SQL Server 2014 SP2 e versioni successive producono piani di esecuzione di runtime ("effettivi") che possono includere tempo trascorso e Utilizzo della CPU per ogni operatore del piano di esecuzione (vedi KB3170113 e questo post del blog di Pedro Lopes).
Interpretare questi numeri non è sempre così semplice come ci si potrebbe aspettare. Esistono differenze importanti tra la modalità riga e modalità batch esecuzione, nonché problemi complicati con il parallelismo della modalità riga . SQL Server apporta alcune aggiustamenti della tempistica parallelamente piani per promuovere la coerenza, ma non sono perfettamente attuati. Ciò può rendere difficile trarre conclusioni sull'ottimizzazione delle prestazioni audio.
Questo articolo ha lo scopo di aiutarti a capire da dove provengono i tempi in ciascun caso e come possono essere interpretati al meglio nel contesto.
Configurazione
Gli esempi seguenti utilizzano lo Stack Overflow 2013 pubblico database (dettagli download), con un unico indice aggiunto:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Le query del test restituiscono il numero di domande con una risposta accettata, raggruppate per mese e anno. Vengono eseguiti su SQL Server 2019 CU9 , su un laptop con 8 core e 16 GB di memoria allocati all'istanza di SQL Server 2019. Livello di compatibilità 150 viene utilizzato esclusivamente.
Esecuzione seriale in modalità batch
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Il piano di esecuzione è (clicca per ingrandire):
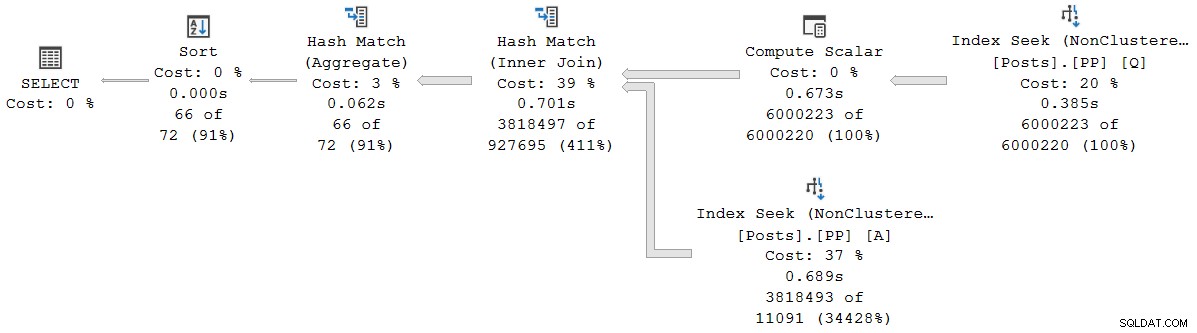
Ogni operatore in questo piano viene eseguito in modalità batch, grazie alla modalità batch su rowstore Funzionalità di elaborazione delle query intelligente in SQL Server 2019 (non è necessario alcun indice columnstore). La query viene eseguita per 2.523 ms con 2.522 ms di tempo CPU utilizzato, quando tutti i dati necessari sono già nel pool di buffer.
Come nota Pedro Lopes nel post del blog collegato in precedenza, i tempi trascorsi e CPU riportati per la singola modalità batch gli operatori rappresentano il tempo utilizzato da solo quell'operatore .
SSMS mostra il tempo trascorso nella rappresentazione grafica. Per vedere i orari della CPU , seleziona un operatore del piano, quindi cerca nelle Proprietà finestra. Questa visualizzazione dettagliata mostra sia il tempo trascorso che quello della CPU, per operatore e per thread.
I tempi dello showplan (compresa la rappresentazione XML) sono troncati a millisecondi. Se hai bisogno di una maggiore precisione, usa il query_thread_profile evento esteso, che riporta in microsecondi . L'output di questo evento per il piano di esecuzione mostrato sopra è:
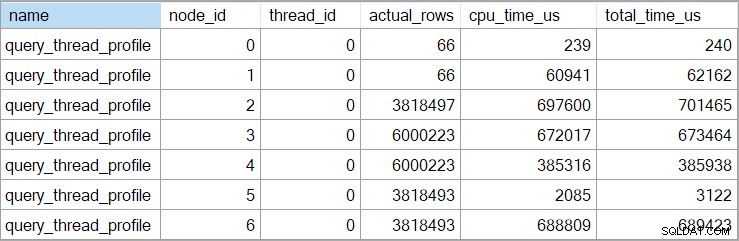
Questo mostra che il tempo trascorso per il join (nodo 2) è 701.465 µs (troncato a 701 ms in showplan). L'aggregato ha un tempo trascorso di 62.162 µs (62 ms). La ricerca dell'indice "domande" viene visualizzata come in esecuzione per 385 ms, mentre l'evento esteso mostra che la cifra reale per il nodo 4 era 385.938 µs (quasi quasi 386 ms).
