ProxySQL si trova comunemente tra i livelli dell'applicazione e del database, nel cosiddetto livello proxy inverso. Quando i contenitori delle tue applicazioni sono orchestrati e gestiti da Kubernetes, potresti voler utilizzare ProxySQL davanti ai tuoi server di database.
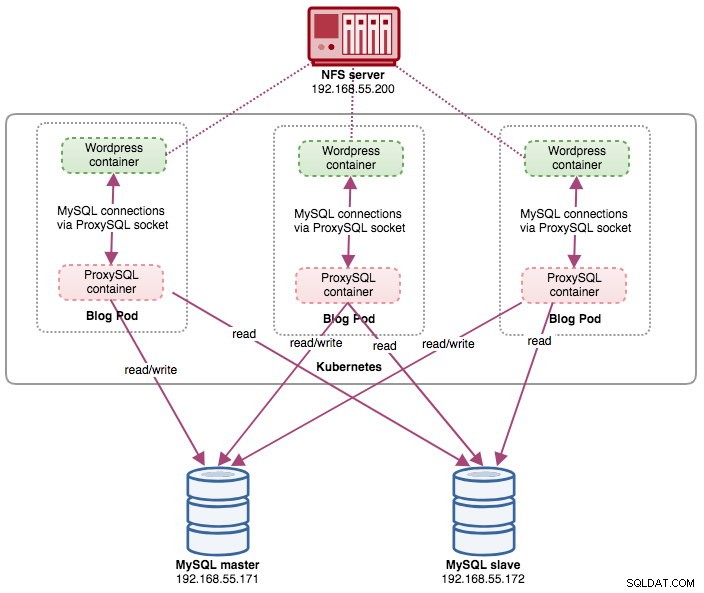
In questo post, ti mostreremo come eseguire ProxySQL su Kubernetes come contenitore di supporto in un pod. Useremo Wordpress come applicazione di esempio. Il servizio dati è fornito dalla nostra replica MySQL a due nodi, distribuita utilizzando ClusterControl e posizionata al di fuori della rete Kubernetes su un'infrastruttura bare-metal, come illustrato nel diagramma seguente:
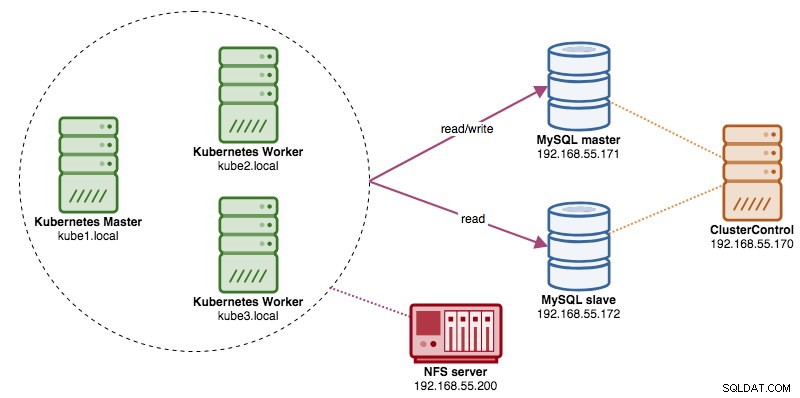
Immagine Docker proxySQL
In questo esempio, utilizzeremo l'immagine ProxySQL Docker gestita da Multiplenines, un'immagine pubblica generica creata per un utilizzo multiuso. L'immagine viene fornita senza script entrypoint e supporta Galera Cluster (oltre al supporto integrato per MySQL Replication), dove è necessario uno script aggiuntivo per scopi di controllo dello stato.
Fondamentalmente, per eseguire un container ProxySQL, esegui semplicemente il seguente comando:
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlQuesta immagine consiglia di associare un file di configurazione ProxySQL al punto di montaggio, /etc/proxysql.cnf, anche se puoi ignorarlo e configurarlo in seguito utilizzando la console di amministrazione ProxySQL. Esempi di configurazione sono forniti nella pagina Docker Hub o nella pagina Github.
