Uno dei casi di utilizzo degli indici filtrati citati nella documentazione in linea riguarda una colonna che contiene principalmente NULLs valori. L'idea è di creare un indice filtrato che escluda i NULLs , risultando in un indice non cluster più piccolo che richiede meno manutenzione rispetto all'indice non filtrato equivalente. Un altro uso diffuso degli indici filtrati è quello di filtrare NULLs da un UNIQUE index, fornendo il comportamento che gli utenti di altri motori di database potrebbero aspettarsi da un UNIQUE predefinito indice o vincolo:l'univocità viene applicata solo per il non NULLs valori.
Purtroppo, Query Optimizer ha dei limiti per quanto riguarda gli indici filtrati. Questo post esamina un paio di esempi meno noti.
Tabelle di esempio
Utilizzeremo due tabelle (A e B) che hanno la stessa struttura:una chiave primaria cluster surrogata, per lo più -NULLs colonna che è univoca (senza tener conto di NULLs ) e una colonna di riempimento che rappresenta le altre colonne che potrebbero trovarsi in una tabella reale.
La colonna di interesse è prevalentemente-NULLs uno, che ho dichiarato come SPARSE . L'opzione sparse non è richiesta, la includo solo perché non ho molte possibilità di usarla. In ogni caso, SPARSE probabilmente ha senso in molti scenari in cui i dati della colonna dovrebbero essere per lo più NULLs . Sentiti libero di rimuovere l'attributo sparse dagli esempi, se lo desideri.
CREATE TABLE dbo.TableA
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
CREATE TABLE dbo.TableB
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
Ogni tabella contiene i numeri da 1 a 2.000 nella colonna dati con ulteriori 40.000 righe dove la colonna dati è NULLs :
-- Numbers 1 - 2,000
INSERT
dbo.TableA WITH (TABLOCKX)
(data)
SELECT TOP (2000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2
ORDER BY
ROW_NUMBER() OVER (ORDER BY (SELECT NULL));
-- NULLs
INSERT TOP (40000)
dbo.TableA WITH (TABLOCKX)
(data)
SELECT
CONVERT(bigint, NULL)
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2;
-- Copy into TableB
INSERT dbo.TableB WITH (TABLOCKX)
(data)
SELECT
ta.data
FROM dbo.TableA AS ta;
Entrambe le tabelle ottengono un UNIQUE indice filtrato per i 2.000 non NULLs valori dei dati:
CREATE UNIQUE NONCLUSTERED INDEX uqA ON dbo.TableA (data) WHERE data IS NOT NULL; CREATE UNIQUE NONCLUSTERED INDEX uqB ON dbo.TableB (data) WHERE data IS NOT NULL;
L'output di DBCC SHOW_STATISTICS riassume la situazione:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER; DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

Richiesta di esempio
La query seguente esegue un semplice join delle due tabelle:immagina che le tabelle siano in una sorta di relazione genitore-figlio e molte delle chiavi esterne siano NULL. Qualcosa del genere comunque.
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data; Piano di esecuzione predefinito
Con SQL Server nella sua configurazione predefinita, l'ottimizzatore sceglie un piano di esecuzione caratterizzato da un join di cicli annidati paralleli:
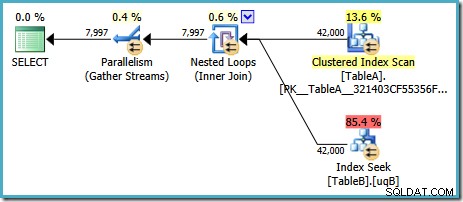
Questo piano ha un costo stimato di 7,7768 unità di ottimizzazione magica™.
Ci sono alcune cose strane in questo piano, tuttavia. La ricerca dell'indice utilizza il nostro indice filtrato sulla tabella B, ma la query è guidata da una scansione dell'indice cluster della tabella A. Il predicato di join è un test di uguaglianza sulle colonne di dati, che rifiuterà NULLs (indipendentemente da ANSI_NULLS collocamento). Avremmo potuto sperare che l'ottimizzatore eseguisse un ragionamento avanzato basato su tale osservazione, ma no. Questo piano legge ogni riga dalla tabella A (inclusi i 40.000 NULLs ), esegue una ricerca nell'indice filtrato sulla tabella B per ciascuno, basandosi sul fatto che NULLs non corrisponderà a NULLs in quella ricerca. Questo è un enorme spreco di sforzi.
La cosa strana è che l'ottimizzatore deve aver realizzato che il join rifiuta NULLs per scegliere l'indice filtrato per la tabella B cerca, ma non ha pensato di filtrare NULLs dalla tabella A prima – o meglio ancora, scansionare semplicemente il NULLs -indice filtrato gratuito sulla tabella A. Potresti chiederti se questa è una decisione basata sui costi, forse le statistiche non sono molto buone? Forse dovremmo forzare l'uso dell'indice filtrato con un suggerimento? Indicando l'indice filtrato sulla tabella A si ottiene solo lo stesso piano con i ruoli invertiti:scansione della tabella B e ricerca nella tabella A. Forzare l'indice filtrato per entrambe le tabelle produce errore 8622 :il Query Processor non ha potuto produrre un piano di query.
