Ti aggrappi ancora al design padre/figlio o vorresti provare qualcosa di nuovo, come l'ID gerarchia di SQL Server? Ebbene, è davvero una novità perché HierarchID fa parte di SQL Server dal 2008. Naturalmente, la novità in sé non è un argomento convincente. Ma tieni presente che Microsoft ha aggiunto questa funzionalità per rappresentare in modo migliore le relazioni uno-a-molti con più livelli.
Potresti chiederti che differenza fa e quali vantaggi ottieni dall'uso di HierarchidID invece delle solite relazioni genitore/figlio. Se non hai mai esplorato questa opzione, potrebbe sorprenderti.
La verità è che non ho esplorato questa opzione da quando è stata rilasciata. Tuttavia, quando finalmente l'ho fatto, l'ho trovato una grande innovazione. È un codice più bello, ma contiene molto di più. In questo articolo scopriremo tutte queste eccellenti opportunità.
Tuttavia, prima di approfondire le peculiarità dell'utilizzo di SQL Server HierarchidID, chiariamone il significato e l'ambito.
Che cos'è SQL Server HierarchyID?
L'ID gerarchia di SQL Server è un tipo di dati predefinito progettato per rappresentare gli alberi, che sono il tipo più comune di dati gerarchici. Ogni elemento in un albero è chiamato nodo. In un formato tabella, è una riga con una colonna di tipo di dati HierarchiaID.
Di solito, dimostriamo le gerarchie utilizzando un design a tabella. Una colonna ID rappresenta un nodo e un'altra colonna rappresenta il genitore. Con SQL Server HierarchyID, è necessaria solo una colonna con un tipo di dati HierarchyID.
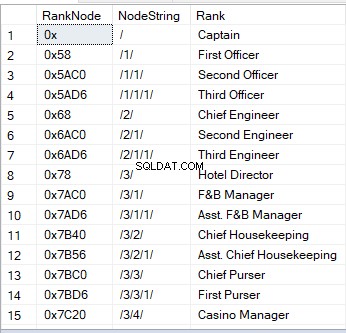
Quando esegui una query su una tabella con una colonna HierarchiaID, vengono visualizzati valori esadecimali. È una delle immagini visive di un nodo. Un altro modo è una stringa:
'/' sta per il nodo principale;
‘/1/’, ‘/2/’, ‘/3/’ o ‘/n/’ stanno per i figli – discendenti diretti da 1 a n;
‘/1/1/’ o ‘/1/2/’ sono i “figli di figli – “nipoti”. La stringa come '/1/2/' significa che il primo figlio della radice ha due figli, che sono, a loro volta, due nipoti della radice.
Ecco un esempio di come appare:
A differenza di altri tipi di dati, le colonne HierarchidID possono sfruttare i metodi incorporati. Ad esempio, se disponi di una colonna HierarchiaID denominata RankNode , puoi avere la seguente sintassi:
RankNode.
Metodi di SQL Server HierarchyID
Uno dei metodi disponibili è IsDescendantOf . Restituisce 1 se il nodo corrente è un discendente di un valore di HierarchiaID.
Puoi scrivere codice con questo metodo simile a quello seguente:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Altri metodi utilizzati con l'ID gerarchia sono i seguenti:
- GetRoot – il metodo statico che restituisce la radice dell'albero.
- GetDescendant:restituisce un nodo figlio di un genitore.
- GetAncestor:restituisce un ID gerarchia che rappresenta l'ennesimo predecessore di un determinato nodo.
- GetLevel:restituisce un numero intero che rappresenta la profondità del nodo.
- ToString – restituisce la stringa con la rappresentazione logica di un nodo. ToString viene chiamato in modo implicito quando si verifica la conversione dall'ID gerarchia al tipo stringa.
- GetReparentedValue:sposta un nodo dal vecchio genitore al nuovo genitore.
- Analizza:agisce come l'opposto di ToString . Converte la visualizzazione stringa di un ID gerarchia valore in esadecimale.
