mark all others as NORECOVERY
-- in this case there should be only one, but just in case
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT bh.BackupSetID, s.ServerInstance, bh.Location, s.StandbyLocation,
rn = ROW_NUMBER() OVER (PARTITION BY s.ServerInstance ORDER BY bh.BackupSetID DESC)
FROM dbo.PMAG_LogBackupHistory AS bh
INNER JOIN dbo.PMAG_Secondaries AS s
ON bh.DatabaseName = s.DatabaseName
AND bh.ServerInstance = s.ServerInstance
WHERE s.DatabaseName = @dbname
AND s.ServerInstance = CASE @PrepareAll
WHEN 1 THEN s.ServerInstance ELSE @StandbyInstance END
AND NOT EXISTS
(
SELECT 1 FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE DatabaseName = @dbname
AND ServerInstance = s.ServerInstance
AND BackupSetID = bh.BackupSetID
)
ORDER BY CASE s.ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 2 END, bh.BackupSetID;
OPEN c;
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
WHILE @@FETCH_STATUS -1
BEGIN
-- kick users out - set to single_user then back to multi
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance) + N'.[master].sys.sp_executesql '
+ 'N''IF EXISTS (SELECT 1 FROM sys.databases WHERE name = N'''''
+ @dbname + ''''' AND [state] 1)
BEGIN
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET SINGLE_USER '
+ N'WITH ROLLBACK IMMEDIATE;
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET MULTI_USER;
END;'';';
EXEC [master].sys.sp_executesql @sql;
-- restore the log (in STANDBY if it's the last one):
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance)
+ N'.[master].sys.sp_executesql ' + N'N''RESTORE LOG ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + @Location + N''''' WITH ' + CASE WHEN @rn = 1
AND (@CurrentInstance = @StandbyInstance OR @PrepareAll = 1) THEN
N'STANDBY = N''''' + @StandbyLocation + @dbname + N'.standby''''' ELSE
N'NORECOVERY' END + N';'';';
EXEC [master].sys.sp_executesql @sql;
-- record the fact that we've restored logs
INSERT dbo.PMAG_LogRestoreHistory
(DatabaseName, ServerInstance, BackupSetID, RestoreTime)
SELECT @dbname, @CurrentInstance, @BackupSetID, SYSDATETIME();
-- mark the new standby
IF @rn = 1 AND @CurrentInstance = @StandbyInstance -- this is the new STANDBY
BEGIN
UPDATE dbo.PMAG_Secondaries
SET IsCurrentStandby = CASE ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 0 END
WHERE DatabaseName = @dbname;
END
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
END
CLOSE c; DEALLOCATE c;
END (So che c'è molto codice e molto SQL dinamico e criptico. Ho cercato di essere molto liberale con i commenti; se c'è un pezzo con cui hai problemi, faccelo sapere.)
Quindi ora, tutto ciò che devi fare per far funzionare il sistema è effettuare due chiamate di procedura:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'bak', @init = 1; EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Ora dovresti vedere ogni istanza con una copia standby del database:
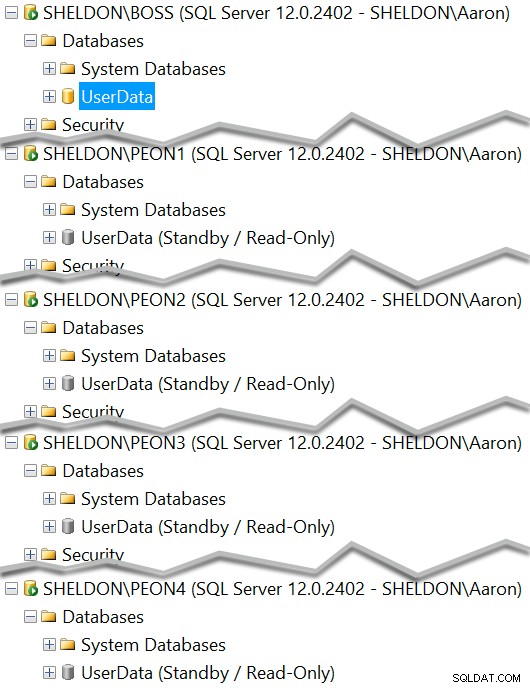
E puoi vedere quale dovrebbe attualmente fungere da standby di sola lettura:
SELECT ServerInstance, IsCurrentStandby FROM dbo.PMAG_Secondaries WHERE DatabaseName = N'UserData';
Passaggio 6:crea un lavoro che esegue il backup/ripristina i registri
Puoi inserire questo comando in un lavoro che pianifichi ogni 15 minuti:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Questo sposterà il secondario attivo ogni 15 minuti e i suoi dati saranno 15 minuti più recenti del secondario attivo precedente. Se disponi di più database con pianificazioni diverse, puoi creare più lavori o pianificare il lavoro più frequentemente e controllare dbo.PMAG_Databases tabella per ogni singolo LogBackupFrequency_Minutes valore per determinare se è necessario eseguire il backup/ripristino per quel database.
