Introduzione
È risaputo nei circoli di database che gli indici migliorano le prestazioni delle query soddisfacendo interamente il set di risultati richiesto (indici di copertura) o agendo come ricerche che indirizzano facilmente il motore di query alla posizione esatta del set di dati richiesto. Tuttavia, come sanno i DBA esperti, non si dovrebbe essere troppo entusiasti di creare indici in ambienti OLTP senza comprendere la natura del carico di lavoro. Utilizzando Query Store nell'istanza di SQL Server 2019 (Query Store è stato introdotto in SQL Server 2016), è abbastanza facile mostrare l'effetto di un indice sugli inserimenti.
Inserisci senza indice
Iniziamo ripristinando il database di esempio di WideWorldImporters e quindi creando una copia del Sales. Tabella fatture utilizzando lo script nell'elenco 1. Notare che il database di esempio ha già Query Store abilitato in modalità di lettura-scrittura.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Nota che non ci sono indici nella tabella che abbiamo appena creato. Tutto ciò che abbiamo è la struttura della tabella. Una volta fatto, eseguiamo gli inserimenti nella nuova tabella usando i dati del suo genitore come mostrato nel Listato 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
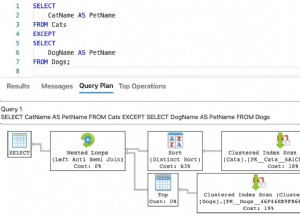
Durante questa operazione, Query Store acquisisce il piano di esecuzione della query. La figura 1 mostra brevemente cosa sta succedendo sotto il cofano. Leggendo da sinistra a destra, vediamo che SQL Server esegue gli inserimenti utilizzando Plan ID 563 – una scansione indice sulla chiave primaria della tabella di origine per recuperare i dati e quindi un inserto tabella sulla tabella di destinazione. (Lettura