ProxySQL su Kubernetes
La progettazione dell'architettura ProxySQL è un argomento soggettivo e fortemente dipendente dal posizionamento dell'applicazione e dei contenitori del database, nonché dal ruolo di ProxySQL stesso. ProxySQL non solo instrada le query, ma può anche essere utilizzato per riscrivere e memorizzare nella cache le query. L'efficienza degli accessi alla cache potrebbe richiedere una configurazione personalizzata su misura per il carico di lavoro del database dell'applicazione.
Idealmente, possiamo configurare ProxySQL per essere gestito da Kubernetes con due configurazioni:
- ProxySQL come servizio Kubernetes (distribuzione centralizzata).
- ProxySQL come contenitore di supporto in un pod (distribuzione distribuita).
La prima opzione è piuttosto semplice, in cui creiamo un pod ProxySQL e colleghiamo un servizio Kubernetes ad esso. Le applicazioni si connetteranno quindi al servizio ProxySQL tramite rete sulle porte configurate. Il valore predefinito è 6033 per la porta con bilanciamento del carico di MySQL e 6032 per la porta di amministrazione ProxySQL. Questa distribuzione sarà trattata nel prossimo post del blog.
La seconda opzione è leggermente diversa. Kubernetes ha un concetto chiamato "pod". Puoi avere uno o più contenitori per pod, questi sono relativamente strettamente accoppiati. I contenuti di un pod sono sempre collocati e programmati insieme ed eseguiti in un contesto condiviso. Un pod è l'unità container più piccola gestibile di Kubernetes.
Entrambe le distribuzioni possono essere facilmente distinte osservando il diagramma seguente:
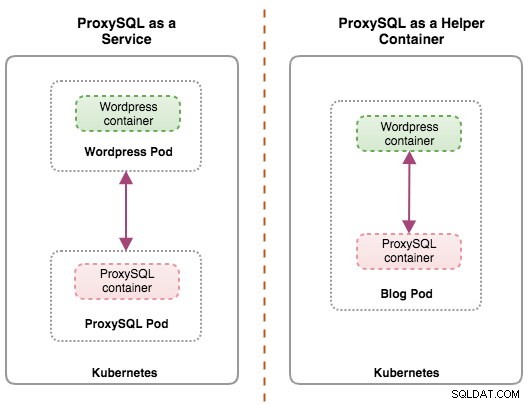
Il motivo principale per cui i pod possono avere più contenitori è supportare le applicazioni di supporto che assistono un'applicazione primaria. Esempi tipici di applicazioni di supporto sono data puller, data pusher e proxy. Le applicazioni di supporto e primarie spesso devono comunicare tra loro. Tipicamente questo viene fatto attraverso un filesystem condiviso, come mostrato in questo esercizio, o tramite l'interfaccia di rete di loopback, localhost. Un esempio di questo modello è un server Web insieme a un programma di supporto che esegue il polling di un repository Git per nuovi aggiornamenti.
Questo post del blog tratterà la seconda configurazione:eseguire ProxySQL come contenitore di supporto in un pod.
ProxySQL come helper in un pod
In questa configurazione, eseguiamo ProxySQL come contenitore di supporto per il nostro contenitore di Wordpress. Il diagramma seguente illustra la nostra architettura di alto livello:
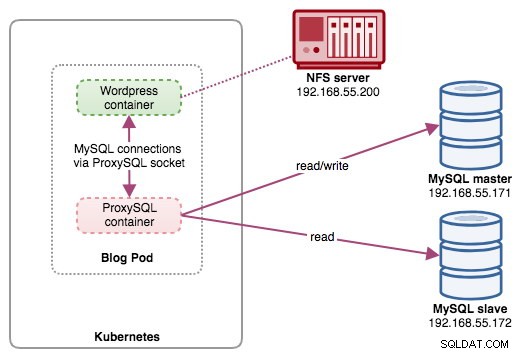
In questa configurazione, il contenitore ProxySQL è strettamente associato al contenitore di Wordpress e lo abbiamo chiamato pod "blog". Se si verifica una riprogrammazione, ad esempio, il nodo di lavoro Kubernetes si interrompe, questi due contenitori verranno sempre riprogrammati insieme come un'unità logica sul successivo host disponibile. Per mantenere il contenuto dei contenitori dell'applicazione persistente su più nodi, dobbiamo utilizzare un file system cluster o remoto, che in questo caso è NFS.
