Cosa sono i vincoli chiave univoci?
Un vincolo univoco è una regola che limita le voci di colonna a univoche. In altre parole, questo tipo di vincoli impedisce l'inserimento di duplicati in una colonna. Un vincolo univoco è uno degli strumenti per imporre l'integrità dei dati in un database di SQL Server. Poiché una tabella può avere solo una chiave primaria, puoi utilizzare un vincolo univoco per imporre l'unicità di una colonna o una combinazione di colonne che non costituiscono una chiave primaria.
La creazione di un vincolo univoco su una colonna crea automaticamente un indice univoco. In questo modo SQL Server implementa il requisito di integrità del vincolo univoco. Pertanto, quando si tenta di inserire un valore duplicato in una colonna in cui è definito un vincolo univoco, Motore di database rileverà la violazione del vincolo univoco ed emetterà un errore corrispondente. Di conseguenza, la riga con i valori duplicati non verrà aggiunta a una tabella.
Creazione di un vincolo unico
La query di esempio seguente crea gli Studenti tabella e un vincolo univoco su Login colonna in modo che non ci siano studenti con lo stesso login.
CREATE TABLE Students ( Login CHAR NOT NULL ,CONSTRAINT AK_Student_Login UNIQUE (Login) ); GO
Se gli Studenti esiste già, quindi puoi utilizzare la seguente query di esempio per creare il vincolo univoco.
ALTER TABLE Students ADD CONSTRAINT AK_Student_Login UNIQUE (Login); GO
Si noti che quando si aggiunge un vincolo univoco a una tabella esistente, Motore di database verifica se la colonna a cui viene aggiunto il vincolo include valori duplicati. Se sono presenti tali valori, il vincolo non verrà aggiunto restituendo un errore.
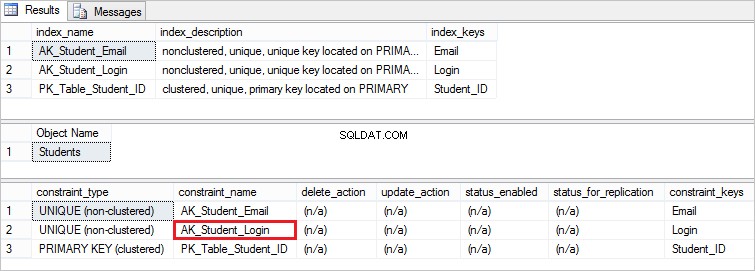
Ora, per verificare che il vincolo univoco sia stato effettivamente aggiunto, eseguire le seguenti istruzioni:
EXEC sp_helpindex Students EXEC sp_helpconstraint Students
Ecco il vincolo che abbiamo creato:
Creazione di un vincolo univoco in SQL Server Management Studio
Diciamo che dobbiamo definire un vincolo univoco sul Login nella colonna Studenti tabella.
1. In Esplora oggetti , fai clic con il pulsante destro del mouse su Studenti tabella e fai clic su Design .
2. Fai clic con il pulsante destro del mouse su Designer tabella e scegli Indici/Chiavi...
3. Negli Indici/Chiavi finestra, fai clic su Aggiungi .
4. Sotto il Generale sezione, fai clic su Colonne e quindi fare clic sul pulsante con i puntini di sospensione. Nelle colonne dell'indice finestra, seleziona le colonne che desideri includere nel vincolo univoco.
5. Sotto il Generale sezione, fai clic su Tipo e seleziona Chiave univoca dall'elenco a discesa.
6. Sotto l'Identità sezione, specifica il nome del vincolo (nel nostro caso, AK_Student_Login ) e fai clic su Chiudi per salvare il vincolo appena creato.
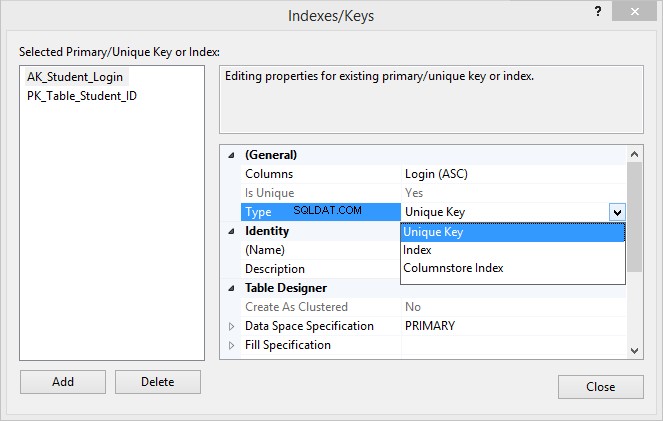
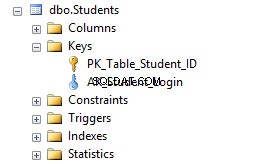
Ora, se vai a Studenti tabella in Esplora oggetti e fai clic su Indici cartella, vedrai che la tabella contiene una chiave primaria e un vincolo univoco AK_Student_Login .