Aggiunta di un predicato NOT NULL
Sospettando che la causa sia qualcosa a che fare con il implicito NULLs -rifiuto del predicato join, aggiungiamo un esplicito NOT NULL predicato al ON clausola (o il WHERE clausola se preferisci, si tratta della stessa cosa qui):
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL;
Abbiamo aggiunto il NOT NULL controlla la colonna della tabella A perché il piano originale ha scansionato l'indice cluster di quella tabella anziché utilizzare il nostro indice filtrato (la ricerca nella tabella B andava bene:utilizzava l'indice filtrato). La nuova query è semanticamente esattamente la stessa della precedente, ma il piano di esecuzione è diverso:
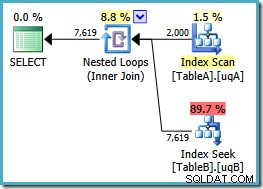
Ora abbiamo la scansione sperata dell'indice filtrato sulla tabella A, che produce 2.000 non NULLs righe per guidare il ciclo nidificato cerca nella tabella B. Entrambe le tabelle stanno utilizzando i nostri indici filtrati apparentemente in modo ottimale ora:il nuovo piano costa solo 0,362835 unità (in calo da 7,7768). Tuttavia, possiamo fare di meglio.
Aggiunta di due predicati NOT NULL
Il NOT NULL ridondante predicato per la tabella A ha funzionato a meraviglia; cosa succede se ne aggiungiamo uno anche per la tabella B?
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL; Questa query è ancora logicamente la stessa dei due tentativi precedenti, ma il piano di esecuzione è di nuovo diverso:
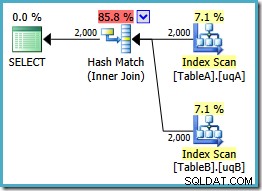
Questo piano crea una tabella hash per le 2.000 righe della tabella A, quindi cerca le corrispondenze utilizzando le 2.000 righe della tabella B. Il numero stimato di righe restituite è molto migliore del piano precedente (hai notato la stima di 7.619 lì?) e il costo di esecuzione stimato è sceso di nuovo, da 0,362835 a 0,0772056 .
Puoi provare a forzare un hash join usando un suggerimento sull'originale o single-NOT NULL domande, ma non otterrai il piano a basso costo mostrato sopra. L'ottimizzatore semplicemente non ha la capacità di ragionare completamente sul NULLs -rifiuto del comportamento del join in quanto si applica ai nostri indici filtrati senza entrambi i predicati ridondanti.
Puoi essere sorpreso da questo, anche se è solo l'idea che un predicato ridondante non fosse abbastanza (sicuramente se ta.data è NOT NULL e ta.data = tb.data , ne consegue che tb.data è anche NOT NULL , giusto?)
Non ancora perfetto
È un po' sorprendente vedere un hash che si unisce lì. Se hai familiarità con le principali differenze tra i tre operatori di join fisici, probabilmente saprai che l'hash join è un ottimo candidato in cui:
- L'input preordinato non è disponibile
- L'input di build hash è più piccolo dell'input probe
- L'ingresso della sonda è abbastanza grande
Nessuna di queste cose è vera qui. La nostra aspettativa sarebbe che il miglior piano per questa query e set di dati sarebbe un merge join, sfruttando l'input ordinato disponibile dai nostri due indici filtrati. Possiamo provare a suggerire un merge join, mantenendo i due extra ON predicati delle clausole:
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL
OPTION (MERGE JOIN); La forma del piano è come speravamo:
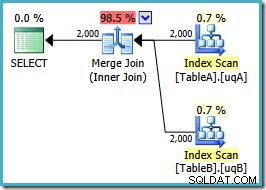
Una scansione ordinata di entrambi gli indici filtrati, ottime stime di cardinalità, fantastico. Solo un piccolo problema:questo piano di esecuzione è molto peggiore; il costo stimato è passato da 0,0772056 a 0,741527 . Il motivo del salto nel costo stimato viene rivelato controllando le proprietà dell'operatore di unione join:
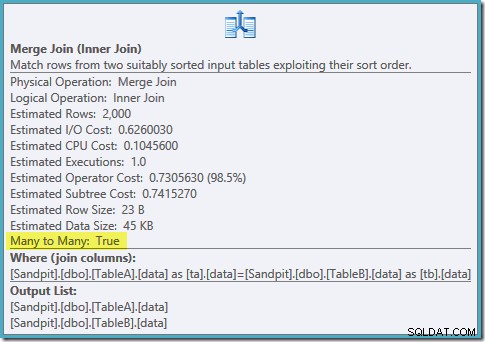
Questo è un costoso join molti-a-molti, in cui il motore di esecuzione deve tenere traccia dei duplicati dall'input esterno in un tavolo di lavoro e riavvolgere se necessario. Duplicati? Stiamo scansionando un indice univoco! Si scopre che l'ottimizzatore non sa che un indice univoco filtrato produce valori univoci (collegare l'elemento qui). In realtà si tratta di un join uno a uno, ma l'ottimizzatore costa come se fosse molti a molti, spiegando perché preferisce il piano di hash join.
