Ogni prodotto presenta bug e SQL Server non fa eccezione. L'uso delle funzionalità del prodotto in un modo leggermente insolito (o la combinazione di funzionalità relativamente nuove insieme) è un ottimo modo per trovarle. I bug possono essere interessanti e persino educativi, ma forse alcune delle gioie vengono perse quando la scoperta fa sì che il tuo cercapersone si spenga alle 4 del mattino, forse dopo una serata particolarmente social con gli amici...
Il bug oggetto di questo post è probabilmente ragionevolmente raro in natura, ma non è un classico caso limite. Conosco almeno un consulente che l'ha riscontrato in un sistema di produzione. Su un argomento completamente non correlato, dovrei cogliere l'occasione per salutare il Grumpy Old DBA (blog).
Inizierò con alcune informazioni rilevanti sui join di unione. Se sei certo di sapere già tutto ciò che c'è da sapere sull'unione di unioni o vuoi semplicemente andare al sodo, sentiti libero di scorrere fino alla sezione intitolata "Il bug".
Unisci Unisciti
Merge join non è una cosa terribilmente complicata e può essere molto efficiente nelle giuste circostanze. Richiede che i suoi input siano ordinati sulle chiavi di unione e funzioni al meglio in modalità uno-a-molti (dove almeno dei suoi input è univoco sulle chiavi di unione). Per join uno-a-molti di dimensioni moderate, il join di unione seriale non è affatto una cattiva scelta, a condizione che i requisiti di ordinamento dell'input possano essere soddisfatti senza eseguire un ordinamento esplicito.
Evitare un ordinamento si ottiene più comunemente sfruttando l'ordinamento fornito da un indice. Unisci join può anche sfruttare l'ordinamento preservato da un ordinamento precedente e inevitabile. Un aspetto interessante di merge join è che può interrompere l'elaborazione delle righe di input non appena uno dei due input esaurisce le righe. Un'ultima cosa:merge join non si preoccupa se l'ordinamento degli input è crescente o decrescente (sebbene entrambi gli input debbano essere gli stessi). L'esempio seguente utilizza una tabella di numeri standard per illustrare la maggior parte dei punti precedenti:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Si noti che gli indici che impongono le chiavi primarie su queste due tabelle sono definiti discendenti. Il piano di query per INSERT ha una serie di caratteristiche interessanti:
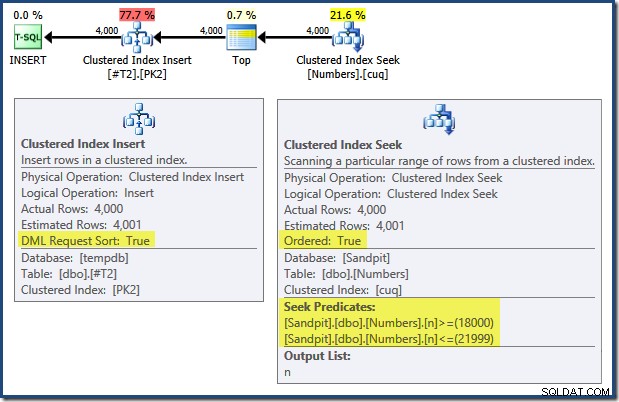
Leggendo da sinistra a destra (come è ragionevole!) l'Inserimento indice cluster ha la proprietà "Ordinamento richiesta DML" impostata. Ciò significa che l'operatore richiede le righe nell'ordine delle chiavi dell'indice cluster. L'indice cluster (che applica la chiave primaria in questo caso) è definito come DESC , quindi le righe con valori più alti devono arrivare per prime. L'indice raggruppato sulla mia tabella Numbers è ASC , quindi Query Optimizer evita un ordinamento esplicito cercando prima la corrispondenza più alta nella tabella Numbers (21.999), quindi effettuando la scansione verso la corrispondenza più bassa (18.000) in ordine inverso. La vista "Plan Tree" in SQL Sentry Plan Explorer mostra chiaramente la scansione inversa (all'indietro):
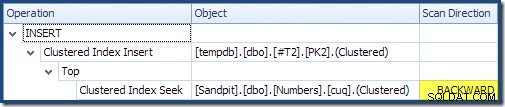
La scansione all'indietro inverte l'ordine naturale dell'indice. Una scansione all'indietro di un ASC la chiave dell'indice restituisce le righe in ordine decrescente delle chiavi; una scansione all'indietro di un DESC chiave indice restituisce le righe in ordine crescente di chiave. La "direzione di scansione" non indica di per sé l'ordine delle chiavi restituite:devi sapere se l'indice è ASC o DESC per prendere tale determinazione.