Strategie di indicizzazione di SQL Server HierarchyID
Per garantire che le query per le tabelle che utilizzano l'ID gerarchia vengano eseguite il più velocemente possibile, è necessario indicizzare la colonna. Esistono due strategie di indicizzazione:
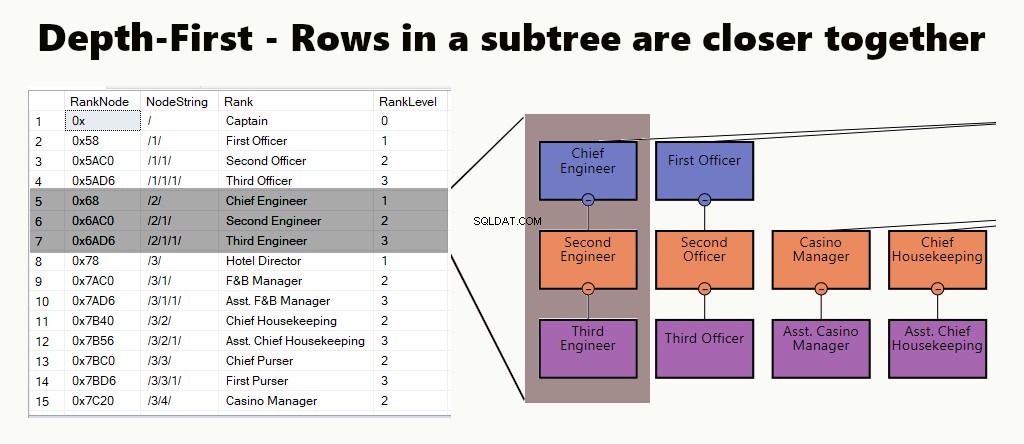
PROFONDITÀ-PRIMA
In un indice di profondità, le righe della sottostruttura sono più vicine l'una all'altra. Si adatta a query come trovare un dipartimento, le sue sottounità e i dipendenti. Un altro esempio è un manager e i suoi dipendenti conservati più vicini.
In una tabella è possibile implementare un indice di profondità creando un indice cluster per i nodi. Inoltre, eseguiamo uno dei nostri esempi, proprio così.
LARGHEZZA-PRIMA
In un indice di ampiezza, le righe dello stesso livello sono più vicine tra loro. Si adatta a domande come trovare tutti i dipendenti che riportano direttamente il manager. Se la maggior parte delle query è simile a questa, crea un indice cluster basato su (1) livello e (2) nodo.
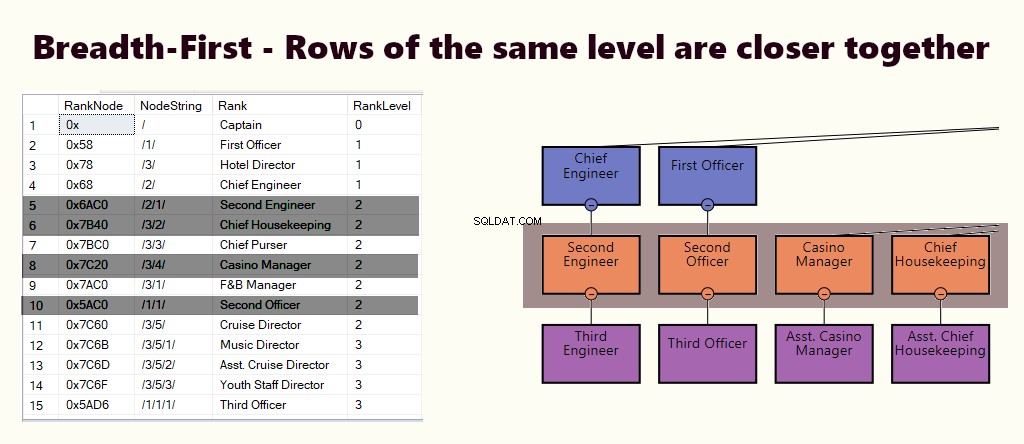
Dipende dalle tue esigenze se hai bisogno di un indice di profondità, di ampiezza o entrambi. Devi bilanciare l'importanza del tipo di query e le istruzioni DML che esegui sulla tabella.
