Per qualsiasi nuovo database creato in SQL Server, il valore predefinito per l'opzione Statistiche di aggiornamento automatico è abilitato . Sospetto che la maggior parte dei DBA lasci l'opzione abilitata, poiché consente all'ottimizzatore di aggiornare automaticamente le statistiche quando vengono invalidate e generalmente si consiglia di lasciarla abilitata. Le statistiche vengono aggiornate anche quando gli indici vengono ricostruiti e, sebbene non sia raro che le statistiche siano ben gestite tramite l'opzione di aggiornamento automatico delle statistiche e tramite le ricostruzioni degli indici, di tanto in tanto un DBA potrebbe ritenere necessario impostare un lavoro regolare per aggiornare un statistica o insieme di statistiche.
La gestione personalizzata delle statistiche spesso implica il comando UPDATE STATISTICS, che sembra abbastanza benigno. Può essere eseguito per tutte le statistiche per una tabella o una vista indicizzata o per una statistica specifica. È possibile utilizzare il campione predefinito, specificare una frequenza di campionamento specifica o un numero di righe da campionare oppure utilizzare lo stesso valore di campionamento utilizzato in precedenza. Se le statistiche vengono aggiornate per una tabella o una vista indicizzata, puoi scegliere di aggiornare tutte le statistiche, solo le statistiche dell'indice o solo le statistiche delle colonne. E infine, puoi disabilitare l'opzione di aggiornamento automatico delle statistiche per una statistica.
Per la maggior parte dei DBA, la considerazione più importante potrebbe essere quando per eseguire l'istruzione UPDATE STATISTICS. Ma i DBA decidono anche, consapevolmente o meno, la dimensione del campione per l'aggiornamento. La dimensione del campione selezionata può influire sulle prestazioni dell'aggiornamento effettivo, nonché sulle prestazioni delle query.
Comprendere gli effetti della dimensione del campione
La dimensione del campione predefinita per UPDATE STATISTICS deriva da un algoritmo non lineare e la dimensione del campione diminuisce all'aumentare della dimensione della tabella, come ha mostrato Joe Sack nel suo post, Test di campionamento predefinito delle statistiche di aggiornamento automatico. In alcuni casi, la dimensione del campione potrebbe non essere sufficientemente ampia per acquisire informazioni interessanti sufficienti o il destra informazioni, per l'istogramma delle statistiche, come notato da Conor Cunningham nel suo post sui tassi di campionamento delle statistiche. Se il campione predefinito non crea un buon istogramma, i DBA possono scegliere di aggiornare le statistiche con una frequenza di campionamento più elevata, fino a un FULLSCAN (scansione di tutte le righe nella tabella o vista indicizzata). Ma come menzionato da Conor nel suo post, la scansione di più righe ha un costo e il DBA deve decidere se eseguire un FULLSCAN per provare a creare l'istogramma "migliore" possibile, o campionare una percentuale più piccola per ridurre al minimo l'impatto sulle prestazioni di l'aggiornamento.
Per cercare di capire a che punto un campione impiega più tempo di un FULLSCAN, ho eseguito le seguenti istruzioni rispetto alle copie della tabella SalesOrderDetail che sono state ingrandite utilizzando lo script di Jonathan Kehayias:
| ID dichiarazione | istruzione UPDATE STATISTICS |
|---|---|
| 1 | AGGIORNAMENTO STATISTICHE [Sales].[SalesOrderDetailEnlarged] CON FULLSCAN; |
| 2 | AGGIORNAMENTO STATISTICHE [Sales].[SalesOrderDetailEnlarged]; |
| 3 | AGGIORNAMENTO STATISTICHE [Sales].[SalesOrderDetailEnlarged] CON IL CAMPIONE 10 PERCENT; |
| 4 | AGGIORNAMENTO STATISTICHE [Sales].[SalesOrderDetailEnlarged] CON IL CAMPIONE 25 PERCENT; |
| 5 | AGGIORNA LE STATISTICHE [Sales].[SalesOrderDetailEnlarged] CON IL CAMPIONE 50 PERCENT; |
| 6 | AGGIORNAMENTO STATISTICHE [Sales].[SalesOrderDetailEnlarged] CON IL CAMPIONE 75 PERCENT; |
Avevo tre copie della tabella SalesOrderDetailEnlarged, con le seguenti caratteristiche*:
| Conteggio righe | Conteggio pagine | MAXDOP | Memoria massima | Archiviazione | Macchina |
|---|---|---|---|---|---|
| 23.899.449 | 363.284 | 4 | 8 GB | SSD_1 | Laptop |
| 607.312.902 | 7.757.200 | 16 | 54 GB | SSD_2 | Server di prova |
| 607.312.902 | 7.757.200 | 16 | 54 GB | 15K | Server di prova |
*Ulteriori dettagli sull'hardware sono alla fine di questo post.