da sinistra a destra). Osserva che in questo caso, la maggior parte del costo è sull'inserto della tabella:99% del costo della query.
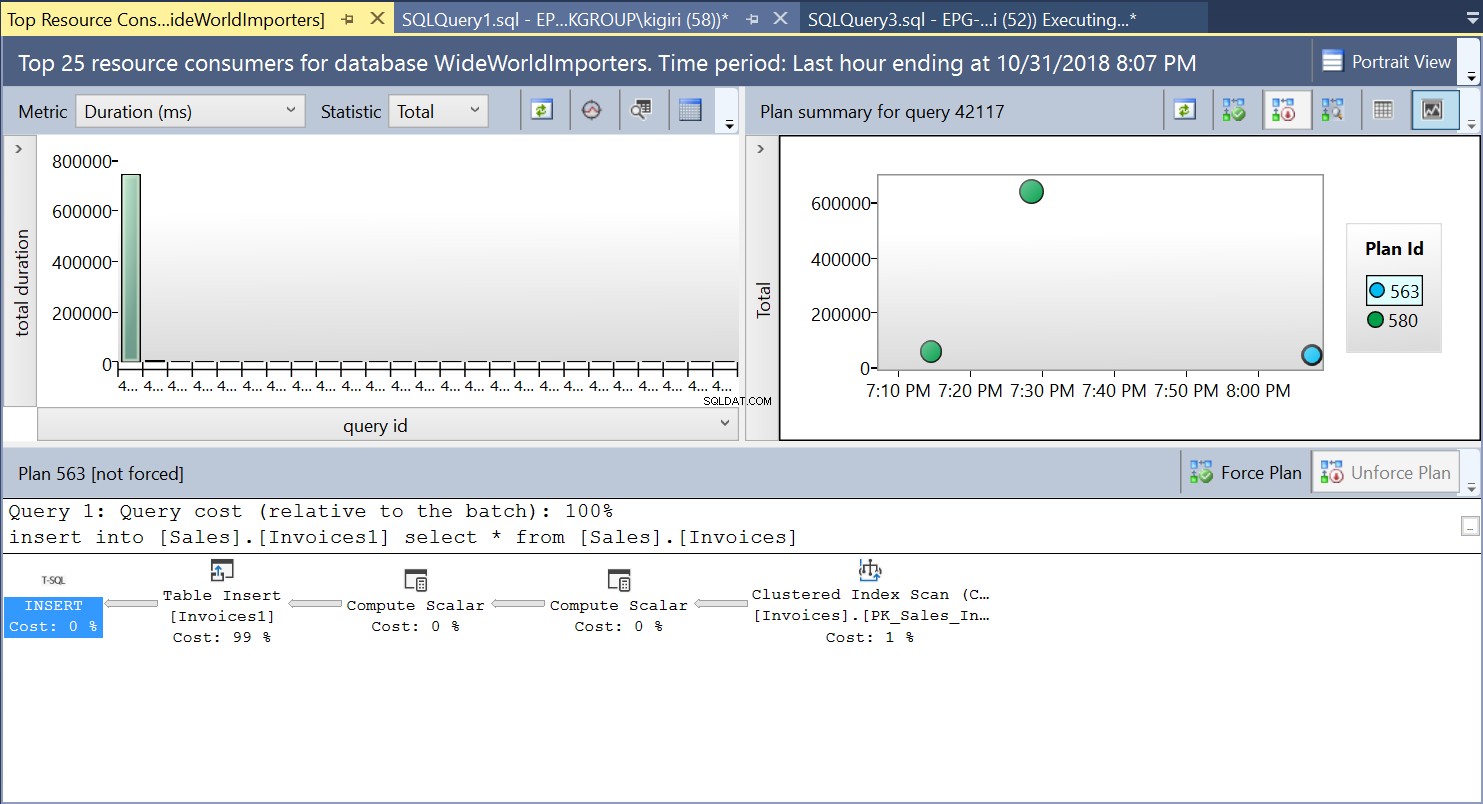
Fig. 1 Piano di esecuzione 563
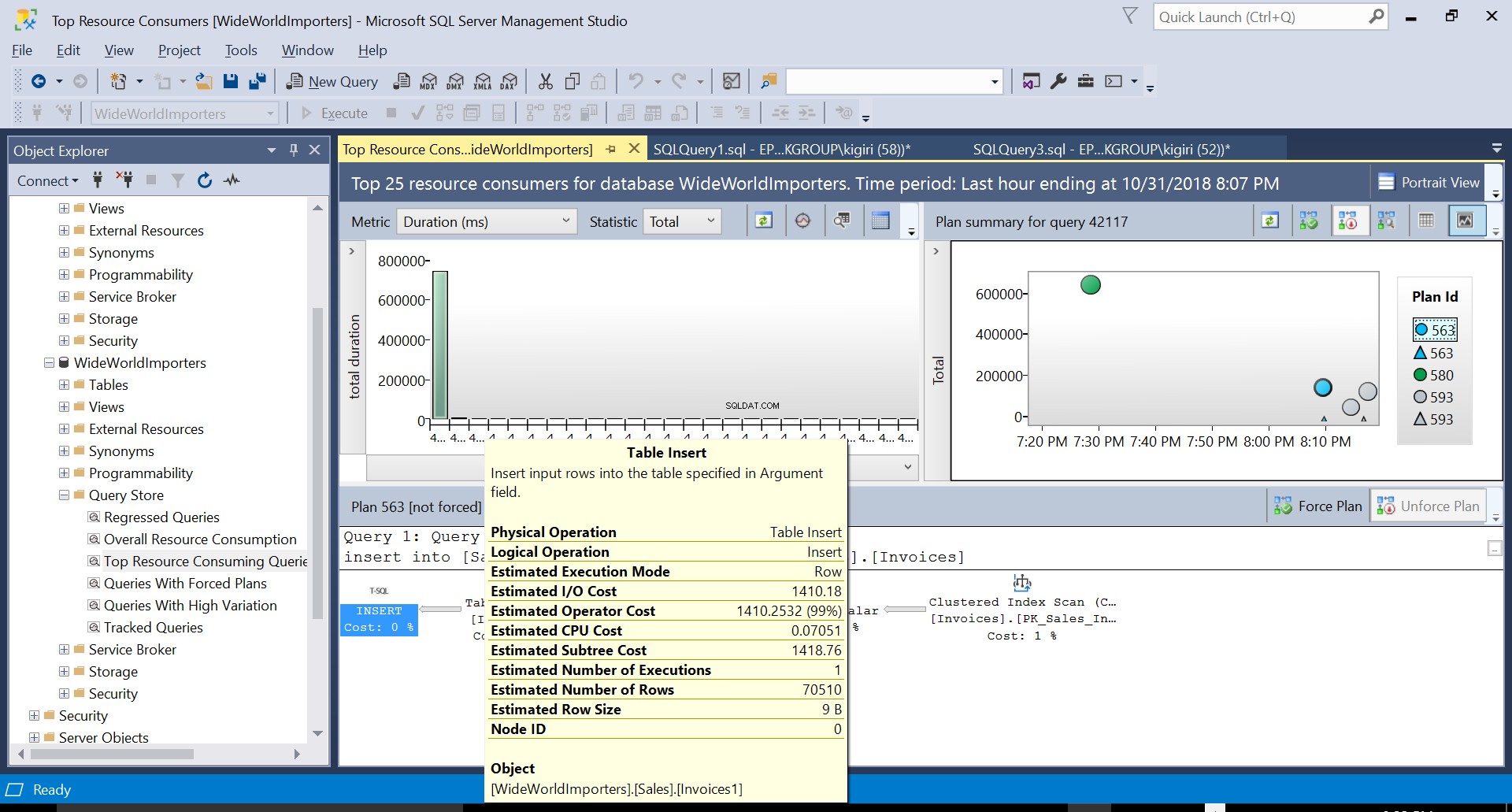
Fig. 2 Inserimento tabella su Destinazione
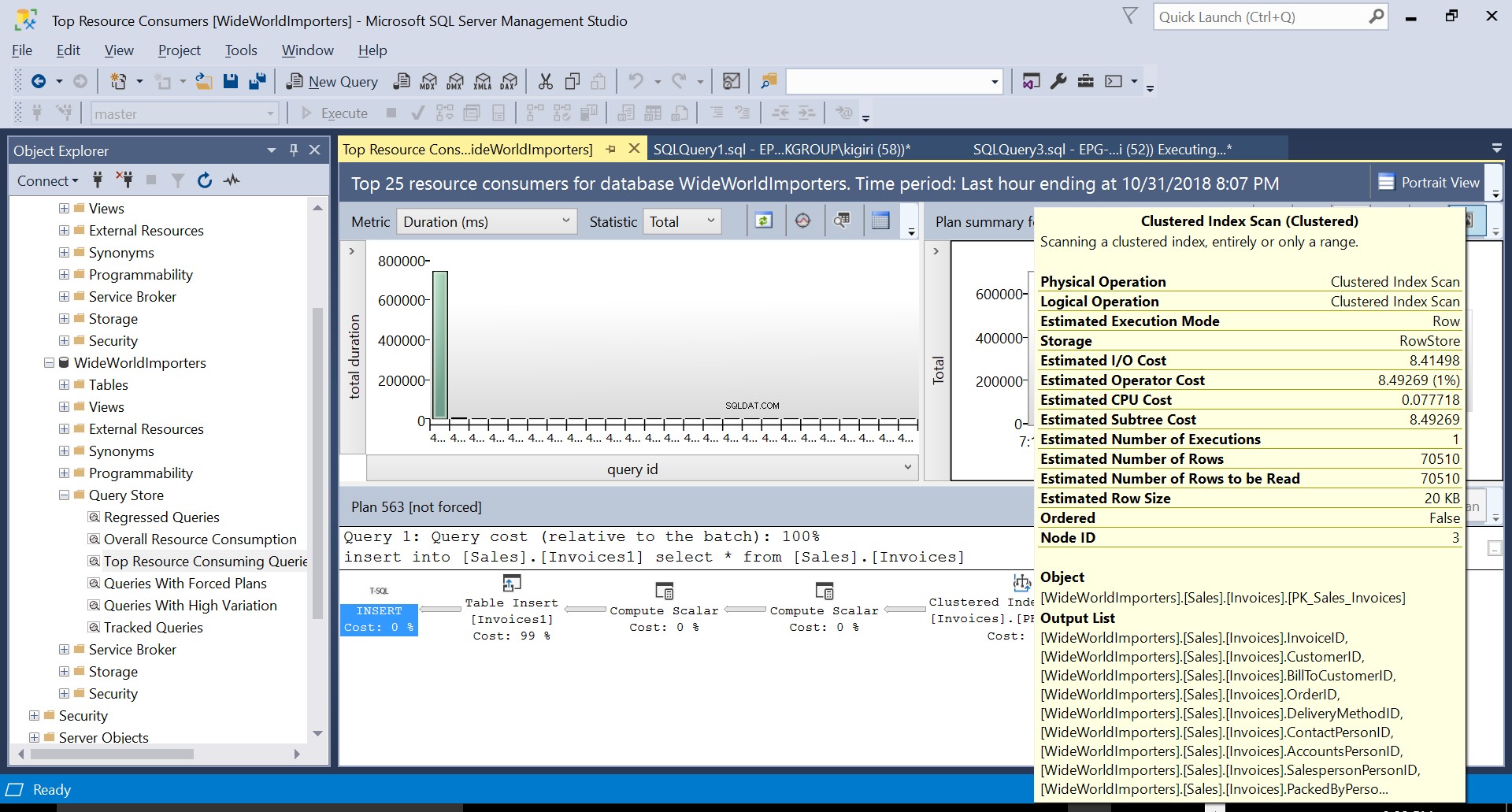
Fig. 3 Scansione indice raggruppata sulla tabella di origine
Inserisci con indice
Creiamo quindi un indice sulla tabella di destinazione utilizzando il DDL nel Listato 3. Quando ripetiamo l'istruzione nel Listato 2 dopo aver troncato la tabella di destinazione, vediamo un piano di esecuzione leggermente diverso (ID piano 593 mostrato in Fig 4). Vediamo ancora l'inserto tabella ma contribuisce solo per il 58% al costo della domanda. Le dinamiche di esecuzione sono leggermente distorte con l'introduzione di un