Limitazioni di SQL Server HierarchyID
Sfortunatamente, l'utilizzo dell'ID gerarchia non può risolvere tutti i problemi:
- SQL Server non può indovinare quale sia il figlio di un genitore. Devi definire l'albero nella tabella.
- Se non utilizzi un vincolo univoco, il valore di GerarchiaID generato non sarà univoco. La gestione di questo problema è responsabilità dello sviluppatore.
- Le relazioni di un nodo padre e figlio non vengono applicate come una relazione di chiave esterna. Quindi, prima di eliminare un nodo, interrogare eventuali discendenti esistenti.
Visualizzazione delle gerarchie
Prima di procedere, considera un'altra domanda. Osservando il set di risultati con stringhe di nodi, trovi difficile visualizzare la gerarchia per i tuoi occhi?
Per me è un grande sì perché non sto invecchiando.
Per questo motivo, utilizzeremo Power BI e Hierarchy Chart di Akvelon insieme alle nostre tabelle di database. Aiuteranno a visualizzare la gerarchia in un organigramma. Spero che semplificherà il lavoro.
Ora mettiamoci al lavoro.
Utilizzo di SQL Server HierarchyID
Puoi utilizzare HierarchyID con i seguenti scenari aziendali:
- Struttura organizzativa
- Cartelle, sottocartelle e file
- Attività e sottoattività in un progetto
- Pagine e sottopagine di un sito web
- Dati geografici con paesi, regioni e città
Anche se il tuo scenario aziendale è simile al precedente e raramente esegui query tra le sezioni della gerarchia, non hai bisogno dell'ID gerarchia.
Ad esempio, la tua organizzazione elabora le buste paga per i dipendenti. Hai bisogno di accedere al sottoalbero per elaborare il libro paga di qualcuno? Affatto. Tuttavia, se elabori commissioni di persone in un sistema di marketing multilivello, può essere diverso.
In questo post utilizziamo la parte della struttura organizzativa e della catena di comando su una nave da crociera. La struttura è stata adattata dall'organigramma da qui. Dai un'occhiata alla Figura 4 di seguito:

Ora puoi visualizzare la gerarchia in questione. Usiamo le tabelle seguenti in tutto questo post:
- Navi – è la tabella che rappresenta la lista delle navi da crociera.
- Classifiche – è la tabella dei ranghi dell'equipaggio. Lì stabiliamo le gerarchie utilizzando l'ID gerarchia.
- Equipaggio – è l'elenco dell'equipaggio di ciascuna nave e dei suoi ranghi.
La struttura della tabella di ogni caso è la seguente:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOInserimento di dati di tabella con SQL Server HierarchyID
La prima attività nell'utilizzo completo dell'ID gerarchia consiste nell'aggiungere record alla tabella con un ID gerarchia colonna. Ci sono due modi per farlo.
Utilizzo delle stringhe
Il modo più rapido per inserire i dati con l'ID gerarchia consiste nell'utilizzare le stringhe. Per vederlo in azione, aggiungiamo alcuni record alle Classi tabella.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Il codice sopra aggiunge 20 record alla tabella Ranks.
Come puoi vedere, la struttura ad albero è stata definita nel INSERT dichiarazione sopra. È facilmente distinguibile quando usiamo le stringhe. Inoltre, SQL Server lo converte nei valori esadecimali corrispondenti.
Utilizzo di Max(), GetAncestor() e GetDescendant()
L'uso di stringhe si adatta al compito di popolare i dati iniziali. A lungo termine, è necessario che il codice gestisca l'inserimento senza fornire stringhe.
