Un impegno per l'ottimizzazione delle prestazioni può richiedere molti turni durante il lavoro:tutto dipende da ciò che si presenta come il problema e da ciò che i dati ti dicono. Alcuni giorni atterra su una query specifica, o un insieme di query, che può essere migliorata con indici, nuovi o modifiche agli indici esistenti. Una delle mie parti preferite dell'ottimizzazione è lavorare con gli indici e, mentre stavo pensando a questo post, sono stato tentato di etichettare l'ottimizzazione degli indici come un'attività "più facile" ... ma in realtà non lo è.
Penso all'indicizzazione come un'arte e una scienza. Devi provare a pensare come l'ottimizzatore e devi comprendere lo schema della tabella e la query (o le query) che stai cercando di ottimizzare. Entrambi sono basati sui dati e quindi nella categoria della scienza. La componente artistica entra in gioco quando pensi all'altro indici sul tavolo e tutti l'altro query che coinvolgono la tabella che potrebbe essere influenzata dalle modifiche all'indice.
Fase 1:identifica la query e rivedi il piano
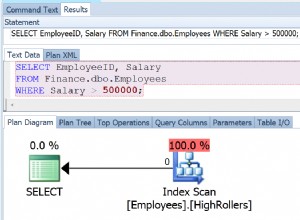
Quando identifico una query che potrebbe trarre vantaggio da un indice, ottengo immediatamente il suo piano. Spesso ottengo il piano di esecuzione dalla cache del piano o dal Query Store, quindi utilizzo SSMS per ottenere il piano di esecuzione più le statistiche di runtime (ovvero il piano di esecuzione effettivo). Molte volte, la forma di quei due piani è la stessa; ma non è una garanzia, motivo per cui mi piace vedere entrambi.
Il piano potrebbe avere una raccomandazione sull'indice mancante, potrebbe avere un'analisi dell'indice in cluster (o un'analisi dell'heap se non è presente un indice in cluster), potrebbe utilizzare un indice non in cluster ma quindi avere una ricerca per recuperare colonne aggiuntive. Risolvere ciascuno di questi problemi individualmente sembra abbastanza facile. Basta aggiungere l'indice mancante, giusto? Se è presente una scansione di un indice o di un heap cluster, creare l'indice di cui ho bisogno per la query e il gioco è fatto? Oppure, se viene utilizzato un indice ma va alla tabella per ottenere le colonne aggiuntive, aggiungi semplicemente le colonne a quell'indice?
Di solito non è così facile, e anche quando lo è, continuo a seguire il processo che sto delineando qui.
Fase 2:determina quali tabelle rivedere
Ora che ho la mia query, devo capire quali tabelle non sono indicizzate correttamente. Oltre a rivedere il piano, abilito anche le statistiche IO e TIME in SSMS. Questa è probabilmente la mia vecchia scuola, poiché i piani di esecuzione contengono sempre più informazioni, inclusi durata e numeri di I/O per operatore, con ogni versione, ma mi piacciono le statistiche di I/O perché posso vedere rapidamente le letture per ogni tabella. Per le query complesse con più join, sottoquery, CTE o viste nidificate, capire dove viene speso l'IO e/o il tempo nelle unità di query in cui trascorro il mio tempo. Quando possibile da questo punto, prendo la query più grande e complessa e la riduco alla parte che sta causando il problema più grande.
Ad esempio, se c'è una query che si unisce a 10 tabelle e ha due sottoquery, il piano (insieme alle informazioni sull'IO e sulla durata) mi aiuta a identificare dove esiste il problema. Quindi tirerò fuori quella parte della query - la tabella problematica e forse un paio di altre a cui si unisce - e mi concentrerò su quella. A volte è solo la sottoquery, quindi comincio da lì.
Passaggio 3:esamina gli indici esistenti
Con la query (o parte della query) definita, mi concentro sugli indici esistenti per le tabelle coinvolte. Per questo passaggio, mi affido alla versione di sp_helpindex di Kimberly. Preferisco di gran lunga la sua versione allo sp_helpindex standard perché elenca anche le colonne INCLUDEd e la definizione del filtro (se ne esiste una). A seconda del numero di indici visualizzati per una tabella, lo copierò spesso e lo incollerò in Excel, quindi ordinerò in base alla chiave dell'indice e quindi alle colonne incluse. Questo mi consente di trovare rapidamente eventuali ridondanze.
