Questa è la terza parte di una serie sulle soluzioni alla sfida del generatore di serie numeriche. Nella parte 1 ho trattato le soluzioni che generano le righe al volo. Nella parte 2 ho trattato le soluzioni che interrogano una tabella di base fisica che precompila con le righe. Questo mese mi concentrerò su una tecnica affascinante che può essere utilizzata per affrontare la nostra sfida, ma che ha anche applicazioni interessanti ben oltre. Non sono a conoscenza di un nome ufficiale per la tecnica, ma è in qualche modo simile nel concetto all'eliminazione della partizione orizzontale, quindi la chiamerò informalmente eliminazione dell'unità orizzontale tecnica. La tecnica può avere interessanti vantaggi in termini di prestazioni, ma ci sono anche avvertimenti di cui devi essere consapevole, in quanto in determinate condizioni può incorrere in una penalità di prestazione.
Grazie ancora ad Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea e Paul White per aver condiviso idee e commenti.
Farò i miei test in tempdb, abilitando le statistiche temporali:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Idee precedenti
La tecnica di eliminazione delle unità orizzontali può essere utilizzata in alternativa alla logica di eliminazione delle colonne, o eliminazione delle unità verticali tecnica, su cui ho fatto affidamento in molte delle soluzioni che ho trattato in precedenza. Puoi leggere i fondamenti della logica di eliminazione delle colonne con le espressioni di tabella in Nozioni di base sulle espressioni di tabella, Parte 3 – Tabelle derivate, considerazioni sull'ottimizzazione in "Proiezione di colonne e una parola su SELECT *".
L'idea di base della tecnica di eliminazione delle unità verticali è che se si dispone di un'espressione di tabella nidificata che restituisce le colonne x e y e la query esterna fa riferimento solo alla colonna x, il processo di compilazione della query elimina y dall'albero della query iniziale e quindi il piano non ha bisogno di valutarlo. Ciò ha diverse implicazioni positive relative all'ottimizzazione, come il raggiungimento della copertura dell'indice solo con x e, se y è il risultato di un calcolo, non è necessario valutare affatto l'espressione sottostante di y. Questa idea era al centro della soluzione di Alan Burstein. Ho anche fatto affidamento su di esso in molte delle altre soluzioni che ho trattato, ad esempio con la funzione dbo.GetNumsAlanCharlieItzikBatch (dalla parte 1), le funzioni dbo.GetNumsJohn2DaveObbishAlanCharlieItzik e dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 (dalla parte 2) e altri. Ad esempio, userò dbo.GetNumsAlanCharlieItzikBatch come soluzione di base con la logica di eliminazione verticale.
Come promemoria, questa soluzione usa un join con una tabella fittizia che ha un indice columnstore per ottenere l'elaborazione batch. Ecco il codice per creare la tabella fittizia:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Ed ecco il codice con la definizione della funzione dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Ho usato il codice seguente per testare le prestazioni della funzione con 100 milioni di righe, restituendo la colonna del risultato calcolato n (manipolazione del risultato della funzione ROW_NUMBER), ordinata per n:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Ecco le statistiche temporali che ho ottenuto per questo test:
Tempo CPU =9328 ms, tempo trascorso =9330 ms.Ho usato il codice seguente per testare le prestazioni della funzione con 100 milioni di righe, restituendo la colonna rn (diretta, non manipolata, risultato della funzione ROW_NUMBER), ordinata per rn:
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Ecco le statistiche temporali che ho ottenuto per questo test:
Tempo CPU =7296 ms, tempo trascorso =7291 ms.Esaminiamo le idee importanti che sono incorporate in questa soluzione.
Basandosi sulla logica di eliminazione delle colonne, Alan ha avuto l'idea di restituire non solo una colonna con la serie numerica, ma tre:
- Colonna rn rappresenta un risultato non manipolato della funzione ROW_NUMBER, che inizia con 1. È economico da calcolare. È la conservazione dell'ordine sia quando si forniscono costanti sia quando si forniscono non costanti (variabili, colonne) come input per la funzione. Ciò significa che quando la tua query esterna utilizza ORDER BY rn, non ottieni un operatore di ordinamento nel piano.