Per eseguire questa attività, ottieni l'ultimo nodo utilizzato da un genitore o predecessore. Lo realizziamo usando le funzioni MAX() e GetAncestor() . Vedere il codice di esempio di seguito:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Di seguito sono riportati i punti presi dal codice sopra:
- In primo luogo, hai bisogno di una variabile per l'ultimo nodo e l'immediato superiore.
- L'ultimo nodo può essere acquisito utilizzando MAX() contro RankNode per il genitore specificato o il superiore diretto. Nel nostro caso, è l'Assistente F&B Manager con un valore del nodo di 0x7AD6.
- Successivamente, per assicurarti che nessun figlio duplicato venga visualizzato, usa @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . Il valore in @MaxNode è l'ultimo figlio Se non è NULL , Ottieni Discendente() restituisce il prossimo valore del nodo possibile.
- Ultima, GetLevel() restituisce il livello del nuovo nodo creato.
Richiesta di dati
Dopo aver aggiunto i record alla nostra tabella, è il momento di interrogarlo. Sono disponibili 2 modi per interrogare i dati:
La query per i discendenti diretti
Quando cerchiamo i dipendenti che riportano direttamente al manager, dobbiamo sapere due cose:
- Il valore del nodo del gestore o del genitore
- Il livello del dipendente sotto il manager
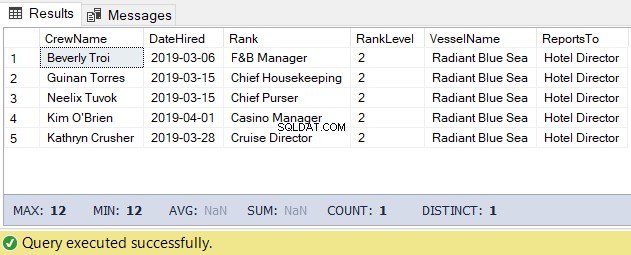
Per questa attività, possiamo utilizzare il codice seguente. L'output è l'elenco dell'equipaggio sotto il Direttore dell'hotel.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorIl risultato del codice precedente è il seguente nella Figura 5:
Query per le sottostrutture
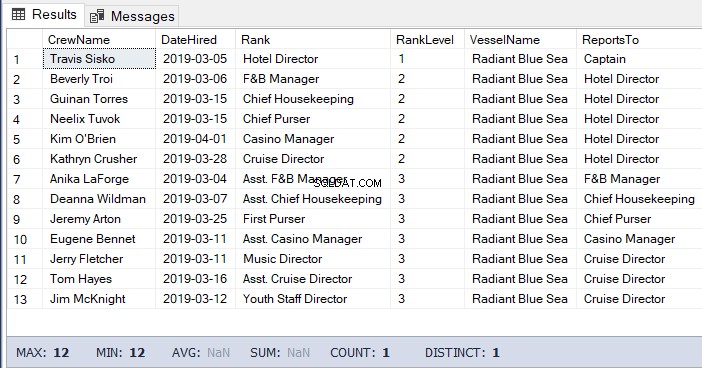
A volte, devi anche elencare i bambini e i bambini dei bambini fino in fondo. Per fare ciò, è necessario disporre dell'ID gerarchia del genitore.
La query sarà simile al codice precedente ma senza la necessità di ottenere il livello. Vedi l'esempio di codice:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Il risultato del codice sopra:
Spostamento di nodi con SQL Server HierarchyID
Un'altra operazione standard con i dati gerarchici è lo spostamento di un figlio o di un intero sottoalbero su un altro genitore. Tuttavia, prima di procedere, prendi nota di un potenziale problema:
Potenziale problema
- In primo luogo, lo spostamento dei nodi coinvolge l'I/O. La frequenza con cui sposti i nodi può essere il fattore decisivo se utilizzi l'ID gerarchia o il solito genitore/figlio.
- In secondo luogo, lo spostamento di un nodo in un progetto padre/figlio aggiorna una riga. Allo stesso tempo, quando sposti un nodo con HierarchiaID, aggiorna una o più righe. Il numero di righe interessate dipende dalla profondità del livello gerarchico. Può trasformarsi in un problema di prestazioni significativo.
