Nel mio ultimo post, ho dimostrato che a piccoli volumi, un TVP ottimizzato per la memoria può offrire sostanziali vantaggi in termini di prestazioni ai tipici modelli di query.
Per testare su una scala leggermente superiore, ho fatto una copia di SalesOrderDetailEnlarged tabella, che avevo ampliato a circa 5.000.000 di righe grazie a questo script di Jonathan Kehayias (blog | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Ho anche creato tre versioni in memoria di questa tabella, ciascuna con un numero di bucket diverso (ricerca di un "punto debole"):16.384, 131.072 e 1.048.576. (Puoi usare numeri più arrotondati, ma vengono comunque arrotondati alla potenza successiva di 2.) Esempio:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Si noti che ho cambiato la dimensione del secchio dall'esempio precedente (256). Quando si crea la tabella, si desidera selezionare il "punto ottimale" per la dimensione del bucket:si desidera ottimizzare l'indice hash per le ricerche di punti, il che significa che si desidera il maggior numero possibile di bucket con il minor numero possibile di righe in ogni bucket. Ovviamente se crei circa 5 milioni di bucket (poiché in questo caso, forse non è un ottimo esempio, ci sono circa 5 milioni di combinazioni univoche di valori), avrai a che fare con alcuni compromessi sull'utilizzo della memoria e sulla raccolta dei rifiuti. Tuttavia, se provi a inserire ~5 milioni di valori univoci in 256 bucket, riscontrerai anche alcuni problemi. In ogni caso, questa discussione va ben oltre lo scopo dei miei test per questo post.
