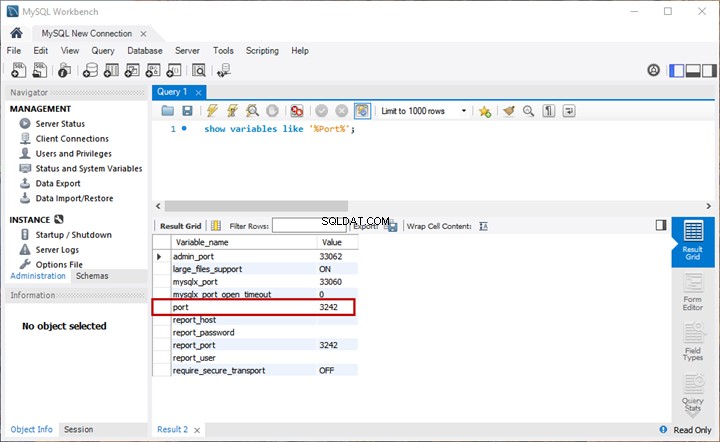
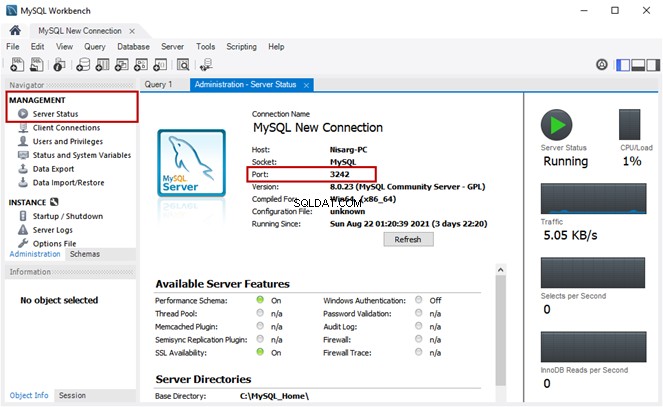
Questa è la seconda parte del materiale dedicato a Ricerca semantica di SQL Server . Nell'articolo precedente, abbiamo esplorato le basi. Ora ci concentreremo sul confronto dei documenti archiviati nel file system di Windows e sull'analisi comparativa con la ricerca semantica in SQL Server.
Esecuzione dell'analisi comparativa di documenti basati sul nome
Effettueremo un'analisi comparativa dei documenti in base alla loro denominazione standard. A questo punto, facciamo un rapido controllo interrogando EmployeesFilestreamSample database che abbiamo creato in precedenza:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
I risultati devono mostrarci i documenti archiviati:
Elenco di controllo per la ricerca semantica
Abbiamo già il database e due esempi di documenti MS Word su File System utilizzando File Table (potresti fare riferimento alla Parte 1 per aggiornare le conoscenze se necessario). Tuttavia, ciò non qualificano automaticamente i nostri documenti per lo scenario di ricerca semantica.
La ricerca semantica può essere abilitata in uno dei seguenti modi:
- Se hai già impostato la Ricerca full-text , puoi abilitare la ricerca semantica in un solo passaggio.
- Puoi impostare direttamente la ricerca semantica, ma prima devi anche impostare la ricerca full-text.
Test di ricerca full-text prima dell'impostazione della ricerca semantica
Se una query full-text funziona, dobbiamo solo abilitare la ricerca semantica. Per verificarlo, esegui una query full-text sulla tabella desiderata:
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
L'uscita:
Pertanto, dobbiamo prima soddisfare i requisiti di ricerca full-text e quindi abilitare la ricerca semantica.
Abilitazione della ricerca semantica per l'uso
Per utilizzare la ricerca semantica sono necessari almeno due dei seguenti punti:
- Indice unico
- Un catalogo full-text
- Un indice full-text
Esegui il seguente script T-SQL per creare un indice univoco:
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
Crea un catalogo full-text basato sull'indice univoco appena creato. Quindi, crea un indice di testo completo come mostrato di seguito:
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
I risultati:
Test di ricerca full-text dopo l'impostazione della ricerca semantica
Eseguiamo la stessa query full-text per cercare la parola Dipendente nei documenti archiviati:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
L'uscita:
Va bene che le query full-text funzionino sulla tabella dei file mentre la stiamo preparando per la ricerca semantica.
Aggiungi altri documenti MS Word
Andiamo a EmployeesDocumentStore Tabella file e fai clic su Esplora directory FileTable :
Crea e archivia un nuovo documento chiamato Impiegato a contratto Sadaf :
Quindi, aggiungi il testo seguente al documento appena creato. La prima riga deve essere il titolo del documento!
