In un recente thread su StackExchange, un utente ha riscontrato il seguente problema:
Voglio una query che restituisca la prima persona nella tabella con un GroupID =2. Se non esiste nessuno con un GroupID =2, voglio la prima persona con un RoleID =2.
Scartiamo, per ora, il fatto che "first" sia terribilmente definito. In realtà, all'utente non importava quale persona ricevesse, se fosse arrivata casualmente, arbitrariamente o attraverso una logica esplicita oltre ai suoi criteri principali. Ignorandolo, supponiamo che tu abbia una tabella di base:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
Nel mondo reale ci sono probabilmente altre colonne, vincoli aggiuntivi, forse chiavi esterne ad altre tabelle e sicuramente altri indici. Ma manteniamo questo semplice e facciamo una domanda.
Probabili soluzioni
Con quel design del tavolo, risolvere il problema sembra semplice, giusto? Il primo tentativo che probabilmente faresti è:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Questo utilizza TOP e un ORDER BY condizionale per trattare quegli utenti con un GroupID =2 come priorità più alta. Il piano per questa query è piuttosto semplice, con la maggior parte dei costi che si verificano in un'operazione di ordinamento. Di seguito sono riportate le metriche di runtime rispetto a una tabella vuota:
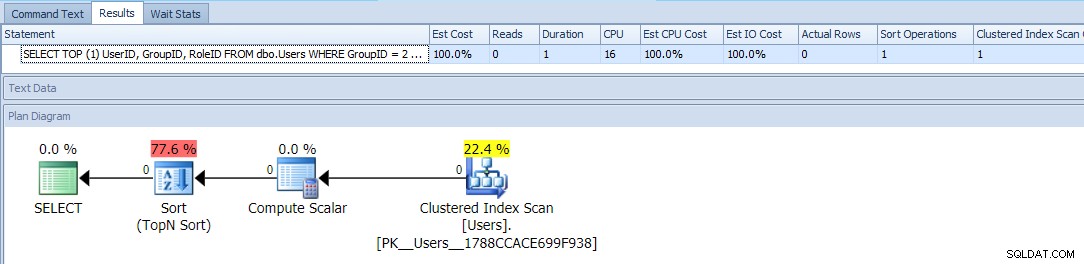
Questo sembra essere il massimo che puoi fare:un semplice piano che scansiona il tavolo solo una volta e diverso da un tipo fastidioso con cui dovresti essere in grado di convivere, nessun problema, giusto?
Bene, un'altra risposta nel thread ha offerto questa variazione più complessa:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
A prima vista, probabilmente penseresti che questa query sia estremamente meno efficiente, poiché richiede due scansioni di indici cluster. Avresti sicuramente ragione su questo; ecco le metriche del piano e del runtime rispetto a una tabella vuota:
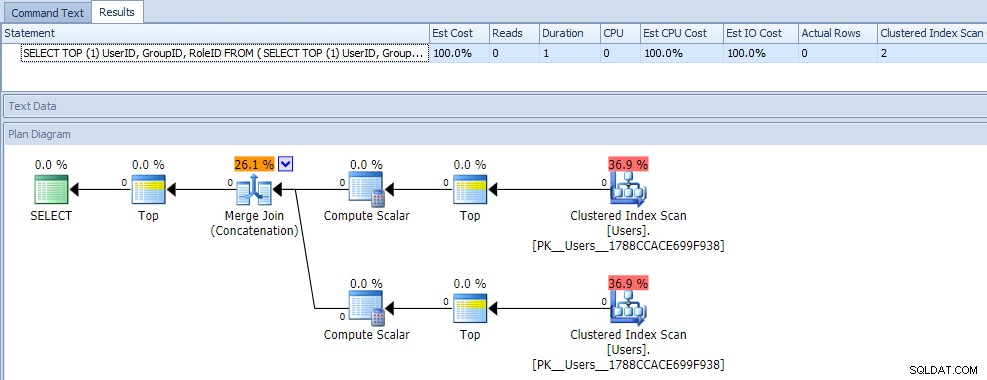
Ma ora aggiungiamo i dati
Per testare queste query, volevo utilizzare alcuni dati realistici. Quindi prima ho popolato 1.000 righe da sys.all_objects, con operazioni modulo contro object_id per ottenere una distribuzione decente:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Ora, quando eseguo le due query, ecco le metriche di runtime:

La versione UNION ALL viene fornita con un I/O leggermente inferiore (4 letture contro 5), una durata inferiore e un costo complessivo stimato inferiore, mentre la versione condizionale ORDER BY ha un costo CPU stimato inferiore. I dati qui sono piuttosto piccoli su cui trarre conclusioni; Lo volevo solo come un palo nel terreno. Ora, cambiamo la distribuzione in modo che la maggior parte delle righe soddisfi almeno uno dei criteri (e talvolta entrambi):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Questa volta, l'ordine condizionale di ha i costi stimati più alti sia in CPU che in I/O:

Ma ancora una volta, a queste dimensioni di dati, c'è un impatto relativamente irrilevante sulla durata e sulle letture e, a parte i costi stimati (che comunque sono in gran parte inventati), è difficile dichiarare un vincitore qui.
Quindi, aggiungiamo molti più dati
Sebbene mi piaccia creare dati di esempio dalle viste del catalogo, poiché tutti li hanno, questa volta disegnerò sul tavolo Sales.SalesOrderHeaderEnlarged da AdventureWorks2012, ampliato utilizzando questo script di Jonathan Kehayias. Sul mio sistema, questa tabella ha 1.258.600 righe. Il seguente script inserirà un milione di quelle righe nella nostra tabella dbo.Users:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Ok, ora quando eseguiamo le query, vediamo un problema:la variazione ORDER BY è andata in parallelo e ha cancellato sia le letture che la CPU, producendo una differenza di durata di quasi 120 volte:
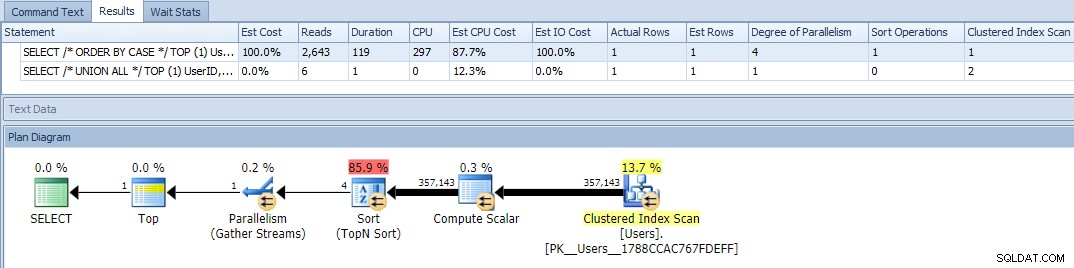
Eliminare il parallelismo (usando MAXDOP) non ha aiutato:
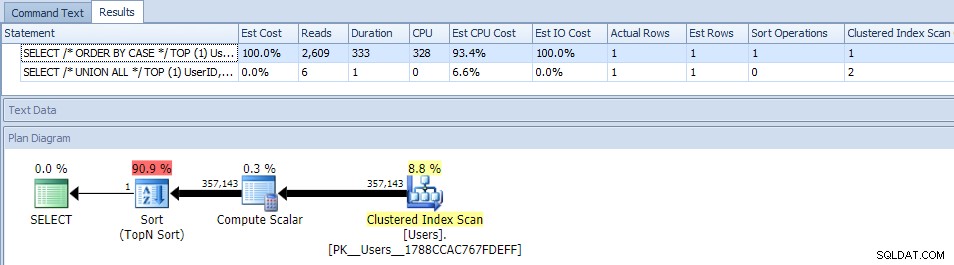
(Il piano UNION ALL ha ancora lo stesso aspetto.)
E se cambiamo lo skew in modo che sia pari, dove il 95% delle righe soddisfa almeno un criterio:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Le query mostrano ancora che l'ordinamento è proibitivo:

E con MAXDOP =1 era molto peggio (basta guardare la durata):

Infine, che ne dici di un'inclinazione del 95% in entrambe le direzioni (ad es. la maggior parte delle righe soddisfa i criteri GroupID o la maggior parte delle righe soddisfa i criteri RoleID)? Questo script garantirà che almeno il 95% dei dati abbia GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
I risultati sono abbastanza simili (d'ora in poi smetterò di provare la cosa MAXDOP):

E poi se ci spostiamo dall'altra parte, dove almeno il 95% dei dati ha RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Risultati:

Conclusione
In nessun singolo caso che ho potuto produrre, la query ORDER BY "più semplice" - anche con una scansione dell'indice meno raggruppata - ha superato la query UNION ALL più complessa. A volte devi stare molto attento a cosa deve fare SQL Server quando introduci operazioni come gli ordinamenti nella semantica della tua query e non fare affidamento solo sulla semplicità del piano (non importa eventuali pregiudizi che potresti avere in base a scenari precedenti).
Il tuo primo istinto potrebbe spesso essere corretto, ma scommetto che ci sono momenti in cui c'è un'opzione migliore che sembra, in superficie, come se non potesse funzionare meglio. Come in questo esempio. Sto migliorando un po' nel mettere in discussione le ipotesi che ho fatto dalle osservazioni e nel non fare affermazioni generali come "le scansioni non funzionano mai bene" e "le query più semplici vengono sempre eseguite più velocemente". Se elimini le parole mai e sempre dal tuo vocabolario, potresti ritrovarti a mettere alla prova più di quelle ipotesi e affermazioni generali e finire molto meglio.