Il ruolo ProxySQL consiste nel fornire un livello di astrazione del database al contenitore dell'applicazione. Poiché stiamo eseguendo una replica MySQL a due nodi come servizio di database back-end, la suddivisione in lettura e scrittura è fondamentale per massimizzare il consumo di risorse su entrambi i server MySQL. ProxySQL eccelle in questo e richiede modifiche minime o nulle all'applicazione.
Esistono numerosi altri vantaggi nell'esecuzione di ProxySQL in questa configurazione:
- Porta la capacità di memorizzazione nella cache delle query più vicina al livello dell'applicazione in esecuzione in Kubernetes.
- Implementazione sicura mediante la connessione tramite il file socket UNIX ProxySQL. È come una pipe che il server ei client possono utilizzare per connettersi e scambiare richieste e dati.
- Livello proxy inverso distribuito con architettura nulla condivisa.
- Meno sovraccarico di rete grazie all'implementazione "salta la rete".
- Approccio alla distribuzione stateless utilizzando Kubernetes ConfigMaps.
Preparazione del database
Crea il database wordpress e l'utente sul master e assegna con il privilegio corretto:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Inoltre, crea l'utente di monitoraggio ProxySQL:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Quindi, ricarica la tabella delle sovvenzioni:
mysql-master> FLUSH PRIVILEGES;Preparazione del Pod
Ora, copia e incolla le seguenti righe in un file chiamato blog-deployment.yml sull'host in cui è configurato kubectl:
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Il file YAML ha molte righe e guardiamo solo la parte interessante. La prima sezione:
apiVersion: apps/v1
kind: DeploymentLa prima riga è apiVersion. Il nostro cluster Kubernetes è in esecuzione su v1.12, quindi dovremmo fare riferimento alla documentazione dell'API Kubernetes v1.12 e seguire la dichiarazione delle risorse in base a questa API. Il prossimo è il tipo, che indica il tipo di risorsa che vogliamo distribuire. Deployment, Service, ReplicaSet, DaemonSet, PersistentVolume sono alcuni degli esempi.
La prossima sezione importante è la sezione "contenitori". Qui definiamo tutti i contenitori che vorremmo eseguire insieme in questo pod. La prima parte è il contenitore di Wordpress:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpIn questa sezione, stiamo dicendo a Kubernetes di distribuire Wordpress 4.9 utilizzando il server Web Apache e abbiamo assegnato al contenitore il nome "wordpress". Vogliamo anche che Kubernetes passi una serie di variabili d'ambiente:
- WORDPRESS_DB_HOST - L'host del database. Poiché il nostro contenitore ProxySQL risiede nello stesso Pod con il contenitore Wordpress, è più sicuro utilizzare invece un file socket ProxySQL. Il formato per utilizzare il file socket in Wordpress è "localhost:{percorso del file socket}". Per impostazione predefinita, si trova nella directory /tmp del contenitore ProxySQL. Questo percorso /tmp è condiviso tra i contenitori di Wordpress e ProxySQL utilizzando i montaggi di volume "dati condivisi", come mostrato più in basso. Entrambi i container devono montare questo volume per condividere lo stesso contenuto nella directory /tmp.
- WORDPRESS_DB_USER - Specificare l'utente del database wordpress.
- WORDPRESS_DB_PASSWORD - La password per WORDPRESS_DB_USER . Poiché non vogliamo esporre la password in questo file, possiamo nasconderla utilizzando Kubernetes Secrets. Qui indichiamo a Kubernetes di leggere invece la risorsa segreta "mysql-pass". I segreti devono essere creati in anticipo prima dell'implementazione del pod, come spiegato più avanti.
