Nel nostro precedente blog sulle dashboard SCUMM, abbiamo esaminato la dashboard panoramica di MySQL. La nuova versione di ClusterControl (ver. 1.7) offre una serie di grafici ad alta risoluzione di metriche utili e abbiamo esaminato il significato di ciascuna metrica e come aiutano a risolvere i problemi del database. In questo blog, esamineremo la dashboard di MySQL Replication. Procediamo con i dettagli di questa dashboard su ciò che ha da offrire.
Dashboard Replica MySQL
MySQL Replication Dashboard offre un set di grafici molto semplice che semplifica il monitoraggio del master e delle repliche MySQL. Partendo dall'alto, mostra le variabili e le informazioni più importanti per determinare lo stato di salute delle repliche o anche del master. Questa dashboard offre una parte molto utile durante l'ispezione dello stato di salute degli slave o di un master nella configurazione master-master. Si può anche controllare su questa dashboard la creazione del log binario del master e determinare la dimensione complessiva, in termini di dimensione generata, in un determinato periodo di tempo.
La prima cosa in questa dashboard, ti presenta le informazioni più importanti di cui potresti aver bisogno con l'integrità della tua replica. Vedi il grafico qui sotto:

Fondamentalmente, ti mostrerà IO_Thread, SQL_Thread, errore di replica del thread Slave e se ha abilitato la variabile di sola lettura. Dallo screenshot di esempio sopra, tutte le informazioni mostrano che il mio slave 192.168.70.20 è integro e funziona normalmente.
