I piani di esecuzione forniscono una ricca fonte di informazioni che possono aiutarci a identificare i modi per migliorare le prestazioni di query importanti. Le persone spesso cercano cose come scansioni e ricerche di grandi dimensioni come un modo per identificare potenziali ottimizzazioni del percorso di accesso ai dati. Questi problemi possono essere spesso risolti rapidamente creando un nuovo indice o estendendone uno esistente con più colonne incluse.
Possiamo anche utilizzare i piani di post-esecuzione per confrontare i conteggi di righe effettivi con quelli previsti tra gli operatori del piano. Laddove questi risultano essere significativamente discordanti, possiamo provare a fornire migliori informazioni statistiche all'ottimizzatore aggiornando le statistiche esistenti, creando nuovi oggetti statistici, utilizzando statistiche su colonne calcolate o forse suddividendo una query complessa in componenti meno complessi parti.
Oltre a ciò, possiamo anche esaminare le operazioni costose nel piano, in particolare quelle che consumano memoria come l'ordinamento e l'hashing. L'ordinamento a volte può essere evitato attraverso le modifiche all'indicizzazione. Altre volte, potremmo dover rifattorizzare la query utilizzando la sintassi che favorisce un piano che preserva un particolare ordinamento desiderato.
A volte, le prestazioni non saranno ancora sufficientemente buone anche dopo aver applicato tutte queste tecniche di ottimizzazione delle prestazioni. Un possibile passo successivo è pensare un po' di più al piano nel suo insieme . Questo significa fare un passo indietro, cercare di capire la strategia complessiva scelta dal Query Optimizer, per vedere se possiamo identificare un miglioramento algoritmico.
Questo articolo esplora quest'ultimo tipo di analisi, usando un semplice problema di esempio per trovare valori di colonna univoci in un set di dati moderatamente grande. Come spesso accade in analoghi problemi del mondo reale, la colonna di interesse avrà relativamente pochi valori univoci, rispetto al numero di righe nella tabella. Ci sono due parti in questa analisi:creare i dati di esempio e scrivere la query con valori distinti stessa.
Creazione dei dati di esempio
Per fornire l'esempio più semplice possibile, la nostra tabella di test ha solo una singola colonna con un indice cluster (questa colonna conterrà valori duplicati in modo che l'indice non possa essere dichiarato univoco):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Per scegliere alcuni numeri dall'aria, sceglieremo di caricare dieci milioni di righe in totale, con una distribuzione uniforme su mille valori distinti . Una tecnica comune per generare dati come questo consiste nell'unire in modo incrociato alcune tabelle di sistema e applicare il ROW_NUMBER funzione. Useremo anche l'operatore modulo per limitare i numeri generati ai valori distinti desiderati:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Il piano di esecuzione stimato per quella query è il seguente (fai clic sull'immagine per ingrandirla se necessario):

Ci vogliono circa 30 secondi per creare i dati di esempio sul mio laptop. Non si tratta affatto di un lasso di tempo enorme, ma è comunque interessante considerare cosa potremmo fare per rendere questo processo più efficiente...
Analisi del piano
Inizieremo comprendendo a cosa serve ogni operazione nel piano.
La sezione del piano di esecuzione a destra dell'operatore Segmento riguarda la produzione di righe mediante unione incrociata di tabelle di sistema:

L'operatore Segmento è presente nel caso in cui la funzione della finestra avesse un PARTITION BY clausola. Non è il caso qui, ma è comunque presente nel piano di query. L'operatore Sequence Project genera i numeri di riga e Top limita l'output del piano a dieci milioni di righe:

Compute Scalar definisce l'espressione che applica la funzione modulo e ne aggiunge una al risultato:

Possiamo vedere come si relazionano le etichette Sequence Project e Compute Scalar usando la scheda Espressioni di Plan Explorer:

Questo ci dà un'idea più completa del flusso di questo piano:il progetto Sequence numera le righe ed etichetta l'espressione Expr1050; il calcolo scalare etichetta il risultato del calcolo modulo e più uno come Expr1052 . Notare anche la conversione implicita nell'espressione Compute Scalar. La colonna della tabella di destinazione è di tipo intero, mentre il ROW_NUMBER La funzione produce un bigint, quindi è necessaria una conversione restringente.
L'operatore successivo nel piano è un Sort. Secondo le stime dei costi di Query Optimizer, questa dovrebbe essere l'operazione più costosa (88,1% stimato ):