Vogliamo anche pubblicare la porta 80 del container per l'utente finale. Il contenuto di Wordpress archiviato all'interno di /var/www/html nel contenitore verrà montato nella nostra memoria permanente in esecuzione su NFS.
Successivamente, definiamo il contenitore ProxySQL:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlNella sezione precedente, stiamo dicendo a Kubernetes di distribuire un ProxySQL usando diverselnines/proxysql immagine versione 1.4.12. Vogliamo anche che Kubernetes monti il nostro file di configurazione preconfigurato personalizzato e lo mappi a /etc/proxysql.cnf all'interno del contenitore. Ci sarà un volume chiamato "shared-data" che mappa alla directory /tmp da condividere con l'immagine di Wordpress - una directory temporanea che condivide la vita di un pod. Ciò consente al file socket ProxySQL (/tmp/proxysql.sock) di essere utilizzato dal contenitore di Wordpress durante la connessione al database, bypassando la rete TCP/IP.
L'ultima parte è la sezione "volumi":
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Kubernetes dovrà creare tre volumi per questo pod:
- wordpress-persistent-storage:utilizza PersistentVolumeClaim risorsa per mappare l'esportazione NFS nel contenitore per l'archiviazione permanente dei dati per il contenuto di Wordpress.
- proxysql-config - Usa la ConfigMap risorsa per mappare il file di configurazione ProxySQL.
- dati condivisi:utilizza la emptyDir risorsa per montare una directory condivisa per i nostri contenitori all'interno del Pod. directory vuota risorsa è una directory temporanea che condivide la durata di un pod.
Pertanto, in base alla nostra definizione YAML di cui sopra, dobbiamo preparare un certo numero di risorse Kubernetes prima di poter iniziare a distribuire il pod "blog":
- Volume persistente e Richiesta volume persistente - Per archiviare i contenuti web della nostra applicazione Wordpress, così quando il pod viene riprogrammato su un altro nodo di lavoro, non perderemo le ultime modifiche.
- Segreti - Per nascondere la password utente del database Wordpress all'interno del file YAML.
- ConfigMap - Per mappare il file di configurazione sul contenitore ProxySQL, così quando viene riprogrammato su un altro nodo, Kubernetes può rimontarlo automaticamente.
Volume persistente e Richiesta volume persistente
Una buona memoria persistente per Kubernetes dovrebbe essere accessibile da tutti i nodi Kubernetes nel cluster. Per il bene di questo post del blog, abbiamo utilizzato NFS come provider PersistentVolume (PV) perché è facile e supportato immediatamente. Il server NFS si trova da qualche parte al di fuori della nostra rete Kubernetes e lo abbiamo configurato per consentire a tutti i nodi Kubernetes con la seguente riga all'interno di /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Tieni presente che il pacchetto client NFS deve essere installato su tutti i nodi Kubernetes. In caso contrario, Kubernetes non sarebbe in grado di montare correttamente l'NFS. Su tutti i nodi:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSInoltre, assicurati che sul server NFS esista la directory di destinazione:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressQuindi, crea un file chiamato wordpress-pv-pvc.yml e aggiungi le seguenti righe:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendNella definizione di cui sopra, vorremmo che Kubernetes allocasse 3 GB di spazio di volume sul server NFS per il nostro contenitore Wordpress. Prendi nota per l'utilizzo in produzione, NFS deve essere configurato con provisioner automatico e classe di archiviazione.
Crea le risorse FV e PVC:
$ kubectl create -f wordpress-pv-pvc.ymlVerifica se tali risorse sono state create e lo stato deve essere "Bound":
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hSegreti
Il primo consiste nel creare un segreto da utilizzare nel contenitore di Wordpress per WORDPRESS_DB_PASSWORD variabile d'ambiente. Il motivo è semplicemente perché non vogliamo esporre la password in chiaro all'interno del file YAML.
