In generale, il miglior tipo di ordinamento è quello che viene completamente evitato. Con un'attenta indicizzazione e talvolta una scrittura di query creativa, spesso possiamo rimuovere la necessità di un operatore di ordinamento dai piani di esecuzione. Laddove i dati da ordinare sono di grandi dimensioni, evitare questo tipo di ordinamento può produrre miglioramenti delle prestazioni molto significativi.
Il secondo miglior tipo di Sort è quello che non possiamo evitare, ma che riserva una quantità adeguata di memoria e la usa tutta o la maggior parte per fare qualcosa di utile. Essere utile può assumere molte forme. A volte, un ordinamento può più che ripagarsi abilitando un'operazione successiva che funziona in modo molto più efficiente sull'input ordinato. Altre volte, l'ordinamento è semplicemente necessario e dobbiamo solo renderlo il più efficiente possibile.
Poi vengono i tipi che di solito vogliamo evitare:quelli che riservano molta più memoria del necessario e quelli che riservano troppo poco. Quest'ultimo caso è quello su cui la maggior parte delle persone si concentra. Con memoria insufficiente riservata (o disponibile) per completare l'operazione di ordinamento richiesta in memoria, un operatore di ordinamento, con poche eccezioni, trasferirà le righe di dati a tempdb . In realtà, questo significa quasi sempre scrivere le pagine di ordinamento nella memoria fisica (e rileggerle in seguito ovviamente).
Nelle versioni moderne di SQL Server, un ordinamento fuoriuscito risulta in un'icona di avviso nei piani di post-esecuzione, che può includere dettagli sulla quantità di dati riversati, sul numero di thread coinvolti e sul livello di spill.
Sfondo:livelli di dispersione
Considera il compito di ordinare 4000 MB di dati, quando abbiamo solo 500 MB di memoria disponibile. Ovviamente, non possiamo ordinare l'intero set in memoria in una volta, ma possiamo suddividere l'attività:
Prima leggiamo 500 MB di dati, ordiniamo il set in memoria, quindi scriviamo il risultato su disco. L'esecuzione di questa operazione per un totale di 8 volte consuma l'intero input di 4000 MB, risultando in 8 set di dati ordinati di dimensioni pari a 500 MB. Il secondo passaggio consiste nell'eseguire un'unione a 8 vie dei set di dati ordinati. Tieni presente che una unione è richiesta, non una semplice concatenazione dei set poiché i dati sono garantiti solo per essere ordinati come richiesto all'interno di un determinato set da 500 MB nella fase intermedia.
In linea di principio, potremmo leggere e unire una riga alla volta da ciascuna delle otto esecuzioni di ordinamento, ma ciò non sarebbe molto efficiente. Invece, leggiamo la prima parte di ogni tipo eseguito di nuovo in memoria, diciamo 60 MB. Questo consuma 8 x 60 MB =480 MB dei 500 MB che abbiamo a disposizione. Possiamo quindi eseguire in modo efficiente l'unione a 8 vie in memoria per un po', bufferizzando l'output ordinato finale con i 20 MB di memoria ancora disponibili. Quando ciascuno dei buffer di memoria di esecuzione di ordinamento si svuota, leggiamo una nuova sezione di tale ordinamento in memoria. Una volta che tutte le esecuzioni di ordinamento sono state consumate, l'ordinamento è completo.
Ci sono alcuni dettagli aggiuntivi e ottimizzazioni che possiamo includere, ma questo è lo schema di base di uno spill di livello 1, noto anche come spill a passaggio singolo. È necessario un singolo passaggio aggiuntivo sui dati per produrre l'output ordinato finale.
Ora, un'unione a n vie potrebbe teoricamente ospitare una sorta di qualsiasi dimensione, in qualsiasi quantità di memoria, semplicemente aumentando il numero di insiemi intermedi ordinati localmente. Il problema è che all'aumentare di 'n', finiamo per leggere e scrivere porzioni di dati più piccole. Ad esempio, l'ordinamento di 400 GB di dati in 500 MB di memoria significherebbe qualcosa come un'unione a 800 vie, con solo 0,6 MB circa da ogni set ordinato intermedio in memoria in qualsiasi momento (800 x 0,6 MB =480 MB, lasciando un po' di spazio per un buffer di uscita).
