Panoramica
Questo articolo discute due diversi approcci disponibili per rimuovere le righe duplicate dalle tabelle SQL che spesso diventano difficili nel tempo man mano che i dati crescono se ciò non viene eseguito in tempo.
La presenza di righe duplicate è un problema comune che gli sviluppatori SQL ei tester devono affrontare di tanto in tanto, tuttavia, queste righe duplicate rientrano in una serie di categorie diverse di cui parleremo in questo articolo.
Questo articolo si concentra su uno scenario specifico, quando i dati inseriti in una tabella di database portano all'introduzione di record duplicati e quindi esamineremo più da vicino i metodi per rimuovere i duplicati e infine rimuovere i duplicati utilizzando questi metodi.
Preparazione di dati campione
Prima di iniziare a esplorare le diverse opzioni disponibili per rimuovere i duplicati, a questo punto vale la pena creare un database di esempio che ci aiuterà a comprendere le situazioni in cui i dati duplicati si fanno strada nel sistema e gli approcci da utilizzare per eliminarli .
Imposta database di esempio (UniversityV2)
Inizia creando un database molto semplice che consiste solo di uno Studente tabella all'inizio.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Popola la tabella degli studenti
Aggiungiamo solo due record alla tabella Studente:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Controllo dati
Visualizza la tabella che contiene al momento due record distinti:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
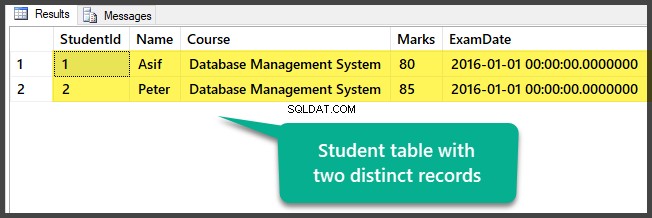
Hai preparato con successo i dati di esempio impostando un database con una tabella e due record distinti (diversi).
Discuteremo ora alcuni potenziali scenari in cui sono stati introdotti ed eliminati duplicati a partire da situazioni semplici o leggermente complesse.
Caso 01:aggiunta e rimozione di duplicati
Ora introdurremo righe duplicate nella tabella Student.
Precondizioni
In questo caso, si dice che una tabella abbia record duplicati se il Nome di uno studente , Corso , Segnali e Data dell'esame coincidono in più record anche se l'ID studente è diverso.
Quindi, assumiamo che due studenti non possano avere lo stesso nome, corso, voti e data d'esame.
Aggiunta di dati duplicati per Student Asif
Inseriamo deliberatamente un record duplicato per Studente:Asif allo Studente tabella come segue:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Visualizza dati studenti duplicati
Visualizza lo Studente tabella per vedere i record duplicati:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
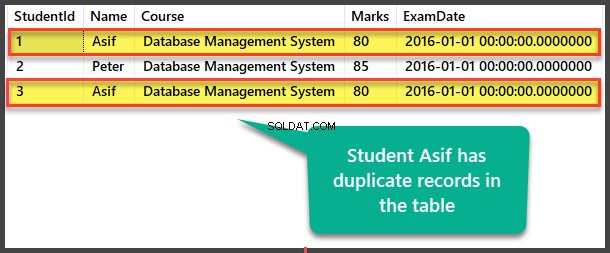
Trovare duplicati con il metodo autoreferenziale
Se ci sono migliaia di record in questa tabella, la visualizzazione della tabella non sarà di grande aiuto.
Nel metodo autoreferenziale, prendiamo due riferimenti alla stessa tabella e li uniamo utilizzando la mappatura colonna per colonna con l'eccezione dell'ID che è reso minore o maggiore dell'altro.
Diamo un'occhiata al metodo autoreferenziale per trovare duplicati che assomigliano a questo:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
L'output dello script precedente ci mostra solo i record duplicati:

Trovare duplicati con il metodo autoreferenziale-2
Un altro modo per trovare i duplicati utilizzando l'autoriferimento è utilizzare INNER JOIN come segue:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Rimozione dei duplicati con il metodo autoreferenziale
Possiamo rimuovere i duplicati usando lo stesso metodo che abbiamo usato per trovare i duplicati con l'eccezione di usare DELETE in linea con la sua sintassi come segue:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Controllo dati dopo la rimozione dei duplicati
Controlliamo rapidamente i record dopo aver rimosso i duplicati:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
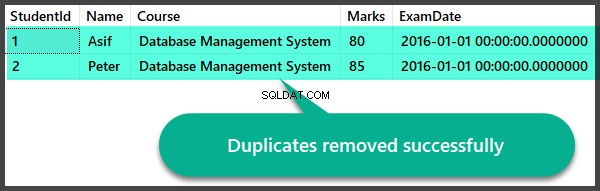
Creazione di duplicati Visualizza e Rimuovi duplicati stored procedure
Ora che sappiamo che i nostri script possono trovare ed eliminare con successo le righe duplicate in SQL, è meglio trasformarle in viste e procedure memorizzate per facilità d'uso:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
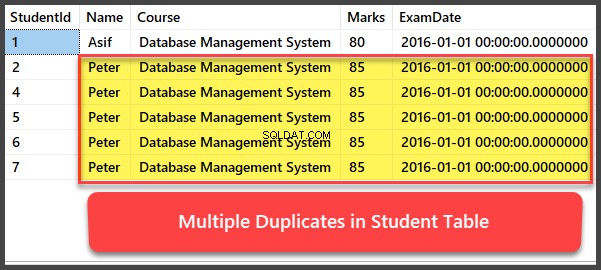
Aggiunta e visualizzazione di più record duplicati
Aggiungiamo ora altri quattro record allo Studente tabella e tutti i record sono duplicati in modo tale da avere lo stesso nome, corso, voti e data d'esame:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Rimozione dei duplicati utilizzando la procedura UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
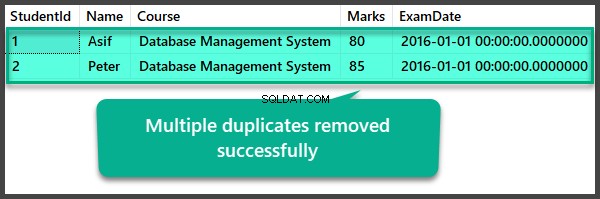
Controllo dei dati dopo la rimozione di più duplicati
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Caso 02:aggiunta e rimozione di duplicati con gli stessi ID
Finora, abbiamo identificato record duplicati con ID distinti, ma cosa succede se gli ID sono gli stessi.
