Questa è la seconda parte di una serie in cinque parti che approfondisce il modo in cui vengono avviati i piani paralleli in modalità riga di SQL Server. Alla fine della prima parte, avevamo creato contesto di esecuzione zero per il compito genitore. Questo contesto contiene l'intero albero degli operatori eseguibili, ma non sono ancora pronti per il modello di esecuzione iterativo del motore di elaborazione delle query.
Esecuzione iterativa
SQL Server esegue una query tramite un processo noto come analisi delle query . L'inizializzazione del piano inizia alla radice da parte del Query Processor che chiama Open sul nodo radice. Open le chiamate attraversano l'albero degli iteratori chiamando ricorsivamente Open su ogni bambino fino all'apertura dell'intero albero.
Anche il processo di restituzione delle righe dei risultati è ricorsivo, attivato dal Query Processor che chiama GetRow alla radice. Ogni chiamata radice restituisce una riga alla volta. Il Query Processor continua a chiamare GetRow sul nodo radice fino a quando non sono disponibili più righe. L'esecuzione si interrompe con un Close ricorsivo finale chiamata. Questa disposizione consente al Query Processor di inizializzare, eseguire e chiudere qualsiasi piano arbitrario chiamando gli stessi metodi di interfaccia solo alla radice.
Per trasformare l'albero degli operatori eseguibili in uno adatto all'elaborazione riga per riga, SQL Server aggiunge una scansione delle query wrapper a ciascun operatore. La scansione delle query l'oggetto fornisce l'Open , GetRow e Close metodi necessari per l'esecuzione iterativa.
L'oggetto di scansione della query mantiene anche le informazioni sullo stato ed espone altri metodi specifici dell'operatore necessari durante l'esecuzione. Ad esempio, l'oggetto di scansione della query per un operatore di filtro di avvio (CQScanStartupFilterNew ) espone i seguenti metodi:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
I metodi aggiuntivi per questo iteratore sono utilizzati principalmente nei piani del cursore.
Inizializzazione della scansione delle query
Il processo di wrapping è chiamato inizializzazione della scansione della query . Viene eseguito da una chiamata dal Query Processor a CQueryScan::InitQScanRoot . L'attività principale esegue questo processo per l'intero piano (contenuto nel contesto di esecuzione zero). Il processo di traduzione è esso stesso di natura ricorsiva, partendo dalla radice e proseguendo lungo l'albero.
Durante questo processo, ogni operatore è responsabile dell'inizializzazione dei propri dati e della creazione di eventuali risorse di runtime ha bisogno. Ciò può includere la creazione di oggetti aggiuntivi al di fuori del Query Processor, ad esempio le strutture necessarie per comunicare con il motore di archiviazione per recuperare i dati dalla memoria permanente.
Un promemoria del piano di esecuzione, con l'aggiunta di numeri di nodo (clicca per ingrandire):
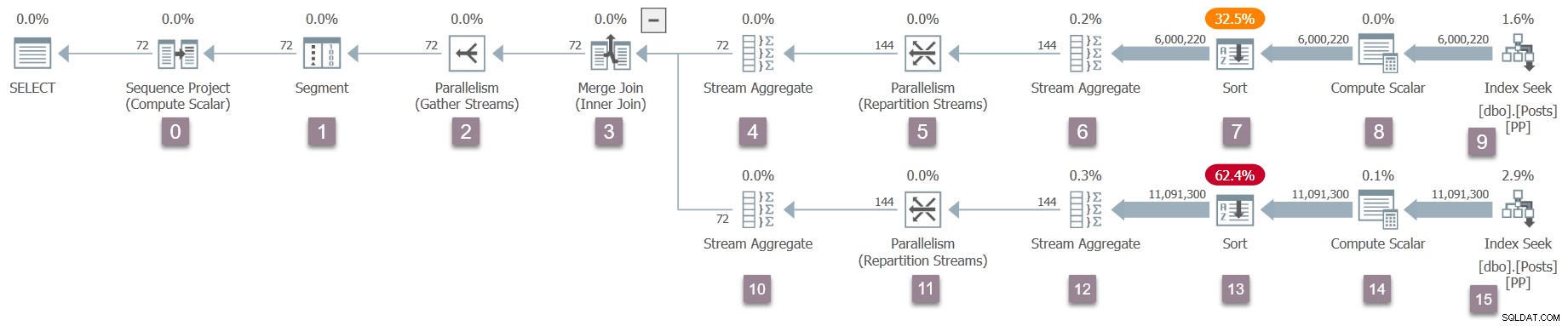
L'operatore alla radice (nodo 0) dell'albero del piano eseguibile è un progetto di sequenza . È rappresentato da una classe denominata CXteSeqProject . Come al solito, è qui che inizia la trasformazione ricorsiva.