Inoltre, ClusterControl ha anche informazioni da raccogliere se si passa a Cluster -> Panoramica. Scorri verso il basso e puoi vedere il grafico qui sotto:
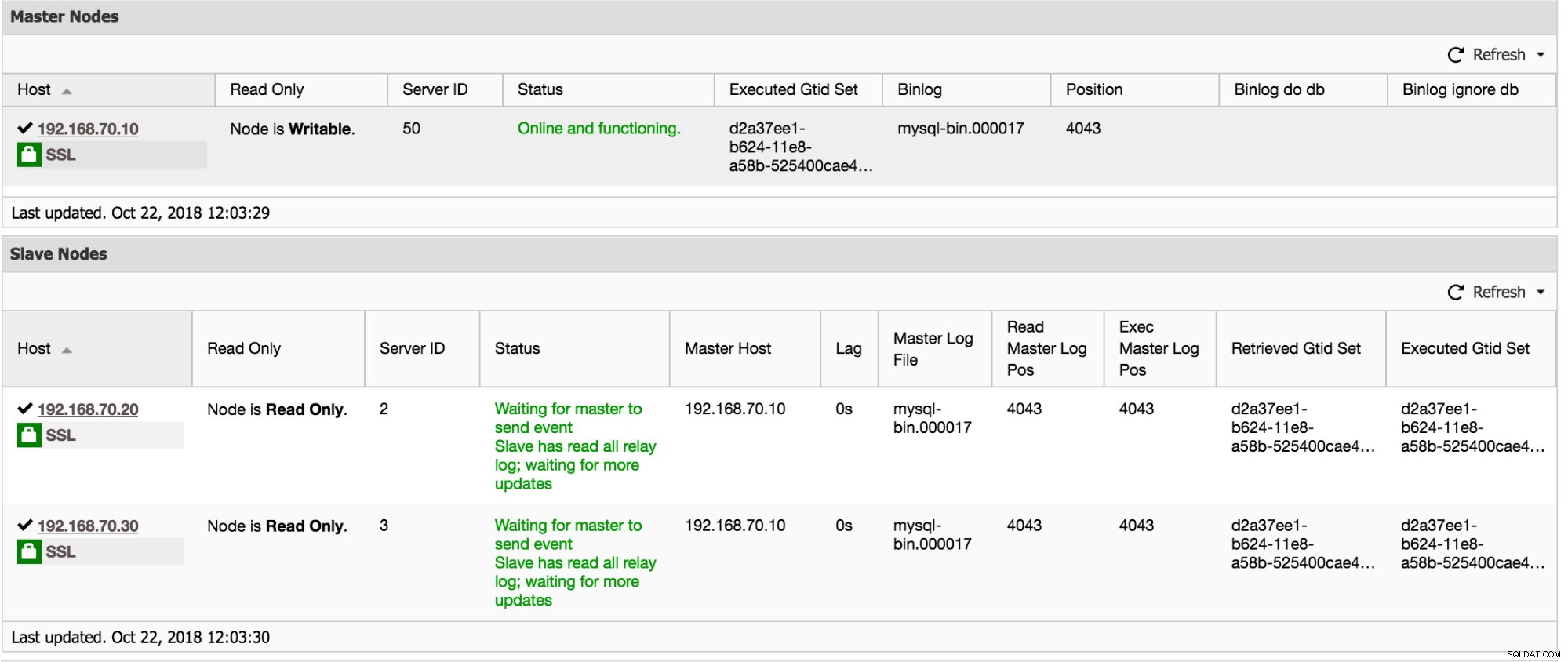
Un'altra posizione per visualizzare l'impostazione della replica è la visualizzazione della topologia dell'impostazione della replica, accessibile da Cluster -> Topologia. Fornisce, a una rapida occhiata, una vista dei diversi nodi nella configurazione, i loro ruoli, il ritardo di replica, il GTID recuperato e altro ancora. Vedi il grafico qui sotto:
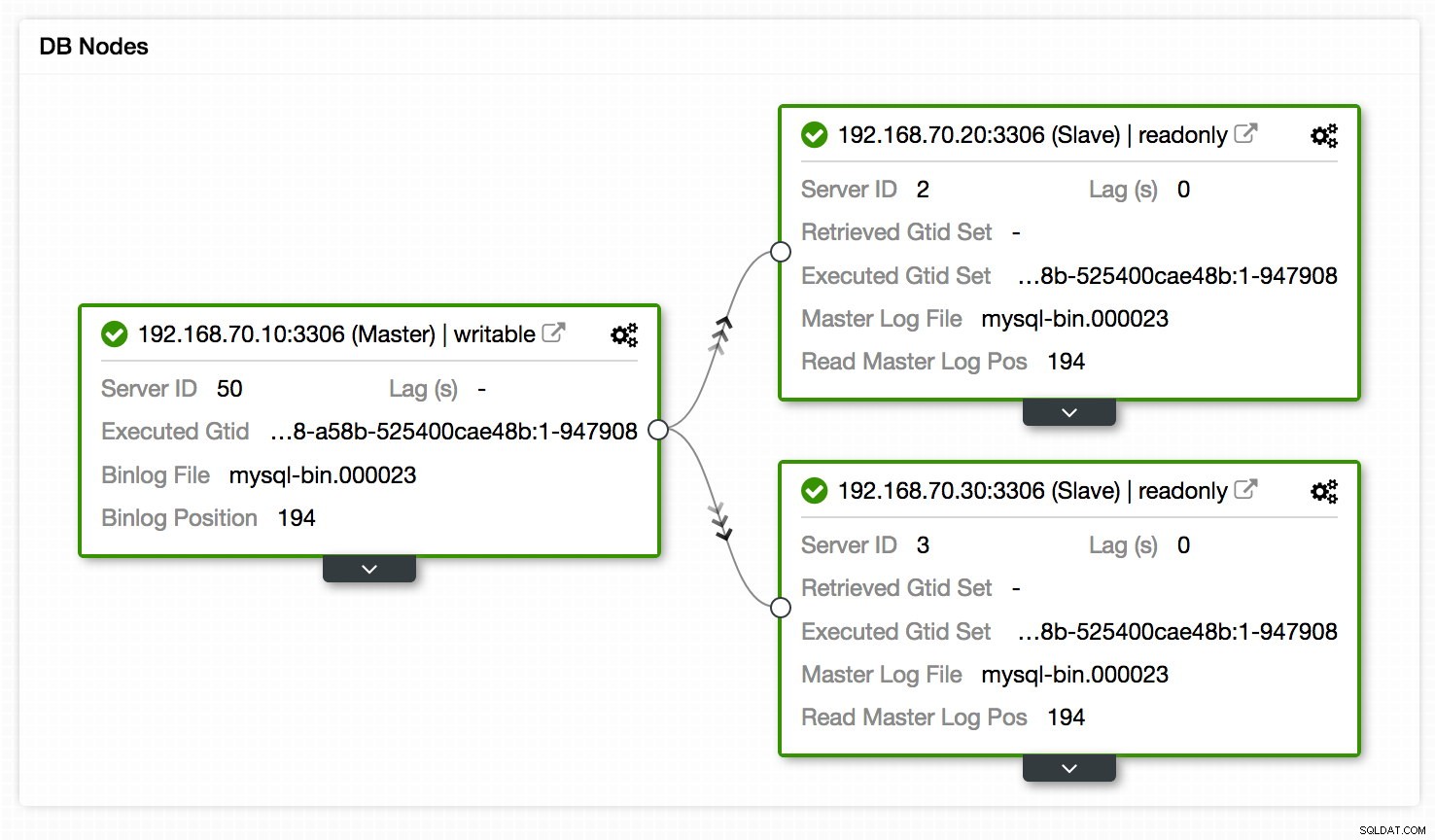
Oltre a ciò, la visualizzazione della topologia mostra anche tutti i diversi nodi che fanno parte del cluster del database, siano essi i nodi del database, i bilanciatori del carico (ProxySQL/MaxScale/HaProxy) o gli arbitri (garbd), nonché le connessioni tra di essi. I nodi, le connessioni e i relativi stati vengono rilevati da ClusterControl. Poiché ClusterControl monitora continuamente i nodi e conserva le informazioni sullo stato, qualsiasi modifica alla topologia si riflette nell'interfaccia Web. In caso di guasto dei nodi vengono segnalati, è possibile utilizzare questa visualizzazione insieme alle dashboard SCUMM e vedere quale impatto potrebbe averlo causato.