È possibile utilizzare più passaggi di unione per aggirare questo problema. L'idea generale è quella di unire progressivamente piccoli pezzi in pezzi più grandi, fino a quando non siamo in grado di produrre in modo efficiente il flusso di output ordinato finale. Nell'esempio, ciò potrebbe significare unire 40 degli 800 set ordinati di primo passaggio alla volta, ottenendo 20 blocchi più grandi, che possono quindi essere nuovamente uniti per formare l'output. Con un totale di due passaggi aggiuntivi sui dati, si tratterebbe di una fuoriuscita di livello 2 e così via. Fortunatamente, un aumento lineare del livello di sversamento consente un aumento esponenziale delle dimensioni dello smistamento, quindi raramente sono necessari livelli di sversamento di smistamento profondo.
La fuoriuscita di "Livello 15.000"
A questo punto, ti starai chiedendo quale combinazione di minuscola concessione di memoria e enorme dimensione dei dati potrebbe comportare una fuoriuscita di ordinamento di livello 15.000. Stai cercando di ordinare l'intera Internet in 1 MB di memoria? Forse, ma è troppo difficile da dimostrare. Ad essere onesti, non ho idea se un livello di spill davvero alto sia possibile anche in SQL Server. L'obiettivo qui (un trucco, di sicuro) è far sì che SQL Server segnala una fuoriuscita di livello 15.000.
L'ingrediente chiave è il partizionamento. Da SQL Server 2012, è stato consentito un (comodo) massimo di 15.000 partizioni per oggetto (il supporto per 15.000 partizioni è disponibile anche su 2008 SP2 e 2008 R2 SP1, ma è necessario abilitarlo manualmente per database ed essere a conoscenza di tutto le avvertenze).
La prima cosa di cui avremo bisogno è una funzione di partizione da 15.000 elementi e uno schema di partizione associato. Per evitare un blocco di codice inline davvero enorme, il seguente script utilizza SQL dinamico per generare le istruzioni richieste:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Lo script è abbastanza facile da modificare a un numero inferiore nel caso in cui la tua configurazione abbia problemi con 15.000 partizioni (in particolare dal punto di vista della memoria, come vedremo tra poco). I passaggi successivi consistono nel creare una tabella heap normale (non partizionata) con una singola colonna intera, quindi popolarla con i numeri interi da 1 a 15.000 inclusi:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Dovrebbe essere completato in circa 100 ms. Se hai una tabella numeri disponibile, sentiti libero di usarla invece per un'esperienza più basata su set. Il modo in cui viene popolata la tabella di base non è importante. Per ottenere il nostro spill di 15.000 livelli, tutto ciò che dobbiamo fare ora è creare un indice cluster partizionato sul tavolo:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Il tempo di esecuzione dipende molto dal sistema di archiviazione in uso. Sul mio laptop, utilizzando un SSD consumer abbastanza tipico di un paio di anni fa, ci vogliono circa 20 secondi, il che è piuttosto significativo considerando che abbiamo a che fare solo con 15.000 righe in totale. In una macchina virtuale di Azure con specifiche piuttosto basse con prestazioni I/O piuttosto terribili, lo stesso test ha richiesto circa 20 minuti.
Analisi
Il piano di esecuzione per la build dell'indice è:
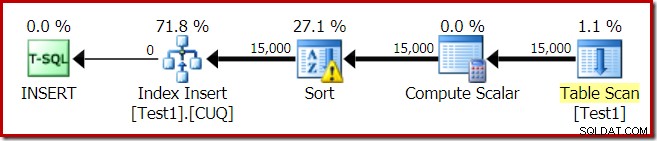
La scansione tabella legge le 15.000 righe dalla nostra tabella heap. Compute Scalar calcola il numero di partizione dell'indice di destinazione per ogni riga utilizzando la funzione interna RangePartitionNew() . L'ordinamento è la parte più interessante del piano, quindi lo esamineremo più in dettaglio.