- Colonna n rappresenta un calcolo basato su @low, una costante e rownum (risultato della funzione ROW_NUMBER). È la conservazione dell'ordine rispetto a rownum quando si forniscono costanti come input alla funzione. Questo grazie all'intuizione di Charlie riguardo alla piegatura costante (vedi Parte 1 per i dettagli). Tuttavia, non si tratta di preservare l'ordine quando si forniscono input non costanti, poiché non si ottiene un ripiegamento costante. Lo dimostrerò più avanti nella sezione sulle avvertenze.
- Colonna op rappresenta n in ordine opposto. È il risultato di un calcolo e non è la conservazione dell'ordine.
Basandosi sulla logica di eliminazione delle colonne, se devi restituire una serie di numeri che iniziano con 1, esegui una query sulla colonna rn, che è più economica rispetto alla query n. Se hai bisogno di una serie di numeri che inizi con un valore diverso da 1, esegui una query n e paghi il costo aggiuntivo. Se hai bisogno del risultato ordinato per la colonna del numero, con le costanti come input puoi usare sia ORDER BY rn che ORDER BY n. Ma con non costanti come input, assicurati di utilizzare ORDER BY rn. Potrebbe essere una buona idea attenersi sempre all'utilizzo di ORDER BY rn quando è necessario che il risultato ordinato sia al sicuro.
L'idea di eliminazione dell'unità orizzontale è simile all'idea di eliminazione dell'unità verticale, solo che si applica a insiemi di righe anziché a insiemi di colonne. In effetti, Joe Obbish ha fatto affidamento su questa idea nella sua funzione dbo.GetNumsObbish (dalla parte 2) e faremo un ulteriore passo avanti. Nella sua soluzione, Joe ha unificato più query che rappresentano sottointervalli disgiunti di numeri, utilizzando un filtro nella clausola WHERE di ciascuna query per definire l'applicabilità del sottointervallo. Quando chiami la funzione e passi input costanti che rappresentano i delimitatori dell'intervallo desiderato, SQL Server elimina le query inapplicabili in fase di compilazione, quindi il piano non le riflette nemmeno.
Eliminazione unità orizzontale, tempo di compilazione rispetto a tempo di esecuzione
Forse sarebbe una buona idea iniziare dimostrando il concetto di eliminazione orizzontale delle unità in un caso più generale e discutere anche un'importante distinzione tra eliminazione in fase di compilazione ed eliminazione in fase di esecuzione. Quindi possiamo discutere su come applicare l'idea alla nostra sfida delle serie numeriche.
Userò tre tabelle chiamate dbo.T1, dbo.T2 e dbo.T3 nel mio esempio. Utilizza il seguente codice DDL e DML per creare e popolare queste tabelle:
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Si supponga di voler implementare un TVF inline chiamato dbo.OneTable che accetta uno dei tre nomi di tabella precedenti come input e restituisce i dati dalla tabella richiesta. Sulla base del concetto di eliminazione dell'unità orizzontale, è possibile implementare la funzione in questo modo:
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
Ricorda che un TVF in linea applica l'incorporamento dei parametri. Ciò significa che quando si passa una costante come N'dbo.T2' come input, il processo di inlining sostituisce tutti i riferimenti a @WhichTable con la costante prima dell'ottimizzazione . Il processo di eliminazione può quindi rimuovere i riferimenti a T1 e T3 dall'albero delle query iniziale e quindi l'ottimizzazione delle query risulta in un piano che fa riferimento solo a T2. Proviamo questa idea con la seguente query:
SELECT * FROM dbo.OneTable(N'dbo.T2');
Il piano per questa query è mostrato nella Figura 1.
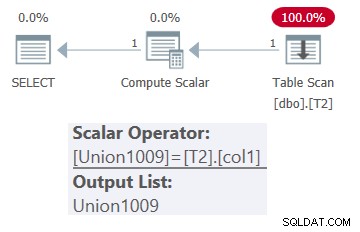 Figura 1:piano per dbo.OneTable con input costante
Figura 1:piano per dbo.OneTable con input costante
Come puoi vedere, nel piano compare solo la tabella T2.
Le cose sono un po' più complicate quando si passa una non costante come input. Questo potrebbe essere il caso quando si utilizza una variabile, un parametro di procedura o si passa una colonna tramite APPLY. Il valore di input è sconosciuto al momento della compilazione oppure è necessario prendere in considerazione il potenziale di riutilizzo del piano parametrizzato.