Per testare la tabella standard, ho creato stored procedure simili a quelle dei test precedenti:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Quindi, per prima cosa, per esaminare i piani per, diciamo, 1.000 righe che vengono inserite nelle variabili della tabella e quindi eseguire le procedure:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Questa volta, vediamo che in entrambi i casi, l'ottimizzatore ha scelto una ricerca di indice cluster rispetto alla tabella di base e un join di loop nidificato rispetto al TVP. Alcune metriche di costo sono diverse, ma per il resto i piani sono abbastanza simili:
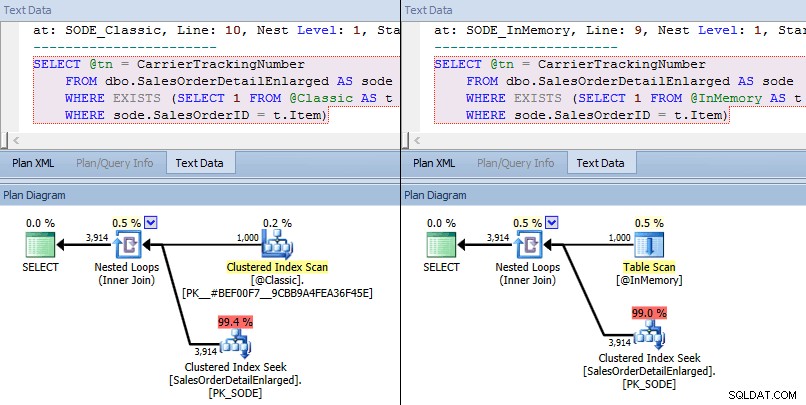 Piani simili per TVP in memoria e TVP classico su scala superiore
Piani simili per TVP in memoria e TVP classico su scala superiore
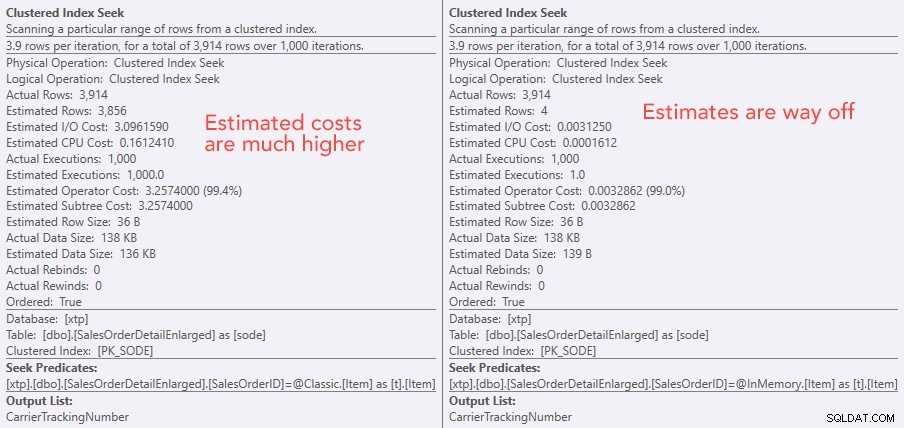 Confronto dei costi dell'operatore di ricerca – Classico a sinistra, In-Memory a destra
Confronto dei costi dell'operatore di ricerca – Classico a sinistra, In-Memory a destra
Il valore assoluto dei costi fa sembrare che il TVP classico sarebbe molto meno efficiente del TVP In-Memory. Ma mi chiedevo se questo sarebbe stato vero nella pratica (soprattutto perché la cifra del numero stimato di esecuzioni a destra sembrava sospetta), quindi ovviamente ho eseguito alcuni test. Ho deciso di controllare 100, 1.000 e 2.000 valori da inviare alla procedura.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
I risultati delle prestazioni mostrano che, a un numero maggiore di ricerche di punti, l'utilizzo di un TVP in memoria porta a rendimenti leggermente decrescenti, essendo ogni volta leggermente più lenti:
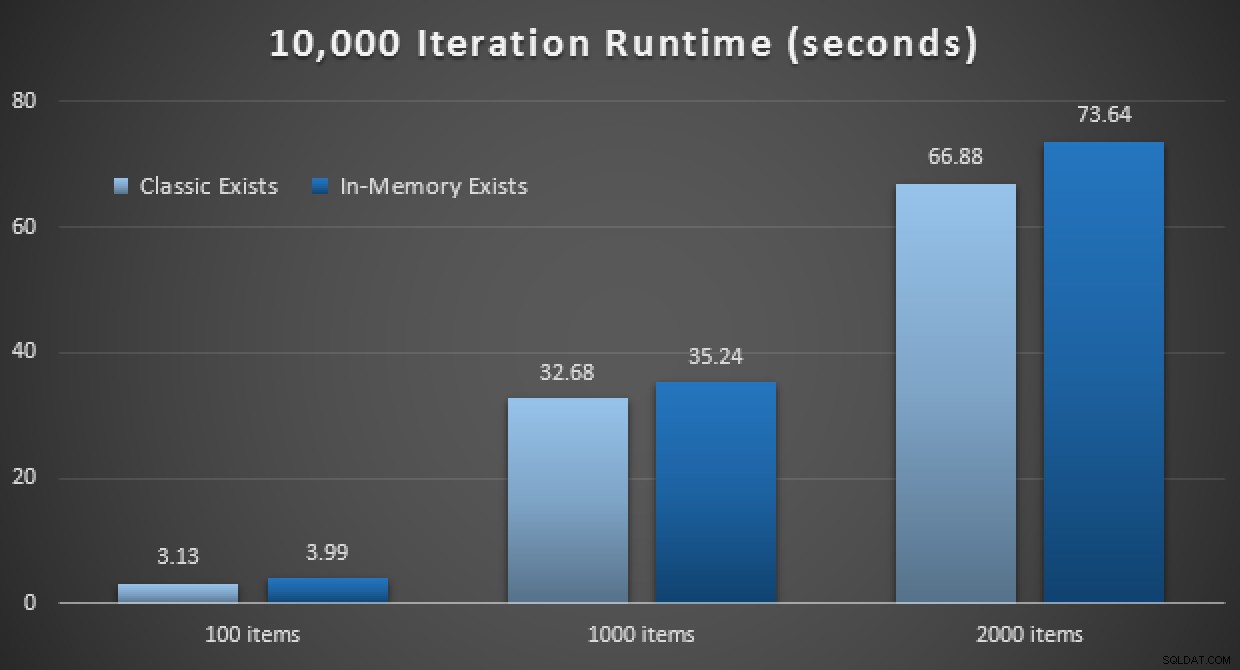
Risultati di 10.000 esecuzioni utilizzando TVP classici e in memoria
Quindi, contrariamente all'impressione che potresti aver preso dal mio post precedente, l'utilizzo di un TVP in memoria non è necessariamente vantaggioso in tutti i casi.