SQL Server utilizza l'alta precisione QueryPerformanceCounter API per acquisire i dati di temporizzazione. Questo utilizza hardware, in genere un oscillatore a cristallo, che produce tick a una velocità costante molto elevata indipendentemente dalla velocità del processore, dalle impostazioni di alimentazione o da qualsiasi cosa del genere. L'orologio continua a funzionare alla stessa velocità anche durante il sonno. Vedi l'articolo molto dettagliato collegato se sei interessato a tutti i dettagli più fini. Il breve riassunto è che puoi fidarti che i numeri dei microsecondi siano accurati.
In questo piano in modalità batch pura, il tempo di esecuzione totale è molto vicino alla somma dei tempi trascorsi dal singolo operatore. La differenza è in gran parte dovuta al lavoro successivo alla dichiarazione non associato agli operatori del piano (che a quel punto hanno tutti chiuso), sebbene anche il troncamento di millisecondi abbia un ruolo.
Nei piani in modalità batch pura, è necessario sommare manualmente i tempi dell'operatore corrente e figlio per ottenere il cumulativo tempo trascorso in un dato nodo.
Esecuzione parallela in modalità batch
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Il piano di esecuzione è:
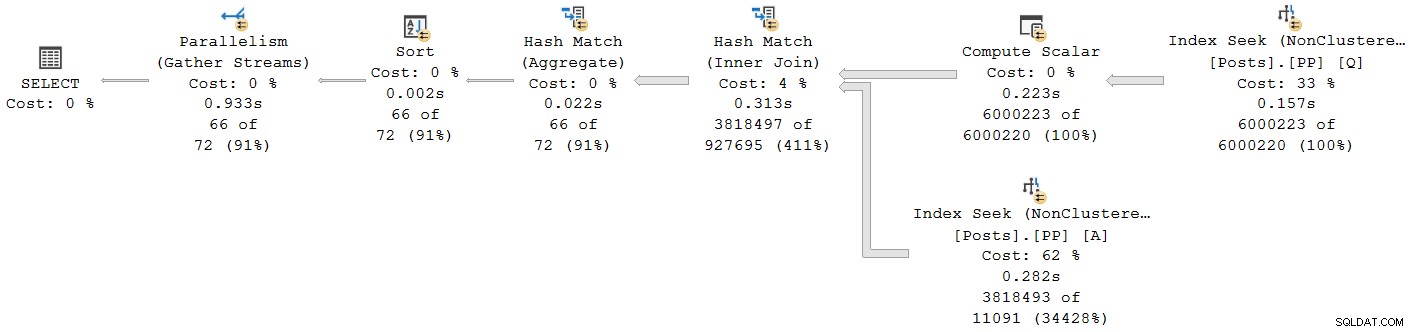
Ogni operatore, tranne lo scambio di flusso di raccolta finale, viene eseguito in modalità batch. Il tempo totale trascorso è 933 ms con 6.673 ms di tempo CPU con una cache calda.
Selezionare l'hash join e cercare nelle Proprietà di SSMS finestra, vediamo il tempo trascorso e CPU per thread per quell'operatore:
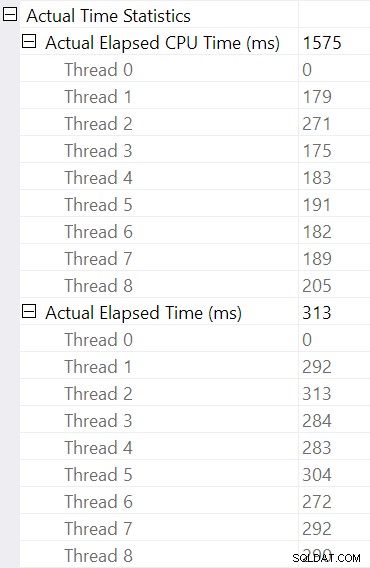
L'ora della CPU riportato per l'operatore è la somma dei tempi di CPU del singolo thread. L'operatore segnalato tempo trascorso è il massimo dei tempi per thread trascorsi. Entrambi i calcoli vengono eseguiti sui valori di millisecondi troncati per thread. Come prima, il tempo totale di esecuzione è molto vicino alla somma dei tempi trascorsi dal singolo operatore.
I piani paralleli in modalità batch non utilizzano gli scambi per distribuire il lavoro tra i thread. Gli operatori batch vengono implementati in modo che più thread possano lavorare in modo efficiente su una singola struttura condivisa (es. tabella hash). È ancora necessaria una certa sincronizzazione tra i thread nei piani paralleli in modalità batch, ma i punti di sincronizzazione e altri dettagli non sono visibili nell'output di showplan.