L'ottimizzatore non può eliminare nessuna delle tabelle dal piano, ma ha comunque un trucco. Può utilizzare gli operatori di filtro di avvio sopra i sottoalberi che accedono alle tabelle ed eseguire solo il sottoalbero pertinente in base al valore di runtime di @WhichTable. Utilizza il codice seguente per testare questa strategia:
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
Il piano per questa esecuzione è mostrato nella Figura 2:
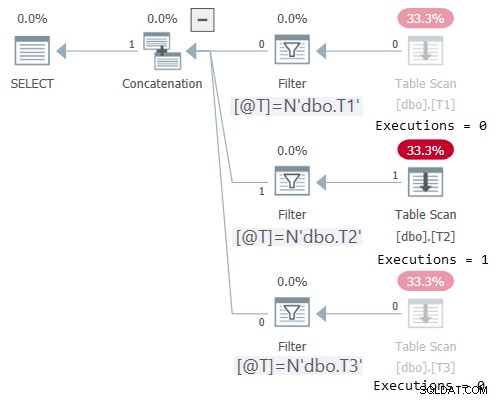 Figura 2:piano per dbo.OneTable con input non costante
Figura 2:piano per dbo.OneTable con input non costante
Plan Explorer rende straordinariamente ovvio vedere che solo il sottoalbero applicabile è stato eseguito (Esecuzioni =1) e disattiva i sottoalbero che non sono stati eseguiti (Esecuzioni =0). Inoltre, STATISTICS IO mostra le informazioni di I/O solo per la tabella a cui è stato effettuato l'accesso:
Tabella 'T2'. Conteggio scansioni 1, letture logiche 1, letture fisiche 0, letture del page server 0, letture read-ahead 0, letture read-ahead del server delle pagine 0, letture logiche lob 0, letture fisiche lob 0, letture del server delle pagine lob 0, letture lob- avanti legge 0, il server della pagina lob read-ahead legge 0.Applicazione della logica di eliminazione delle unità orizzontali alla sfida delle serie numeriche
Come accennato, è possibile applicare il concetto di eliminazione dell'unità orizzontale modificando una qualsiasi delle soluzioni precedenti che attualmente utilizzano la logica di eliminazione verticale. Userò la funzione dbo.GetNumsAlanCharlieItzikBatch come punto di partenza per il mio esempio.
Ricordiamo che Joe Obbish ha utilizzato l'eliminazione delle unità orizzontali per estrarre i relativi sottointervalli disgiunti della serie numerica. Useremo il concetto per separare orizzontalmente il calcolo meno costoso (rn) dove @low =1 dal calcolo più costoso (n) dove @low <> 1.
Già che ci siamo, possiamo sperimentare aggiungendo l'idea di Jeff Moden nella sua funzione fnTally, dove usa una riga sentinella con il valore 0 per i casi in cui l'intervallo inizia con @low =0.
Quindi abbiamo quattro unità orizzontali:
- Riga sentinella con 0 dove @low =0, con n =0
- Righe TOP (@high) dove @low =0, con cheap n =rownum e op =@high – rownum
- Righe TOP (@high) dove @low =1, con cheap n =rownum e op =@high + 1 – rownum
- TOP(@high – @low + 1) righe dove @low <> 0 AND @low <> 1, con più costoso n =@low – 1 + rownum e op =@high + 1 – rownum
Questa soluzione combina le idee di Alan, Charlie, Joe, Jeff e me stesso, quindi chiameremo la versione in modalità batch della funzione dbo.GetNumsAlanCharlieJoeJeffItzikBatch.
Innanzitutto, ricorda di assicurarti di avere ancora la tabella fittizia dbo.BatchMe presente per ottenere l'elaborazione batch nella nostra soluzione, oppure, in caso contrario, utilizza il codice seguente:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Ecco il codice con la definizione della funzione dbo.GetNumsAlanCharlieJoeJeffItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Importante:il concetto di eliminazione delle unità orizzontali è senza dubbio più complesso da implementare rispetto a quello verticale, quindi perché preoccuparsi? Perché rimuove la responsabilità di scegliere la colonna giusta dall'utente. L'utente deve solo preoccuparsi di interrogare una colonna chiamata n, invece di ricordarsi di usare rn quando l'intervallo inizia con 1, e n altrimenti.