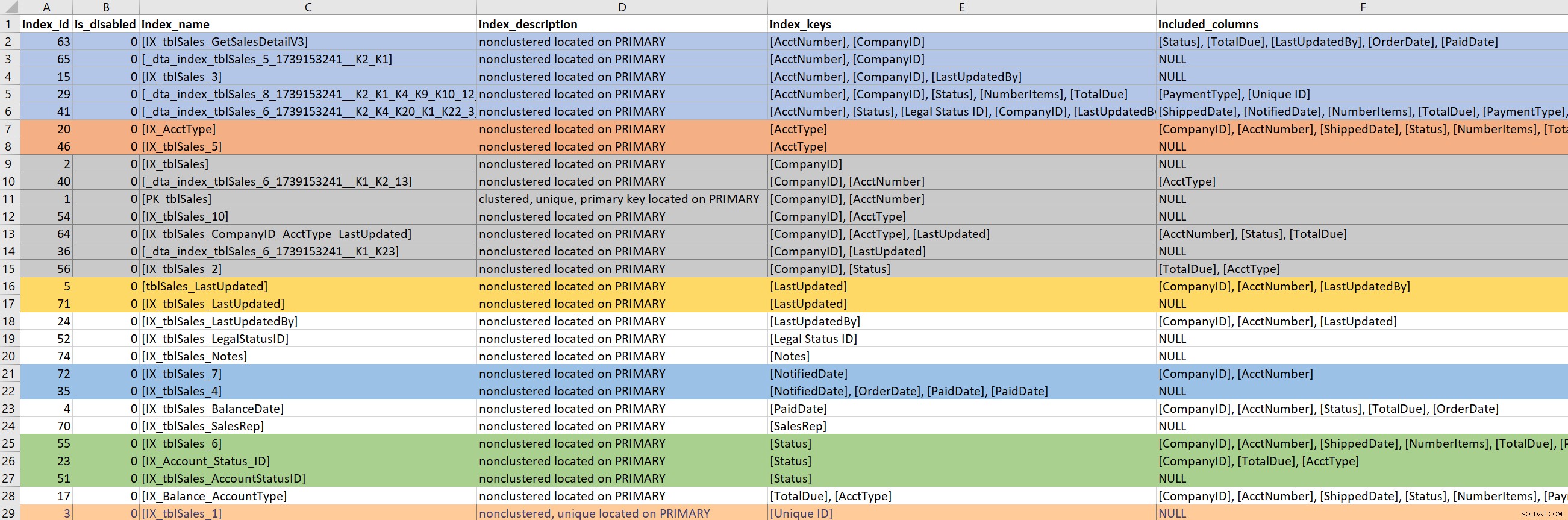
Sulla base dell'output di esempio sopra, ci sono sette indici che iniziano con CompanyID, cinque che iniziano con AcctNumber e alcune altre potenziali ridondanze. Anche se sembra ideale averne solo uno indice che porta su una particolare colonna (ad es. CompanyID), per alcuni modelli di query che non sono sufficienti.
Quando guardo gli indici esistenti, è molto facile andare in una tana del coniglio. Guardo l'output sopra e inizio immediatamente a chiedere perché ci sono sette indici che iniziano con CompanyID e voglio sapere chi li ha creati, perché e per quale query. Ma... se la mia query problematica non utilizza CompanyID, dovrei preoccuparmi? Sì... perché in generale sono lì per migliorare le prestazioni, e se questo significa guardare altri indici sul tavolo lungo il percorso, allora così sia. Ma è qui che è facile perdere la cognizione del tempo (e del vero scopo).
Se la mia query problematica ha bisogno di un indice che porta a PaidDate, devo gestire solo un indice esistente. Se la mia query problematica ha bisogno di un indice che porta su AcctNumber, diventa complicato. Quando gli indici esistenti coprono una query e sto cercando di espandere un indice (aggiungere più colonne) o consolidare (unire due o forse tre indici in uno), allora devo scavare.
Fase 4:Statistiche sull'utilizzo dell'indice
Trovo che molte persone non acquisiscano le statistiche sull'utilizzo dell'indice su base continuativa. Questo è un peccato, perché trovo che i dati siano utili per decidere quali indici mantenere e quali eliminare o unire. Nel caso in cui non disponga di statistiche di utilizzo storiche, controllo almeno per vedere come appare attualmente l'utilizzo (dall'ultimo riavvio del servizio):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
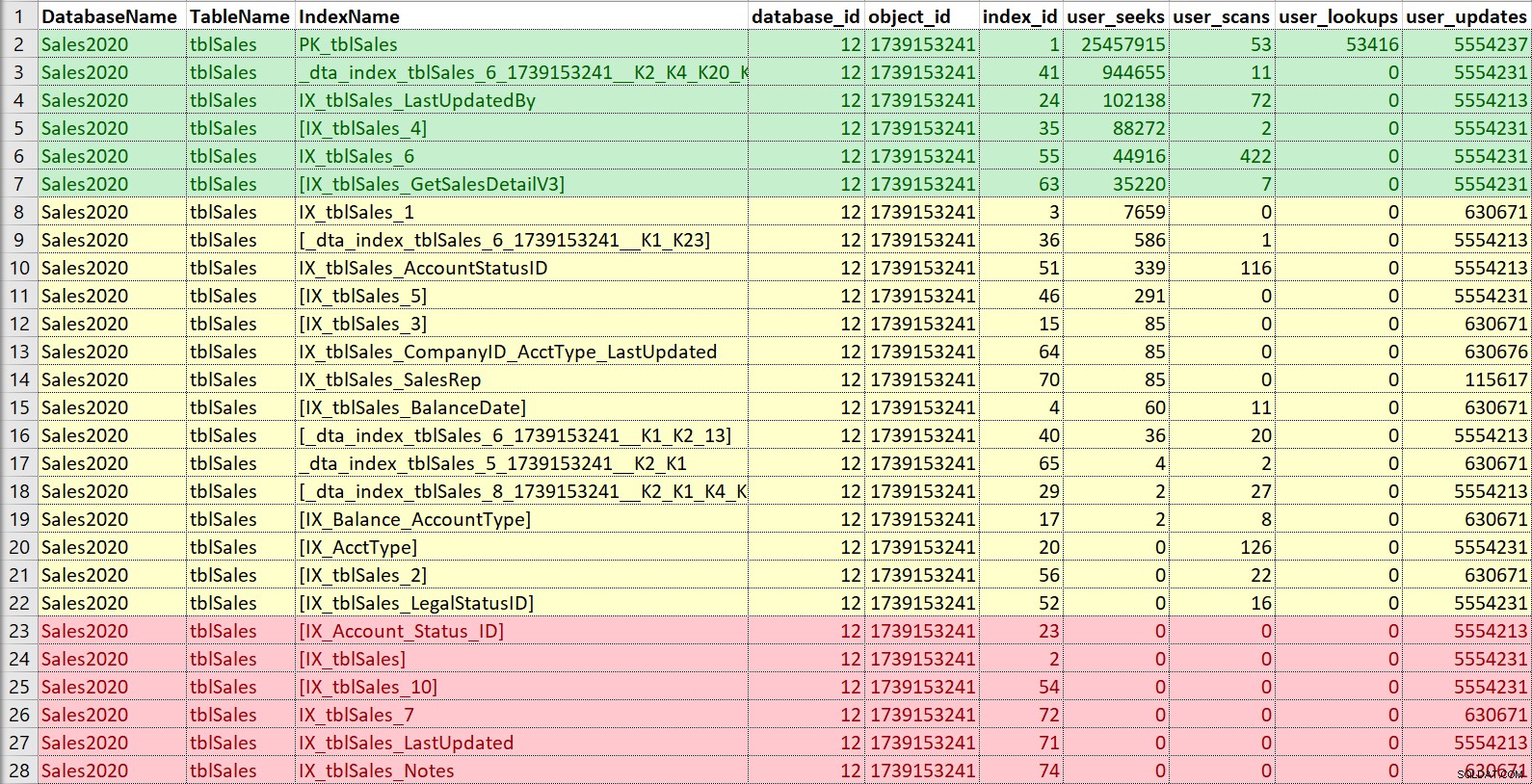