Query wrapper di scansione
Come accennato, il CXteSeqProject l'oggetto non è attrezzato per prendere parte alla scansione delle query iterativa process — non ha il Open richiesto , GetRow e Close metodi. Il Query Processor ha bisogno di un wrapper attorno all'operatore eseguibile per fornire quell'interfaccia.
Per ottenere quel wrapper di scansione della query, l'attività padre chiama CXteSeqProject::QScanGet per restituire un oggetto di tipo CQScanSeqProjectNew . La mappa collegata degli operatori creati in precedenza viene aggiornato per fare riferimento al nuovo oggetto di scansione della query e i suoi metodi iteratori sono collegati alla radice del piano.
Il figlio del progetto sequenza è un segmento operatore (nodo 1). Chiamando CXteSegment::QScanGet restituisce un oggetto wrapper di scansione query di tipo CQScanSegmentNew . La mappa collegata viene nuovamente aggiornata e i puntatori della funzione iteratore sono collegati alla scansione della query del progetto della sequenza padre.
Mezzo scambio
L'operatore successivo è un scambio di raccolta di flussi (nodo 2). Chiamando CXteExchange::QScanGet restituisce un CQScanExchangeNew come potresti aspettarti ormai.
Questo è il primo operatore nell'albero che deve eseguire un'inizializzazione aggiuntiva significativa. Crea il lato dei consumatori dello scambio tramite CXTransport::CreateConsumerPart . Questo crea la porta (CXPort ) — una struttura dati nella memoria condivisa utilizzata per la sincronizzazione e lo scambio di dati — e una pipe (CXPipe ) per il trasporto di pacchetti. Tieni presente che il produttore lato dello scambio non è stato creato in questo momento. Abbiamo solo mezzo scambio!
Più avvolgimento
Il processo di configurazione della scansione di Query Processor continua con il unione di join (nodo 3). Non ripeterò sempre il QScanGet e CQScan* le chiamate da questo momento in poi, ma seguono lo schema stabilito.
L'unione di unione ha due figli. L'impostazione della scansione della query continua come prima con l'input esterno (in alto), un aggregato di flusso (nodo 4), quindi una ripartizione esegue lo streaming di scambio (nodo 5). I flussi di ripartizione creano ancora una volta solo il lato consumer dello scambio, ma questa volta ci sono due pipe create perché DOP è due. Il lato consumatore di questo tipo di scambio ha connessioni DOP al suo operatore padre (uno per thread).
Poi abbiamo un altro aggregato di stream (nodo 6) e un ordinamento (nodo 7). L'ordinamento ha un figlio non visibile nei piani di esecuzione:un set di righe del motore di archiviazione utilizzato per implementare lo spilling su tempdb . Il CQScanSortNew previsto è quindi accompagnato da un bambino CQScanRowsetNew nell'albero interno. Non è visibile nell'output dello showplan.