ordinamento e di un inserto indice. In sostanza, SQL Server deve introdurre le righe corrispondenti nell'indice quando vengono introdotti nuovi record nella tabella.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
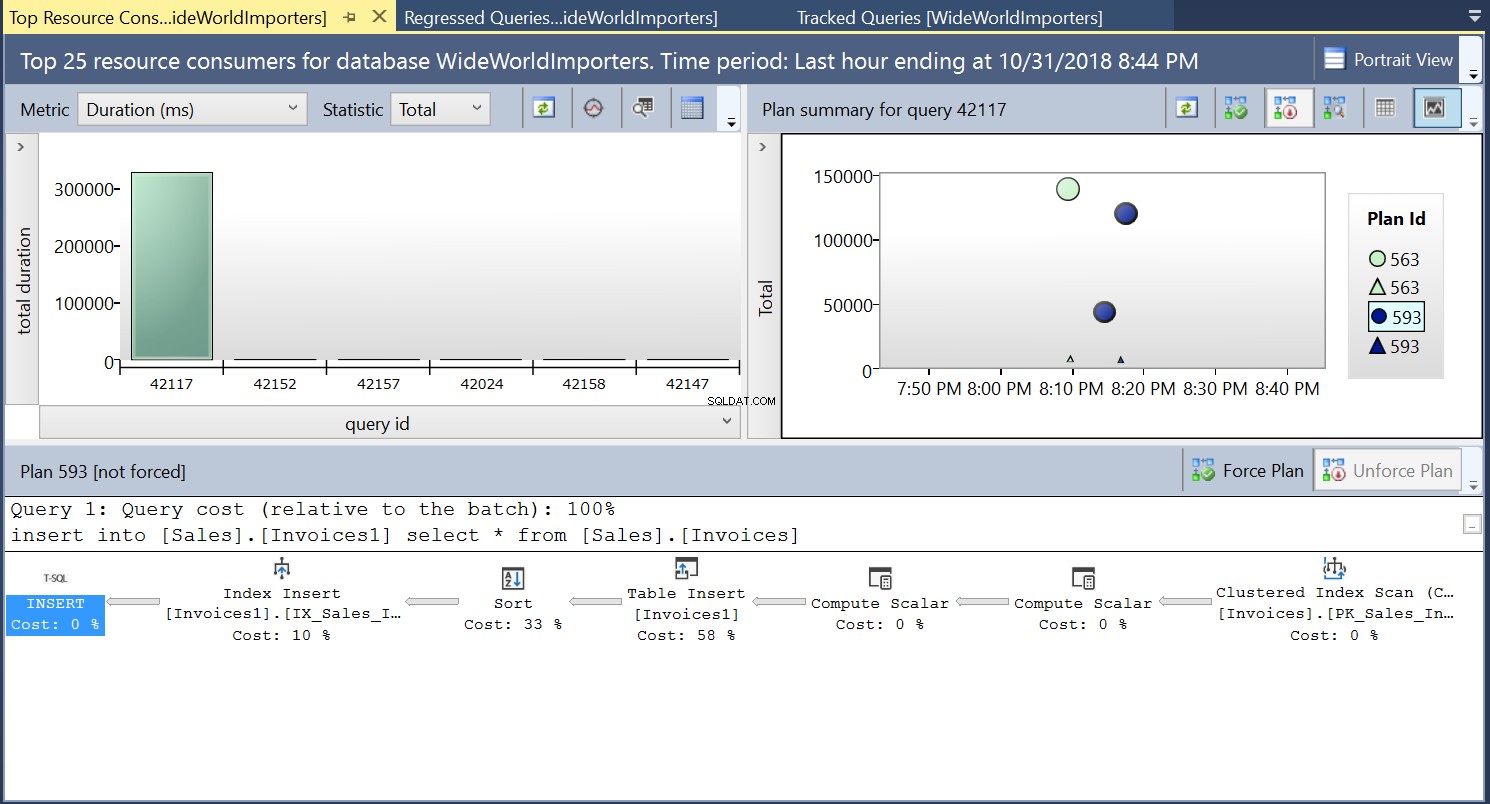
Fig. 4 Piano di esecuzione 593
Guardare più a fondo
Possiamo esaminare i dettagli di entrambi i piani e vedere come questi nuovi fattori aumentano il tempo di esecuzione della dichiarazione. Il piano 593 aggiunge altri 300 ms circa alla durata media dell'istruzione. Con un carico di lavoro intenso in un ambiente di produzione, questa differenza potrebbe essere significativa.
L'attivazione di STATISTICS IO durante l'esecuzione dell'istruzione insert solo una volta in entrambi i casi, con Indice nella tabella di destinazione e senza un indice nella tabella di destinazione, mostra anche che viene svolto più lavoro in termini di IO logico quando si inseriscono righe in una tabella con indici.