Ancora una volta, mi piace inserirlo in Excel, ordinare per ricerche e quindi scansioni e anche prendere nota degli aggiornamenti. Per questo esempio, gli indici in rosso sono quelli senza ricerche, scansioni o ricerche... solo aggiornamenti. Questi sono candidati per essere disabilitati e potenzialmente abbandonati, se non vengono davvero utilizzati (di nuovo, avere una cronologia di utilizzo aiuterebbe qui). Gli indici in verde sono sicuramente in uso, li voglio mantenere (anche se forse in alcuni casi potrebbero essere modificati). Quelli in giallo... alcuni sono usati, altri a malapena. Anche in questo caso, la cronologia sarebbe utile in questo caso o il contesto di altri:a volte un indice può essere fondamentale per un rapporto o un processo che non viene eseguito continuamente.
Se sto solo cercando di modificare o aggiungere un nuovo indice, rispetto a una vera pulizia e consolidamento, mi preoccupo principalmente di tutti gli indici simili a quelli che voglio aggiungere o modificare. Tuttavia, mi assicurerò di indicare le informazioni sull'utilizzo al cliente e, se il tempo lo consente, assisterò con la strategia di indicizzazione generale per la tabella.
Cosa c'è dopo?
Non abbiamo finito! Questa è la parte 1 del mio approccio all'ottimizzazione dell'indice e la mia prossima puntata elencherà il resto dei miei passaggi. Nel frattempo, se non stai acquisendo le statistiche sull'utilizzo dell'indice, è qualcosa che puoi mettere in atto utilizzando la query sopra o un'altra variazione. Consiglierei di acquisire le statistiche di utilizzo per tutti i database utente, non solo una tabella e un database specifici come ho fatto sopra, quindi modifica il predicato se necessario. E infine, come parte del lavoro pianificato per eseguire lo snapshot di tali informazioni su una tabella, non dimenticare un altro passaggio per ripulire la tabella dopo che i dati sono stati presenti per un po' (lo conservo per almeno sei mesi; qualcuno potrebbe dire un anno è necessario).