Il tipico DBA MySQL potrebbe avere familiarità con il lavoro e la gestione di un database OLTP (Online Transaction Processing) come parte della loro routine quotidiana. Potresti avere familiarità con il suo funzionamento e come gestire operazioni complesse. Sebbene il motore di archiviazione predefinito fornito da MySQL sia abbastanza buono per OLAP (Online Analytical Processing), è piuttosto semplicistico, specialmente per coloro che vorrebbero imparare l'intelligenza artificiale o che si occupano di previsioni, data mining e analisi dei dati.
In questo blog parleremo di MariaDB ColumnStore. Il contenuto sarà personalizzato a vantaggio del DBA MySQL che potrebbe avere meno comprensione con ColumnStore e come potrebbe essere applicabile alle applicazioni OLAP (Online Analytical Processing).
OLTP vs OLAP
OLTP
Risorse correlate Analytics with MariaDB AX - the Open Source Columnar Datastore Introduzione ai database di serie temporali Carichi di lavoro ibridi di database OLTP/analytics nel cluster Galera utilizzando slave asincroniL'attività tipica di MySQL DBA per la gestione di questo tipo di dati è l'utilizzo di OLTP (Online Transaction Processing). OLTP è caratterizzato da transazioni di database di grandi dimensioni che eseguono inserimenti, aggiornamenti o eliminazioni. I database di tipo OLTP sono specializzati per l'elaborazione rapida delle query e il mantenimento dell'integrità dei dati durante l'accesso in più ambienti. La sua efficacia è misurata dal numero di transazioni al secondo (tps). È abbastanza comune che le tabelle di relazione padre-figlio (dopo l'implementazione del modulo di normalizzazione) riducano i dati ridondanti in una tabella.
I record in una tabella vengono comunemente elaborati e archiviati in sequenza in modo orientato alla riga e sono altamente indicizzati con chiavi univoche per ottimizzare il recupero o le scritture dei dati. Questo è comune anche per MySQL, specialmente quando si ha a che fare con inserti di grandi dimensioni o scritture simultanee elevate o inserti di massa. La maggior parte dei motori di archiviazione supportati da MariaDB sono applicabili alle applicazioni OLTP:InnoDB (il motore di archiviazione predefinito dalla 10.2), XtraDB, TokuDB, MyRocks o MyISAM/Aria.
Applicazioni come CMS, FinTech e app Web spesso gestiscono scritture e letture pesanti e richiedono spesso un throughput elevato. Per far funzionare queste applicazioni spesso è necessaria una profonda esperienza in alta disponibilità, ridondanza, resilienza e ripristino.
OLAP
OLAP affronta le stesse sfide di OLTP, ma utilizza un approccio diverso (soprattutto quando si tratta di recupero dati). OLAP gestisce set di dati più grandi ed è comune per il data warehousing, spesso utilizzato per applicazioni di tipo business intelligence. Viene comunemente utilizzato per la gestione delle prestazioni aziendali, la pianificazione, il budget, le previsioni, il reporting finanziario, l'analisi, i modelli di simulazione, l'individuazione della conoscenza e il reporting del data warehouse.
I dati archiviati in OLAP in genere non sono così critici come quelli archiviati in OLTP. Questo perché la maggior parte dei dati può essere simulata proveniente da OLTP e quindi può essere inviata al database OLAP. Questi dati vengono in genere utilizzati per il caricamento in blocco, spesso necessari per l'analisi aziendale che alla fine viene resa in grafici visivi. OLAP esegue anche analisi multidimensionali dei dati aziendali e fornisce risultati che possono essere utilizzati per calcoli complessi, analisi delle tendenze o modelli di dati sofisticati.
OLAP di solito memorizza i dati in modo persistente utilizzando un formato a colonne. In MariaDB ColumnStore, tuttavia, i record sono suddivisi in base alle sue colonne e vengono archiviati separatamente in un file. In questo modo il recupero dei dati è molto efficiente, poiché esegue la scansione solo della colonna pertinente a cui si fa riferimento nella query dell'istruzione SELECT.
