Le persone si chiedono se dovrebbero fare del loro meglio per prevenire le eccezioni o semplicemente lasciare che il sistema le gestisca. Ho visto diverse discussioni in cui le persone discutono se dovrebbero fare tutto il possibile per prevenire un'eccezione, perché la gestione degli errori è "costosa". Non c'è dubbio che la gestione degli errori non sia gratuita, ma prevedo che una violazione di un vincolo sia efficiente almeno quanto controllare prima una potenziale violazione. Questo potrebbe essere diverso per una violazione chiave rispetto a una violazione di un vincolo statico, ad esempio, ma in questo post mi concentrerò sulla prima.
Gli approcci principali utilizzati dalle persone per gestire le eccezioni sono:
- Lascia che sia il motore a gestirlo e invia qualsiasi eccezione al chiamante.
- Utilizza
BEGIN TRANSACTIONeROLLBACKse@@ERROR <> 0. - Usa
TRY/CATCHconROLLBACKnelCATCHblocco (SQL Server 2005+).
E molti adottano l'approccio che dovrebbero verificare prima se incorreranno nella violazione, poiché sembra più pulito gestire il duplicato da soli piuttosto che costringere il motore a farlo. La mia teoria è che dovresti fidarti ma verificare; per esempio, considera questo approccio (per lo più pseudo-codice):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Sappiamo che il IF NOT EXISTS check non garantisce che qualcun altro non avrà inserito la riga prima che arriviamo a INSERT (a meno che non posizioniamo lucchetti aggressivi sul tavolo e/o utilizziamo SERIALIZABLE ), ma il controllo esterno ci impedisce di provare a commettere un errore e quindi di dover eseguire il rollback. Rimaniamo fuori dall'intero TRY/CATCH struttura se sappiamo già che il INSERT fallirà e sarebbe logico presumere che, almeno in alcuni casi, questo sarà più efficiente dell'inserimento di TRY/CATCH struttura incondizionatamente. Questo ha poco senso in un singolo INSERT scenario, ma immagina un caso in cui c'è dell'altro in quel TRY blocco (e più potenziali violazioni che potresti verificare in anticipo, il che significa ancora più lavoro che potresti altrimenti dover eseguire e quindi annullare se si verifica una violazione successiva).
Ora, sarebbe interessante vedere cosa accadrebbe se utilizzassi un livello di isolamento non predefinito (qualcosa che tratterò in un post futuro), in particolare con la concorrenza. Per questo post, però, ho voluto iniziare lentamente e testare questi aspetti con un solo utente. Ho creato una tabella chiamata dbo.