Utilizzando queste tabelle di test e dati (T1 ha 10.000 righe numerate da 10.000 a 19.999 comprese; T2 ha 4.000 righe numerate da 18.000 a 21.999) la seguente query unisce le due tabelle e restituisce i risultati in ordine decrescente di entrambe le chiavi:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; La query restituisce le 2.000 righe corrispondenti corrette come ci si aspetterebbe. Il piano post-esecuzione è il seguente:
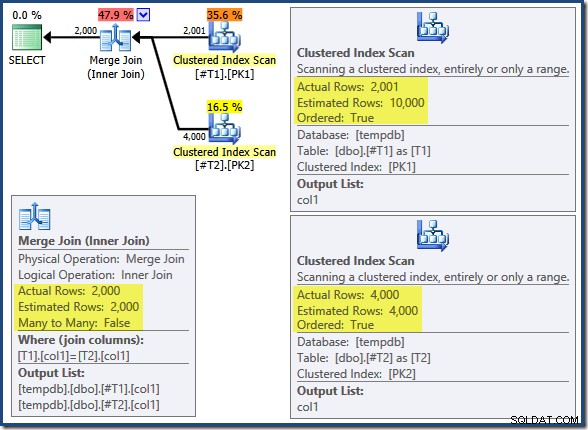
L'unione di unione non è in esecuzione in modalità molti-a-molti (l'input superiore è univoco sulle chiavi di unione) e la stima della cardinalità di 2.000 righe è esattamente corretta. La scansione dell'indice cluster della tabella T2 è ordinato (anche se dobbiamo aspettare un momento per scoprire se quell'ordine è avanti o indietro) e anche la stima della cardinalità di 4.000 righe è esattamente corretta. La scansione dell'indice cluster della tabella T1 viene anche ordinato, ma sono state lette solo 2.001 righe mentre ne sono state stimate 10.000. La vista ad albero del piano mostra che entrambe le scansioni dell'indice raggruppate sono ordinate in avanti:
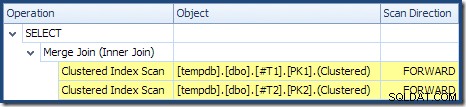
Ricordalo leggendo un DESC indice FORWARD produrrà le righe in ordine di chiave inverso. Questo è esattamente ciò che è richiesto da ORDER BY T1.col DESC, T2.col1 DESC clausola, quindi non è necessario alcun ordinamento esplicito. Lo pseudo-codice per Merge Join uno a molti (riprodotto dal blog Merge Join di Craig Freedman) è:

La scansione in ordine decrescente di T1 restituisce righe a partire da 19.999 e scendendo verso 10.000. La scansione in ordine decrescente di T2 restituisce righe a partire da 21.999 e scendendo verso 18.000. Tutte le 4.000 righe in T2 vengono infine letti, ma il processo di unione iterativo si interrompe quando viene letto il valore della chiave 17.999 da T1 , perché T2 esaurisce le righe. L'elaborazione dell'unione viene quindi completata senza leggere completamente T1 . Legge le righe da 19.999 fino a 17.999 comprese; un totale di 2.001 righe come mostrato nel piano di esecuzione sopra.
Sentiti libero di eseguire nuovamente il test con ASC indici invece, modificando anche il ORDER BY clausola da DESC a ASC . Il piano di esecuzione prodotto sarà molto simile e non sarà necessario alcun tipo di ordinamento.
Per riassumere i punti che saranno importanti tra un momento, Merge Join richiede input ordinati per chiavi di unione, ma non importa se le chiavi sono ordinate crescente o decrescente.
Il bug
Per riprodurre il bug, almeno una delle nostre tabelle deve essere partizionata. Per mantenere i risultati gestibili, questo esempio utilizzerà solo un piccolo numero di righe, quindi anche la funzione di partizionamento necessita di piccoli limiti:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
La prima tabella contiene due colonne ed è partizionata sulla CHIAVE PRIMARIA:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
La seconda tabella non è partizionata. Contiene una chiave primaria e una colonna che si unirà alla prima tabella:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); I dati di esempio
La prima tabella ha 14 righe, tutte con lo stesso valore in SomeID colonna. SQL Server assegna il IDENTITY valori di colonna, numerati da 1 a 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
La seconda tabella è semplicemente popolata con IDENTITY valori dalla tabella uno:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
I dati nelle due tabelle si presentano così:
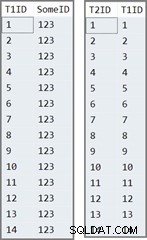
La query di prova
La prima query unisce semplicemente entrambe le tabelle, applicando un singolo predicato della clausola WHERE (che corrisponde a tutte le righe in questo esempio notevolmente semplificato):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Il risultato contiene tutte le 14 righe, come previsto:

A causa del numero ridotto di righe, l'ottimizzatore sceglie un piano di unione di cicli nidificati per questa query:
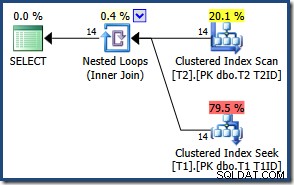
I risultati sono gli stessi (e sempre corretti) se si forza un hash o si unisce un join:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
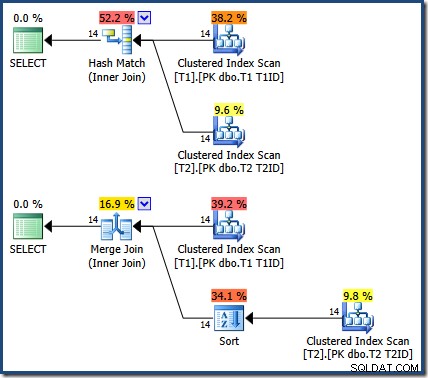
Il Merge Join è uno a molti, con un ordinamento esplicito su T1ID richiesto per la tabella T2 .