Iniziamo testando la soluzione con input costanti 1 e 100.000.000, chiedendo di ordinare il risultato:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Il piano per questa esecuzione è mostrato nella Figura 3.
 Figura 3:piano per dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Figura 3:piano per dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Osservare che l'unica colonna restituita è basata sull'espressione ROW_NUMBER diretta, non manipolata (Espr1313). Osserva inoltre che non è necessario eseguire l'ordinamento nel piano.
Ho ottenuto le seguenti statistiche temporali per questa esecuzione:
Tempo CPU =7359 ms, tempo trascorso =7354 ms.Il runtime riflette adeguatamente il fatto che il piano utilizza la modalità batch, l'espressione ROW_NUMBER non manipolata e nessun ordinamento.
Quindi, verifica la funzione con l'intervallo costante da 0 a 99.999.999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Il piano per questa esecuzione è mostrato nella Figura 4.
 Figura 4:piano per dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Figura 4:piano per dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Il piano utilizza un operatore Merge Join (Concatenation) per unire la riga sentinella con il valore 0 e il resto. Anche se la seconda parte è efficiente come prima, la logica di unione richiede un tributo piuttosto elevato di circa il 26% sul tempo di esecuzione, risultando nelle seguenti statistiche temporali:
Tempo CPU =9265 ms, tempo trascorso =9298 ms.Testiamo la funzione con l'intervallo costante da 2 a 100.000.001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Il piano per questa esecuzione è mostrato nella Figura 5.
 Figura 5:piano per dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Figura 5:piano per dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Questa volta non esiste una logica di unione costosa poiché la parte della fila sentinella è irrilevante. Tuttavia, osserva che la colonna restituita è l'espressione manipolata @low – 1 + rownum, che dopo l'incorporamento/inlining dei parametri e la piegatura costante è diventata 1 + rownum.
Ecco le statistiche temporali che ho ottenuto per questa esecuzione:
Tempo CPU =9000 ms, tempo trascorso =9015 ms.Come previsto, non è così veloce come con un intervallo che inizia con 1, ma, cosa interessante, è più veloce di un intervallo che inizia con 0.
Rimozione della fila 0 sentinella
Dato che la tecnica con la riga sentinella con il valore 0 sembra essere più lenta dell'applicazione della manipolazione a rownum, ha senso semplicemente evitarla. Questo ci porta a una soluzione semplificata basata sull'eliminazione orizzontale che mescola le idee di Alan, Charlie, Joe e me stesso. Chiamerò la funzione con questa soluzione dbo.GetNumsAlanCharlieJoeItzikBatch. Ecco la definizione della funzione:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO Proviamolo con l'intervallo da 1 a 100M:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Il piano è lo stesso di quello mostrato in precedenza nella Figura 3, come previsto.
Di conseguenza, ho ottenuto le seguenti statistiche temporali:
Tempo CPU =7219 ms, tempo trascorso =7243 ms.Provalo con l'intervallo da 0 a 99.999.999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Questa volta ottieni lo stesso piano di quello mostrato in precedenza nella Figura 5, non nella Figura 4.
Ecco le statistiche temporali che ho ottenuto per questa esecuzione:
Tempo CPU =9313 ms, tempo trascorso =9334 ms.Provalo con l'intervallo da 2 a 100.000.001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Ancora una volta ottieni lo stesso piano di quello mostrato in precedenza nella Figura 5.
Ho le seguenti statistiche temporali per questa esecuzione:
Tempo CPU =9125 ms, tempo trascorso =9148 ms.Avvertenze quando si utilizzano input non costanti
Con le tecniche di eliminazione delle unità verticali e orizzontali, le cose funzionano idealmente fintanto che si passano le costanti come input. Tuttavia, è necessario essere consapevoli degli avvertimenti che possono comportare penalità sulle prestazioni quando si superano input non costanti. La tecnica di eliminazione verticale delle unità presenta meno problemi e i problemi che esistono sono più facili da affrontare, quindi iniziamo con essa.
Ricorda che in questo articolo abbiamo usato la funzione dbo.GetNumsAlanCharlieItzikBatch come nostro esempio che si basa sul concetto di eliminazione delle unità verticali. Eseguiamo una serie di test con input non costanti, come le variabili.
