Questo articolo illustra come SQL Server combina le informazioni sulla densità da più statistiche a colonna singola per produrre una stima della cardinalità per un'aggregazione su più colonne. Si spera che i dettagli siano di per sé interessanti. Forniscono inoltre una panoramica di alcuni degli approcci generali e degli algoritmi utilizzati dallo stimatore di cardinalità.
Considera la seguente query di database di esempio AdventureWorks, che elenca il numero di articoli di inventario dei prodotti in ogni collocazione su ogni scaffale del magazzino:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Il piano di esecuzione stimato mostra 1.069 righe lette dalla tabella, ordinate in Shelf e Bin ordine, quindi aggregato utilizzando un operatore Stream Aggregate:
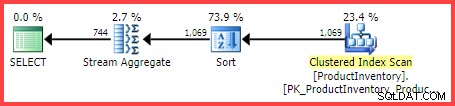
Piano di esecuzione stimato
La domanda è:in che modo Query Optimizer di SQL Server è arrivato alla stima finale di 744 righe?
Statistiche disponibili
Durante la compilazione della query precedente, Query Optimizer creerà statistiche a colonna singola sullo Shelf e Bin colonne, se non esistono già statistiche adeguate. Tra le altre cose, queste statistiche forniscono informazioni sul numero di valori di colonna distinti (nel vettore di densità):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; I risultati sono riassunti nella tabella seguente (la terza colonna è calcolata dalla densità):
| Colonna | Densità | 1 / Densità |
|---|---|---|
| Scaffale | 0.04761905 | 21 |
| Cestino | 0,01612903 | 62 |
Informazioni sui vettori di densità degli scaffali e dei contenitori
Come osserva la documentazione, il reciproco della densità è il numero di valori distinti nella colonna. Dalle informazioni statistiche mostrate sopra, SQL Server sa che c'erano 21 Shelf distinti valori e 62 distinti Bin valori nella tabella, quando sono state raccolte le statistiche.
Il compito di stimare il numero di righe prodotte da un GROUP BY La clausola è banale quando è coinvolta solo una singola colonna (supponendo che non siano presenti altri predicati). Ad esempio, è facile vedere che GROUP BY Shelf produrrà 21 righe; GROUP BY Bin produrrà 62.
Tuttavia, non è immediatamente chiaro come SQL Server possa stimare il numero di (Shelf, Bin) distinti combinazioni per il nostro GROUP BY Shelf, Bin interrogazione. Per porre la domanda in un modo leggermente diverso:dati 21 ripiani e 62 contenitori, quante combinazioni uniche di scaffali e contenitori ci saranno? Lasciando da parte gli aspetti fisici e altre conoscenze umane del dominio del problema, la risposta potrebbe essere ovunque da max(21, 62) =62 a (21 * 62) =1.302. Senza ulteriori informazioni, non esiste un modo ovvio per sapere dove presentare una stima in quell'intervallo.
Tuttavia, per la nostra query di esempio, SQL Server stima 744.312 righe (arrotondate a 744 nella vista Plan Explorer) ma su quale base?
Evento esteso stima della cardinalità
Il modo documentato per esaminare il processo di stima della cardinalità consiste nell'utilizzare l'evento esteso query_optimizer_estimate_cardinality (nonostante sia nel canale "debug"). Durante l'esecuzione di una sessione di raccolta di questo evento, gli operatori del piano di esecuzione ottengono una proprietà aggiuntiva StatsCollectionId che collega le stime dei singoli operatori ai calcoli che le hanno prodotte. Per la nostra query di esempio, l'ID 2 della raccolta delle statistiche è collegato alla stima della cardinalità per il gruppo per operatore aggregato.
L'output rilevante dell'evento esteso per la nostra query di test è:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Ci sono alcune informazioni utili, di sicuro.
Possiamo vedere che la classe calcolatrice di valori distinti della foglia del piano (CDVCPlanLeaf ) è stato utilizzato, utilizzando statistiche a colonna singola su Shelf e Bin come ingressi. L'elemento di raccolta delle statistiche abbina questo frammento all'id (2) mostrato nel piano di esecuzione, che mostra la stima della cardinalità di 744,31 e anche ulteriori informazioni sugli ID oggetto delle statistiche utilizzati.
Sfortunatamente, nell'output dell'evento non c'è nulla che dica esattamente come la calcolatrice sia arrivata alla cifra finale, che è la cosa che ci interessa davvero.