Esecuzione seriale in modalità riga
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Il piano di esecuzione è visivamente lo stesso del piano seriale in modalità batch, ma ora ogni operatore è in esecuzione in modalità riga:
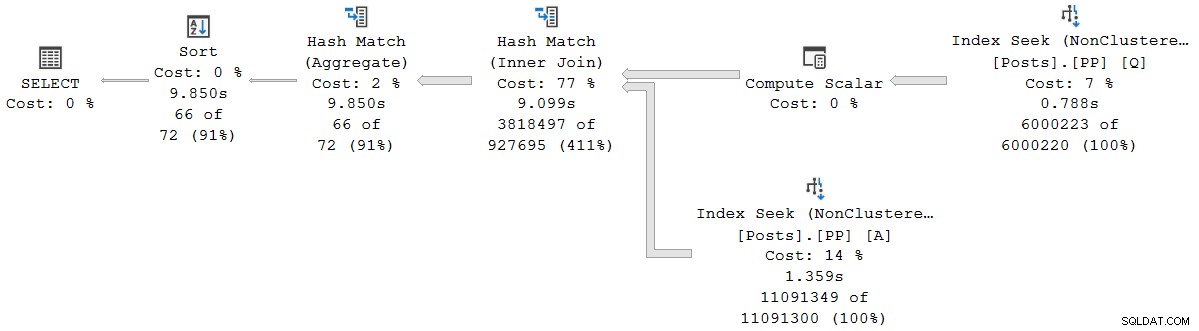
La query viene eseguita per 9.850 ms con 9.845 ms di tempo CPU. Questo è molto più lento della query in modalità batch seriale (2523 ms/2522 ms), come previsto. Ancora più importante per la presente discussione, la modalità riga operatore trascorso e i tempi della CPU rappresentano il tempo utilizzato dall'operatore corrente e da tutti i suoi figli .
L'evento esteso mostra anche la CPU cumulativa e i tempi trascorsi su ciascun nodo (in microsecondi):
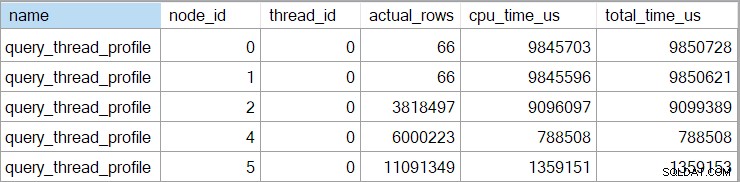
Non ci sono dati per l'operatore scalare di calcolo (nodo 3) perché l'esecuzione in modalità riga può differire la maggior parte dei calcoli delle espressioni all'operatore che utilizza il risultato. Questo non è attualmente implementato per l'esecuzione in modalità batch.
Il cumulativo segnalato il tempo trascorso per gli operatori in modalità riga indica che il tempo mostrato per l'operatore di ordinamento finale corrisponde molto al tempo di esecuzione totale della query (comunque con una risoluzione in millisecondi). Allo stesso modo, il tempo trascorso per l'hash join include i contributi delle due ricerche di indice al di sotto di esso, nonché il proprio tempo. Per calcolare il tempo trascorso per il solo join hash in modalità riga, dovremmo sottrarre entrambi i tempi di ricerca da esso.
Ci sono vantaggi e svantaggi per entrambe le presentazioni (cumulative per la modalità riga, operatore singolo solo per la modalità batch). Qualunque cosa tu preferisca, è importante essere consapevoli delle differenze.
Piani per modalità di esecuzione mista
In generale, i moderni piani di esecuzione possono contenere qualsiasi combinazione di operatori in modalità riga e modalità batch. Gli operatori in modalità batch riporteranno i tempi solo per se stessi. Gli operatori della modalità riga includeranno un totale cumulativo fino a quel momento nel piano, inclusi tutti operatori figli. Per essere chiari:i tempi cumulativi di un operatore in modalità riga includono qualsiasi operatore figlio in modalità batch.
Lo abbiamo visto in precedenza nel piano della modalità batch parallela:l'operatore dei flussi di raccolta finale (modalità riga) aveva un tempo trascorso (cumulativo) visualizzato di 0,933 secondi, inclusi tutti i suoi operatori della modalità batch figlio. Gli altri operatori erano tutti in modalità batch, quindi riportavano i tempi solo per il singolo operatore.
Questa situazione, in cui alcuni operatori del piano nello stesso piano hanno tempi cumulativi e altri no, sarà senza dubbio considerato confuso da molte persone.
Esecuzione parallela in modalità riga
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Il piano di esecuzione è:

Ogni operatore è in modalità riga. La query viene eseguita per 4.677 ms con 23.311 ms di tempo CPU (somma di tutti i thread).
Essendo un piano esclusivamente in modalità riga, ci aspetteremmo che tutti i tempi siano cumulativi . Passando dal figlio al genitore (da destra a sinistra), i tempi dovrebbero aumentare in quella direzione.