Ad esempio, pensa allo scenario in cui una tabella è stata importata di recente da un file di testo o Excel che non ha una chiave primaria.
Precondizioni
In questo caso, si dice che una tabella abbia record duplicati se tutti i valori delle colonne sono esattamente gli stessi, inclusa una colonna ID e manca la chiave primaria, il che ha semplificato l'immissione dei record duplicati.
Crea tabella del corso senza chiave primaria
Per riprodurre lo scenario in cui record duplicati in assenza di una chiave primaria cadono in una tabella, creiamo prima un nuovo Corso tabella senza alcuna chiave primaria nel database di University2 come segue:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
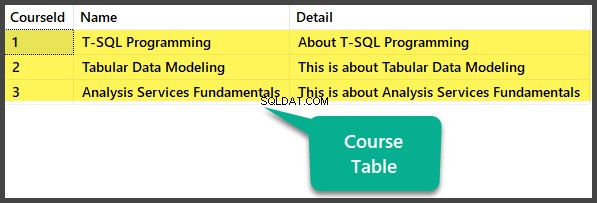
Popola la tabella dei corsi
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Controllo dati
Visualizza il Corso tabella:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Aggiunta di dati duplicati nella tabella del corso
Ora inserisci i duplicati nel Corso tabella:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Visualizza i dati del corso duplicati
Seleziona tutte le colonne per visualizzare la tabella:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

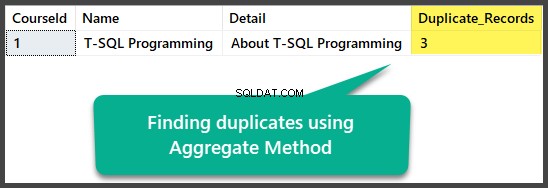
Trovare duplicati con il metodo aggregato
Possiamo trovare duplicati esatti utilizzando il metodo aggregato raggruppando tutte le colonne con un totale di più di una dopo aver selezionato tutte le colonne e contando tutte le righe utilizzando la funzione di conteggio aggregato(*):
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Questo può essere applicato come segue:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Rimozione dei duplicati con il metodo aggregato
Rimuoviamo i duplicati utilizzando il metodo aggregato come segue:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Controllo dati
USA UniversityV2
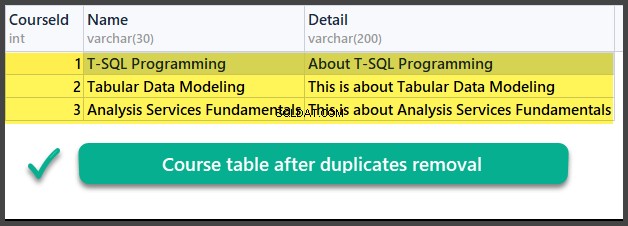
Quindi, abbiamo imparato con successo come rimuovere i duplicati da una tabella di database utilizzando due metodi diversi basati su due diversi scenari.
Cose da fare
Ora puoi facilmente identificare e rimuovere una tabella di database dal valore duplicato.
1. Prova a creare il UspRemoveDuplicatesByAggregate stored procedure in base al metodo sopra menzionato e rimuovere i duplicati chiamando la stored procedure
2. Prova a modificare la stored procedure creata in precedenza (UspRemoveDuplicatesByAggregates) e implementa i suggerimenti per la pulizia menzionati in questo articolo.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Puoi essere sicuro che UspRemoveDuplicatesByAggregate la procedura memorizzata può essere eseguita il maggior numero di volte possibile, anche dopo aver rimosso i duplicati, per dimostrare innanzitutto che la procedura rimane coerente?
4. Fare riferimento al mio articolo precedente Vai a iniziare lo sviluppo di database basato su test (TDDD) - Parte 1 e prova a inserire duplicati nelle tabelle del database SQLDevBlog, dopodiché prova a rimuovere i duplicati utilizzando entrambi i metodi menzionati in questo suggerimento.
5. Prova a creare un altro database di esempio EmployeesSample facendo riferimento al mio precedente articolo Art of Isolating Dependencies and Data in Database Unit Testing e inserisci duplicati nelle tabelle e prova a rimuoverli usando entrambi i metodi che hai imparato da questo suggerimento.
Strumento utile:
dbForge Data Compare per SQL Server – potente strumento di confronto SQL in grado di lavorare con i big data.