Combinazione di conteggi distinti
Seguendo un percorso meno documentato, possiamo richiedere un piano stimato per la query con flag di traccia 2363 e 3604 abilitati:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Ciò restituisce le informazioni di debug nella scheda Messaggi in SQL Server Management Studio. La parte interessante è riprodotta di seguito:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Questo mostra più o meno le stesse informazioni dell'evento esteso in un formato (probabilmente) più facile da consumare:
- L'operatore relazionale di input per calcolare una stima della cardinalità per (
LogOp_GbAgg– gruppo logico per aggregato) - La calcolatrice utilizzata (
CDVCPlanLeaf) e inserire statistiche - I dettagli della raccolta delle statistiche risultanti
La nuova informazione interessante riguarda la parte sull'utilizzo della cardinalità ambientale per combinare conteggi distinti .
Ciò mostra chiaramente che sono stati utilizzati i valori 21, 62 e 1069, ma (in modo frustrante) non sono ancora esattamente quali calcoli sono stati eseguiti per arrivare al 744.312 risultato.
Al debugger!
L'associazione di un debugger e l'utilizzo di simboli pubblici ci consentono di esplorare in dettaglio il percorso del codice seguito durante la compilazione della query di esempio.
L'istantanea seguente mostra la parte superiore dello stack di chiamate in un punto rappresentativo del processo:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Ci sono alcuni dettagli interessanti qui. Lavorando dal basso verso l'alto, vediamo che la cardinalità viene derivata utilizzando il CE aggiornato (CCardFrameworkSQL12 ) disponibile in SQL Server 2014 e versioni successive (il CE originale è CCardFrameworkSQL7 ), per il gruppo per operatore logico aggregato (CLogOp_GbAgg ).
Il calcolo della cardinalità distinta implica la combinazione (munging) di più input, utilizzando il campionamento senza sostituzione.
Il riferimento a H e un logaritmo (naturale) nel secondo metodo dall'alto mostra l'uso di Shannon Entropy nel calcolo:
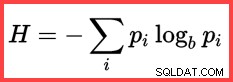
Entropia di Shannon
L'entropia può essere utilizzata per stimare la correlazione informativa (informazione reciproca) tra due statistiche:
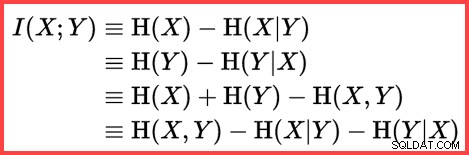
Informazioni reciproche
Mettendo tutto questo insieme, possiamo costruire uno script di calcolo T-SQL che corrisponda al modo in cui SQL Server utilizza il campionamento senza sostituzione, Shannon Entropy e informazioni reciproche per produrre la stima finale della cardinalità.
Iniziamo con i numeri di input (cardinalità ambiente e numero di valori distinti in ogni colonna):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; La frequenza di ogni colonna è il numero medio di righe per valore distinto:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Il campionamento senza sostituzione (SWR) consiste semplicemente nel sottrarre il numero medio di righe per valore distinto (frequenza) dal numero totale di righe:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Calcola le entropie (N log N) e le informazioni reciproche:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Ora che abbiamo stimato quanto sono correlati i due insiemi di statistiche, possiamo calcolare la stima finale:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Il risultato del calcolo è 744.311823994677, che è 744.312 arrotondato al terzo decimale.
Per comodità, ecco l'intero codice in un blocco:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Pensieri finali
La stima finale in questo caso è imperfetta:la query di esempio restituisce effettivamente 441 righe.
Per ottenere una stima migliore, potremmo fornire all'ottimizzatore informazioni migliori sulla densità del Bin e Shelf colonne utilizzando una statistica multicolonna. Ad esempio:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Con quella statistica in atto (come data o come effetto collaterale dell'aggiunta di un indice multicolonna simile), la stima della cardinalità per la query di esempio è esattamente corretta. Tuttavia, è raro calcolare un'aggregazione così semplice. Con predicati aggiuntivi, la statistica multicolonna potrebbe essere meno efficace. Tuttavia, è importante ricordare che le informazioni aggiuntive sulla densità fornite dalle statistiche multicolonna possono essere utili per le aggregazioni (oltre che per i confronti di uguaglianza).
Senza una statistica multicolonna, una query aggregata con predicati aggiuntivi potrebbe comunque essere in grado di utilizzare la logica essenziale illustrata in questo articolo. Ad esempio, invece di applicare la formula alla cardinalità della tabella, può essere applicata per inserire gli istogrammi passo dopo passo.
Contenuti correlati:Stima della cardinalità per un predicato su un'espressione COUNT