Profilazione I/O e operazioni differite
Il ordinamento operator è anche il primo che abbiamo inizializzato finora e che potrebbe essere responsabile dell'I/O . Supponendo che l'esecuzione abbia richiesto dati di profilazione I/O (ad esempio richiedendo un piano "reale"), l'ordinamento crea un oggetto per registrare questi dati di profilazione di runtime tramite CProfileInfo::AllocProfileIO .
L'operatore successivo è un calcolo scalare (nodo 8), chiamato progetto internamente. La chiamata di configurazione della scansione della query a CXteProject::QScanGet non restituisce un oggetto di scansione della query, perché i calcoli eseguiti da questo calcolo scalare sono differiti al primo operatore genitore che necessita del risultato. In questo piano, quell'operatore è il tipo. L'ordinamento eseguirà tutto il lavoro assegnato al calcolo scalare, quindi il progetto sul nodo 8 non fa parte dell'albero di scansione della query. Il calcolo scalare in realtà non viene eseguito in fase di esecuzione. Per maggiori dettagli sugli scalari di calcolo posticipati, consulta Scalari di calcolo, espressioni e prestazioni del piano di esecuzione.
Scansione parallela
L'operatore finale dopo il calcolo scalare su questo ramo del piano è un ricerca dell'indice (CXteRange ) al nodo 9. Questo produce l'operatore di scansione della query previsto (CQScanRangeNew ), ma richiede anche una complessa sequenza di inizializzazioni per connettersi al motore di archiviazione e facilitare una scansione parallela dell'indice.
Coprendo solo i punti salienti, inizializzando la ricerca dell'indice:
- Crea un oggetto di profilatura per I/O (
CProfileInfo::AllocProfileIO). - Crea un insieme di righe parallelo scansione della query (
CQScanRowsetNew::ParallelGetRowset). - Imposta una sincronizzazione oggetto per coordinare la scansione dell'intervallo parallelo di runtime (
CQScanRangeNew::GetSyncInfo). - Crea il motore di archiviazione cursore tabella e un descrittore di transazione di sola lettura .
- Apre il set di righe padre per la lettura (accedendo a HoBt e prendendo i latch necessari).
- Imposta il timeout di blocco.
- Imposta il precaricamento (compresi i buffer di memoria associati).
Aggiunta di operatori di profilatura in modalità riga
Abbiamo ora raggiunto il livello foglia di questo ramo del piano (l'indice di ricerca non ha figli). Dopo aver appena creato l'oggetto di scansione della query per la ricerca dell'indice, il passaggio successivo consiste nel avvolgere la scansione della query con una classe di profilazione (supponendo che abbiamo richiesto un piano effettivo). Questo viene fatto tramite una chiamata a sqlmin!PqsWrapQScan . Nota che i profiler vengono aggiunti dopo che la scansione della query è stata creata, mentre iniziamo a risalire l'albero dell'iteratore.
PqsWrapQScan crea un nuovo operatore di profilazione come genitore della ricerca dell'indice, tramite una chiamata a CProfileInfo::GetOrCreateProfileInfo . L'operatore di profilazione (CQScanProfileNew ) ha i consueti metodi dell'interfaccia di scansione delle query. Oltre a raccogliere i dati necessari per i piani effettivi, i dati di profilazione vengono anche esposti tramite il sys.dm_exec_query_profiles DMV .
Interrogare quel DMV in questo preciso momento per la sessione corrente mostra che esiste un solo operatore di piano (nodo 9) (il che significa che è l'unico avvolto da un profiler):

Questa schermata mostra il set di risultati completo del DMV al momento attuale (non è stato modificato).
Avanti, CQScanProfileNew chiama l'API del contatore delle prestazioni della query (KERNEL32!QueryPerformanceCounterStub ) fornito dal sistema operativo per registrare il primo e ultimo orario attivo dell'operatore profilato:

L'ultimo orario attivo verrà aggiornato utilizzando l'API del contatore delle prestazioni della query ogni volta che viene eseguito il codice per quell'iteratore.