Come primo test, restituiremo rn e chiederemo i dati ordinati da rn:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Ricorda che rn rappresenta l'espressione ROW_NUMBER non manipolata, quindi il fatto che usiamo input non costanti in questo caso non ha un significato speciale. Non è necessario un ordinamento esplicito nel piano.
Ho ottenuto le seguenti statistiche temporali per questa esecuzione:
Tempo CPU =7390 ms, tempo trascorso =7386 ms.Questi numeri rappresentano il caso ideale.
Nel test successivo, ordina le righe dei risultati per n:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Il piano per questa esecuzione è mostrato nella Figura 6.
 Figura 6:piano per dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ordinamento per n
Figura 6:piano per dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ordinamento per n
Vedi il problema? Dopo l'inlining, @low è stato sostituito con @mylow, non con il valore in @mylow, che è 1. Di conseguenza, la piegatura costante non ha avuto luogo, e quindi n non è la conservazione dell'ordine rispetto a rownum. Ciò ha comportato un ordinamento esplicito nel piano.
Ecco le statistiche temporali che ho ottenuto per questa esecuzione:
Tempo CPU =25141 ms, tempo trascorso =25628 ms.Il tempo di esecuzione è quasi triplicato rispetto a quando non era necessario l'ordinamento esplicito.
Una semplice soluzione alternativa consiste nell'utilizzare l'idea originale di Alan Burstein di ordinare sempre per rn quando è necessario il risultato ordinato, sia quando si restituisce rn che quando si restituisce n, in questo modo:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Questa volta non c'è un ordinamento esplicito nel piano.
Ho le seguenti statistiche temporali per questa esecuzione:
Tempo CPU =9156 ms, tempo trascorso =9184 ms.I numeri riflettono adeguatamente il fatto che stai restituendo l'espressione manipolata, ma non incorre in alcun ordinamento esplicito.
Con soluzioni basate sulla tecnica di eliminazione delle unità orizzontali, come la nostra funzione dbo.GetNumsAlanCharlieJoeItzikBatch, la situazione è più complicata quando si utilizzano input non costanti.
Per prima cosa testiamo la funzione con un intervallo molto piccolo di 10 numeri:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Il piano per questa esecuzione è mostrato nella Figura 7.
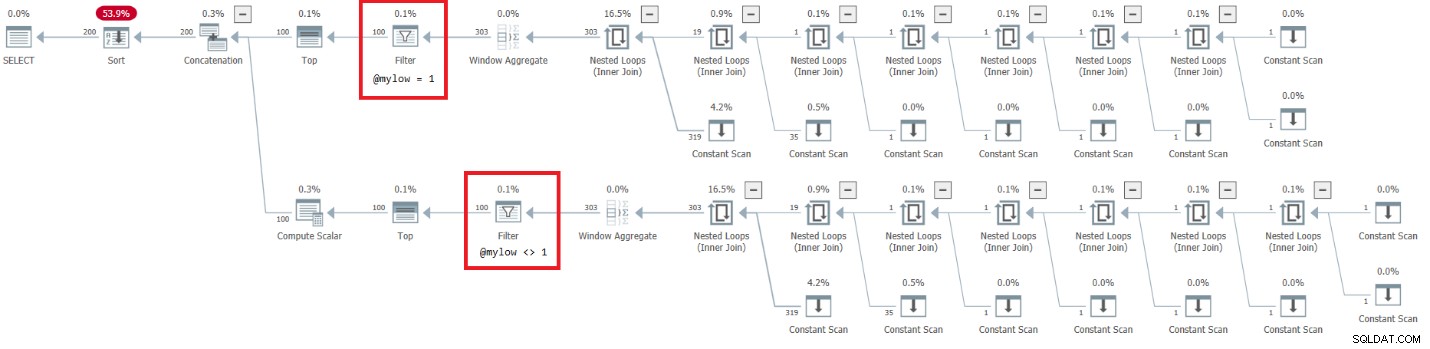 Figura 7:piano per dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figura 7:piano per dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
C'è un lato molto allarmante in questo piano. Osserva che gli operatori del filtro appaiono sotto i Top operatori! In ogni chiamata alla funzione con input non costanti, naturalmente uno dei rami sotto l'operatore di concatenazione avrà sempre una condizione di filtro falsa. Tuttavia, entrambi gli operatori Top richiedono un numero di righe diverso da zero. Quindi l'operatore Top sopra l'operatore con la condizione di filtro falso richiederà le righe e non sarà mai soddisfatto poiché l'operatore di filtro continuerà a scartare tutte le righe che otterrà dal suo nodo figlio. Il lavoro nel sottoalbero sotto l'operatore Filtro dovrà essere eseguito fino al completamento. Nel nostro caso questo significa che il sottoalbero eseguirà il lavoro di generazione di 4B righe, che l'operatore Filter scarterà. Ti chiedi perché l'operatore del filtro si preoccupi di richiedere righe dal suo nodo figlio, ma sembrerebbe che sia così che attualmente funziona. È difficile vederlo con un piano statico. È più facile vederlo dal vivo, ad esempio, con l'opzione di esecuzione di query in tempo reale in SentryOne Plan Explorer, come mostrato nella Figura 8. Provalo.