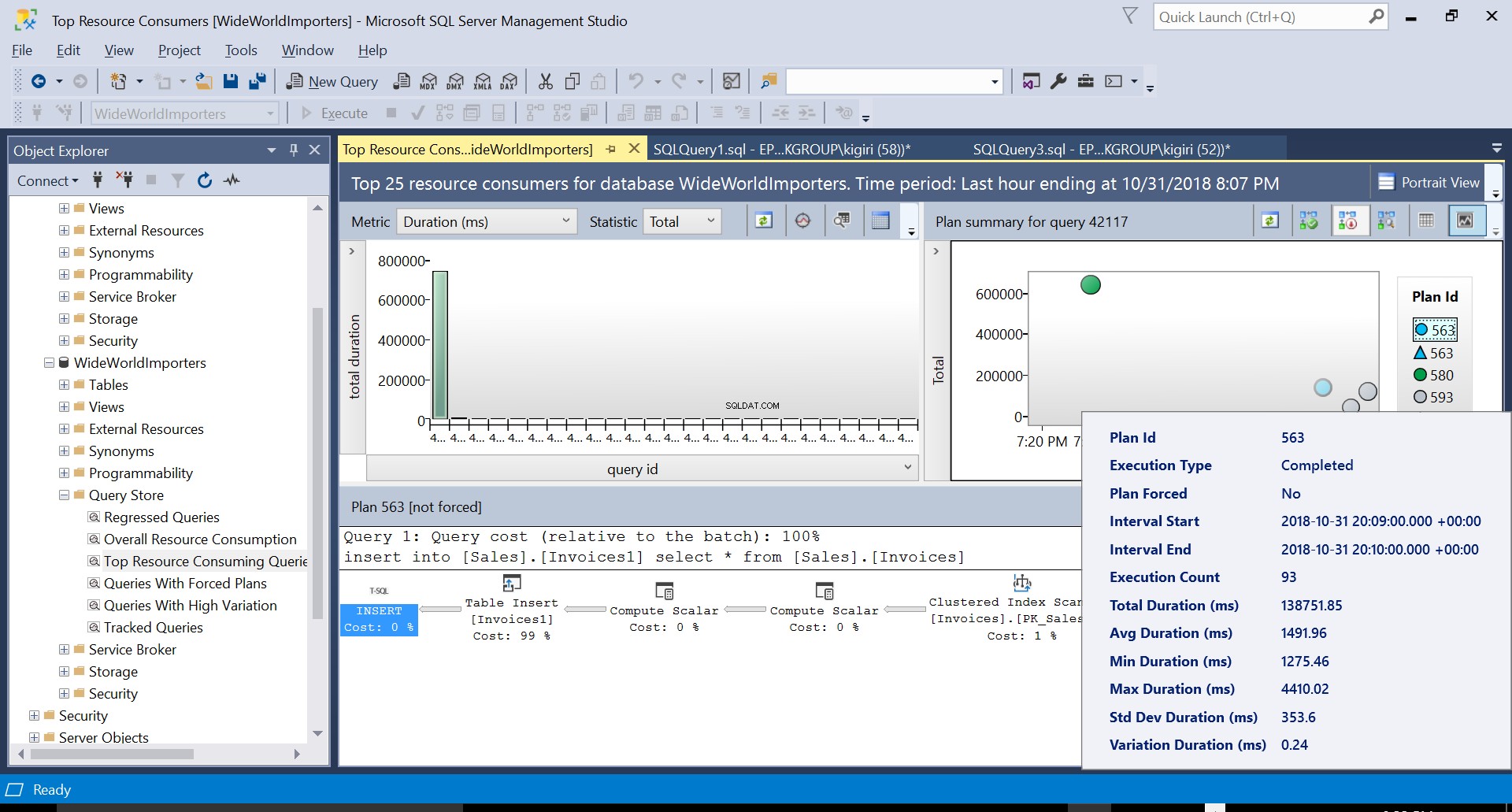
Fig. 5 Dettagli del Piano di Esecuzione 563
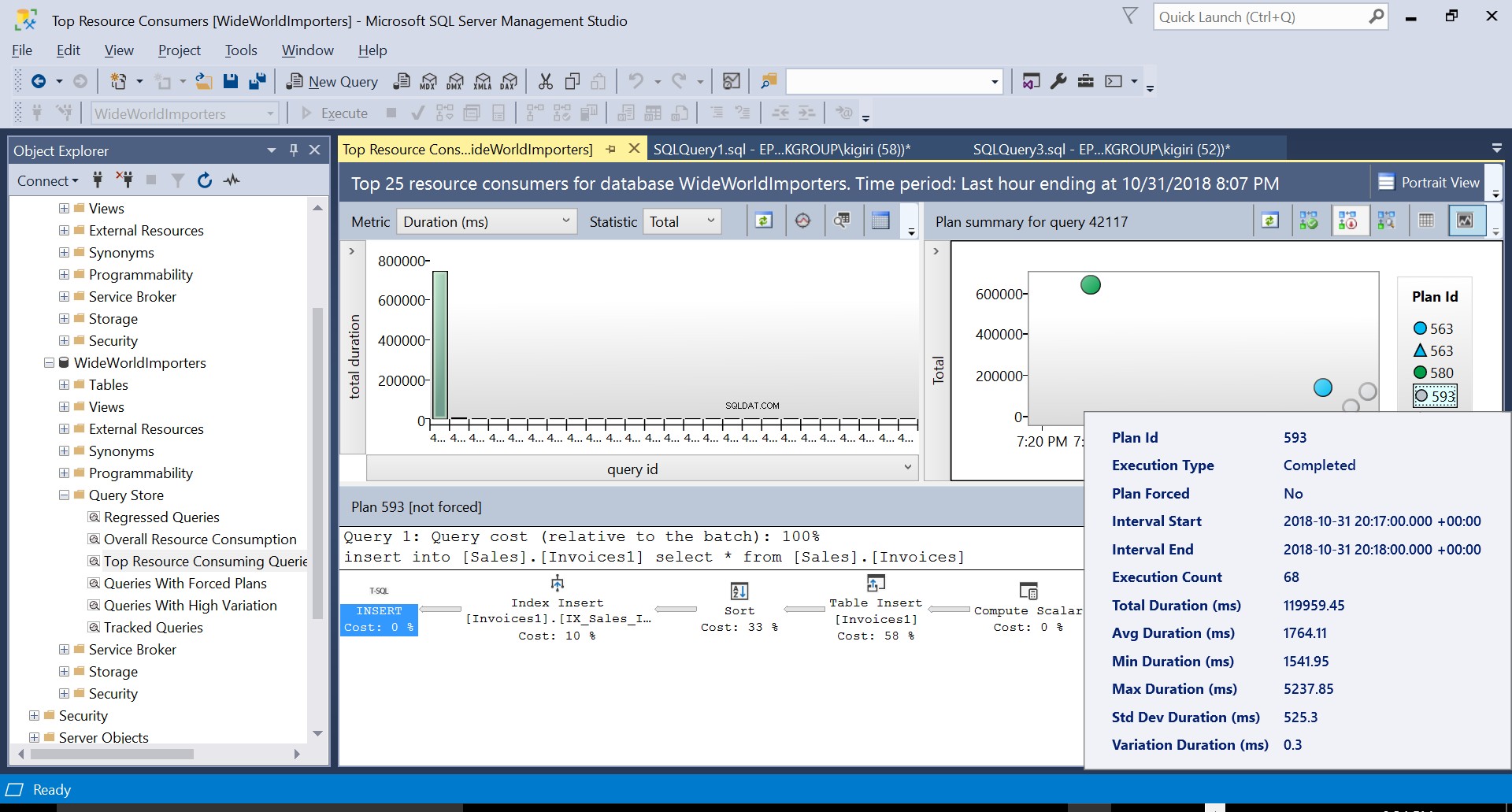
Fig. 4 Dettagli del Piano di Esecuzione 593
Nessun indice:output con STATISTICS IO attivato:
Tabella 'Fatture1'. Conteggio scansioni 0, letture logiche 78372 , letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Fatture'. Conteggio scansioni 1, letture logiche 11400, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
(70510 righe interessate)
Indice:output con STATISTICS IO attivato:
Tabella 'Fatture1'. Conteggio scansioni 0, letture logiche 81119 , letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tavolo 'Tavolo da lavoro'. Conteggio scansioni 0, letture logiche 0, letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