Il problema dell'indice discendente
Tutto va bene finché un giorno (per buoni motivi che non devono preoccuparci qui) un altro amministratore aggiunge un indice discendente su SomeID colonna della tabella 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
La nostra query continua a produrre risultati corretti quando l'ottimizzatore sceglie un ciclo nidificato o un join hash, ma è una storia diversa quando viene utilizzato un join unito. Quanto segue usa ancora un suggerimento per la query per forzare il Merge Join, ma questa è solo una conseguenza del basso numero di righe nell'esempio. L'ottimizzatore sceglierà naturalmente lo stesso piano Merge Join con dati di tabella diversi.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Il piano di esecuzione è:
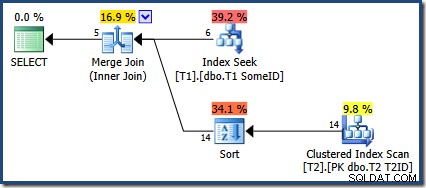
L'ottimizzatore ha scelto di utilizzare il nuovo indice, ma la query ora produce solo cinque righe di output:

Che fine hanno fatto le altre 9 righe? Per essere chiari, questo risultato non è corretto. I dati non sono cambiati, quindi tutte le 14 righe dovrebbero essere restituite (poiché lo sono ancora con un piano Nested Loops o Hash Join).
Causa e spiegazione
Il nuovo indice non cluster su SomeID non è dichiarato come univoco, quindi la chiave dell'indice cluster viene aggiunta automaticamente a tutti i livelli di indice non cluster. SQL Server aggiunge il T1ID colonna (la chiave del cluster) all'indice non cluster proprio come se avessimo creato l'indice in questo modo:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Nota la mancanza di un DESC qualificatore sul T1ID aggiunto in modo invisibile all'utente chiave. Le chiavi di indice sono ASC per impostazione predefinita. Questo non è un problema in sé (sebbene contribuisca). La seconda cosa che accade automaticamente al nostro indice è che è partizionato allo stesso modo della tabella di base. Quindi, la specifica completa dell'indice, se dovessimo scriverla in modo esplicito, sarebbe:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Questa è ora una struttura piuttosto complessa, con chiavi in tutti i tipi di ordini diversi. È abbastanza complesso da consentire a Query Optimizer di sbagliare quando ragiona sull'ordinamento fornito dall'indice. Per illustrare, considera la seguente semplice query:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
La colonna extra ci mostrerà solo a quale partizione appartiene la riga corrente. Altrimenti, è solo una semplice query che restituisce T1ID valori in ordine crescente, WHERE SomeID = 123 . Sfortunatamente, i risultati non sono quelli specificati dalla query:
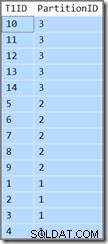
La query richiede quel T1ID i valori dovrebbero essere restituiti in ordine crescente, ma non è quello che otteniamo. Otteniamo valori in ordine crescente per partizione , ma le partizioni stesse vengono restituite in ordine inverso! Se le partizioni sono state restituite in ordine crescente (e il T1ID i valori sono rimasti ordinati all'interno di ciascuna partizione come mostrato) il risultato sarebbe corretto.