Pensala in questo modo, l'elaborazione OLTP gestisce le tue transazioni di dati quotidiane e cruciali che eseguono la tua applicazione aziendale, mentre OLAP ti aiuta a gestire, prevedere, analizzare e commercializzare meglio il tuo prodotto, gli elementi costitutivi di un'applicazione aziendale.
Cos'è MariaDB ColumnStore?
MariaDB ColumnStore è un motore di archiviazione a colonne collegabile che viene eseguito su MariaDB Server. Utilizza un'architettura di dati distribuiti parallelamente mantenendo la stessa interfaccia SQL ANSI utilizzata nel portafoglio di server MariaDB. Questo motore di archiviazione è in circolazione da un po ', poiché è stato originariamente portato da InfiniDB (un codice ora defunto che è ancora disponibile su github). È progettato per il ridimensionamento dei big data (per elaborare petabyte di dati), scalabilità lineare e reale -tempo di risposta alle query di analisi. Sfrutta i vantaggi I/O dell'archiviazione colonnare; compressione, proiezione just-in-time e partizionamento orizzontale e verticale per offrire prestazioni eccezionali durante l'analisi di grandi set di dati.
Infine, MariaDB ColumnStore è la spina dorsale del loro prodotto MariaDB AX come motore di archiviazione principale utilizzato da questa tecnologia.
In che modo MariaDB ColumnStore è diverso da InnoDB?
InnoDB è applicabile per l'elaborazione OLTP che richiede che la tua applicazione risponda nel modo più veloce possibile. È utile se la tua applicazione ha a che fare con quella natura. D'altra parte, MariaDB ColumnStore è una scelta adatta per la gestione di transazioni di big data o set di dati di grandi dimensioni che implicano join complessi, aggregazione a diversi livelli di gerarchia delle dimensioni, proiezione di un totale finanziario per un'ampia gamma di anni o utilizzo di selezioni di uguaglianza e intervallo . Questi approcci che utilizzano ColumnStore non richiedono l'indicizzazione di questi campi, poiché possono funzionare sufficientemente più velocemente. InnoDB non può davvero gestire questo tipo di prestazioni, anche se non c'è modo di impedirti di provarlo come è possibile con InnoDB, ma a un costo. Ciò richiede l'aggiunta di indici, che aggiungono grandi quantità di dati alla memoria su disco. Ciò significa che potrebbe essere necessario più tempo per completare la query e potrebbe non terminare affatto se è intrappolata in un ciclo di tempo.