Diamo un'occhiata alla sezione più a destra del piano:
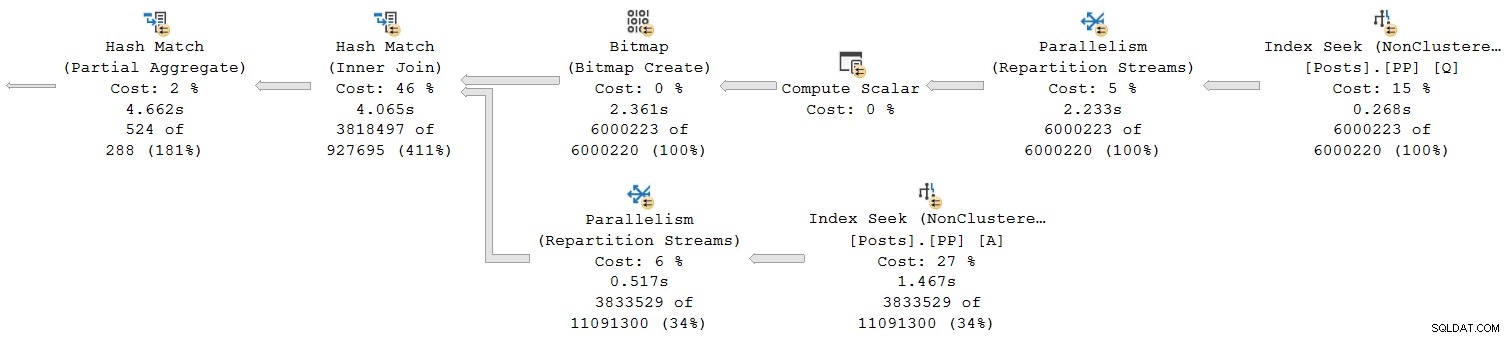
Lavorando da destra a sinistra nella riga superiore, i tempi cumulativi sembrano certamente essere il caso. Ma c'è un'eccezione sull'input inferiore all'hash join:la ricerca dell'indice ha un tempo trascorso di 1,467 s , mentre il suo genitore flussi di ripartizione ha un tempo trascorso di soli 0,517 secondi .
Come può un genitore operatore eseguito per meno tempo rispetto a suo figlio se i tempi trascorsi sono cumulativi nei piani in modalità riga?
Tempi incoerenti
Ci sono diverse parti per la risposta a questo enigma. Prendiamolo pezzo per pezzo, perché è piuttosto complesso:
Innanzitutto, ricorda che uno scambio (operatore di parallelismo) ha due parti. La mano sinistra (consumatore ) è collegato a una serie di thread che eseguono operatori nel ramo parallelo a sinistra. La mano destra (produttore ) dello scambio è collegato a un diverso insieme di thread che eseguono operatori nel ramo parallelo a destra.
Le righe dal lato produttore sono assemblate in pacchetti e poi trasferito al lato consumatore. Ciò fornisce un grado di buffering e controllo del flusso tra le due serie di fili collegati. (Se hai bisogno di un aggiornamento su scambi e rami di piani paralleli, consulta il mio articolo Piani di esecuzione paralleli – Rami e thread.)
La portata dei tempi cumulativi
Guardando il ramo parallelo sul produttore lato dello scambio:
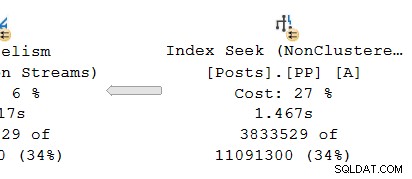
Come al solito, i thread di lavoro aggiuntivi DOP (grado di parallelismo) eseguono un seriale indipendente copia degli operatori del piano in questo ramo. Quindi, a DOP 8, ci sono 8 ricerche di indici seriali indipendenti che cooperano per eseguire la parte di scansione dell'intervallo dell'operazione di ricerca dell'indice complessiva (parallela). Ogni ricerca a thread singolo è collegata a un input (porta) diverso sul lato produttore del single shared operatore di cambio.
Una situazione simile esiste per il consumatore lato dello scambio. In DOP 8, ci sono 8 copie separate a thread singolo di questo ramo, tutte eseguite in modo indipendente:
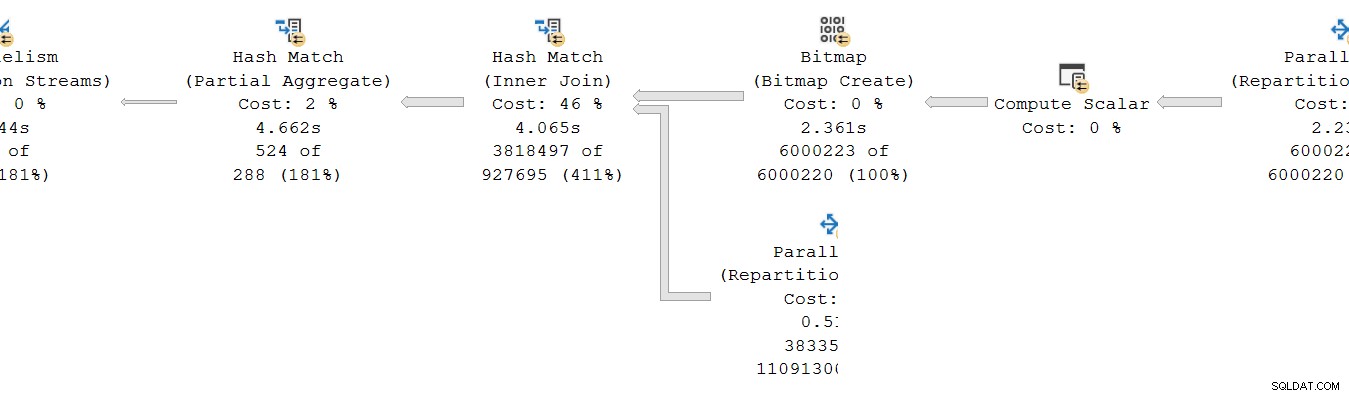
Ciascuno di questi sottopiani a thread singolo viene eseguito nel modo consueto, con ogni operatore che accumula il tempo trascorso e il tempo CPU totale su ciascun nodo. Essendo operatori in modalità riga, ogni totale rappresenta il tempo trascorso il totale cumulativo per il nodo corrente e ciascuno dei suoi figli.