Impiegato a contratto Sadaf (titolo)
Sadaf è un analista aziendale molto efficiente che svolge un lavoro basato sui contatti. È pienamente in grado di gestire i requisiti aziendali e di trasformarli in specifiche tecniche su cui gli sviluppatori possono lavorare. È un'analista aziendale di grande esperienza.
Aggiungi un altro documento chiamato Mike Permanent Employee :
Aggiorna il documento con il seguente testo:
Mike Permanent Employee (Titolo del documento)
Mike è un nuovo programmatore la cui esperienza include lo sviluppo web. È uno studente veloce e felice di lavorare su qualsiasi progetto. Ha forti capacità di problem solving ma ha meno conoscenze di business. Ha bisogno dell'assistenza di altri sviluppatori o analisti aziendali per comprendere il problema e soddisfare i requisiti.
È bravo quando lavora su piccoli progetti, ma fa fatica se gli viene affidato un progetto grande o complesso.
Abbiamo quattro documenti archiviati nel File System di Windows gestito da File Table. Questi documenti devono essere utilizzati dalla ricerca semantica (inclusa la ricerca full-text).
Importante:sebbene abbiamo appena archiviato quattro documenti MS Word nella cartella come esempio, puoi immaginare l'importanza di utilizzare la ricerca semantica quando centinaia di tali documenti sono gestiti da un database di SQL Server e devi interrogare quei documenti per trovare informazioni preziose.
La denominazione standard dei documenti è molto importante per il successo dell'implementazione di questo approccio.
Conteggio semplice dei documenti
Possiamo confrontare questi documenti e definire le differenze e le somiglianze in base alla loro denominazione standard utilizzando la ricerca semantica. Ad esempio, una semplice query può dirci il numero totale di documenti archiviati nella cartella Windows:
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

Confronto tra dipendenti a tempo indeterminato e a contratto
Questa volta, utilizziamo la ricerca semantica per confrontare il numero di dipendenti a tempo indeterminato e a contratto nella nostra organizzazione:
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
L'uscita:
Eseguiamo una semplice query di ricerca semantica (basata sul nome del documento) per visualizzare la frase chiave e il suo punteggio relativo per ogni documento:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
L'uscita:
Aggiungiamo ulteriori dettagli ai nomi dei documenti. Li rinomineremo come segue:
- Impiegato a tempo indeterminato Asif – Project Manager esperto
- Mike Dipendente Permanente – Programmatore Fresco
- Peter Dipendente a tempo indeterminato – Fresh Project Manager
- Impiegato a contratto Sadaf - Analista aziendale esperto
Trovare nuovi dipendenti (documenti)
Trova i documenti relativi ai nuovi dipendenti in base ai loro titoli (denominazione standard):
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
I risultati:
Trovare dipendenti esperti (documenti)
Supponiamo di voler rivedere rapidamente tutti i dettagli dei dipendenti esperti per il complesso progetto che ci aspetta. Usa la seguente query di ricerca semantica:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
L'uscita:
Trovare tutti i Project Manager (Documenti)
Infine, se vogliamo esaminare rapidamente i documenti per tutti i project manager, abbiamo bisogno della seguente query di ricerca semantica:
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
I risultati:
Dopo aver implementato la procedura dettagliata, puoi archiviare correttamente dati non strutturati, come documenti MS Word, in una cartella di Windows utilizzando la tabella file.
Revisione dell'analisi basata sul nome
Finora, abbiamo imparato come eseguire un'analisi basata sui nomi dei documenti archiviati in una tabella di file utilizzando la ricerca semantica. Tuttavia, abbiamo bisogno delle seguenti condizioni soddisfatte:
- Dovrebbe essere presente la denominazione standard.
- I nomi dovrebbero fornire le informazioni richieste per l'analisi.
Queste condizioni sono anche limitazioni dell'analisi basata sul nome. Ma questo non significa che non possiamo farci molto.
Il nostro focus rimane sull'approccio di ricerca semantica basato su nome/colonna.
Visualizza le colonne dei nomi dei documenti
Esaminiamo alcune delle colonne principali della tabella Documenti incluso il Nome colonna:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
L'uscita:
Comprendere la funzione SEMANTICKEYPHRASETABLE
SQL Server offre la SEMANTICKEYPHRASETABLE funzione per analizzare il documento con la ricerca semantica. La sintassi è la seguente:
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
Questa funzione ci fornisce le frasi chiave associate al documento. Possiamo usarli per analizzare i documenti in base ai loro nomi o contenuti. Nel nostro caso, dobbiamo non solo utilizzare questa funzione, ma anche capire come utilizzarla correttamente.
La funzione richiede i seguenti dati:
- Nome della tabella file da utilizzare per l'analisi della ricerca semantica.