Architettura ColumnStore di MariaDB
Diamo un'occhiata all'architettura di MariaDB ColumStore di seguito:
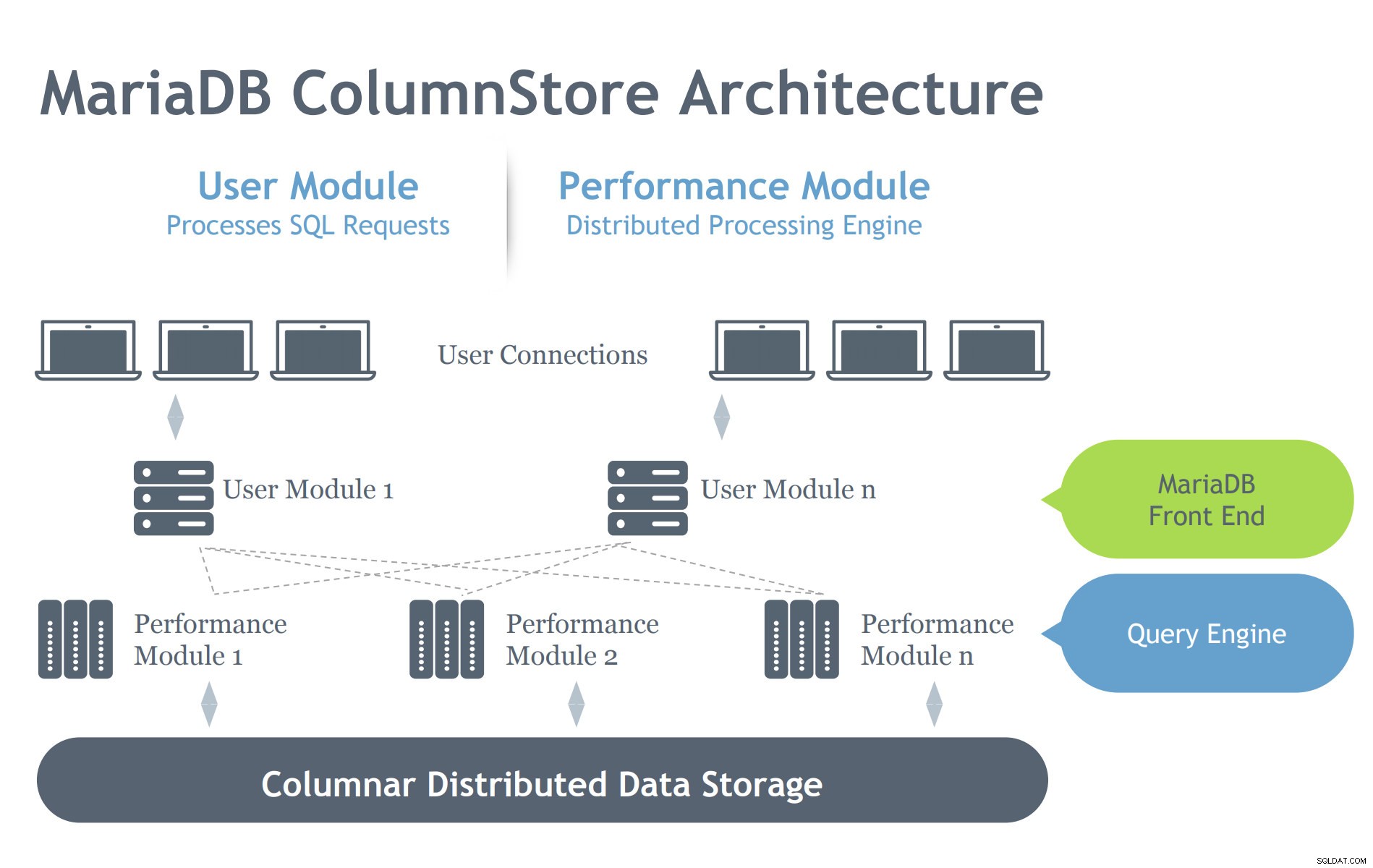 Immagine per gentile concessione della presentazione di MariaDB ColumnStore
Immagine per gentile concessione della presentazione di MariaDB ColumnStore In contrasto con l'architettura InnoDB, ColumnStore contiene due moduli che denota il suo intento è quello di lavorare in modo efficiente su un ambiente architettonico distribuito. InnoDB è destinato alla scalabilità su un server, ma si estende su più nodi interconnessi a seconda della configurazione del cluster. Pertanto, ColumnStore ha più livelli di componenti che si prendono cura dei processi richiesti al server MariaDB. Analizziamo di seguito questi componenti:
- Modulo utente (UM):la messaggistica unificata è responsabile dell'analisi delle richieste SQL in un insieme ottimizzato di fasi di lavoro primitive eseguite da uno o più server PM. La messaggistica unificata è quindi responsabile dell'ottimizzazione delle query e dell'orchestrazione dell'esecuzione delle query da parte dei server PM. Sebbene sia possibile distribuire più istanze di messaggistica unificata in una distribuzione multi-server, una singola messaggistica unificata è responsabile di ogni singola query. È possibile distribuire un servizio di bilanciamento del carico del database, come MariaDB MaxScale, per bilanciare in modo appropriato le richieste esterne rispetto ai singoli server di messaggistica unificata.
- Modulo prestazioni (PM):il PM esegue fasi di lavoro granulari ricevute da una messaggistica unificata in modo multi-thread. ColumnStore consente la distribuzione del lavoro su molti moduli di prestazioni. La messaggistica unificata è composta dal processo MariaDB mysqld e dal processo ExeMgr.