Il punto cruciale è che i totali cumulativi includi solo operatori sullo stesso thread e solo all'interno del ramo corrente . Si spera che questo abbia un senso intuitivo, perché ogni thread non ha idea di cosa potrebbe succedere altrove.
Come vengono raccolte le metriche in modalità riga
La seconda parte del puzzle riguarda il modo in cui il conteggio delle righe e le metriche temporali vengono raccolte nei piani della modalità riga. Quando sono richieste informazioni sul piano di runtime ("effettivi"), il motore di esecuzione aggiunge un invisibile operatore di profilazione alla immediata sinistra (principale) di ogni operatore nel piano che verrà eseguito in fase di esecuzione.
Questo operatore può registrare (tra le altre cose) la differenza tra il momento in cui ha passato il controllo al suo operatore figlio e il momento in cui il controllo è stato restituito. Questa differenza di tempo rappresenta il tempo trascorso per l'operatore monitorato e tutti i suoi figli , poiché il figlio chiama il proprio figlio per riga e così via. Un operatore può essere chiamato più volte (per inizializzare, poi una per riga, infine per chiudere) quindi il tempo raccolto dall'operatore di profilazione è un accumulo su potenzialmente molte iterazioni per riga.
Per maggiori dettagli sui dati di profilazione raccolti utilizzando diversi metodi di acquisizione, vedere la documentazione del prodotto relativa all'infrastruttura di profilazione delle query. Per chi fosse interessato a queste cose, il nome dell'operatore di profilazione invisibile utilizzato dall'infrastruttura standard è sqlmin!CQScanProfileNew . Come tutti gli iteratori in modalità riga, ha Open , GetRow e Close metodi, tra gli altri. Ciascun metodo contiene chiamate a QueryPerformanceCounter di Windows API per raccogliere il valore corrente del timer ad alta risoluzione.
Poiché l'operatore di profilazione è a sinistra dell'operatore target, misura solo il consumatore lato dello scambio. Non esiste nessun operatore di profilazione per il produttore lato dello scambio (purtroppo). Se ci fosse, corrisponderebbe o supererebbe il tempo trascorso mostrato sulla ricerca dell'indice, perché la ricerca dell'indice e il lato produttore eseguono lo stesso set di thread e il lato produttore dello scambio è l'operatore padre della ricerca dell'indice.
Tempo rivisitato

Detto questo, potresti comunque avere problemi con i tempi mostrati sopra. In che modo una ricerca di un indice può richiedere 1.467s per passare le righe al lato produttore di uno scambio, ma il lato consumatore prende solo 0,517s riceverli? Indipendentemente da thread separati, buffering e quant'altro, sicuramente lo scambio dovrebbe durare (end-to-end) più a lungo di quanto non faccia la ricerca?
Ebbene sì, ma è una misurazione diversa dal tempo trascorso o CPU. Cerchiamo di essere precisi su ciò che stiamo misurando qui.
Per la modalità riga tempo trascorso , immagina un cronometro per thread presso ogni operatore. Il cronometro parte quando SQL Server immette il codice per un operatore dal relativo padre e si interrompe (ma non si ripristina) quando quel codice lascia che l'operatore restituisca il controllo al genitore (non a un figlio). Il tempo trascorso include eventuali attese o ritardi di programmazione, nessuno di questi ferma l'orologio.
Per la modalità riga Tempo CPU , immagina lo stesso cronometro con le stesse caratteristiche, tranne che si ferma durante le attese e i ritardi di programmazione. Accumula solo tempo quando l'operatore o uno dei suoi figli sta eseguendo attivamente su uno scheduler (CPU). Il tempo totale su un cronometro per thread per operatore è costruito da un ciclo di avvio-arresto per ogni riga.
Applichiamolo alla situazione attuale con il lato consumatore dello scambio e l'indice cerca:
Ricorda, il lato consumer dello scambio e quello di ricerca dell'indice sono in rami separati, quindi funzionano su thread separati . Il lato consumatore non ha figli nello stesso thread. La ricerca dell'indice ha il lato produttore dello scambio come genitore dello stesso thread, ma non abbiamo un cronometro lì.