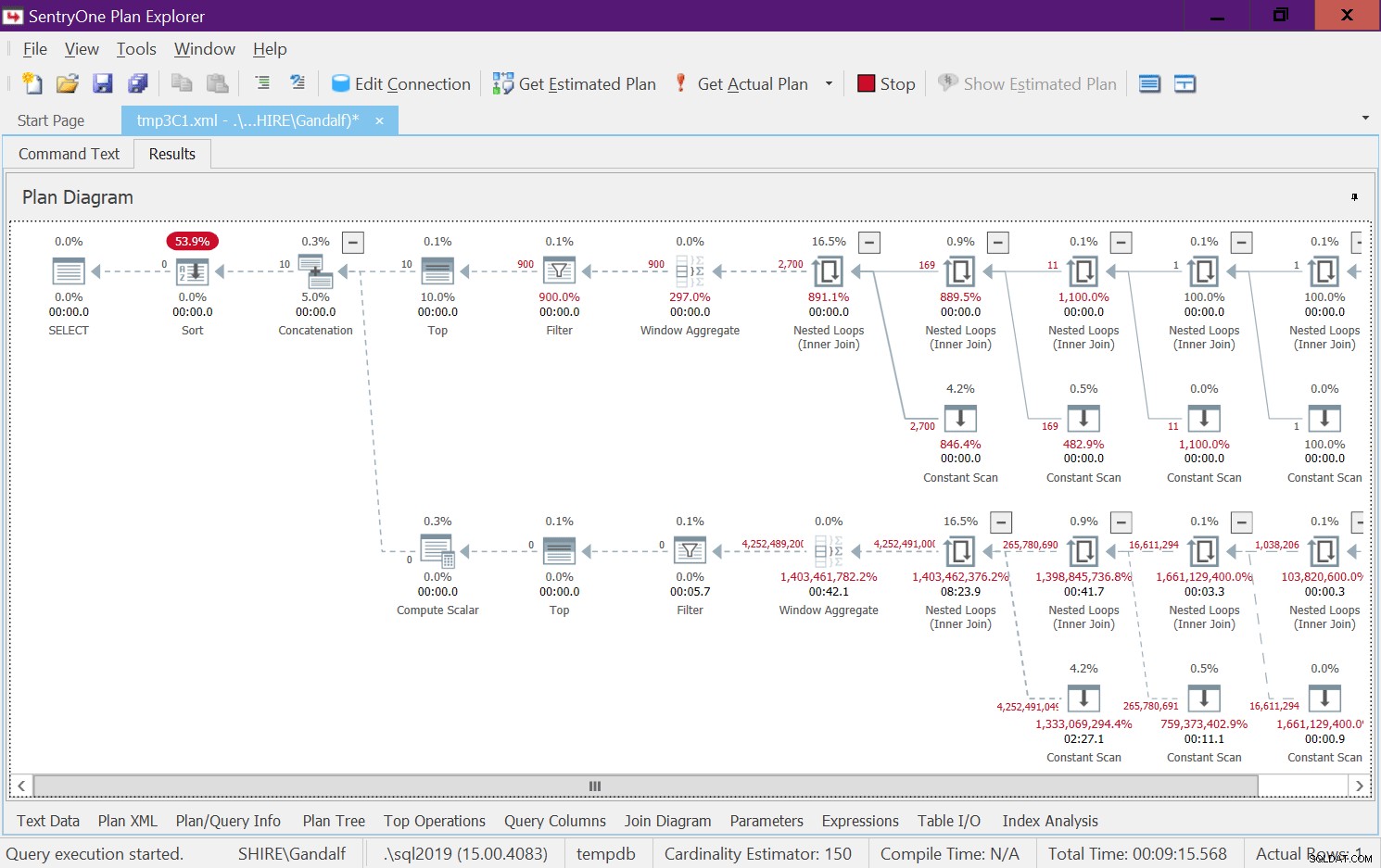 Figura 8:statistiche sulle query live per dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figura 8:statistiche sulle query live per dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Ci sono voluti 9:15 minuti per completare questo test sulla mia macchina e ricorda che la richiesta era di restituire un intervallo di 10 numeri.