Innanzitutto, l'avviso di ordinamento, come visualizzato in Plan Explorer:

Un avviso simile da SSMS (preso da una diversa esecuzione dello script):
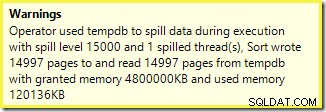
La prima cosa da notare è il rapporto di un livello di sversamento di 15.000 tipi, come promesso. Questo non è del tutto accurato, ma i dettagli sono piuttosto interessanti. L'ordinamento in questo piano ha un Partition ID proprietà, che normalmente non è presente:
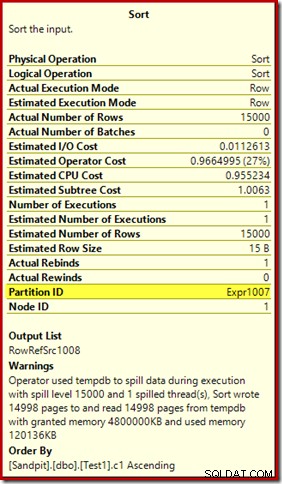
Questa proprietà è impostata uguale alla definizione della funzione di partizionamento interna in Compute Scalar.
Questa è una build dell'indice non allineato , perché l'origine e la destinazione hanno disposizioni di partizionamento diverse. In questo caso, tale differenza si verifica perché la tabella heap di origine non è partizionata, ma lo è l'indice di destinazione. Di conseguenza, in fase di esecuzione vengono creati 15.000 ordinamenti separati:uno per partizione di destinazione non vuota. Ciascuno di questi tipi di versamenti viene trasferito al livello 1 e SQL Server somma tutti questi tipi di versamento per ottenere il livello di versamento di ordinamento finale di 15.000.
I 15.000 ordinamenti separati spiegano la grande concessione di memoria. Ogni istanza di ordinamento ha una dimensione minima di 40 pagine, ovvero 40 x 8 KB =320 KB. I 15.000 ordinamenti richiedono quindi almeno 15.000 x 320 KB =4.800.000 KB di memoria. Questo è poco meno di 4,6 GB di RAM riservati esclusivamente a una query che ordina 15.000 righe contenenti una singola colonna intera. E ogni tipo si riversa su disco, nonostante riceva solo una riga! Se si utilizzasse il parallelismo per la compilazione dell'indice, la concessione di memoria potrebbe essere ulteriormente gonfiata dal numero di thread. Si noti inoltre che la singola riga viene scritta in una pagina, il che spiega il numero di pagine scritte e lette da tempdb. Sembra esserci una condizione di competizione che significa che il numero di pagine riportato è spesso inferiore a 15.000.
Questo esempio riflette un caso limite, ovviamente, ma è ancora difficile capire perché ogni ordinamento riversa la sua singola riga invece di ordinare nella memoria che gli è stata assegnata. Forse questo è di progettazione per qualche motivo, o forse è semplicemente un bug. In ogni caso, è comunque abbastanza divertente vedere una sorta di poche centinaia di KB di dati che impiegano così tanto tempo con una concessione di memoria di 4,6 GB e uno spill di 15.000 livelli. A meno che non lo incontri in un ambiente di produzione, forse. Ad ogni modo, è qualcosa di cui essere consapevoli.
Il rapporto fuorviante di 15.000 livelli di sversamento si riduce praticamente ai limiti di rappresentazione nell'output del piano dello spettacolo. Il problema fondamentale è qualcosa che si pone in molti luoghi in cui si verificano azioni ripetute, ad esempio sul lato interno dell'unione di anelli nidificati. Sarebbe certamente utile poter vedere in questi casi una ripartizione più precisa anziché un totale complessivo. Nel tempo, quest'area è leggermente migliorata, quindi ora abbiamo più informazioni sul piano per thread o per partizione per alcune operazioni. C'è ancora molta strada da fare però.
È ancora poco utile che 15.000 sversamenti di livello 1 separati siano riportati qui come un unico sversamento di 15.000 livelli.
Test varianti
Questo articolo riguarda più l'evidenziazione dei limiti delle informazioni del piano e il potenziale di scarse prestazioni quando vengono utilizzati numeri estremi di partizioni, che il rendere più efficiente la particolare operazione di esempio, ma ci sono anche un paio di variazioni interessanti che voglio esaminare .