Ogni thread consumer avvia il controllo quando il suo operatore padre (il lato probe dell'hash join) passa il controllo (ad esempio per recuperare una riga). L'orologio continua a funzionare mentre il consumatore recupera una riga dal pacchetto di scambio corrente. L'orologio si ferma quando il controllo lascia il consumatore e ritorna al lato della sonda hash join. Altri genitori (l'aggregato parziale e il relativo scambio padre) lavoreranno anche su quella riga (e potrebbero attendere) prima che il controllo ritorni sul lato consumer del nostro scambio per recuperare la riga successiva. A quel punto, il lato consumer del nostro scambio ricomincia ad accumulare tempo trascorso e CPU.
Nel frattempo, indipendentemente da qualunque cosa possano fare i thread del ramo lato consumatore, l'indice cerca i thread continuano a individuare le righe nell'indice e ad alimentarle nello scambio. Un thread di ricerca dell'indice avvia il suo cronometro quando il lato produttore dello scambio gli chiede una riga. Il cronometro viene messo in pausa quando la riga viene passata allo scambio. Quando lo scambio richiede la riga successiva, il cronometro di ricerca dell'indice riprende.
Nota che il lato produttore dello scambio potrebbe riscontrare CXPACKET attende che i buffer di scambio si riempiano, ma ciò non si aggiungerà ai tempi trascorsi registrati alla ricerca dell'indice perché il suo cronometro non è in funzione quando ciò accade. Se avessimo un cronometro per il produttore dello scambio, il tempo trascorso mancante verrebbe visualizzato lì.
Per approssimare visivamente un riepilogo della situazione, il diagramma seguente mostra quando ciascun operatore accumula il tempo trascorso nei due rami paralleli:
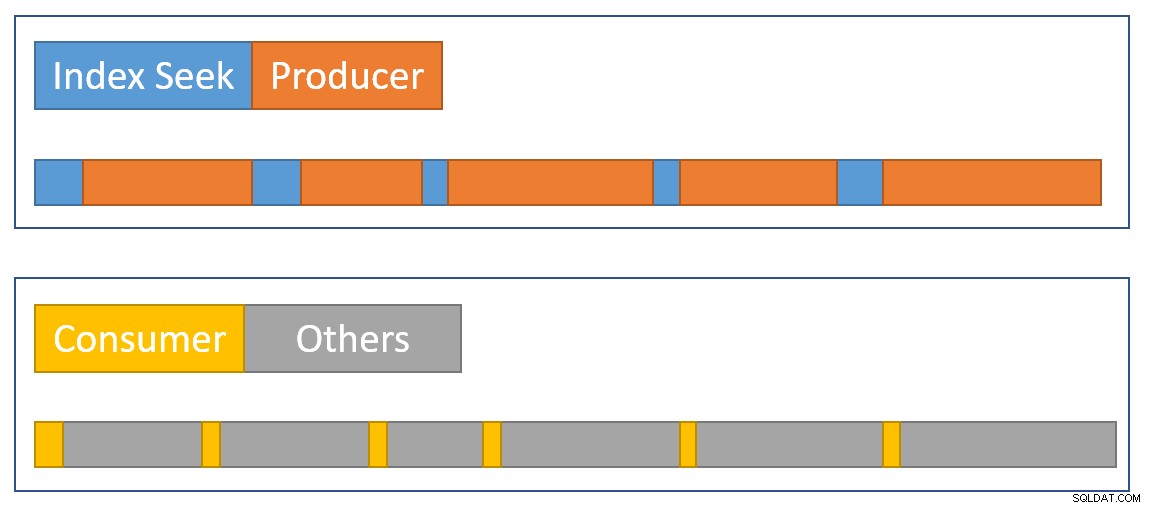
Il blu Le barre temporali di ricerca dell'indice sono brevi perché il recupero di una riga da un indice è veloce. L'arancione i tempi del produttore potrebbero essere lunghi a causa di CXPACKET aspetta. Il giallo i tempi del consumatore sono brevi perché è veloce recuperare una riga dallo scambio quando i dati sono disponibili. Il grigio i segmenti temporali rappresentano il tempo utilizzato dagli altri operatori (lato sonda hash join, aggregato parziale e lato produttore dello scambio padre) sopra il lato consumatore dello scambio.
Prevediamo che i pacchetti di scambio vengano riempiti rapidamente dall'indice di ricerca, ma svuotato lentamente (relativamente parlando) dagli operatori lato consumatore perché hanno più lavoro da fare. Ciò significa che i pacchetti nello scambio saranno generalmente pieni o quasi pieni. Il consumatore sarà in grado di recuperare rapidamente una riga di attesa, ma il produttore potrebbe dover attendere che venga visualizzato lo spazio per i pacchetti.
È un peccato non poter vedere i tempi trascorsi dal lato produttore dello scambio. Sono stato a lungo del parere che uno scambio dovrebbe essere rappresentato da due diversi operatori nei piani di esecuzione. Renderebbe difficile CXPACKET /CXCONSUMER attendere l'analisi molto meno necessaria e i piani di esecuzione molto più facili da capire. L'operatore del produttore di scambio otterrebbe naturalmente il proprio operatore di profilazione.