- Nome della colonna da utilizzare per l'analisi della ricerca semantica.
Quindi restituisce i seguenti dati:
- Column_id – il numero della colonna
- Chiave_documento – la chiave primaria predefinita per il documento Tabella File
- Frase chiave – è una frase che Semantic Search decide di indicizzare per l'analisi. Si applica sia al nome che al contenuto del documento a seconda della colonna di cui vogliamo vedere le frasi chiave
- Punteggio – determina la forza di una frase chiave associata a un documento, ad esempio il modo migliore per riconoscere un documento dalla sua frase chiave. Il punteggio può essere compreso tra 0,0 e 1,0.
Analisi di tutti i documenti utilizzando la funzione SEMANTICKEYPHRASETABLE
Usiamo la SEMANTICKEYPHRASETABLE funzione per l'analisi nominativa dei documenti archiviati nella cartella Windows gestita dalla Tabella File.
Esegui il seguente script T-SQL:
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
L'uscita:
Abbiamo un elenco di tutte le frasi chiave allegate a tutti i documenti e ai loro punteggi. Il id_colonna 3 nella riga in alto c'è il nome colonna. Inoltre, abbiamo anche chiamato la funzione fornendo questa colonna (nome):
Puoi trovare la document_key : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 eseguendo il seguente script (sebbene sia chiaro che questo documento è quello in cui il nome contiene la frase chiave sadaf ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
L'uscita:
La frase chiave saf ha ottenuto il miglior punteggio :1.0 .
Pertanto, nel caso della denominazione standard del documento con informazioni sufficienti per l'analisi della ricerca semantica, la nostra frase chiave sadaf è la migliore corrispondenza per quel particolare nome del documento.
Analisi di un documento specifico utilizzando la funzione SEMANTICKEYPHRASETABLE
Possiamo restringere la nostra analisi di ricerca semantica in base al nome colonna. Ad esempio, dobbiamo solo visualizzare la colonna nome- frasi chiave basate su un particolare documento. Possiamo specificare la chiave del documento nella SEMANTICKEYPHRASETABLE Funzione.
Innanzitutto, identifichiamo la chiave del documento per quel documento in cui vogliamo vedere tutte le frasi chiave. Esegui il seguente script T-SQL:
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
La chiave del documento è 0xFF6A92952500812FF013376870181CFA6D7C070220
Ora, esaminiamo questo documento riguardante tutte le frasi chiave che possono definire il nome del documento:
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
I risultati:
La frase chiave dipendente ottiene il punteggio più alto in questo documento. Possiamo vedere che tutte le parole della colonna sono frasi chiave che determinano il significato del documento.
Comprendere la funzione SEMANTICSILARITYTABLE
Questa funzione ci aiuta a confrontare un documento con tutti gli altri documenti in base a frasi chiave. La sintassi di questa funzione è la seguente:
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
Richiede il nome della tabella, la colonna e la chiave del documento per abbinare altri documenti. Ad esempio, possiamo affermare che due documenti sono simili se hanno un buon punteggio di corrispondenza della frase chiave.
Confronto di documenti utilizzando la funzione SEMANTICSILARITYTABLE
Confrontiamo un documento con altri documenti utilizzando la SEMANTICSIMILARITYTABLE Funzione.
Confronto di tutti i documenti dei project manager
Abbiamo bisogno di vedere tutti i documenti relativi ai project manager. Dagli esempi precedenti, sappiamo che la chiave del documento per il documento specificato è 0xFF6A92952500812FF013376870181CFA6D7C070220 . Quindi, possiamo usare questa chiave per trovare altre corrispondenze, inclusi i project manager:
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
L'uscita:
Il documento più strettamente correlato è Asif Permanent Employee – Expert Project Manager.docx
Confronto tra documenti di analisti aziendali esperti
Ora confronteremo i documenti relativi a analista aziendale esperto se trova la corrispondenza più vicina utilizzando la ricerca semantica. Ci limitiamo all'analisi basata sul nome del documento:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
L'uscita:
Come possiamo vedere dai risultati sopra, la corrispondenza più vicina per il documento relativo a l'esperto analista aziendale è il documento del direttore di progetto esperto perché entrambi sono esperti . Tuttavia, il punteggio di 0,3 indica che non c'è molto in comune tra questi due documenti.
Conclusione
Congratulazioni! Abbiamo imparato con successo come archiviare documenti nelle cartelle di Windows e analizzarli utilizzando la ricerca semantica. Abbiamo anche esplorato le funzioni da utilizzare nella pratica. Ora puoi applicare le nuove conoscenze e provare i seguenti esercizi a
Resta sintonizzato per ulteriori materiali!