- Mappe estensioni:ColumnStore conserva i metadati su ciascuna colonna in un oggetto distribuito condiviso noto come mappa estensioni. Il server Messaggistica unificata fa riferimento alla mappa estensioni per aiutare a generare le fasi del lavoro primitive corrette. Il server PM fa riferimento all'Extent Map per identificare i blocchi del disco corretti da leggere. Ogni colonna è composta da uno o più file e ogni file può contenere più estensioni. Per quanto possibile, il sistema tenta di allocare memoria fisica contigua per migliorare le prestazioni di lettura.
- Archiviazione:ColumnStore può utilizzare l'archiviazione locale o condivisa (ad es. SAN o EBS) per archiviare i dati. L'utilizzo dell'archiviazione condivisa consente il failover automatico dell'elaborazione dei dati su un altro nodo in caso di guasto di un server PM.
Di seguito è riportato come MariaDB ColumnStore elabora la query,
- I client inviano una query al server MariaDB in esecuzione sul modulo utente. Il server esegue un'operazione di tabella per tutte le tabelle necessarie per soddisfare la richiesta e ottiene il piano di esecuzione della query iniziale.
- Utilizzando l'interfaccia del motore di archiviazione MariaDB, ColumnStore converte l'oggetto tabella del server in oggetti ColumnStore. Questi oggetti vengono quindi inviati ai processi del modulo utente.
- Il modulo utente converte il piano di esecuzione di MariaDB e ottimizza gli oggetti forniti in un piano di esecuzione ColumnStore. Determina quindi i passaggi necessari per eseguire la query e l'ordine in cui devono essere eseguiti.
- Il modulo utente consulta quindi la mappa dell'estensione per determinare quali moduli delle prestazioni consultare per i dati di cui ha bisogno, quindi esegue l'eliminazione dell'estensione, eliminando dall'elenco eventuali moduli delle prestazioni che contengono solo dati al di fuori dell'intervallo di ciò che la query richiede.
- Il modulo utente invia quindi comandi a uno o più moduli prestazioni per eseguire operazioni di I/O a blocchi.
- Il modulo o i moduli delle prestazioni eseguono il filtraggio dei predicati, l'elaborazione dei join, l'aggregazione iniziale dei dati dall'archiviazione locale o esterna, quindi inviano i dati al modulo utente.
- Il modulo utente esegue l'aggregazione del set di risultati finale e compone il set di risultati per la query.
- Il modulo utente / ExeMgr implementa qualsiasi calcolo delle funzioni della finestra, nonché qualsiasi ordinamento necessario sul set di risultati. Quindi restituisce il set di risultati al server.
- Il server MariaDB esegue tutte le funzioni dell'elenco di selezione, le operazioni ORDER BY e LIMIT sul set di risultati.
- Il server MariaDB restituisce il set di risultati al client.
Paradigmi di esecuzione delle query
Esaminiamo un po' di più in che modo ColumnStore esegue la query e quando ha un impatto.
ColumnStore si differenzia dai motori di archiviazione MySQL/MariaDB standard come InnoDB poiché ColumnStore migliora le prestazioni scansionando solo le colonne necessarie, utilizzando il partizionamento gestito dal sistema e utilizzando più thread e server per scalare i tempi di risposta delle query. Le prestazioni sono vantaggiose quando includi solo le colonne necessarie per il recupero dei dati. Ciò significa che l'asterisco avido (*) nella query di selezione ha un impatto significativo rispetto a SELECT
Come con InnoDB e altri motori di archiviazione, anche il tipo di dati ha un significato in termini di prestazioni su ciò che hai utilizzato. Se supponi di avere una colonna che può avere solo valori da 0 a 100, dichiaralo come tinyint poiché verrà rappresentato con 1 byte anziché 4 byte per int. Ciò ridurrà il costo di I/O di 4 volte. Per i tipi di stringa una soglia importante è char(9) e varchar(8) o superiore. Ogni file di archiviazione di colonna utilizza un numero fisso di byte per valore. Ciò consente una rapida ricerca posizionale di altre colonne per formare la riga. Attualmente il limite superiore per l'archiviazione dei dati in colonna è di 8 byte. Quindi, per stringhe più lunghe di questa, il sistema mantiene un'estensione "dizionario" aggiuntiva in cui vengono archiviati i valori. Il file di estensione colonnare memorizza quindi un puntatore nel dizionario. Quindi è più costoso leggere ed elaborare una colonna varchar(8) rispetto ad esempio a una colonna char(8). Quindi, ove possibile, otterrai prestazioni migliori se puoi utilizzare stringhe più brevi, specialmente se eviti la ricerca nel dizionario. Tutti i tipi di dati TEXT/BLOB dalla versione 1.1 in poi utilizzano un dizionario ed eseguono una ricerca in più blocchi da 8 KB per recuperare i dati, se necessario, più lunghi sono i dati, più blocchi vengono recuperati e maggiore è il potenziale impatto sulle prestazioni.