Tutte le copie della tabella avevano le seguenti statistiche e nessuna delle tre statistiche dell'indice includeva colonne:
| Statistica | Tipo | Colonne in chiave |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Indice | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Indice | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Indice | ID prodotto |
| user_CarrierTrackingNumber | Colonna | NumeroCarrierTracking |
Ho eseguito le istruzioni UPDATE STATISTICS di cui sopra quattro volte ciascuna sulla tabella SalesOrderDetailEnlarged sul mio laptop e due volte ciascuna sulle tabelle SalesOrderDetailEnlarged sul TestServer. Le istruzioni venivano eseguite ogni volta in ordine casuale e la cache delle procedure e la cache del buffer venivano cancellate prima di ogni istruzione di aggiornamento. La durata e l'utilizzo di tempdb per ogni set di istruzioni (media) sono nei grafici seguenti:
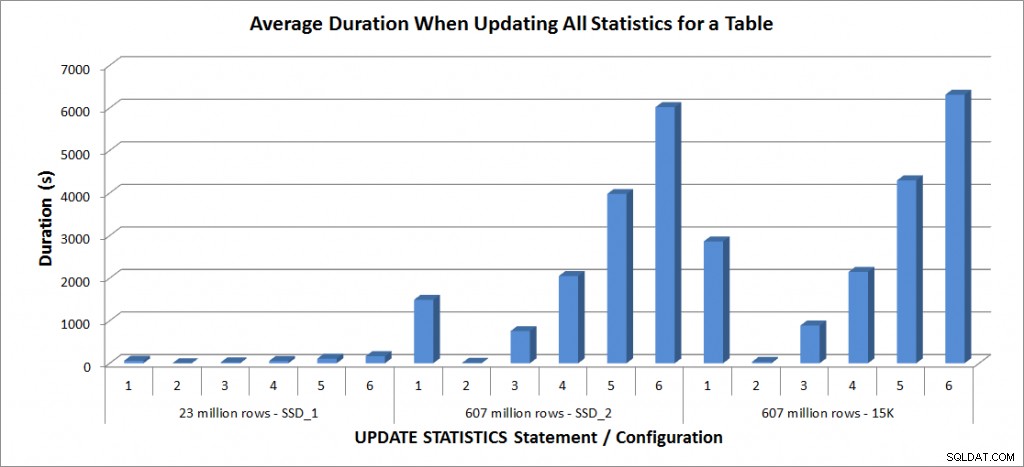
Durata media – Aggiorna tutte le statistiche per SalesOrderDetailEnlarged
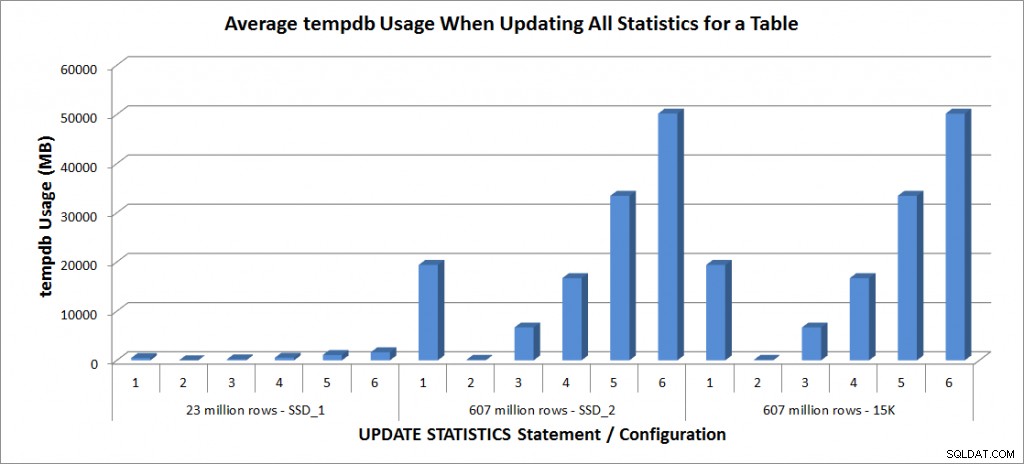
Utilizzo tempdb – Aggiorna tutte le statistiche per SalesOrderDetailEnlarged
Le durate per la tabella di 23 milioni di righe erano tutte inferiori a tre minuti e sono descritte più dettagliatamente nella sezione successiva. Per la tabella sui dischi SSD_2, l'istruzione FULLSCAN ha impiegato 1492 secondi (quasi 25 minuti) e l'aggiornamento con un campione del 25% ha impiegato 2051 secondi (oltre 34 minuti). Al contrario, sui dischi da 15K, l'istruzione FULLSCAN ha richiesto 2864 secondi (oltre 47 minuti) e l'aggiornamento con un campione del 25% ha richiesto 2147 secondi (quasi 36 minuti), meno del tempo FULLSCAN. Tuttavia, l'aggiornamento con un campione del 50% ha richiesto 4296 secondi (oltre 71 minuti).