La visualizzazione della topologia presenta alcune somiglianze con Orchestrator in cui è possibile gestire i nodi, modificare i master trascinando e rilasciando l'oggetto sul master desiderato, riavviare i nodi e sincronizzare i dati. Per saperne di più sulla nostra Topology View, ti suggeriamo di leggere il nostro blog precedente - "Visualizing your Cluster Topology in ClusterControl".
Procediamo ora con i grafici.
-
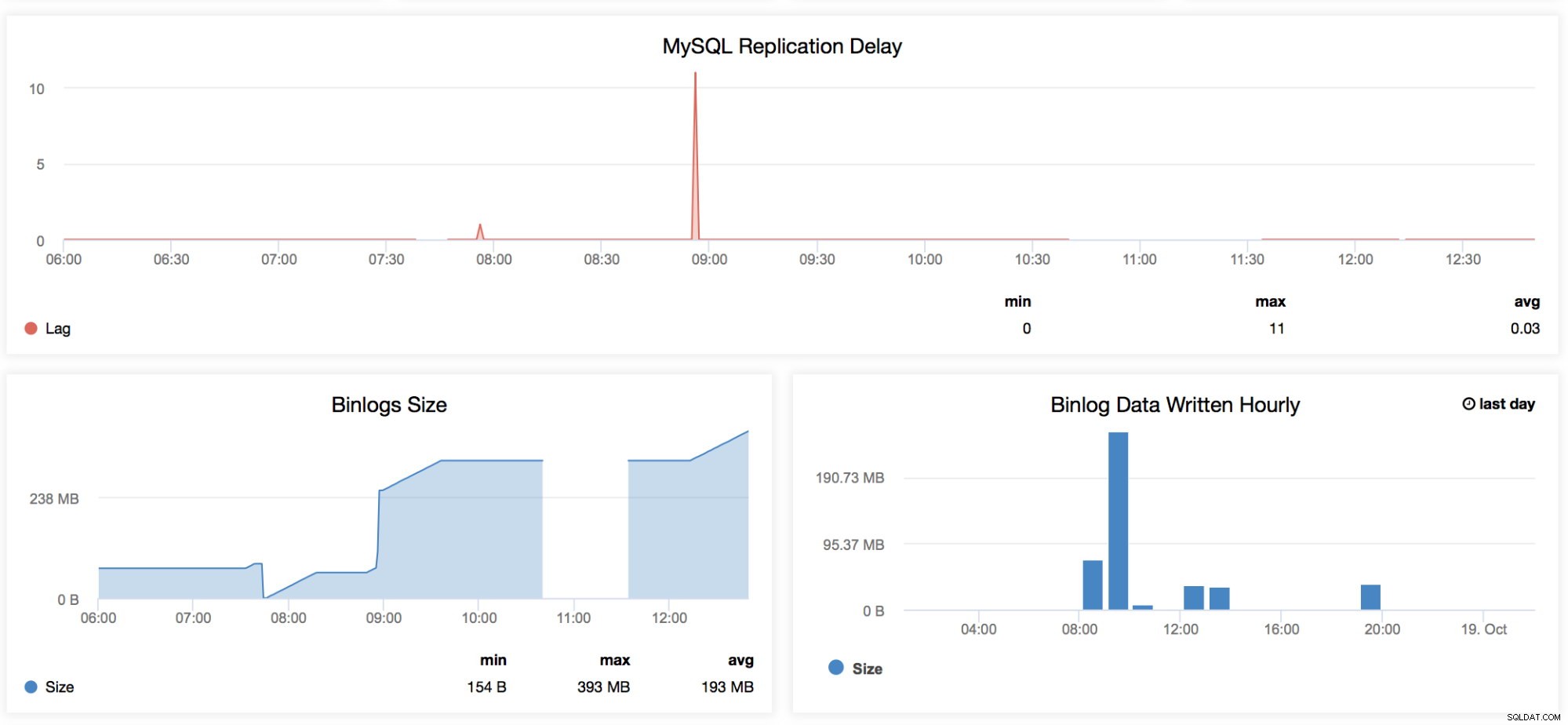
MySQL Replication Delay
Questo grafico è molto familiare a chiunque gestisca MySQL, in particolare a coloro che lavorano quotidianamente sulla propria configurazione master-slave. Questo grafico presenta le tendenze per tutti i ritardi registrati per un intervallo di tempo specifico specificato in questo dashboard. Ogni volta che vogliamo controllare il tempo di caduta periodico che ha la nostra replica, allora questo grafico è buono da guardare. Ci sono alcune occasioni in cui una replica potrebbe rimanere in ritardo per strani motivi come il tuo RAID ha una BBU degradata e necessita di una sostituzione, una tabella non ha una chiave univoca ma non sul master, una scansione completa della tabella indesiderata o una scansione completa dell'indice o una query errata è stato lasciato in esecuzione da uno sviluppatore. Questo è anche un buon indicatore per determinare se lo slave lag è un problema chiave, quindi potresti voler sfruttare la replica parallela. -
Binlog Size
Questi grafici sono correlati tra loro. Il grafico Binlog Size mostra come il tuo nodo genera il log binario e aiuta a determinarne la dimensione in base al periodo di tempo in cui stai scansionando. -