In un sistema basato su righe l'aggiunta di colonne ridondanti si aggiunge al costo complessivo della query, ma in un sistema a colonne si verifica un costo solo se si fa riferimento alla colonna. Pertanto, è necessario creare colonne aggiuntive per supportare percorsi di accesso diversi. Ad esempio, archivia una parte iniziale di un campo in una colonna per consentire ricerche più rapide, ma memorizza inoltre il valore del modulo lungo come un'altra colonna. Le scansioni su un codice più breve o su una colonna della parte iniziale saranno più veloci.
I join di query sono ottimizzati per i join su larga scala ed evitano la necessità di indici e il sovraccarico dell'elaborazione del ciclo nidificato. ColumnStore mantiene le statistiche della tabella in modo da determinare l'ordine di join ottimale. Approcci simili sono condivisi con InnoDB, ad esempio se il join è troppo grande per la memoria di messaggistica unificata, utilizza il join basato su disco per completare la query.
Per le aggregazioni, ColumnStore distribuisce la valutazione aggregata il più possibile. Ciò significa che condivide tra messaggistica unificata e PM per gestire le query in particolare o un numero molto elevato di valori nelle colonne aggregate. Select count(*) è ottimizzato internamente per selezionare il minor numero di byte di archiviazione in una tabella. Ciò significa che selezionerebbe la colonna CHAR(1) (utilizza 1 byte) sulla colonna INT che richiede 4 byte. L'implementazione rispetta ancora la semantica ANSI in quanto select count(*) includerà i null nel conteggio totale invece di una select esplicita (COL-N) che esclude i null nel conteggio.
L'ordine per e il limite sono attualmente implementati alla fine dal processo del server mariadb sulla tabella del set di risultati temporaneo. Questo è stato menzionato nel passaggio n. 9 su come ColumnStore elabora la query. Quindi, tecnicamente, i risultati vengono passati a MariaDB Server per l'ordinamento dei dati.
Per le query complesse che utilizzano sottoquery, è fondamentalmente lo stesso approccio in cui vengono eseguite in sequenza ed è gestito dalla messaggistica unificata, come con le funzioni di Windows sono gestite dalla messaggistica unificata ma utilizza un processo di ordinamento dedicato più veloce, quindi è sostanzialmente più veloce.
Il partizionamento dei dati è fornito da ColumnStore che utilizza Extent Maps che mantiene i valori minimo/massimo dei dati della colonna e fornisce un intervallo logico per il partizionamento ed elimina la necessità di indicizzazione. Extent Maps fornisce anche il partizionamento manuale delle tabelle, viste materializzate, tabelle di riepilogo e altre strutture e oggetti che i database basati su righe devono implementare per le prestazioni delle query. Ci sono alcuni vantaggi per i valori in colonna quando sono in ordine o semi-ordine poiché ciò consente un partizionamento dei dati molto efficace. Con i valori minimo e massimo, verranno eliminate intere mappe di estensione dopo il filtro e l'esclusione. Vedi questa pagina nel loro manuale sull'eliminazione delle estensioni. Questo generalmente funziona particolarmente bene per dati di serie temporali o valori simili che aumentano nel tempo.