Fase 7:visualizzazione e procedura per indicare all'applicazione quale standby è attivo
CREATE VIEW dbo.PMAG_ActiveSecondaries
AS
SELECT DatabaseName, ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 1;
GO
CREATE PROCEDURE dbo.PMAG_GetActiveSecondary
@dbname SYSNAME
AS
BEGIN
SET NOCOUNT ON;
SELECT ServerInstance
FROM dbo.PMAG_ActiveSecondaries
WHERE DatabaseName = @dbname;
END
GO
Nel mio caso, ho anche creato manualmente una vista che unisce tutti i UserData database in modo da poter confrontare l'attualità dei dati sul primario con ogni secondario.
CREATE VIEW dbo.PMAG_CompareRecency_UserData
AS
WITH x(ServerInstance, EventTime)
AS
(
SELECT @@SERVERNAME, EventTime FROM UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON1', EventTime FROM [.\PEON1].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON2', EventTime FROM [.\PEON2].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON3', EventTime FROM [.\PEON3].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON4', EventTime FROM [.\PEON4].UserData.dbo.LastUpdate
)
SELECT x.ServerInstance, s.IsCurrentStandby, x.EventTime,
Age_Minutes = DATEDIFF(MINUTE, x.EventTime, SYSDATETIME()),
Age_Seconds = DATEDIFF(SECOND, x.EventTime, SYSDATETIME())
FROM x LEFT OUTER JOIN dbo.PMAG_Secondaries AS s
ON s.ServerInstance = x.ServerInstance
AND s.DatabaseName = N'UserData';
GO Esempi di risultati del fine settimana:
SELECT [Now] = SYSDATETIME(); SELECT ServerInstance, IsCurrentStandby, EventTime, Age_Minutes, Age_Seconds FROM dbo.PMAG_CompareRecency_UserData ORDER BY Age_Seconds DESC;
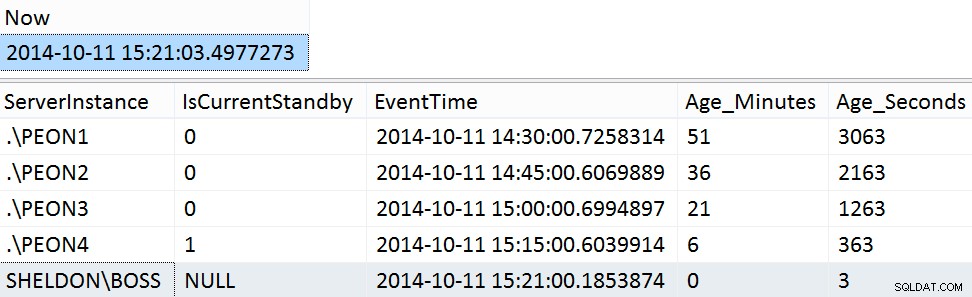
Fase 8:procedura di pulizia
La pulizia della cronologia di backup e ripristino del registro è piuttosto semplice.
CREATE PROCEDURE dbo.PMAG_CleanupHistory
@dbname SYSNAME,
@DaysOld INT = 7
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cutoff INT;
-- this assumes that a log backup either
-- succeeded or failed on all secondaries
SELECT @cutoff = MAX(BackupSetID)
FROM dbo.PMAG_LogBackupHistory AS bh
WHERE DatabaseName = @dbname
AND BackupTime < DATEADD(DAY, -@DaysOld, SYSDATETIME())
AND EXISTS
(
SELECT 1
FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE BackupSetID = bh.BackupSetID
AND DatabaseName = @dbname
AND ServerInstance = bh.ServerInstance
);
DELETE dbo.PMAG_LogRestoreHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
DELETE dbo.PMAG_LogBackupHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
END
GO Ora puoi aggiungerlo come passaggio nel lavoro esistente, oppure puoi programmarlo completamente separatamente o come parte di altre routine di pulizia.