L'utilizzo di tempdb è molto più coerente, mostrando un aumento costante all'aumentare della dimensione del campione e utilizzando più spazio tempdb rispetto a un FULLSCAN compreso tra il 25% e il 50%. Ciò che è degno di nota qui è che UPDATE STATISTICS fa usa tempdb, importante da ricordare quando si ridimensiona tempdb per un ambiente SQL Server. L'utilizzo di tempdb è menzionato nella voce UPDATE STATISTICS BOL:
UPDATE STATISTICS può utilizzare tempdb per ordinare il campione di righe per la creazione di statistiche."
E l'effetto è documentato nel post di Linchi Shea, Impatto sulle prestazioni:tempdb e statistiche di aggiornamento. Tuttavia, non è qualcosa sempre menzionato durante le discussioni sul dimensionamento di tempdb. Se disponi di tabelle di grandi dimensioni ed esegui aggiornamenti con FULLSCAN o valori di esempio elevati, tieni presente l'utilizzo di tempdb.
Prestazioni degli aggiornamenti selettivi
Successivamente ho deciso di testare le istruzioni UPDATE STATISTICS per le altre statistiche sulla tabella, ma ho limitato i miei test alla copia della tabella con 23 milioni di righe. Le sei variazioni precedenti dell'istruzione UPDATE STATISTICS sono state ripetute quattro volte ciascuna per le seguenti singole statistiche e quindi confrontate con l'aggiornamento per l'intera tabella:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Tutti i test sono stati eseguiti con la suddetta configurazione sul mio laptop e i risultati sono nel grafico seguente:
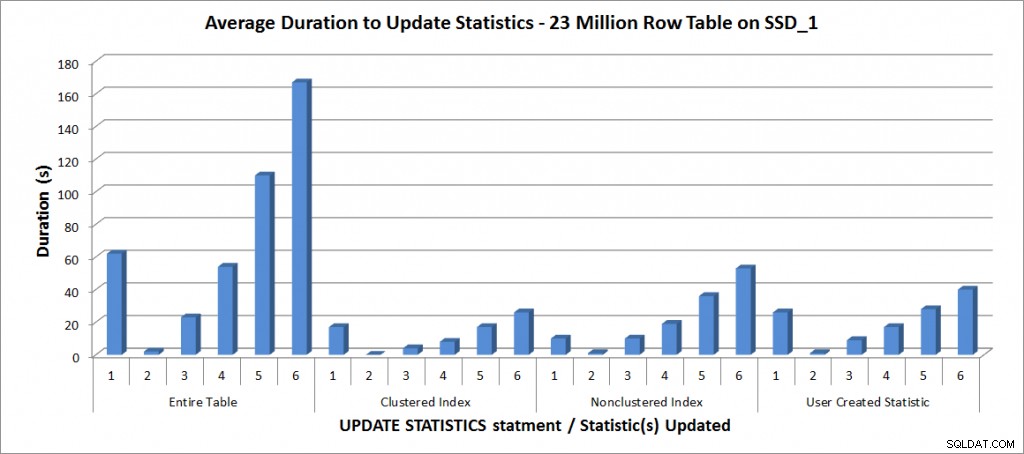
Durata media per l'AGGIORNAMENTO STATISTICHE:tutte le statistiche rispetto a quelle selezionate
Come previsto, gli aggiornamenti di una singola statistica hanno richiesto meno tempo rispetto all'aggiornamento di tutte le statistiche per la tabella. Il valore al quale l'aggiornamento campionato ha richiesto più tempo di un FULLSCAN variava:
| istruzione UPDATE | Durata/i FULLSCAN | Primo AGGIORNAMENTO che ha richiesto più tempo |
|---|---|---|
| Intera tabella | 62 | 50% – 110 secondi |
| Indice cluster | 17 | 75% – 26 secondi |
| Indice non cluster | 10 | 25% – 19 secondi |
| Statistiche create dall'utente | 26 | 50% – 28 secondi |
Conclusione
Sulla base di questi dati e dei dati FULLSCAN delle 607 milioni di tabelle di righe, non esiste una specifica punto critico in cui un aggiornamento campionato richiede più tempo di un FULLSCAN; quel punto dipende dalle dimensioni della tabella e dalle risorse disponibili. Ma i dati sono ancora utili in quanto dimostrano che c'è un punto in cui l'acquisizione di un valore campionato può richiedere più tempo rispetto a un FULLSCAN. Si tratta di nuovo di conoscere i tuoi dati. Questo è fondamentale non solo per capire se una tabella necessita di una gestione personalizzata delle statistiche, ma anche per comprendere la dimensione del campione ideale per creare un istogramma utile e anche ottimizzare l'utilizzo delle risorse.
Specifiche
Specifiche del laptop:Dell M6500, 1 Intel i7 (2.13GHz 4 core e HT è abilitato quindi 8 core logici), 32 GB di memoria, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), file di database archiviati su un SSD Samsung da 265 GB PM810Specifiche del server di test:Dell R720, 2 Intel E5-2670 (2,6 GHz 8 core e HT è abilitato quindi 16 core logici per socket), 64 GB di memoria, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), file di database per una tabella si trova su due schede MLC Fusion-io Duo da 640 GB, i file di database per l'altra tabella si trovano su nove dischi da 15.000 RPM in un array RAID5