Crea una risorsa segreta chiamata mysql-pass e passa la password di conseguenza:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVerifica che il nostro segreto sia stato creato:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mMappa di configurazione
Dobbiamo anche creare una risorsa ConfigMap per il nostro contenitore ProxySQL. Un file Kubernetes ConfigMap contiene coppie chiave-valore di dati di configurazione che possono essere consumati nei pod o utilizzati per archiviare i dati di configurazione. ConfigMaps ti consente di disaccoppiare gli artefatti di configurazione dal contenuto dell'immagine per mantenere le applicazioni containerizzate portatili.
Poiché il nostro server di database è già in esecuzione su server bare-metal con un nome host e un indirizzo IP statici oltre a nome utente e password di monitoraggio statico, in questo caso d'uso il file ConfigMap memorizzerà le informazioni di configurazione preconfigurate sul servizio ProxySQL che vogliamo utilizzare.
Per prima cosa crea un file di testo chiamato proxysql.cnf e aggiungi le seguenti righe:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Presta particolare attenzione alle sezioni "mysql_servers" e "mysql_users", in cui potresti dover modificare i valori per adattarli alla configurazione del tuo cluster di database. In questo caso, abbiamo due server di database in esecuzione in MySQL Replication, come riepilogato nella seguente schermata della topologia presa da ClusterControl:
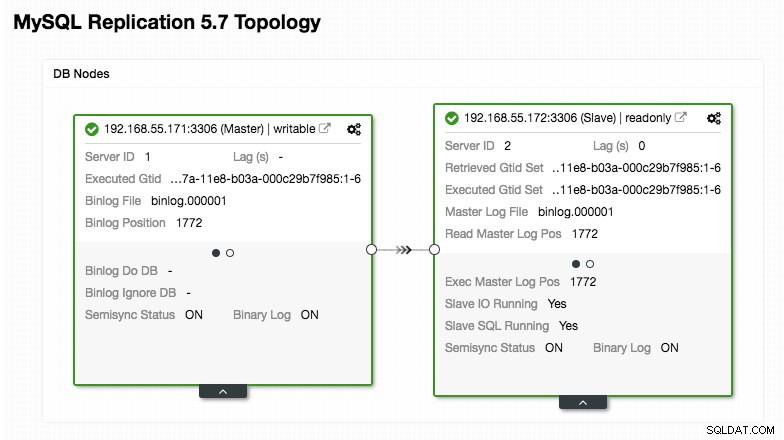
Tutte le scritture dovrebbero andare al nodo master mentre le letture vengono inoltrate al gruppo host 20, come definito nella sezione "mysql_query_rules". Questa è la base della suddivisione in lettura/scrittura e vogliamo utilizzarle del tutto.
Quindi, importa il file di configurazione in ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdVerifica se ConfigMap è caricato in Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sDistribuzione del pod
Ora dovremmo essere a posto per distribuire il blog pod. Invia il processo di distribuzione a Kubernetes:
$ kubectl create -f blog-deployment.ymlVerifica lo stato del pod:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sDeve mostrare 2/2 sotto la colonna PRONTO, indicando che ci sono due contenitori in esecuzione all'interno del pod. Usa il flag dell'opzione -c per controllare i contenitori di Wordpress e ProxySQL all'interno del pod del blog:
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlDal registro del contenitore ProxySQL, dovresti vedere le seguenti righe:
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:HID 10 (gruppo host scrittore) deve avere un solo nodo ONLINE (che indica un singolo master) e l'altro host deve essere almeno nello stato OFFLINE_HARD. Per HID 20, dovrebbe essere ONLINE per tutti i nodi (indicando più repliche di lettura).
Per ottenere un riepilogo della distribuzione, utilizza il flag di descrizione:
$ kubectl describe deployments blogIl nostro blog è ora in esecuzione, tuttavia non possiamo accedervi dall'esterno della rete Kubernetes senza configurare il servizio, come spiegato nella prossima sezione.