Il profiler imposta quindi il numero stimato di righe a questo punto del piano (CProfileInfo::SetCardExpectedRows ), tenendo conto di qualsiasi obiettivo di riga (CXte::CardGetRowGoal ). Poiché si tratta di un piano parallelo, divide il risultato per il numero di thread (CXte::FGetRowGoalDefinedForOneThread ) e salva il risultato nel contesto di esecuzione.
Il numero stimato di righe non è visibile tramite il DMV a questo punto, perché l'attività padre non eseguirà questo operatore. Al contrario, la stima per thread verrà esposta successivamente in contesti di esecuzione parallela (che non sono stati ancora creati). Tuttavia, il numero per thread viene salvato nel profiler dell'attività principale, ma non è visibile tramite DMV.
Il nome descrittivo dell'operatore del piano ("Ricerca indice") viene quindi impostato tramite una chiamata a CXteRange::GetPhysicalOp :

Prima di ciò, potresti aver notato che interrogando il DMV mostrava il nome come "???". Questo è il nome permanente mostrato per gli operatori invisibili (ad es. prelettura di cicli nidificati, ordinamento batch) che non hanno un nome descrittivo definito.
Infine, indicizza i metadati e le attuali statistiche I/O per la ricerca dell'indice avvolto vengono aggiunti tramite una chiamata a CQScanRowsetNew::GetIoCounters :

I contatori sono zero al momento, ma verranno aggiornati man mano che la ricerca dell'indice esegue l'I/O durante l'esecuzione del piano finita.
Più elaborazione della scansione delle query
Con l'operatore di profilatura creato per la ricerca dell'indice, l'elaborazione della scansione della query torna indietro nell'albero al ordinamento padre (nodo 7).
L'ordinamento esegue le seguenti attività di inizializzazione:
- Registra l'utilizzo della memoria con la query gestore memoria (
CQryMemManager::RegisterMemUsage) - Calcola la memoria richiesta per l'input di ordinamento (
CQScanIndexSortNew::CbufInputMemory) e output (CQScanSortNew::CbufOutputMemory). - La tabella di ordinamento viene creato, insieme al set di righe del motore di archiviazione associato (
sqlmin!RowsetSorted). - Una transazione di sistema autonoma (non delimitato dalla transazione utente) viene creato per ordinare le allocazioni del disco di spill, insieme a una tabella di lavoro falsa (
sqlmin!CreateFakeWorkTable). - Il servizio di espressione è inizializzato (
sqlTsEs!CEsRuntime::Startup) affinché l'operatore di ordinamento esegua i calcoli differiti dal calcolo scalare. - Precarica per qualsiasi tipo di esecuzione riversata su tempdb viene quindi creato tramite (
CPrefetchMgr::SetupPrefetch).
Infine, la scansione della query di ordinamento è racchiusa da un operatore di profilazione (incluso I/O) proprio come abbiamo visto per la ricerca dell'indice:

Nota che il calcolo scalare (nodo 8) è mancante dal DMV. Questo perché il suo lavoro è rinviato all'ordinamento, non fa parte dell'albero di scansione della query e quindi non ha alcun oggetto del profiler di wrapping.