Online, Ordina in tempdb
Esecuzione della stessa operazione di creazione dell'indice partizionato con ONLINE = ON, SORT_IN_TEMPDB = ON non soffre della stessa enorme concessione e dispersione della memoria:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Tieni presente che utilizzando ONLINE da solo non è sufficiente. In effetti, ciò si traduce nello stesso piano di prima con tutti gli stessi problemi, più un sovraccarico aggiuntivo per la creazione di ogni partizione di indice in linea. Per me, ciò si traduce in un tempo di esecuzione di oltre un minuto. Dio solo sa quanto tempo ci vorrebbe su un'istanza di Azure con specifiche ridotte con prestazioni I/O terribili.
Ad ogni modo, il piano di esecuzione con ONLINE = ON, SORT_IN_TEMPDB = ON è:

L'ordinamento viene eseguito prima del calcolo del numero della partizione di destinazione. Non ha la proprietà ID partizione, quindi è solo un ordinamento normale. L'intera operazione viene eseguita per una decina di secondi (ci sono ancora molte partizioni da creare). Riserva meno di 3 MB di memoria e utilizza un massimo di 816 KB. Un bel miglioramento rispetto a 4,6 GB e 15.000 spill.
Prima l'indice, poi i dati
Risultati simili possono essere ottenuti scrivendo prima i dati in una tabella heap:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Quindi, crea una tabella cluster partizionata vuota e inserisci i dati dall'heap:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Questa operazione richiede circa dieci secondi, con una concessione di memoria di 2 MB e nessuna fuoriuscita:
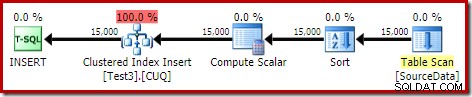
Naturalmente, l'ordinamento potrebbe anche essere evitato completamente indicizzando la tabella di origine (non partizionata) e inserendo i dati nell'ordine dell'indice (l'ordinamento migliore non è affatto l'ordinamento, ricorda).
Heap partizionato, quindi dati, quindi indice
Per quest'ultima variazione, creiamo prima un heap partizionato e carichiamo le 15.000 righe di test:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Quello script viene eseguito per un secondo o due, il che è abbastanza buono. Il passaggio finale consiste nel creare l'indice cluster partizionato:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Questo è un completo disastro, sia dal punto di vista delle prestazioni, sia dal punto di vista delle informazioni sul programma dello spettacolo. L'operazione stessa dura poco meno di un minuto, con il seguente piano di esecuzione:

Questo è un piano di inserimento in colocation. La scansione costante contiene una riga per ogni ID partizione. Il lato interno del ciclo cerca la partizione corrente dell'heap (sì, una ricerca su un heap). L'ordinamento ha una proprietà id di partizione (nonostante questa sia costante per iterazione del ciclo), quindi c'è un ordinamento per partizione e il comportamento di versamento indesiderato. L'avviso sulle statistiche nella tabella heap è spurio.
La radice del piano di inserimento indica che è stata riservata una concessione di memoria di 1 MB, con un massimo di 144 KB utilizzati:
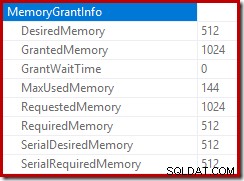
L'operatore di ordinamento non segnala uno spill di livello 15.000, ma per il resto fa un pasticcio completo dei calcoli relativi all'iterazione per ciclo coinvolti:

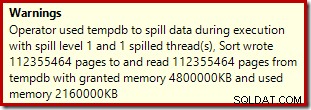
Il monitoraggio delle concessioni di memoria DMV durante l'esecuzione mostra che questa query riserva effettivamente solo 1 MB, con un massimo di 144 KB utilizzato su ogni iterazione del ciclo. (Al contrario, la riserva di memoria di 4,6 GB nel primo test è assolutamente genuina.) Questo ovviamente crea confusione.
Il problema (come accennato in precedenza) è che SQL Server si confonde sul modo migliore per segnalare ciò che è accaduto in molte iterazioni. Probabilmente non è pratico includere le informazioni sulle prestazioni del piano per partizione per iterazione, ma non si può sfuggire al fatto che l'attuale disposizione produce a volte risultati confusi. Possiamo solo sperare che un giorno si possa trovare un modo migliore per segnalare questo tipo di informazioni, in un formato più coerente.