Pensiamo se c'è un modo per evitare di attivare il sottoalbero irrilevante nella sua interezza. Per ottenere ciò, vorresti che gli operatori del filtro di avvio appaiano sopra gli operatori Top invece che sotto di loro. Se leggi Nozioni fondamentali sulle espressioni di tabella, Parte 4 – Tabelle derivate, considerazioni sull'ottimizzazione, continua, sai che un filtro TOP impedisce il disannidamento delle espressioni di tabella. Quindi, tutto ciò che devi fare è inserire la query TOP in una tabella derivata e applicare il filtro in una query esterna rispetto alla tabella derivata.
Ecco la nostra funzione modificata che implementa questo trucco:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO Come previsto, le esecuzioni con costanti continuano a comportarsi e a funzionare come senza il trucco.
Per quanto riguarda gli input non costanti, ora con intervalli ridotti è molto veloce. Ecco un test con un intervallo di 10 numeri:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Il piano per questa esecuzione è mostrato nella Figura 9.
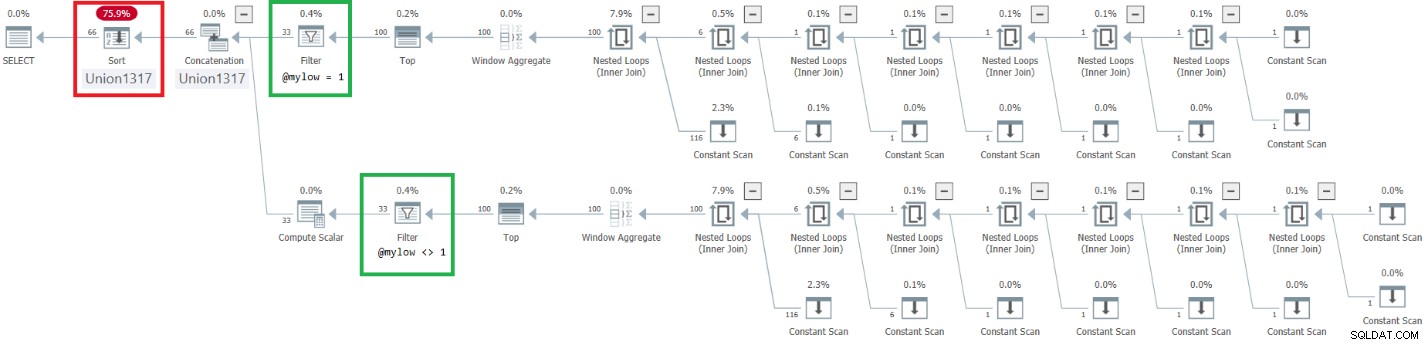 Figura 9:piano per migliorare dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figura 9:piano per migliorare dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Osservare che è stato ottenuto l'effetto desiderato di posizionare gli operatori Filtro sopra gli operatori Top. Tuttavia, la colonna di ordinamento n viene trattata come un risultato di manipolazione e pertanto non è considerata una colonna di conservazione dell'ordine rispetto a rownum. Di conseguenza, c'è un ordinamento esplicito nel piano.
Testare la funzione con un'ampia gamma di 100 milioni di numeri:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Ho le seguenti statistiche temporali:
Tempo CPU =29907 ms, tempo trascorso =29909 ms.Che peccato; era quasi perfetto!