Il piano di query mostra che l'ottimizzatore è stato confuso dal DESC principale chiave dell'indice e ho pensato che fosse necessario leggere le partizioni in ordine inverso per ottenere risultati corretti:
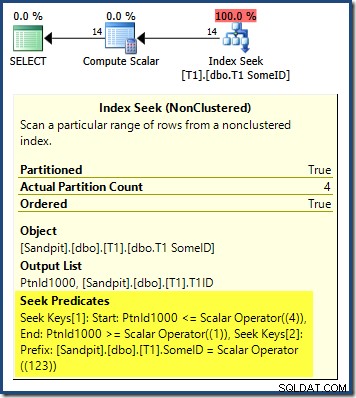
La ricerca della partizione inizia dalla partizione più a destra (4) e procede all'indietro fino alla partizione 1. Potresti pensare che potremmo risolvere il problema ordinando esplicitamente il numero di partizione ASC nel ORDER BY clausola:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Questa query restituisce gli stessi risultati (questo non è un errore di stampa o un errore di copia/incolla):
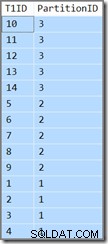
L'ID partizione è ancora in decrescente ordine (non crescente, come specificato) e T1ID viene ordinato solo in ordine crescente all'interno di ciascuna partizione. Tale è la confusione dell'ottimizzatore, pensa davvero (fai un respiro profondo ora) che la scansione dell'indice della chiave iniziale-discendente partizionato in una direzione in avanti, ma con le partizioni invertite, risulterà nell'ordine specificato dalla query.
Non lo biasimo se devo essere sincero, anche le varie considerazioni sull'ordinamento mi fanno male la testa.
Come ultimo esempio, considera:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; I risultati sono:

Di nuovo, il T1ID ordinamento all'interno di ogni partizione è correttamente discendente, ma le partizioni stesse sono elencate all'indietro (va da 1 a 3 lungo le righe). Se le partizioni venissero restituite in ordine inverso, i risultati sarebbero correttamente 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Torna all'unione Unisci
La causa dei risultati errati con la query Unisci join è ora evidente:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
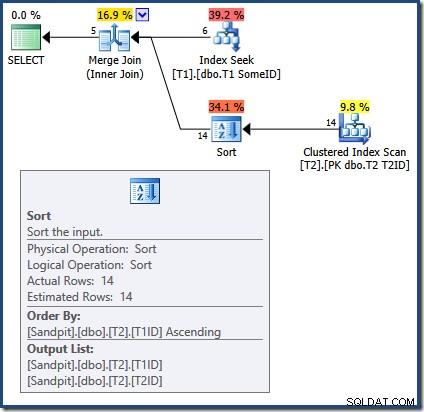
Il Merge Join richiede input ordinati. L'input da T2 è ordinato esplicitamente per T1TD quindi va bene. L'ottimizzatore motiva erroneamente che l'indice su T1 può fornire righe in T1ID ordine. Come abbiamo visto, non è così. Index Seek produce lo stesso output di una query che abbiamo già visto:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Solo le prime 5 righe sono in T1ID ordine. Il valore successivo (5) non è certamente in ordine crescente e Merge Join lo interpreta come end-of-stream piuttosto che produrre un errore (personalmente mi aspettavo un'affermazione al dettaglio qui). Ad ogni modo, l'effetto è che il Merge Join termina in modo errato l'elaborazione in anticipo. Ricordiamo che i risultati (incompleti) sono:

Conclusione
Questo è un bug molto grave a mio avviso. Una semplice ricerca dell'indice può restituire risultati che non rispettano il ORDER BY clausola. Più precisamente, il ragionamento interno dell'ottimizzatore è completamente rotto per indici non cluster partizionati non univoci con una chiave iniziale discendente.
Sì, questo è un leggermente disposizione insolita. Ma, come abbiamo visto, i risultati corretti possono essere improvvisamente sostituiti da risultati errati solo perché qualcuno ha aggiunto un indice discendente. Ricorda che l'indice aggiunto sembrava abbastanza innocente:nessun ASC/DESC esplicito mancata corrispondenza delle chiavi e nessun partizionamento esplicito.
Il bug non è limitato a Unisci join. Potenzialmente qualsiasi query che coinvolge una tabella partizionata e che si basa sull'ordinamento degli indici (esplicito o implicito) potrebbe cadere vittima. Questo bug esiste in tutte le versioni di SQL Server dal 2008 al 2014 CTP 1 incluso. Il database di Windows SQL Azure non supporta il partizionamento, quindi il problema non si pone. SQL Server 2005 utilizzava un modello di implementazione diverso per il partizionamento (basato su APPLY ) e non soffre nemmeno di questo problema.
Se hai un momento, considera di votare il mio articolo Connect per questo bug.
Risoluzione
La correzione di questo problema è ora disponibile e documentata in un articolo della Knowledge Base. Tieni presente che la correzione richiede un aggiornamento del codice e il flag di traccia 4199 , che abilita una serie di altre modifiche a Query Processor. È insolito che un bug con risultati errati venga corretto sotto 4199. Ho chiesto chiarimenti in merito e la risposta è stata:
Anche se questo problema comporta risultati errati come altri hotfix che coinvolgono il processore di query, abbiamo abilitato questa correzione solo con il flag di traccia 4199 per SQL Server 2008, 2008 R2 e 2012. Tuttavia, questa correzione è "attiva" da predefinito senza il flag di traccia in SQL Server 2014 RTM.