Una strategia alternativa
Sembra che continuiamo a scontrarci con le limitazioni dell'ottimizzatore quando utilizziamo qui indici filtrati (nonostante sia un caso d'uso evidenziato nella documentazione in linea). Cosa succede se invece proviamo a utilizzare le visualizzazioni?
Utilizzo delle visualizzazioni
Le due viste seguenti filtrano semplicemente le tabelle di base per mostrare le righe in cui la colonna di dati è NOT NULL :
CREATE VIEW dbo.VA
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableA
WHERE data IS NOT NULL;
GO
CREATE VIEW dbo.VB
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableB
WHERE data IS NOT NULL; Riscrivere la query originale per utilizzare le viste è banale:
SELECT
v.data,
v2.data
FROM dbo.VA AS v
JOIN dbo.VB AS v2
ON v.data = v2.data; Ricorda che questa query originariamente produceva un piano di cicli annidati paralleli al costo di 7,7768 unità. Con i riferimenti di visualizzazione, otteniamo questo piano di esecuzione:
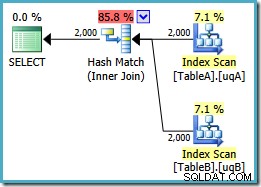
Questo è esattamente lo stesso piano di hash join che abbiamo dovuto aggiungere ridondante NOT NULL predicati da ottenere con gli indici filtrati (il costo è 0,0772056 unità come prima). Questo è previsto, perché tutto ciò che abbiamo essenzialmente fatto qui è stato spingere l'extra NOT NULL predicati dalla query a una vista.
Indicizzazione delle visualizzazioni
Possiamo anche provare a materializzare le viste creando un indice cluster unico nella colonna pk:
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VA (pk); CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VB (pk);
Ora possiamo aggiungere indici non cluster univoci sulla colonna dei dati filtrati nella vista indicizzata:
CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VA (data); CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VB (data);
Nota che il filtro viene eseguito nella vista, questi indici non cluster non vengono filtrati.
Il piano perfetto
Siamo ora pronti per eseguire la nostra query sulla vista, utilizzando NOEXPAND suggerimento per la tabella:
SELECT
v.data,
v2.data
FROM dbo.VA AS v WITH (NOEXPAND)
JOIN dbo.VB AS v2 WITH (NOEXPAND)
ON v.data = v2.data; Il piano di esecuzione è:
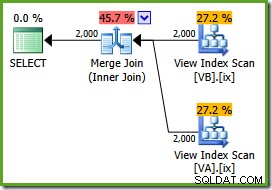
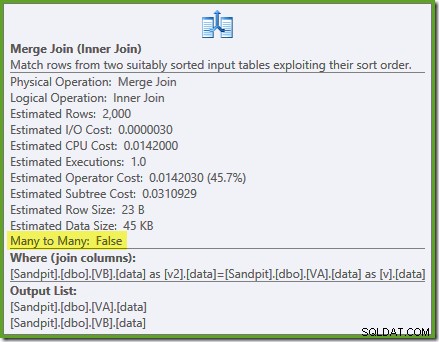
L'ottimizzatore può vedere il non filtrato gli indici di visualizzazione non cluster sono univoci, quindi non è necessario un join di unione molti-a-molti. Questo piano di esecuzione finale ha un costo stimato di 0,0310929 unità – anche inferiore al piano di hash join (0,0772056 unità). Ciò conferma la nostra aspettativa che un merge join dovrebbe avere il costo stimato più basso per questa query e set di dati di esempio.
Il NOEXPAND sono necessari suggerimenti anche in Enterprise Edition per garantire che la garanzia di unicità fornita dagli indici di visualizzazione venga utilizzata dall'ottimizzatore.
Riepilogo
Questo post evidenzia due importanti limitazioni dell'ottimizzatore con indici filtrati:
- Potrebbero essere necessari predicati di join ridondanti per abbinare gli indici filtrati
- Gli indici univoci filtrati non forniscono informazioni sull'unicità all'ottimizzatore
In alcuni casi può essere pratico aggiungere semplicemente i predicati ridondanti a ogni query. L'alternativa consiste nell'incapsulare i predicati impliciti desiderati in una vista non indicizzata. Il piano di corrispondenza hash in questo post era molto migliore del piano predefinito, anche se l'ottimizzatore dovrebbe essere in grado di trovare il piano di unione leggermente migliore. A volte, potrebbe essere necessario indicizzare la vista e utilizzare NOEXPAND suggerimenti (richiesti comunque per le istanze della Standard Edition). In altre circostanze ancora, nessuno di questi approcci sarà adatto. Mi dispiace :)