Dati Binlog scritti ogni ora
I dati Binlog scritti ogni ora sono un grafico basato sul giorno corrente e sul giorno precedente registrato. Questo potrebbe essere utile ogni volta che desideri identificare la dimensione del tuo nodo che accetta scritture, che puoi utilizzare in seguito per la pianificazione della capacità.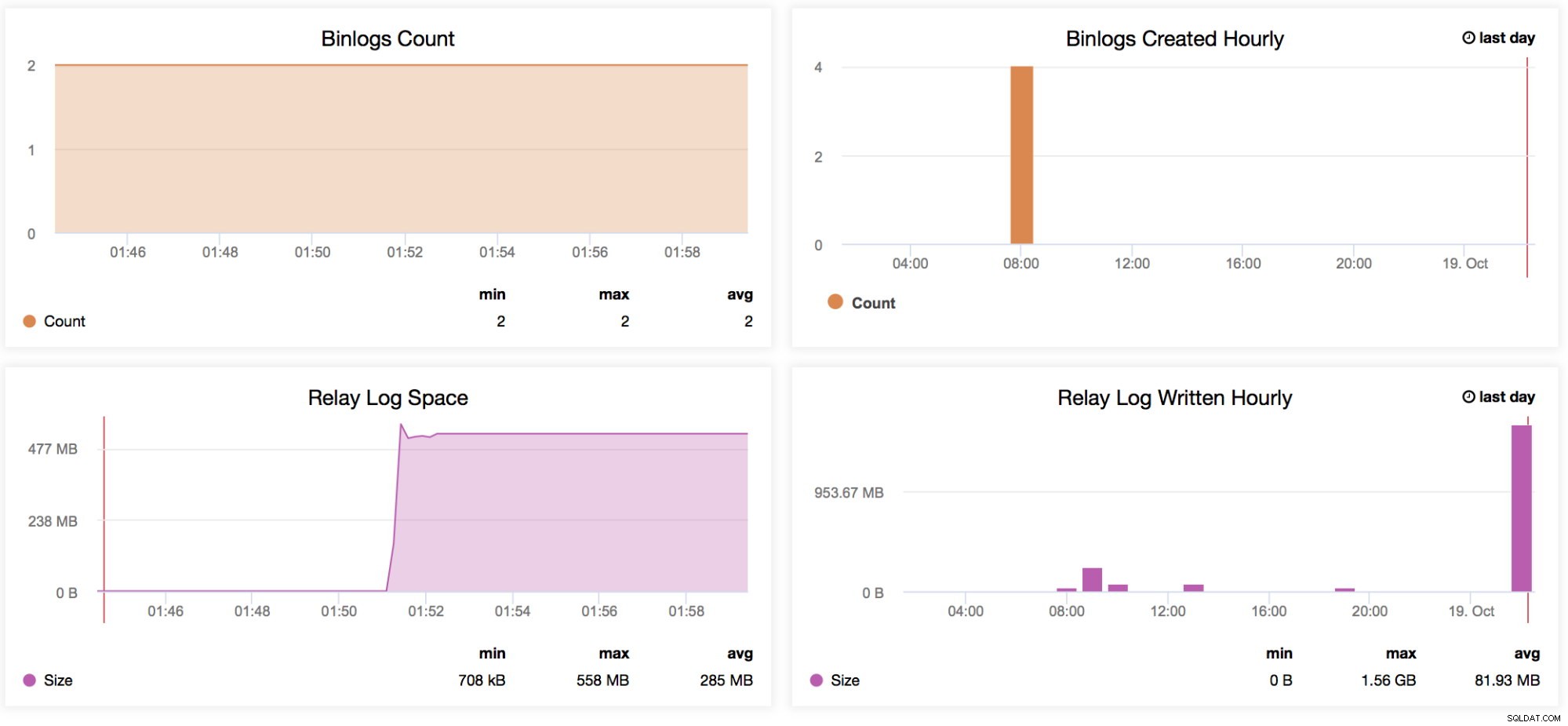
-
Conteggio binlog
Supponiamo che ti aspetti un traffico elevato per una determinata settimana. Vuoi confrontare quanto grandi scritture stanno passando attraverso il tuo master e slave con la settimana precedente. Questo grafico è molto utile per questo tipo di situazione - Per determinare quanto erano alti i log binari generati sul master stesso o anche sugli slave se la variabile log_slave_updates è abilitata. Puoi anche utilizzare questo indicatore per determinare i tuoi dati di log binari master vs slave generati, specialmente se stai filtrando alcune tabelle o schemi (replicate_ignore_db, replicate_ignore_table, replicate_wild_do_table) sui tuoi slave che sono stati generati mentre log_slave_updates è abilitato. -
Binlog creati ogni ora
Questo grafico è una rapida panoramica per confrontare la creazione dei binlog ogni ora tra ieri e la data odierna. -
Spazio del registro di inoltro