Riepilogo delle prestazioni e approfondimenti
La Figura 10 ha un riepilogo delle statistiche temporali per le diverse soluzioni.
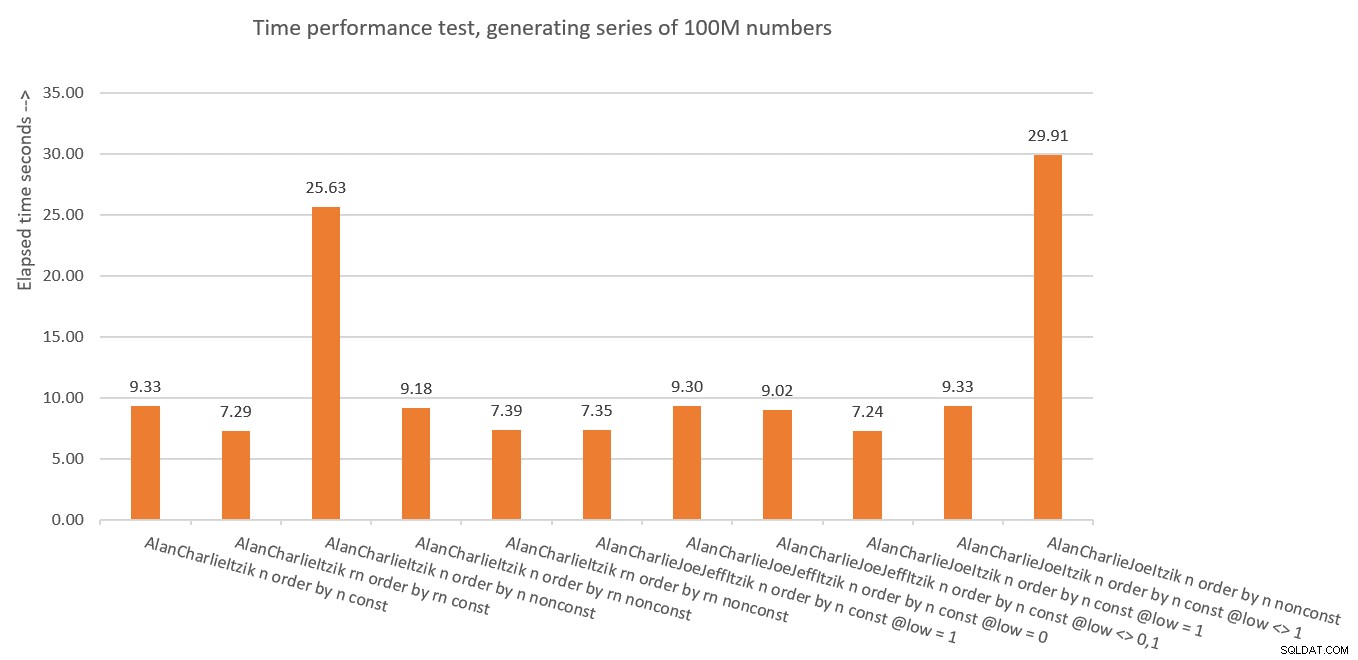 Figura 10:riepilogo delle prestazioni in termini di tempo
Figura 10:riepilogo delle prestazioni in termini di tempo
Allora, cosa abbiamo imparato da tutto questo? Immagino di non farlo più! Stavo solo scherzando. Abbiamo appreso che è più sicuro utilizzare il concetto di eliminazione verticale come in dbo.GetNumsAlanCharlieItzikBatch, che espone sia il risultato ROW_NUMBER non manipolato (rn) che quello manipolato (n). Assicurati solo che quando devi restituire il risultato ordinato, ordina sempre per rn, sia che restituisca rn o n.
Se sei assolutamente certo che la tua soluzione verrà sempre utilizzata con costanti come input, puoi utilizzare il concetto di eliminazione dell'unità orizzontale. Ciò si tradurrà in una soluzione più intuitiva per l'utente, poiché interagirà con una colonna per i valori crescenti. Suggerirei comunque di utilizzare il trucco con le tabelle derivate per evitare il disannidamento e posizionare gli operatori Filtro sopra gli operatori Top se la funzione viene mai utilizzata con input non costanti, solo per sicurezza.
Non abbiamo ancora finito. Il mese prossimo continuerò a esplorare soluzioni aggiuntive.