Creazione del servizio blog
L'ultimo passaggio consiste nel creare allegare un servizio al nostro pod. Questo per garantire che il nostro blog pod Wordpress sia accessibile dal mondo esterno. Crea un file chiamato blog-svc.yml e incolla la seguente riga:
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendCrea il servizio:
$ kubectl create -f blog-svc.ymlVerifica se il servizio è stato creato correttamente:
example@sqldat.com:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hLa porta 80 pubblicata dal blog pod è ora mappata al mondo esterno tramite la porta 30080. Possiamo accedere al nostro post sul blog all'indirizzo https://{any_kubernetes_host}:30080/ e dovrebbe essere reindirizzato alla pagina di installazione di Wordpress. Se procediamo con l'installazione, salterà la parte relativa alla connessione al database e mostrerà direttamente questa pagina:
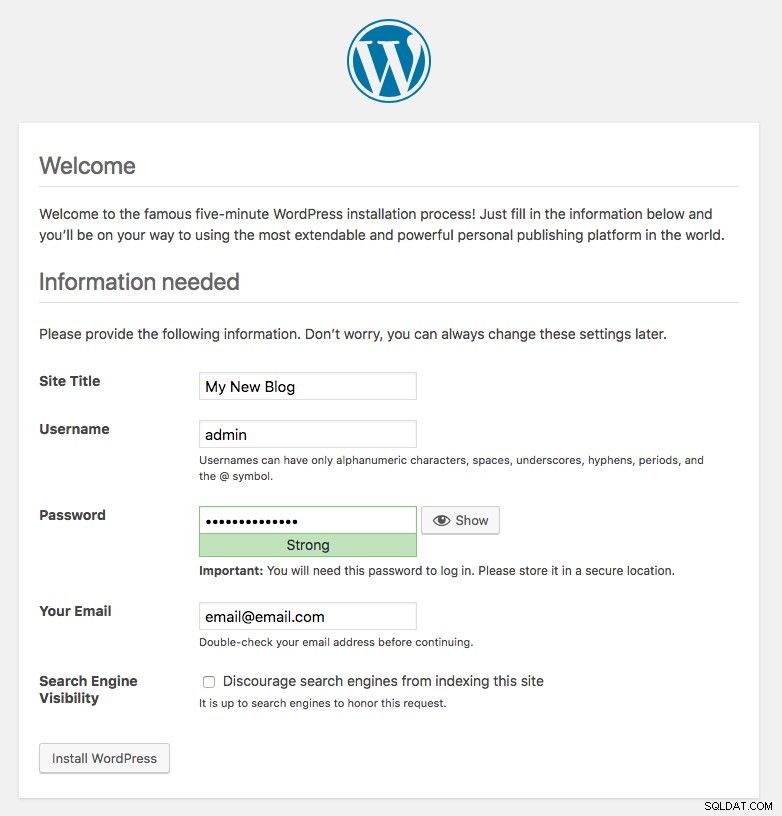
Indica che la nostra configurazione MySQL e ProxySQL è configurata correttamente all'interno del file wp-config.php. In caso contrario, verrai reindirizzato alla pagina di configurazione del database.
La nostra distribuzione è ora completa.
Gestione del contenitore ProxySQL all'interno di un pod
Il failover e il ripristino dovrebbero essere gestiti automaticamente da Kubernetes. Ad esempio, se il ruolo di lavoro Kubernetes si interrompe, il pod verrà ricreato nel successivo nodo disponibile dopo --pod-eviction-timeout (il valore predefinito è 5 minuti). Se il contenitore si arresta in modo anomalo o viene interrotto, Kubernetes lo sostituirà quasi istantaneamente.
Alcune attività di gestione comuni dovrebbero essere diverse durante l'esecuzione all'interno di Kubernetes, come mostrato nelle sezioni successive.