Questo grafico funge da base per i registri di inoltro generati dalla replica. Se utilizzato insieme al grafico MySQL Replication Delay, aiuta a determinare quanto è grande il numero di log di inoltro generati, che l'amministratore deve considerare in termini di disponibilità del disco della replica corrente. Può causare problemi quando il tuo slave è rigorosamente in ritardo e sta generando un gran numero di registri di inoltro. Questo può consumare rapidamente lo spazio su disco. Ci sono alcune situazioni in cui, a causa di un numero elevato di scritture dal master, lo slave/la replica subirà un enorme ritardo, quindi la generazione di una grande quantità di log può causare alcuni seri problemi su quella replica. Questo può aiutare il team operativo quando parla con la propria direzione della pianificazione della capacità. -
Registro di inoltro scritto ogni ora
Uguale allo spazio del registro di inoltro, ma aggiunge una rapida panoramica per confrontare i registri di inoltro scritti da ieri e dalla data odierna.
Conclusione
Hai imparato che l'utilizzo di SCUMM per monitorare la tua replica MySQL aggiunge maggiore produttività ed efficienza al team operativo. Usare le funzionalità delle versioni precedenti combinate con i grafici forniti con SCUMM è come andare in palestra e vedere enormi miglioramenti nella tua produttività. Questo è ciò che SCUMM può offrire:monitoraggio con steroidi! (ora, non stiamo sostenendo che dovresti prendere steroidi quando vai in palestra!)
Nella parte 3 di questo blog, parlerò di InnoDB Metrics e MySQL Performance Schema Dashboards.