Soluzione
Potresti gestire questo problema con la progettazione del tuo database.
Consideriamo il design che abbiamo utilizzato qui.
Invece di definire la gerarchia dell'Equipaggio tabella, l'abbiamo definita in Ranks tavolo. Questo approccio è diverso dal Dipendente tabella in AdventureWorks database di esempio e offre i seguenti vantaggi:
- I membri dell'equipaggio si muovono più spesso dei ranghi di una nave. Questo design ridurrà i movimenti dei nodi nella gerarchia. Di conseguenza, riduce al minimo il problema sopra definito.
- Definire più di una gerarchia nella Equipaggio la tabella è più complicata, poiché due navi hanno bisogno di due capitani. Il risultato sono due nodi radice.
- Se devi visualizzare tutti i gradi con il membro dell'equipaggio corrispondente, puoi utilizzare un LEFT JOIN. Se nessuno è a bordo per quel grado, mostra uno spazio vuoto per la posizione.
Passiamo ora all'obiettivo di questa sezione. Aggiungi nodi figlio sotto i genitori sbagliati.
Per visualizzare quello che stiamo per fare, immagina una gerarchia come quella qui sotto. Nota i nodi gialli.

Sposta un nodo senza figli
Lo spostamento di un nodo figlio richiede quanto segue:
- Definisci l'ID gerarchia del nodo figlio da spostare.
- Definisci l'ID gerarchia del vecchio genitore.
- Definisci l'ID gerarchia del nuovo genitore.
- Utilizza AGGIORNAMENTO con GetReparentedValue() per spostare fisicamente il nodo.
Inizia spostando un nodo senza figli. Nell'esempio seguente, spostiamo il Cruise Staff da sotto il Cruise Director a sotto l'Asst. Direttore della crociera.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
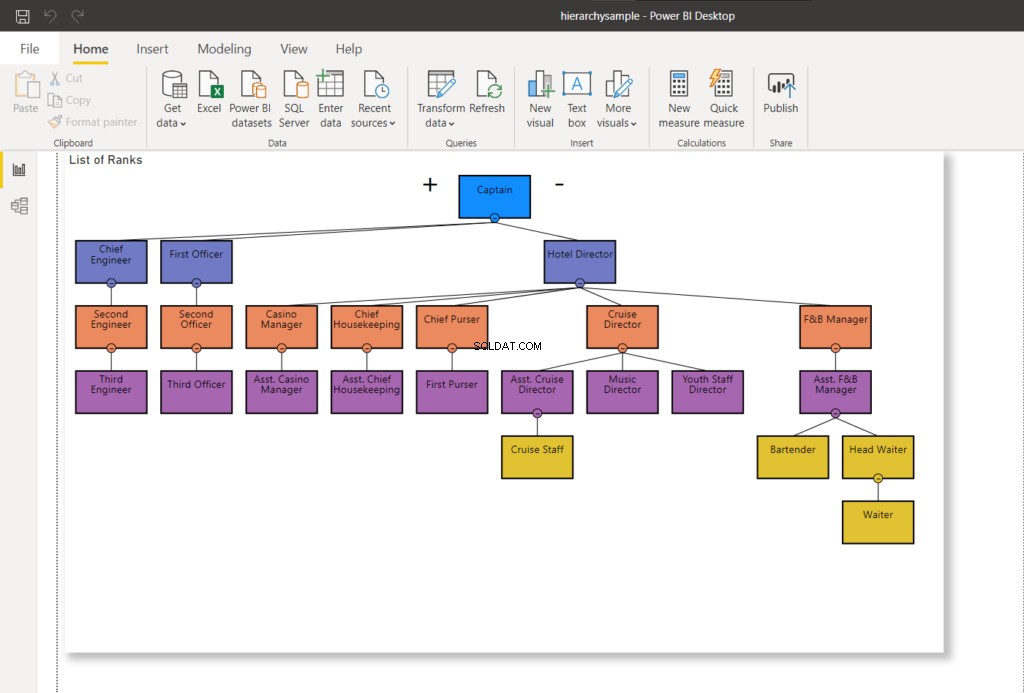
WHERE RankNode = @NodeToMoveUna volta aggiornato il nodo, verrà utilizzato un nuovo valore esadecimale per il nodo. Aggiornando la mia connessione Power BI a SQL Server:cambierà il grafico della gerarchia come mostrato di seguito:
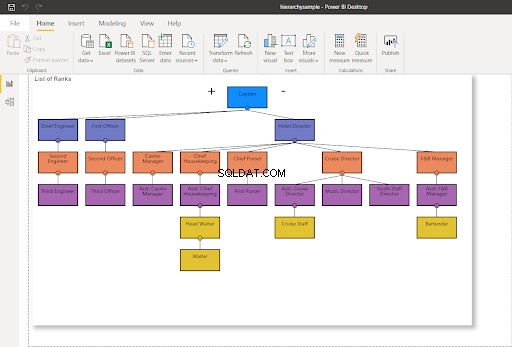
Nella Figura 8, il personale della crociera non riporta più al direttore della crociera, ma viene modificato per riferire all'assistente del direttore della crociera. Confrontalo con la Figura 7 sopra.
Ora, passiamo alla fase successiva e spostiamo il capo cameriere all'assistente F&B Manager.
Sposta un nodo con figli
C'è una sfida in questa parte.
Il fatto è che il codice precedente non funzionerà con un nodo con nemmeno un figlio. Ricordiamo che lo spostamento di un nodo richiede l'aggiornamento di uno o più nodi figli.