Potrebbe non essere immediatamente ovvio il motivo per cui questo piano prevede l'ordinamento, poiché non vi è alcun requisito di ordinamento esplicito nella query. L'ordinamento viene aggiunto al piano per garantire che le righe arrivino all'operatore di inserimento dell'indice cluster nell'ordine dell'indice cluster. Ciò promuove scritture sequenziali, evita la divisione della pagina ed è uno dei prerequisiti per INSERT con registrazione minima operazioni.
Queste sono tutte cose potenzialmente buone, ma l'ordinamento stesso è piuttosto costoso. In effetti, il controllo del piano di esecuzione ("reale") successivo all'esecuzione rivela che anche l'ordinamento ha esaurito la memoria al momento dell'esecuzione e ha dovuto riversarsi su tempdb fisico disco:

La fuoriuscita di ordinamento si verifica nonostante il numero stimato di righe sia esattamente corretto e nonostante alla query sia stata concessa tutta la memoria richiesta (come si vede nelle proprietà del piano per la radice INSERT nodo):

Gli sversamenti di smistamento sono indicati anche dalla presenza di IO_COMPLETION waits nella scheda delle statistiche di attesa di Plan Explorer PRO:

Infine, per questa sezione di analisi del piano, nota il DML Request Sort proprietà dell'operatore Clustered Index Insert è impostata su true:

Questo flag indica che l'ottimizzatore richiede che il sottoalbero sotto l'Insert fornisca le righe nell'ordine ordinato della chiave di indice (da qui la necessità dell'operatore di ordinamento problematico).
Evitare l'ordinamento
Ora che sappiamo perché appare Ordina, possiamo testare per vedere cosa succede se lo rimuoviamo. Ci sono modi in cui potremmo riscrivere la query per "ingannare" l'ottimizzatore facendogli pensare che sarebbero state inserite meno righe (quindi l'ordinamento non varrebbe la pena) ma un modo rapido per evitare l'ordinamento direttamente (solo per scopi sperimentali) consiste nell'usare un flag di traccia non documentato 8795. Questo imposta il DML Request Sort proprietà su false, quindi non è più necessario che le righe arrivino all'Inserimento dell'indice cluster nell'ordine delle chiavi cluster:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Il nuovo piano di query post-esecuzione è il seguente (clicca sull'immagine per ingrandirla):

L'operatore di ordinamento è scomparso, ma la nuova query viene eseguita per oltre 50 secondi (rispetto a 30 secondi prima). Ci sono un paio di ragioni per questo. Innanzitutto, perdiamo ogni possibilità di inserimenti con registrazione minima perché questi richiedono dati ordinati (Ordinamento richiesta DML =true). In secondo luogo, durante l'inserimento si verificherà un gran numero di divisioni di pagina "non valide". Nel caso in cui sembri contro-intuitivo, ricorda che sebbene il ROW_NUMBER funzione numeri righe in sequenza, l'effetto dell'operatore modulo è di presentare una sequenza ripetuta di numeri 1…1000 all'Inserimento indice cluster.
Lo stesso problema fondamentale si verifica se utilizziamo trucchi T-SQL per ridurre il conteggio delle righe previsto per evitare l'ordinamento invece di utilizzare il flag di traccia non supportato.
Evitare l'ordinamento II
Osservando il piano nel suo insieme, sembra chiaro che vorremmo generare righe in un modo che eviti un ordinamento esplicito, ma che raccolga comunque i vantaggi di una registrazione minima e di evitare la divisione della pagina errata. In parole povere:vogliamo un piano che presenti le righe in ordine di chiavi raggruppate, ma senza ordinamento.
Grazie a questa nuova intuizione, possiamo esprimere la nostra domanda in un modo diverso. La query seguente genera ogni numero da 1 a 1000 e incroci incrociati impostati con 10.000 righe per produrre il grado di duplicazione richiesto. L'idea è di generare un set di inserti che presenti 10.000 righe numerate '1' poi 10.000 numerate '2'... e così via.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Sfortunatamente, l'ottimizzatore produce ancora un piano con un ordinamento:

Non c'è molto da dire a difesa dell'ottimizzatore qui, questo è solo un piano stupido. Ha scelto di generare 10.000 righe, quindi unire in modo incrociato quelle con numeri da 1 a 1000. Ciò non consente di preservare l'ordine naturale dei numeri, quindi l'ordinamento non può essere evitato.
Evitare lo smistamento:finalmente!
La strategia che l'ottimizzatore ha mancato è prendere i numeri da 1 a 1000 prima e incrociare ogni numero con 10.000 righe (facendo 10.000 copie di ogni numero in sequenza). Il piano previsto eviterebbe un ordinamento utilizzando un cross join di cicli annidati che conserva l'ordine delle righe sull'ingresso esterno.
Possiamo ottenere questo risultato forzando l'ottimizzatore ad accedere alle tabelle derivate nell'ordine specificato nella query, utilizzando il FORCE ORDER suggerimento per la query:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Finalmente, otteniamo il piano che cercavamo:
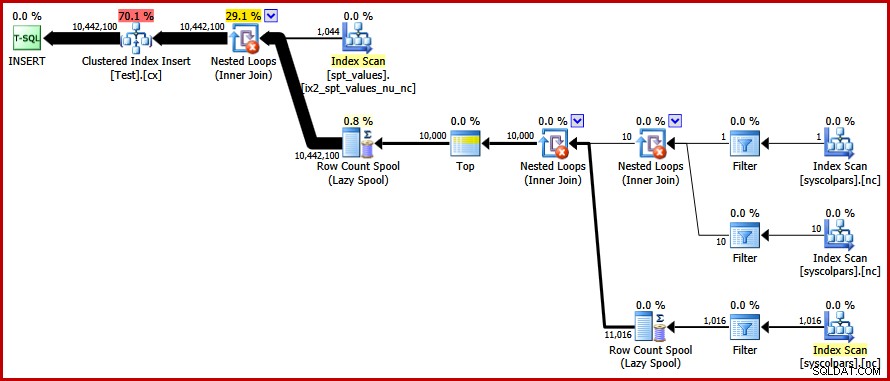
Questo piano evita un ordinamento esplicito pur evitando divisioni di pagina "non valide" e consentendo inserimenti con registrazione minima nell'indice cluster (supponendo che il database non stia utilizzando FULL modello di recupero). Carica tutti i dieci milioni di righe in circa 9 secondi sul mio laptop (con un singolo disco rotante SATA da 7200 rpm). Ciò rappresenta un notevole aumento di efficienza nel 30-50 secondi tempo trascorso visto prima della riscrittura.
Trovare i valori distinti
Ora che abbiamo creato i dati di esempio, possiamo rivolgere la nostra attenzione alla scrittura di una query per trovare i valori distinti nella tabella. Un modo naturale per esprimere questo requisito in T-SQL è il seguente:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Il piano di esecuzione è molto semplice, come ti aspetteresti:

Questo richiede circa 2900 ms per funzionare sulla mia macchina e richiede 43.406 letture logiche:

Rimozione del MAXDOP (1) il suggerimento per la query genera un piano parallelo:

Questo viene completato in circa 1500 ms (ma con 8.764 ms di tempo CPU consumato) e 43.804 letture logiche:

Gli stessi piani e le stesse prestazioni si ottengono se utilizziamo GROUP BY invece di DISTINCT .
Un algoritmo migliore
I piani di query mostrati sopra leggono tutti i valori dalla tabella di base e li elaborano tramite un aggregato di flusso. Considerando l'attività nel suo insieme, sembra inefficiente scansionare tutte le 10 milioni di righe quando sappiamo che ci sono relativamente pochi valori distinti.
Una strategia migliore potrebbe essere quella di trovare il singolo valore più basso nella tabella, quindi trovare il successivo più alto e così via fino a quando non esauriamo i valori. Fondamentalmente, questo approccio si presta alla ricerca singleton nell'indice piuttosto che alla scansione di ogni riga.
Possiamo implementare questa idea in una singola query utilizzando un CTE ricorsivo, in cui la parte di ancoraggio trova il più basso valore distinto, quindi la parte ricorsiva trova il valore distinto successivo e così via. Un primo tentativo di scrivere questa query è:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Sfortunatamente, quella sintassi non viene compilata:

Ok, quindi le funzioni aggregate non sono consentite. Invece di usare MIN , possiamo scrivere la stessa logica usando TOP (1) con un ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Ancora nessuna gioia.
Si scopre che possiamo aggirare queste restrizioni riscrivendo la parte ricorsiva per numerare le righe candidate nell'ordine richiesto, quindi filtrando per la riga numerata "uno". Potrebbe sembrare un po' tortuoso, ma la logica è esattamente la stessa:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Questa query fa compilare e produce il seguente piano post-esecuzione:

Si noti l'operatore Top nella parte ricorsiva del piano di esecuzione (evidenziato). Non possiamo scrivere un TOP T-SQL nella parte ricorsiva di un'espressione di tabella comune ricorsiva, ma ciò non significa che l'ottimizzatore non possa usarne una! L'ottimizzatore introduce il Top in base al ragionamento sul numero di righe che dovrà controllare per trovare quella numerata "1".
Le prestazioni di questo piano (non parallelo) sono molto migliori rispetto all'approccio Stream Aggregate. Si completa in circa 50 ms , con 3007 letture logiche rispetto alla tabella di origine (e 6001 righe lette dalla tabella di lavoro di spool), rispetto al record precedente di 1500 ms (8764 ms di tempo CPU su DOP 8) e 43.804 letture logiche:


Conclusione
Non è sempre possibile ottenere miglioramenti nelle prestazioni delle query considerando i singoli elementi del piano di query da soli. A volte, dobbiamo analizzare la strategia alla base dell'intero piano di esecuzione, quindi pensare lateralmente per trovare un algoritmo e un'implementazione più efficienti.