Design alternativi
Esistono molti modi in cui SQL Server può ottenere un cumulativo coerente tempo trascorso e CPU tra rami paralleli in linea di principio . Invece di profilare gli operatori, ogni riga potrebbe contenere informazioni sulla quantità di tempo trascorsa e sulla CPU accumulata fino a quel momento durante il percorso attraverso il piano. Con la cronologia associata a ciascuna riga, non importa come gli scambi ridistribuiscono le righe tra i thread e così via.
Non è così che è stato progettato il prodotto, quindi non è quello che abbiamo (e potrebbe essere comunque inefficiente). Per essere onesti, il design della modalità riga originale riguardava solo cose come la raccolta dei conteggi di righe effettivi e il numero di iterazioni per ciascun operatore. L'aggiunta del tempo trascorso per operatore ai piani era una funzione molto richiesta , ma non è stato facile integrarlo nel framework esistente.
Quando l'elaborazione in modalità batch è stata aggiunta al prodotto, è stato possibile implementare un approccio diverso (tempistica solo per l'operatore corrente) come parte dello sviluppo originale senza interrompere nulla. Ancora una volta, in linea di principio , gli operatori della modalità riga avrebbero potuto essere modificati per funzionare allo stesso modo degli operatori della modalità batch, ma ciò avrebbe richiesto molto lavoro per riprogettare ogni operatore della modalità riga esistente. L'aggiunta di un nuovo punto dati agli operatori di profilatura in modalità riga esistenti è stata molto più semplice. Date le risorse ingegneristiche limitate e un lungo elenco di miglioramenti del prodotto desiderati, spesso è necessario scendere a compromessi come questo.
Il secondo problema
Un'altra incoerenza temporale cumulativa si verifica nel presente piano sul lato sinistro:

A prima vista, sembra lo stesso problema:l'aggregato parziale ha un tempo trascorso di 4,662 secondi , ma lo scambio di cui sopra funziona solo per 2,844 . Ovviamente sono in gioco le stesse meccaniche di base di prima, ma c'è un altro fattore importante. Un indizio risiede nei tempi sospettosamente uguali segnalati per lo scambio di aggregazione, ordinamento e ripartizionamento del flusso.
Ricordi le "regolazioni dei tempi" che ho menzionato nell'introduzione? È qui che entrano in gioco quelli. Diamo un'occhiata ai singoli tempi trascorsi per i thread sul lato consumer dello scambio di flussi di ripartizione:
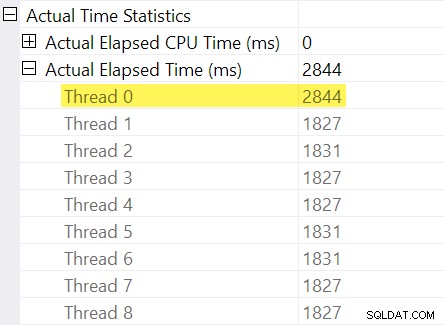
Ricordiamo che i piani mostrano il tempo trascorso per un operatore parallelo come massimo dei tempi per thread. Tutti gli 8 thread hanno avuto un tempo trascorso di circa 1.830 ms, ma c'è una voce aggiuntiva per "Thread 0" con 2.844 ms. Infatti ogni operatore in questo ramo parallelo (l'exchange consumer, l'ordinamento e l'aggregato stream) hanno lo stesso 2.844 ms di contributo da "Thread 0".
Il thread zero (noto anche come attività padre o coordinatore) esegue solo direttamente gli operatori a sinistra dell'operatore dei flussi di raccolta finale. Perché gli è stato assegnato un lavoro qui, in un ramo parallelo?
Spiegazione
Questo problema può verificarsi quando è presente un operatore di blocco nel ramo parallelo sotto (a destra di) quello attuale. Senza questo adeguamento, gli operatori dell'attuale filiale sottostimano il tempo trascorso dalla quantità di tempo necessaria per aprire il ramo figlio (ci sono complicati ragioni architettoniche per questo).
SQL Server cerca di tenere conto di ciò registrando il ritardo del ramo figlio allo scambio nell'operatore di profilatura invisibile. Il valore temporale viene registrato rispetto all'attività principale ("Thread 0") nella differenza tra il suo primo attivo e ultimo attivo volte. (Potrebbe sembrare strano registrare il numero in questo modo, ma nel momento in cui è necessario registrare il numero, i thread di lavoro paralleli aggiuntivi non sono ancora stati creati).
Nel caso attuale, la aggiustamento di 2.844 ms sorge principalmente a causa del tempo impiegato dall'hash join per creare la sua tabella hash. (Nota questa volta è diverso dal totale tempo di esecuzione dell'hash join, che include il tempo impiegato per elaborare il lato probe del join).
La necessità di un adeguamento sorge perché un hash join sta bloccando il suo input di compilazione. (È interessante notare che l'hash aggregato parziale nel piano non è considerato un blocco in questo contesto perché gli viene assegnata solo una quantità minima di memoria, non si riversa mai su tempdb , e interrompe semplicemente l'aggregazione se esaurisce la memoria (tornando così a una modalità di streaming). Craig Freedman lo spiega nel suo post, Partial Aggregation).