Passando al genitore dell'ordinamento, l'aggregato stream l'operatore di scansione della query (nodo 6) inizializza le sue espressioni e i contatori di runtime (ad esempio il conteggio delle righe del gruppo corrente). L'aggregato del flusso viene avvolto con un operatore di profilazione, registrandone i tempi iniziali:

I flussi di ripartizione padre exchange (nodo 5) è avvolto da un profiler (ricorda che a questo punto esiste solo il lato consumer di questo scambio):

Lo stesso vale per il suo aggregato di flussi padre (nodo 4), anch'esso inizializzato come descritto in precedenza:

L'elaborazione della scansione della query ritorna al unione di join padre (nodo 3) ma non lo inizializza ancora. Invece, ci spostiamo lungo il lato interno (inferiore) del join di unione, eseguendo le stesse attività dettagliate per quegli operatori (nodi da 10 a 15) come fatto per il ramo superiore (esterno):
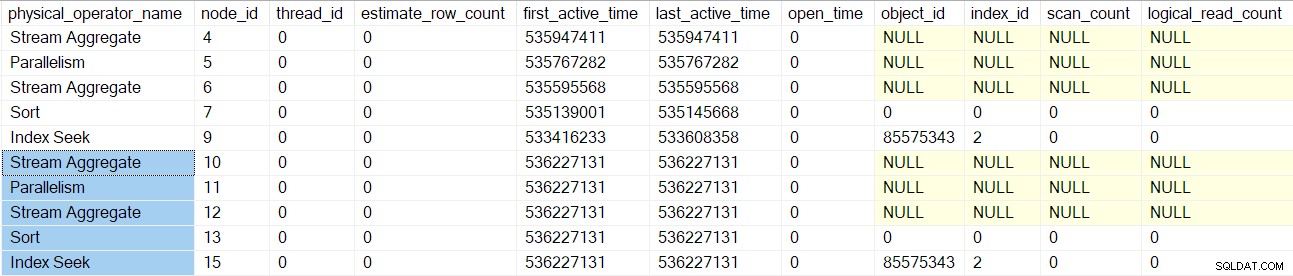
Una volta elaborati questi operatori, il unione unisce la scansione della query viene creata, inizializzata e racchiusa in un oggetto di profilatura. Ciò include i contatori di I/O perché un join di unione molti-molti utilizza una tabella di lavoro (anche se l'unione di unione corrente è uno-molti):
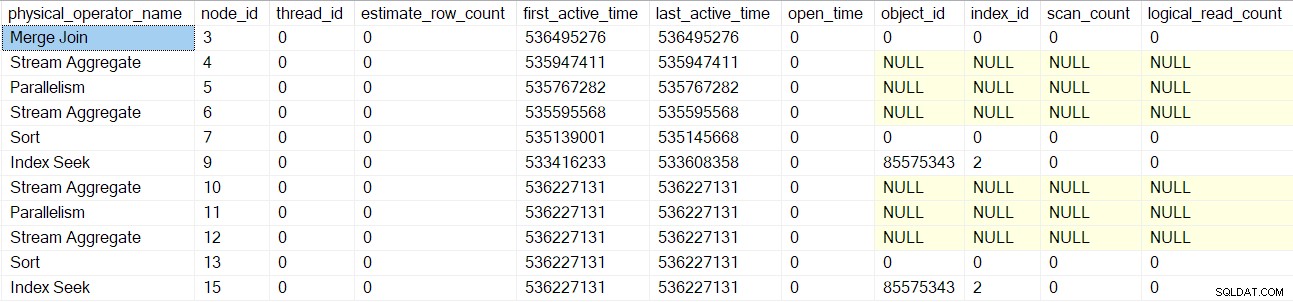
Lo stesso processo viene seguito per gli stream di raccolta padre exchange (nodo 2) solo lato consumatore, segmento (nodo 1) e progetto sequenza (nodo 0) operatori. Non li descriverò in dettaglio.