Inoltre, non finisce qui. Se il nuovo genitore ha un figlio esistente, potremmo imbatterci in valori di nodo duplicati.
In questo esempio, dobbiamo affrontare quel problema:l'Asst. F&B Manager ha un nodo figlio Bartender.
Pronto? Ecco il codice:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;Nell'esempio di codice sopra, l'iterazione inizia come la necessità di trasferire il nodo fino al figlio all'ultimo livello.
Dopo averlo eseguito, i Classi la tabella verrà aggiornata. E ancora, se vuoi vedere le modifiche visivamente, aggiorna il report di Power BI. Vedrai le modifiche simili a quella qui sotto:
Vantaggi dell'utilizzo di SQL Server HierarchyID rispetto a padre/figlio
Per convincere chiunque a utilizzare una funzione, dobbiamo conoscerne i vantaggi.
Pertanto, in questa sezione, confronteremo le affermazioni utilizzando le stesse tabelle come quelle dell'inizio. Uno utilizzerà l'ID gerarchia e l'altro utilizzerà l'approccio genitore/figlio. Il set di risultati sarà lo stesso per entrambi gli approcci. Lo aspettiamo per questo esercizio come quello di Figura 6 sopra.
Ora che i requisiti sono precisi esaminiamo a fondo i vantaggi.
Più semplice da codificare
Vedi il codice qui sotto:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Questo esempio necessita solo di un valore di HierarchiaID. È possibile modificare il valore a piacimento senza modificare la query.
Ora, confronta l'istruzione per l'approccio genitore/figlio producendo lo stesso set di risultati:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Cosa ne pensi? Gli esempi di codice sono quasi gli stessi tranne un punto.
Il DOVE La clausola nella seconda query non sarà flessibile per adattarsi se è richiesto un sottoalbero diverso.
Rendi la seconda query abbastanza generica e il codice sarà più lungo. Accidenti!
Esecuzione più rapida
Secondo Microsoft, "le query della sottostruttura sono significativamente più veloci con l'ID gerarchia" rispetto a padre/figlio. Vediamo se è vero.
Usiamo le stesse query di prima. Una metrica significativa da utilizzare per il rendimento sono le letture logiche da SET STATISTICS IO . Indica quante pagine da 8 KB saranno necessarie a SQL Server per ottenere il set di risultati desiderato. Maggiore è il valore, maggiore è il numero di pagine a cui SQL Server accede e legge e più lenta viene eseguita la query. Esegui IMPOSTA STATISTICHE IO ON ed eseguire nuovamente le due query precedenti. Il valore più basso delle letture logiche sarà il vincitore.