In che modo i vincoli univoci sono diversi dalle chiavi primarie?
Simile a un vincolo univoco, viene utilizzata anche una chiave primaria per imporre l'integrità dei dati in una tabella. Ma lo scopo principale di una chiave primaria è identificare in modo univoco ogni record in una tabella e implementare relazioni appropriate tra le tabelle in un database. Una chiave primaria è richiesta nel 99% delle tabelle per consentire il corretto accesso alle righe della tabella. Può esserci una sola chiave primaria per tabella definita su una o più colonne.
I vincoli univoci vengono utilizzati in modo specifico per impedire l'inserimento di valori duplicati in una colonna. Potrebbero esserci diverse colonne con vincoli univoci o non esistere alcun vincolo univoco definito su una tabella. Non sono obbligatorie per una tabella al contrario delle chiavi primarie.
Diciamo che abbiamo gli Studenti tabella contenente le informazioni personali di ogni studente di un'università. La tabella include StudentID colonna che è una chiave primaria e memorizza un ID univoco di ogni studente specifico. Questa colonna della chiave primaria viene utilizzata per identificare in modo univoco ogni studente di un'università.
Allo stesso tempo, gli Studenti tabella ha colonne come Email , Numero di previdenza sociale e Accedi e ciascuna di queste colonne deve memorizzare valori univoci. Poiché nella tabella è già presente una chiave primaria, utilizzeremo invece vincoli univoci per imporre l'unicità a queste colonne. Pertanto, una tabella può avere molti vincoli univoci e una sola chiave primaria.
Un'altra cosa che differisce da un vincolo univoco da una chiave primaria è che la chiave primaria non consente alcun NULL valori in una colonna, mentre una colonna con un vincolo univoco può includere un NULL value ma solo uno poiché SQL Server interpreta due valori NULL come gli stessi valori.
Supponiamo che venga creato un vincolo univoco sull'Email colonna degli Studenti tavolo. Proviamo a inserire due righe entrambe con NULL s nell'E-mail campi:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (1, 'John White', 19, NULL, 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (2, 'James Marvin', 21, NULL, 987-65-4321, 'Marvin_J17') GO
Otteniamo il seguente messaggio di errore:

Bene, questo è un comportamento prevedibile, perché i valori duplicati, anche se sono NULL, non sono consentiti dal vincolo univoco.
vincolo univoco vs indice univoco
Sebbene sia il vincolo univoco che l'indice univoco siano due entità di database completamente diverse e non correlate, hanno lo stesso obiettivo e lo stesso impatto sulle prestazioni di SQL ServerSQL Server. Entrambi garantiscono l'unicità dei dati in una colonna.
Tuttavia, contrariamente all'indice univoco, non è possibile specificare le opzioni IGNORE_DUP_KEY, DROP_EXISTING, PAD_INDEX e STATISTICS_NORECOMPUTE per il vincolo univoco nelle istruzioni ALTER TABLE.
Quando crei un vincolo univoco su una colonna, SQL Server crea automaticamente un indice univoco sulla colonna, questo è proprio il modo in cui questa funzionalità viene implementata in SQL Server.
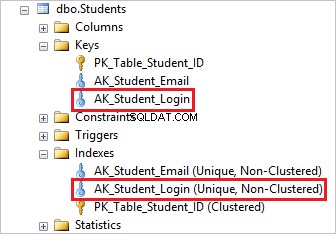
Per eliminare l'indice univoco, devi prima eliminare il vincolo univoco corrispondente e questo eliminerà automaticamente l'indice univoco sottostante.
La seguente dichiarazione eliminerà AK_Student_Login vincolo:
ALTER TABLE Students DROP CONSTRAINT AK_Student_Login; GO
Puoi vederlo eliminando AK_Student_Login vincolo univoco cancella il suo indice corrispondente.
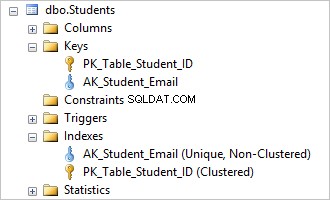
È stato facile, ora puoi inserire valori identici nel Login colonna.
Disabilitazione del vincolo univoco
C'è un'opzione che disabilita un vincolo univoco. La seguente query dovrebbe disabilitare tutti i vincoli di tabella:
ALTER TABLE Students NOCHECK CONSTRAINT ALL GO
Dopo aver eseguito la query, proviamo ora a inserire un record duplicato:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, NULL, 123-45-6789, 'John555') GO
Quello che otteniamo è il messaggio di violazione del vincolo univoco:

Pertanto, sembra che ALTER TABLE