Dato che la regolazione del tempo trascorso rappresenta un ritardo di inizializzazione nel ramo figlio, SQL Server dovrebbe per trattare il valore "Thread 0" come un offset per i numeri di tempo trascorso per thread misurati all'interno del ramo corrente. Prendendo il massimo di tutti i thread poiché il tempo trascorso è ragionevole in generale, poiché i thread tendono ad avviarsi contemporaneamente. non ha senso farlo quando uno dei valori del thread è un offset per tutti gli altri valori!
Possiamo eseguire il calcolo corretto dell'offset manualmente utilizzando i dati disponibili nel piano. Dal lato consumatore dello scambio abbiamo:
Il tempo massimo trascorso tra i thread di lavoro aggiuntivi è 1.831 ms (escluso il valore di offset memorizzato in “Thread 0”). Aggiunta dell'offset di 2.844 ms fornisce un totale di 4.675 ms .
In qualsiasi piano in cui i tempi per thread sono minori rispetto all'offset, l'operatore erroneamente mostra l'offset come il tempo trascorso totale. È probabile che ciò si verifichi quando l'operatore di blocco precedente è lento (forse un ordinamento o un aggregato globale su un ampio set di dati) e gli operatori di filiale successivi richiedono meno tempo.
Rivisitazione di questa parte del piano:
Sostituendo l'offset di 2.844 ms assegnato erroneamente ai flussi di ripartizione, ordina e aggrega gli operatori con i nostri 4.675 ms calcolati value mette i loro tempi cumulativi trascorsi nettamente tra i 4.662 ms dell'aggregato parziale e i 4.676 ms ai flussi finali di raccolta. (L'ordinamento e l'aggregazione operano su un numero ridotto di righe in modo che i loro calcoli del tempo trascorso risultino uguali all'ordinamento, ma in generale sarebbero spesso diversi):

Tutti gli operatori nel frammento del piano sopra hanno 0 ms di tempo CPU trascorso su tutti i thread (a parte l'aggregato parziale, che ha 14.891 ms). Il piano con i nostri numeri calcolati ha quindi molto più senso di quello visualizzato:
- 4.675 ms – 4.662 ms =13 ms trascorso è un numero molto più ragionevole per il tempo impiegato dai flussi di ripartizione solo . Questo operatore non consuma tempo CPU ed elabora solo 524 righe.
- 0 ms trascorso (alla risoluzione in millisecondi) è ragionevole per l'aggregato di ordinamento e streaming minuscolo (di nuovo, esclusi i loro figli).
- 4.676 ms – 4.675 ms =1 ms sembra opportuno che i flussi di raccolta finali raccolgano 66 righe nel thread dell'attività padre per restituirle al client.
A parte l'ovvia incoerenza nel piano dato tra i flussi di aggregazione parziale (4.662 ms) e di ripartizione (2.844 ms), è irragionevole pensare che i flussi di raccolta finali di 66 righe possano essere responsabili di 4.676 ms – 2.844 ms = 1.832 ms del tempo trascorso. Il numero corretto (1 ms) è molto più preciso e non ingannerà i sintonizzatori di query.
Ora, anche se questo calcolo dell'offset fosse eseguito correttamente, i piani in modalità riga parallela potrebbero non mostrare tempi cumulativi coerenti in tutti i casi, per i motivi discussi in precedenza. Raggiungere una coerenza completa potrebbe essere difficile, o addirittura impossibile, senza importanti modifiche all'architettura.
Per anticipare una domanda che potrebbe sorgere a questo punto:No, la precedente analisi di scambio e ricerca dell'indice non ha comportato un errore di calcolo dell'offset "Thread 0". Non è presente alcun operatore di blocco al di sotto di tale scambio, quindi non si verifica alcun ritardo nell'inizializzazione.
Un ultimo esempio
Questa query di esempio successiva utilizza lo stesso database e indice di prima. Non lo esplorerò troppo in dettaglio perché serve solo ad approfondire punti che ho già fatto, per il lettore interessato.
Le caratteristiche di questa demo sono:
- Senza un
ORDER GROUPsuggerimento, mostra come un aggregato parziale non sia considerato un operatore di blocco, quindi non si verifica alcun aggiustamento "Thread 0" allo scambio dei flussi di ripartizione. I tempi trascorsi sono coerenti. - Con il suggerimento, vengono introdotti gli ordinamenti di blocco invece di un aggregato parziale hash. Due diversi Le regolazioni "Thread 0" vengono visualizzate nei due scambi di ripartizionamento. I tempi trascorsi sono incoerenti su entrambi i rami, in modi diversi.
Domanda:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Piano di esecuzione senza ORDER GROUP (nessuna regolazione, tempi coerenti):

Piano di esecuzione con ORDER GROUP (due diverse regolazioni, tempi incoerenti):

Summary and conclusions
Row mode plan operators report cumulative times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.