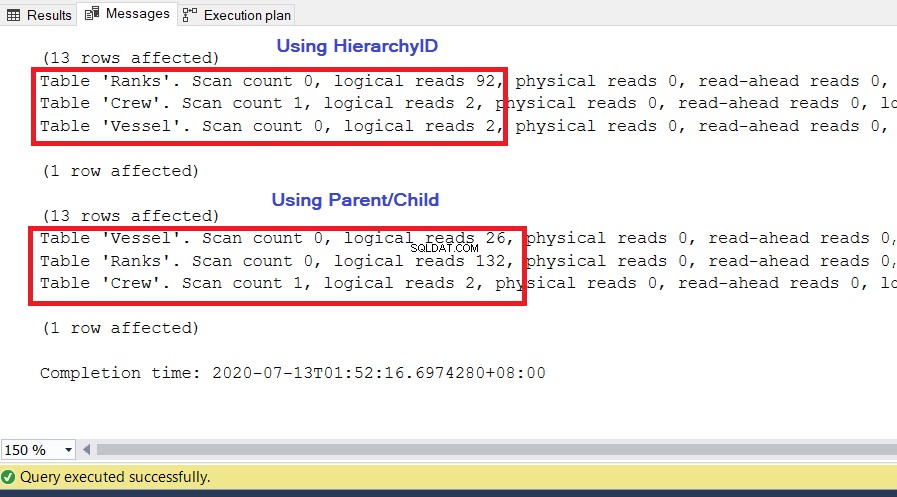
ANALISI
Come si può vedere nella Figura 10, le statistiche di I/O per la query con HierarchiaID hanno letture logiche inferiori rispetto alle loro controparti padre/figlio. Nota i seguenti punti in questo risultato:
- Il vaso table è la più notevole delle tre tabelle. L'utilizzo dell'ID gerarchia richiede solo 2 * 8 KB =16 KB di pagine da leggere da SQL Server dalla cache (memoria). Nel frattempo, l'utilizzo di genitore/figlio richiede 26 * 8 KB =208 KB di pagine, un valore notevolmente superiore rispetto all'utilizzo di HierarchidID.
- Le classifiche tabella, che include la nostra definizione di gerarchie, richiede 92 * 8 KB =736 KB. D'altra parte, l'utilizzo di genitore/figlio richiede 132 * 8 KB =1056 KB.
- L'equipaggio la tabella richiede 2 * 8 KB =16 KB, che è la stessa per entrambi gli approcci.
I kilobyte di pagine potrebbero essere un valore piccolo per ora, ma abbiamo solo pochi record. Tuttavia, ci dà un'idea di quanto sarà gravosa la nostra query su qualsiasi server. Per migliorare le prestazioni, puoi eseguire una o più delle seguenti azioni:
- Aggiungi indici appropriati
- Ristruttura la query
- Aggiorna le statistiche
Se si esegue quanto sopra e le letture logiche diminuiscono senza aggiungere altri record, le prestazioni aumenterebbero. Finché rendi le letture logiche inferiori rispetto a quelle che utilizzano l'ID gerarchia, questa sarà una buona notizia.
Ma perché fare riferimento a letture logiche anziché al tempo trascorso?
Controllo del tempo trascorso per entrambe le query utilizzando SET STATISTICS TIME ON rivela un piccolo numero di differenze di millisecondi per il nostro piccolo set di dati. Inoltre, il server di sviluppo potrebbe avere una configurazione hardware, impostazioni di SQL Server e carico di lavoro diversi. Un tempo trascorso inferiore a un millisecondo potrebbe trarti in inganno se la tua query sta funzionando velocemente come ti aspetti o meno.