Il DMV dei profili di query ora segnala un set completo di nodi di scansione di query avvolti dal profiler:
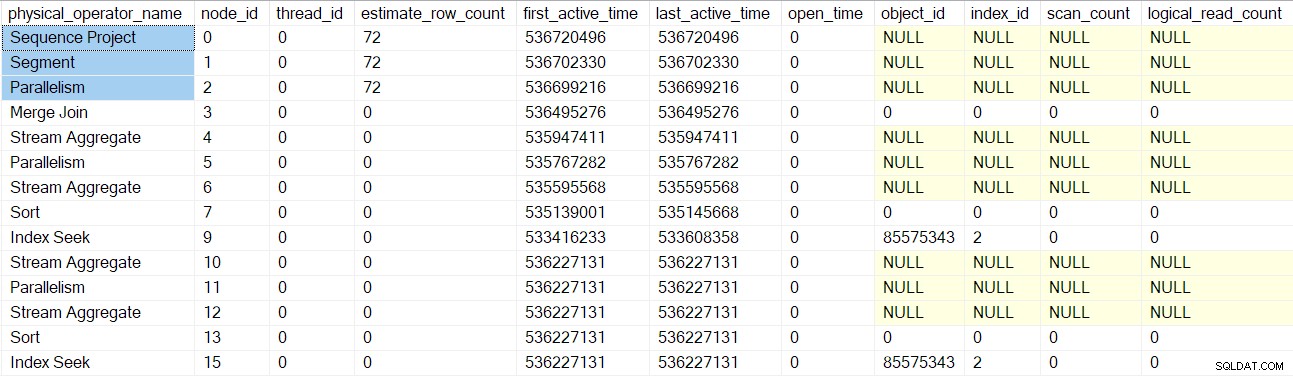
Si noti che il consumer di flussi di progetto, segmentazione e raccolta di sequenza ha un conteggio di righe stimato perché questi operatori verranno eseguiti dall'attività principale , non da attività parallele aggiuntive (vedi CXte::FGetRowGoalDefinedForOneThread prima). L'attività padre non ha lavoro da svolgere nei rami paralleli, quindi il concetto di conteggio delle righe stimato ha senso solo per attività aggiuntive.
I valori di tempo attivi mostrati sopra sono alquanto distorti perché avevo bisogno di interrompere l'esecuzione e acquisire schermate DMV ad ogni passaggio. Un'esecuzione separata (senza i ritardi artificiali introdotti utilizzando un debugger) ha prodotto i seguenti tempi:
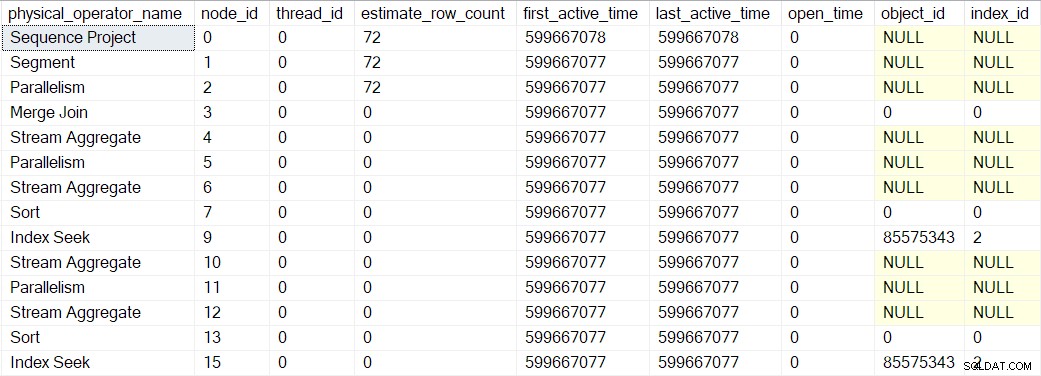
L'albero è costruito nella stessa sequenza descritta in precedenza, ma il processo è così rapido che dura solo 1 microsecondo differenza tra il tempo attivo del primo operatore avvolto (la ricerca dell'indice al nodo 9) e l'ultimo (progetto sequenza al nodo 0).
Fine della parte 2
Potrebbe sembrare che abbiamo fatto molto lavoro, ma ricorda che abbiamo creato solo un albero di scansione delle query per l'attività principale , e gli scambi hanno solo un lato consumatore (ancora nessun produttore). Anche il nostro piano parallelo ha un solo thread (come mostrato nell'ultimo screenshot). La parte 3 vedrà la creazione delle nostre prime attività parallele aggiuntive.