In precedenza ho anche esaminato le procedure memorizzate compilate in modo nativo e le tabelle in memoria, in combinazione con i TVP in memoria. Questo potrebbe fare la differenza qui? Spoiler:assolutamente no. Ho creato tre procedure come questa:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Un altro spoiler:non sono stato in grado di eseguire questi 9 test con un conteggio di iterazioni di 10.000 – ci è voluto troppo tempo. Invece ho eseguito il ciclo ed eseguito ciascuna procedura 10 volte, eseguito quella serie di test 10 volte e ho preso la media. Ecco i risultati:
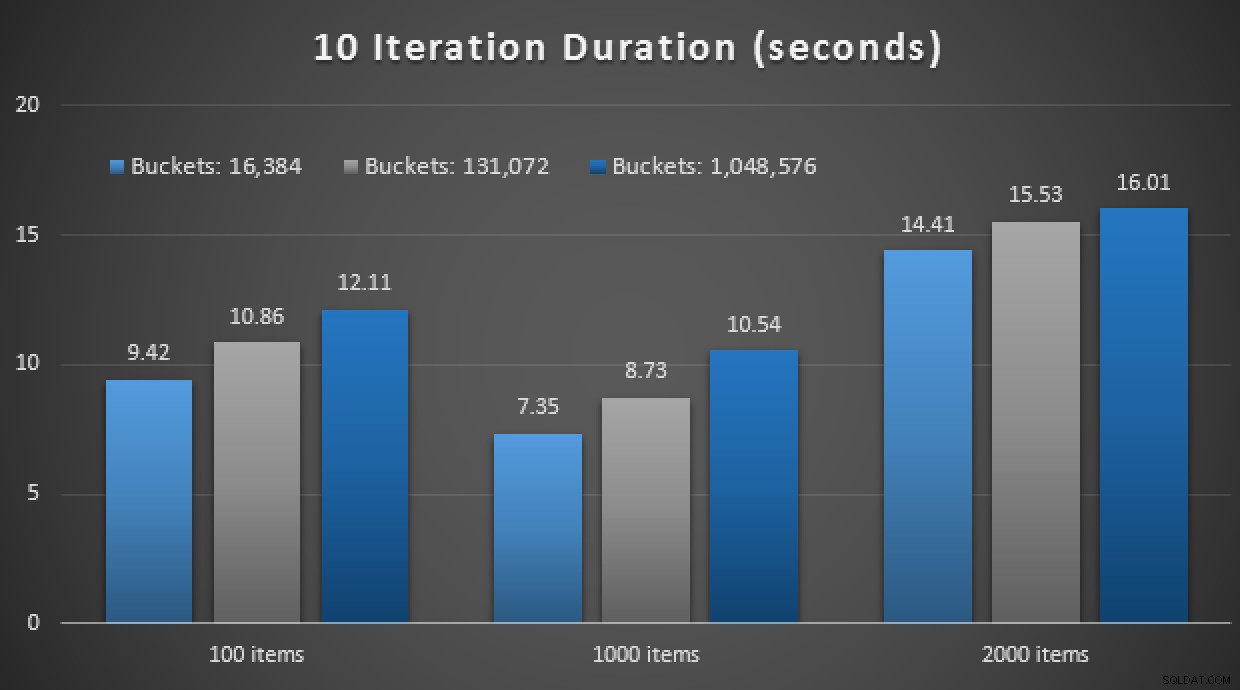
Risultati di 10 esecuzioni utilizzando TVP in memoria e archiviati in modo nativo procedure
Nel complesso, questo esperimento è stato piuttosto deludente. Osservando solo l'entità della differenza, con una tabella su disco, la chiamata media alla stored procedure è stata completata in una media di 0,0036 secondi. Tuttavia, quando tutto utilizzava tecnologie in memoria, la chiamata media alla stored procedure era di 1,1662 secondi. Ahi . È molto probabile che io abbia appena scelto un caso d'uso scadente per la demo in generale, ma all'epoca sembrava essere un "primo tentativo" intuitivo.
Conclusione
C'è molto altro da testare in questo scenario e ho più post sul blog da seguire. Non ho ancora identificato il caso d'uso ottimale per i TVP in memoria su scala più ampia, ma spero che questo post serva a ricordare che, anche se una soluzione sembra ottimale in un caso, non è mai sicuro presumere che sia ugualmente applicabile a diversi scenari. Questo è esattamente il modo in cui dovrebbe essere affrontato In-Memory OLTP:come una soluzione con un insieme ristretto di casi d'uso che devono assolutamente essere convalidati prima dell'implementazione in produzione.