Scala su e giù
Nella configurazione precedente, stavamo distribuendo una replica nella nostra distribuzione. Per aumentare la scalabilità, è sufficiente modificare spec.replicas valore di conseguenza utilizzando il comando di modifica kubectl:
$ kubectl edit deployment blogAprirà la definizione di distribuzione in un file di testo predefinito e cambierà semplicemente spec.replicas valore a qualcosa di più alto, ad esempio "repliche:3". Quindi, salva il file e verifica immediatamente lo stato di rollout utilizzando il seguente comando:
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outA questo punto, abbiamo tre blog pod (Wordpress + ProxySQL) in esecuzione contemporaneamente in Kubernetes:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mA questo punto, la nostra architettura è simile a questa:
Tieni presente che potrebbe richiedere una maggiore personalizzazione rispetto alla nostra configurazione attuale per eseguire Wordpress senza problemi in un ambiente di produzione a scala orizzontale (pensa ai contenuti statici, alla gestione delle sessioni e altro). Questi sono in realtà oltre lo scopo di questo post sul blog.
Le procedure di ridimensionamento sono simili.
Gestione della configurazione
La gestione della configurazione è importante in ProxySQL. È qui che accade la magia in cui puoi definire il tuo set di regole di query per eseguire la memorizzazione nella cache, il firewall e la riscrittura delle query. Contrariamente alla pratica comune, in cui ProxySQL verrebbe configurato tramite la Console di amministrazione e verrà inserito nella persistenza utilizzando "SALVA .. SU DISCO", ci atterremo ai file di configurazione solo per rendere le cose più portatili in Kubernetes. Questo è il motivo per cui utilizziamo ConfigMaps.
Poiché ci affidiamo alla nostra configurazione centralizzata archiviata da Kubernetes ConfigMaps, esistono diversi modi per eseguire modifiche alla configurazione. Innanzitutto, utilizzando il comando di modifica kubectl:
$ kubectl edit configmap proxysql-configmapSi aprirà la configurazione in un editor di testo predefinito e potrai apportare modifiche direttamente ad esso e salvare il file di testo una volta terminato. Altrimenti, ricrea anche le mappe di configurazione:
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfDopo aver eseguito il push della configurazione in ConfigMap, riavviare il pod o il contenitore come mostrato nella sezione Controllo del servizio. La configurazione del contenitore tramite l'interfaccia di amministrazione ProxySQL (porta 6032) non lo renderà persistente dopo la riprogrammazione del pod da parte di Kubernetes.
Controllo del servizio
Poiché i due contenitori all'interno di un pod sono strettamente accoppiati, il modo migliore per applicare le modifiche alla configurazione di ProxySQL è forzare Kubernetes a eseguire la sostituzione del pod. Considera che ora abbiamo tre blog pod dopo l'ampliamento:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mUtilizzare il comando seguente per sostituire un pod alla volta:
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnQuindi, verifica con quanto segue:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sNoterai che il pod più recente è stato riavviato osservando la colonna AGE e RESTART, è uscito con un nome pod diverso. Ripeti gli stessi passaggi per i baccelli rimanenti. In caso contrario, puoi anche utilizzare il comando "docker kill" per terminare manualmente il contenitore ProxySQL all'interno del nodo di lavoro Kubernetes. Ad esempio:
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})Kubernetes sostituirà quindi il container ProxySQL terminato con uno nuovo.
Monitoraggio
Usa il comando kubectl exec per eseguire l'istruzione SQL tramite il client mysql. Ad esempio, per monitorare la digestione delle query:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;O con una riga:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'Modificando l'istruzione SQL, puoi monitorare altri componenti ProxySQL o eseguire attività di amministrazione tramite questa Console di amministrazione. Anche in questo caso, persisterà solo durante la durata del contenitore ProxySQL e non verrà mantenuto se il pod viene riprogrammato.
Pensieri finali
ProxySQL ha un ruolo chiave se desideri ridimensionare i contenitori delle applicazioni e disporre di un modo intelligente per accedere a un back-end di database distribuito. Esistono diversi modi per distribuire ProxySQL su Kubernetes per supportare la crescita delle nostre applicazioni durante l'esecuzione su larga scala. Questo post del blog ne copre solo uno.
In un prossimo post sul blog, esamineremo come eseguire ProxySQL in un approccio centralizzato utilizzandolo come servizio Kubernetes.