Lascerò la pulizia del file system per un altro post (e probabilmente un meccanismo completamente separato, come PowerShell o C#:questo non è in genere il tipo di cosa che vuoi che T-SQL faccia).
Fase 9:aumenta la soluzione
È vero che potrebbe esserci una migliore gestione degli errori e altre sottigliezze qui per rendere questa soluzione più completa. Per ora lo lascerò come esercizio per il lettore, ma ho intenzione di guardare i post di follow-up per dettagliare miglioramenti e perfezionamenti a questa soluzione.
Variabili e limitazioni
Nota che nel mio caso ho usato l'edizione Standard come primaria e l'edizione Express per tutte le secondarie. Potresti fare un ulteriore passo avanti nella scala del budget e persino utilizzare Express Edition come principale:molte persone pensano che Express Edition non supporti la spedizione dei registri, quando in realtà è semplicemente la procedura guidata che non era presente nelle versioni di Management Studio Express prima di SQL Server 2012 Service Pack 1. Detto questo, poiché Express Edition non supporta SQL Server Agent, sarebbe difficile renderlo un editore in questo scenario:dovresti configurare il tuo programma di pianificazione per chiamare le stored procedure (C# app della riga di comando eseguita da Utilità di pianificazione di Windows, processi di PowerShell o processi di SQL Server Agent in un'altra istanza). Per utilizzare Express su entrambe le estremità, dovresti anche essere sicuro che il tuo file di dati non supererà i 10 GB e che le tue query funzioneranno bene con la memoria, la CPU e i limiti delle funzionalità di quell'edizione. Non sto affatto suggerendo che Express sia l'ideale; L'ho usato semplicemente per dimostrare che è possibile avere secondari leggibili molto flessibili gratuitamente (o molto vicino ad esso).
Inoltre, queste istanze separate nel mio scenario risiedono tutte sulla stessa macchina virtuale, ma non deve funzionare affatto in questo modo:puoi distribuire le istanze su più server; oppure, potresti andare dall'altra parte e ripristinare su copie diverse del database, con nomi diversi, sulla stessa istanza. Queste configurazioni richiederebbero modifiche minime rispetto a quanto descritto sopra. E su quanti database eseguire il ripristino e con quale frequenza dipende completamente da te, anche se ci sarà un pratico limite superiore (dove [average query time] > [number of secondaries] x [log backup interval] ).
Infine, ci sono sicuramente alcune limitazioni con questo approccio. Un elenco non esaustivo:
- Anche se puoi continuare a eseguire backup completi secondo la tua pianificazione, i backup dei log devono fungere da unico meccanismo di backup dei log. Se è necessario archiviare i backup dei registri per altri scopi, non sarà possibile eseguire il backup dei registri separatamente da questa soluzione, poiché interferiranno con la catena di registri. Invece, puoi considerare di aggiungere ulteriori
MIRROR TOarguments to the existing log backup scripts, if you need to have copies of the logs used elsewhere. - While "Poor Man's Availability Groups" may seem like a clever name, it can also be a bit misleading. This solution certainly lacks many of the HA/DR features of Availability Groups, including failover, automatic page repair, and support in the UI, Extended Events and DMVs. This was only meant to provide the ability for non-Enterprise customers to have an infrastructure that supports multiple readable secondaries.
- I tested this on a very isolated VM system with no concurrency. This is not a complete solution and there are likely dozens of ways this code could be made tighter; as a first step, and to focus on the scaffolding and to show you what's possible, I did not build in bulletproof resiliency. You will need to test it at your scale and with your workload to discover your breaking points, and you will also potentially need to deal with transactions over linked servers (always fun) and automating the re-initialization in the event of a disaster.
The "Insurance Policy"
Log shipping also offers a distinct advantage over many other solutions, including Availability Groups, mirroring and replication:a delayed "insurance policy" as I like to call it. At my previous job, I did this with full backups, but you could easily use log shipping to accomplish the same thing:I simply delayed the restores to one of the secondary instances by 24 hours. This way, I was protected from any client "shooting themselves in the foot" going back to yesterday, and I could get to their data easily on the delayed copy, because it was 24 hours behind. (I implemented this the first time a customer ran a delete without a where clause, then called us in a panic, at which point we had to restore their database to a point in time before the delete – which was both tedious and time consuming.) You could easily adapt this solution to treat one of these instances not as a read-only secondary but rather as an insurance policy. More on that perhaps in another post.