[Objects] , una tabella molto semplicistica:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Volevo popolare questa tabella con 100.000 righe di dati di esempio. Per rendere univoci i valori nella colonna del nome (poiché il PK è il vincolo che volevo violare), ho creato una funzione di supporto che prende un numero di righe e una stringa minima. La stringa minima verrebbe utilizzata per assicurarsi che (a) l'insieme sia iniziato oltre il valore massimo nella tabella Oggetti o (b) l'insieme sia iniziato al valore minimo nella tabella Oggetti. (Li specificherò manualmente durante i test, verificati semplicemente esaminando i dati, anche se probabilmente avrei potuto incorporare quel controllo nella funzione.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Questo applica un CROSS JOIN di sys.all_objects su se stesso, aggiungendo un numero_riga univoco a ciascun nome, in modo che i primi 10 risultati assomiglierebbero a questo:
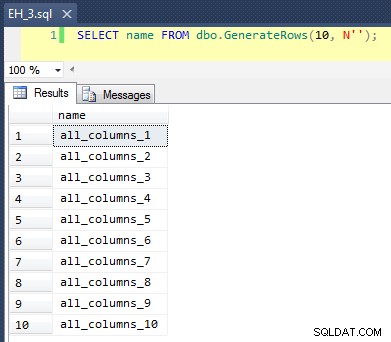
Compilare la tabella con 100.000 righe è stato semplice:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Ora, dal momento che inseriremo nuovi valori univoci nella tabella, ho creato una procedura per eseguire una pulizia all'inizio e alla fine di ogni test:oltre a eliminare le nuove righe che abbiamo aggiunto, ripulirà anche la cache e i buffer. Non qualcosa che vuoi codificare in una procedura sul tuo sistema di produzione, ovviamente, ma va bene per i test delle prestazioni locali.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Ho anche creato una tabella di registro per tenere traccia degli orari di inizio e fine di ogni test:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Infine, la stored procedure di test gestisce una varietà di cose. Abbiamo tre diversi metodi di gestione degli errori, come descritto nei punti elenco sopra:"JustInsert", "Rollback" e "TryCatch"; abbiamo anche tre diversi tipi di inserto:(1) tutti gli inserimenti hanno esito positivo (tutte le righe sono uniche), (2) tutti gli inserimenti hanno esito negativo (tutte le righe sono duplicate) e (3) metà degli inserimenti hanno esito positivo (metà delle righe sono univoche e metà le righe sono duplicate). Insieme a questo ci sono due diversi approcci:verificare la violazione prima di tentare l'inserimento, o semplicemente andare avanti e lasciare che il motore determini se è valido. Ho pensato che questo avrebbe fornito un buon confronto tra le diverse tecniche di gestione degli errori combinate con diverse probabilità di collisioni per vedere se una percentuale di collisione alta o bassa avrebbe un impatto significativo sui risultati.