Tabella 'Fatture'. Conteggio scansioni 1, letture logiche 11400 , letture fisiche 0, letture read-ahead 0, letture logiche lob 0, letture fisiche lob 0, letture read-ahead lob 0.
(70510 righe interessate)
Informazioni aggiuntive
Microsoft e altre fonti forniscono script per esaminare l'ambiente di produzione degli indici e identificare situazioni quali:
- Indici ridondanti – Indici duplicati
- Indici mancanti – Indici che potrebbero migliorare le prestazioni in base al carico di lavoro
- Un mucchio – Tabelle senza indici raggruppati
- Tabelle sovraindicizzate – Tabelle con più indici che colonne
- Utilizzo dell'indice – Conteggio di ricerche, scansioni e ricerche sugli indici
Gli elementi 2, 3 e 5 sono più correlati all'impatto sulle prestazioni rispetto alle letture, mentre gli elementi 1 e 4 sono correlati all'impatto sulle prestazioni rispetto alle scritture. Gli elenchi 4 e 5 sono due esempi di queste query disponibili pubblicamente.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Conclusione
Abbiamo dimostrato, utilizzando Query Store, che un carico di lavoro aggiuntivo con un indice può introdurre nel piano di esecuzione di un'istruzione di inserimento di esempio. In produzione, indici eccessivi e ridondanti possono avere un impatto negativo sulle prestazioni, in particolare nei database destinati ai carichi di lavoro OLTP. È importante utilizzare gli script e gli strumenti disponibili per esaminare gli indici e determinare se stanno effettivamente aiutando o danneggiando le prestazioni.
Strumento utile:
dbForge Index Manager – pratico componente aggiuntivo SSMS per analizzare lo stato degli indici SQL e risolvere i problemi con la frammentazione degli indici.