SCAVANDO OLTRE
IMPOSTA LE STATISTICHE IO ON non rivela le cose che accadono “dietro le quinte”. In questa sezione, scopriamo perché SQL Server arriva con quei numeri osservando il piano di esecuzione.
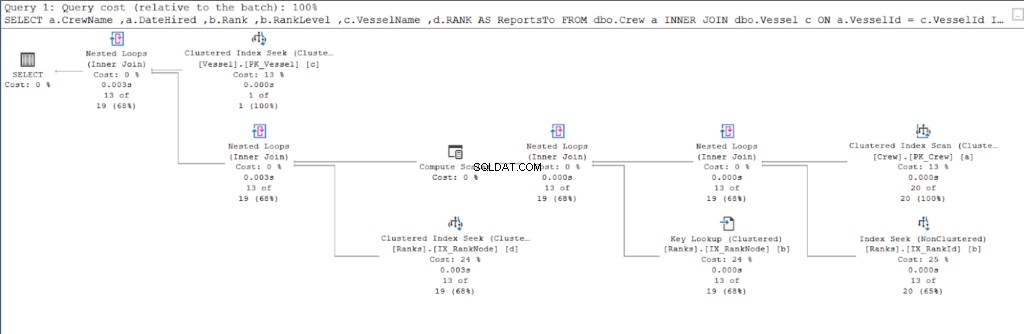
Iniziamo con il piano di esecuzione della prima query.
Ora, guarda il piano di esecuzione della seconda query.
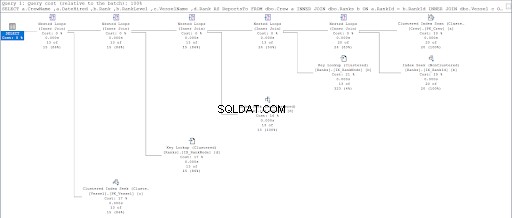
Confrontando le figure 11 e 12, vediamo che SQL Server richiede uno sforzo aggiuntivo per produrre il set di risultati se si utilizza l'approccio padre/figlio. Il DOVE clausola è responsabile di questa complicazione.
Tuttavia, la colpa potrebbe anche essere del design del tavolo. Abbiamo utilizzato la stessa tabella per entrambi gli approcci:i Ranks tavolo. Quindi, ho provato a duplicare i Rank tabella ma utilizza diversi indici cluster appropriati per ciascuna procedura.
Nel risultato, l'utilizzo di gerarchiaID aveva ancora meno letture logiche rispetto alla controparte padre/figlio. Infine, abbiamo dimostrato che Microsoft aveva ragione ad affermarlo.
Conclusione
Qui il momento centrale per l'ID gerarchia sono:
- HierarchyID è un tipo di dati integrato progettato per una rappresentazione più ottimizzata degli alberi, che sono il tipo più comune di dati gerarchici.
- Ogni elemento nell'albero è un nodo e i valori di HierarchiaID possono essere in formato esadecimale o stringa.
- HierarchyID è applicabile per dati di strutture organizzative, attività di progetto, dati geografici e simili.
- Esistono metodi per attraversare e manipolare i dati gerarchici, come GetAncestor (), Get Discendente (). GetLevel (), GetReparentedValue () e altro.
- Il modo convenzionale per interrogare i dati gerarchici è ottenere i discendenti diretti di un nodo o ottenere i sottoalberi sotto un nodo.
- L'utilizzo dell'ID gerarchia per interrogare i sottoalberi non è solo più semplice da codificare. Funziona anche meglio di genitore/figlio.
Il design genitore/figlio non è affatto male e questo post non vuole sminuirlo. Tuttavia, ampliare le opzioni e introdurre nuove idee è sempre un grande vantaggio per uno sviluppatore.
Puoi provare tu stesso gli esempi che abbiamo offerto qui. Ricevi gli effetti e scopri come applicarli al tuo prossimo progetto che coinvolge le gerarchie.
Se ti piace il post e le sue idee, puoi spargere la voce facendo clic sui pulsanti di condivisione per i social media preferiti.