Installazione di MariaDB ColumnStore
L'installazione di MariaDB ColumnStore può essere semplice e diretta. MariaDB ha una serie di note qui a cui puoi fare riferimento. Per questo blog, il nostro ambiente di destinazione dell'installazione è CentOS 7. Puoi andare a questo link https://downloads.mariadb.com/ColumnStore/1.2.4/ e controllare i pacchetti in base al tuo ambiente OS. Consulta i passaggi dettagliati di seguito per accelerare:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
Una volta terminato, devi eseguire postConfigure comando per installare e configurare finalmente il tuo MariaDB ColumnStore. In questa installazione di esempio, ci sono due nodi che ho configurato in esecuzione su una macchina vagabondo:
csnode1:192.168.2.10
csnode2:192.168.2.20
Entrambi questi nodi sono definiti nei rispettivi /etc/hosts ed entrambi i nodi sono impostati per avere i suoi moduli utente e prestazioni combinati in entrambi gli host. L'installazione è un po' banale all'inizio. Quindi, condividiamo come puoi configurarlo in modo da poter avere una base. Vedere i dettagli di seguito per il processo di installazione di esempio:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Al termine dell'installazione e della configurazione, MariaDB creerà una configurazione master/slave per questo, quindi qualsiasi cosa abbiamo caricato da csnode1, verrà replicata in csnode2.
Scarica i tuoi Big Data
Dopo l'installazione, potresti non avere dati di esempio da provare. IMDB ha condiviso un campione di dati che puoi scaricare sul loro sito https://www.imdb.com/interfaces/. Per questo blog, ho creato uno script che fa tutto per te. Dai un'occhiata qui https://github.com/paulnamuag/columnstore-imdb-data-load. Basta renderlo eseguibile, quindi eseguire lo script. Farà tutto per te scaricando i file, creando lo schema, quindi caricando i dati nel database. È così semplice.
Esecuzione delle tue query di esempio
Ora, proviamo a eseguire alcune query di esempio.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Fondamentalmente, è più veloce e veloce. Ci sono query che non puoi elaborare come esegui con altri motori di archiviazione, come InnoDB. Ad esempio, ho provato a giocare e fare alcune domande stupide e vedere come reagisce e il risultato è:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Quindi, ho trovato MCOL-1620 e MCOL-131 e punta all'impostazione della variabile infinidb_vtable_mode. Vedi sotto:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Ma impostando infinitdb_vtable_mode=0 , il che significa che tratta la query come una modalità di elaborazione riga per riga generica e altamente compatibile. Alcuni componenti della clausola WHERE possono essere elaborati da ColumnStore, ma i join vengono elaborati interamente da mysqld utilizzando un meccanismo di join a ciclo nidificato. Vedi sotto:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Ci è voluto del tempo perché spiega che è stato elaborato interamente da mysqld. Tuttavia, l'ottimizzazione e la scrittura di buone query resta l'approccio migliore e non delegare tutto a ColumnStore.
Inoltre, hai dell'aiuto per analizzare le tue query eseguendo comandi come SELECT calSetTrace(1); o SELECT calGetStats(); . È possibile utilizzare questi set di comandi, ad esempio, ottimizzare le query basse e non valide o visualizzare il relativo piano di query. Dai un'occhiata qui per maggiori dettagli sull'analisi delle query.
Amministrazione ColumnStore
Dopo aver configurato completamente MariaDB ColumnStore, viene fornito con il suo strumento chiamato mcsadmin per il quale è possibile utilizzare per eseguire alcune attività amministrative. Puoi anche utilizzare questo strumento per aggiungere un altro modulo, assegnare o passare a DBroots da PM a PM, ecc. Consulta il loro manuale su questo strumento.
Fondamentalmente, puoi fare quanto segue, ad esempio, controllando le informazioni di sistema:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Conclusione
MariaDB ColumnStore è un motore di archiviazione molto potente per il tuo OLAP e l'elaborazione di big data. Questo è interamente open source ed è molto vantaggioso da usare rispetto all'utilizzo di database OLAP proprietari e costosi disponibili sul mercato. Tuttavia, ci sono altre alternative da provare come ClickHouse, Apache HBase o cstore_fdw di Citus Data. Tuttavia, nessuno di questi utilizza MySQL/MariaDB, quindi potrebbe non essere la tua opzione praticabile se scegli di attenersi alle varianti MySQL/MariaDB.