Per questi test ho selezionato 40.000 righe come numero totale di tentativi di inserimento e nella procedura eseguo un'unione di 20.000 righe univoche o non univoche con altre 20.000 righe univoche o non univoche. Puoi vedere che ho codificato le stringhe di taglio nella procedura; tieni presente che sul tuo sistema questi tagli si verificheranno quasi sicuramente in un luogo diverso.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Ora possiamo chiamare questa procedura con vari argomenti per ottenere il diverso comportamento che stiamo cercando, cercando di inserire 40.000 valori (e sapendo, ovviamente, quanti dovrebbero avere successo o fallire in ogni caso). Per ogni "metodo di gestione degli errori" (prova semplicemente con l'inserimento, usa begin tran/rollback o try/catch) e ogni tipo di inserimento (tutto riuscito, metà riuscito e nessuno riuscito), combinato con se verificare o meno la violazione in primo luogo, questo ci dà 18 combinazioni:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Dopo averlo eseguito (ci vogliono circa 8 minuti sul mio sistema), abbiamo alcuni risultati nel nostro registro. Ho eseguito l'intero batch cinque volte per assicurarmi di ottenere medie decenti e per appianare eventuali anomalie. Ecco i risultati:
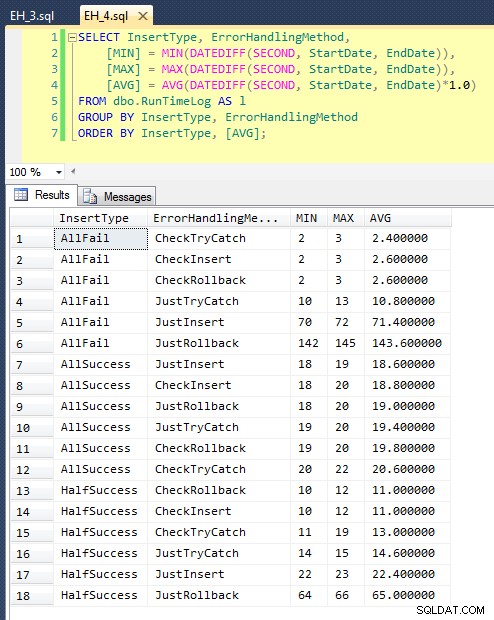
Il grafico che traccia tutte le durate contemporaneamente mostra un paio di valori anomali gravi:
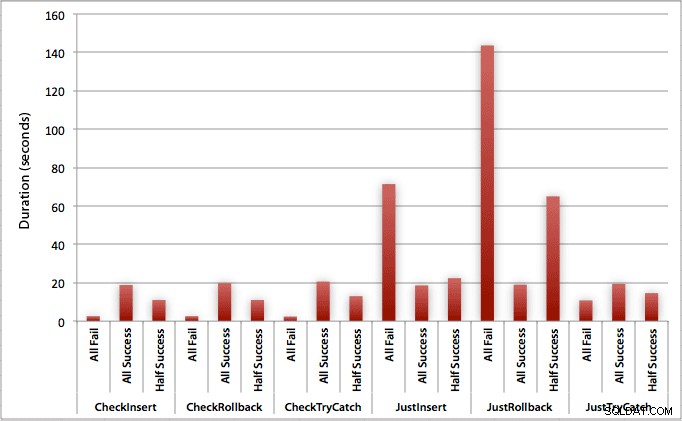
Puoi vedere che, nei casi in cui ci aspettiamo un alto tasso di errore (in questo test, 100%), iniziare una transazione e tornare indietro è di gran lunga l'approccio meno interessante (3,59 millisecondi per tentativo), lasciando semplicemente che il motore si alzi un errore è circa la metà (1,785 millisecondi per tentativo). Il successivo peggior rendimento è stato il caso in cui iniziamo una transazione e poi la annulliamo, in uno scenario in cui ci aspettiamo che circa la metà dei tentativi fallisca (con una media di 1,625 millisecondi per tentativo). I 9 casi sul lato sinistro del grafico, dove stiamo controllando per primi la violazione, non si sono spinti oltre 0,515 millisecondi per tentativo.
Detto questo, i singoli grafici per ogni scenario (alta % di successo, alta % di fallimento e 50-50) portano davvero a casa l'impatto di ciascun metodo.
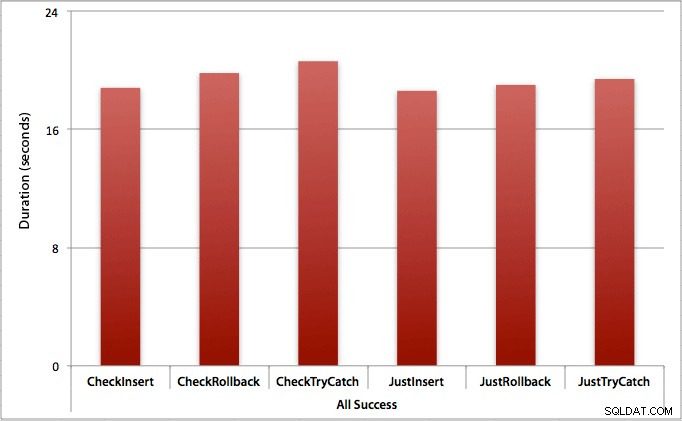
Dove tutti gli inserti hanno successo
In questo caso vediamo che l'overhead della verifica della prima violazione è trascurabile, con una differenza media di 0,7 secondi nel batch (o 125 microsecondi per tentativo di inserimento):
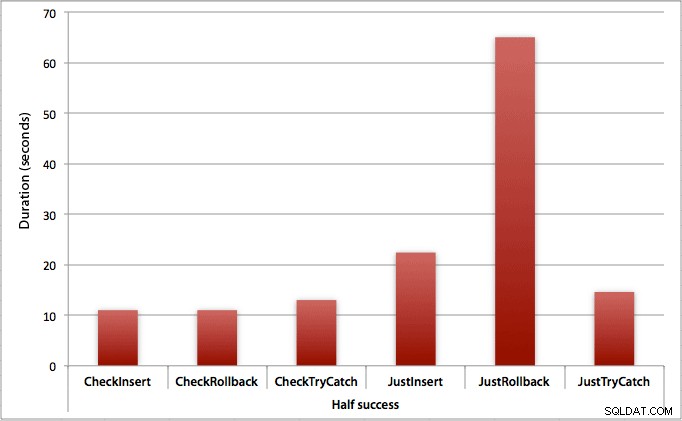
Dove solo la metà degli inserti riesce
Quando metà degli inserti falliscono, vediamo un grande salto nella durata per i metodi di inserimento/ripristino. Lo scenario in cui si avvia una transazione e si esegue il rollback è circa 6 volte più lento nel batch rispetto al primo controllo (1,625 millisecondi per tentativo contro 0,275 millisecondi per tentativo). Anche il metodo TRY/CATCH è più veloce dell'11% quando controlliamo prima:
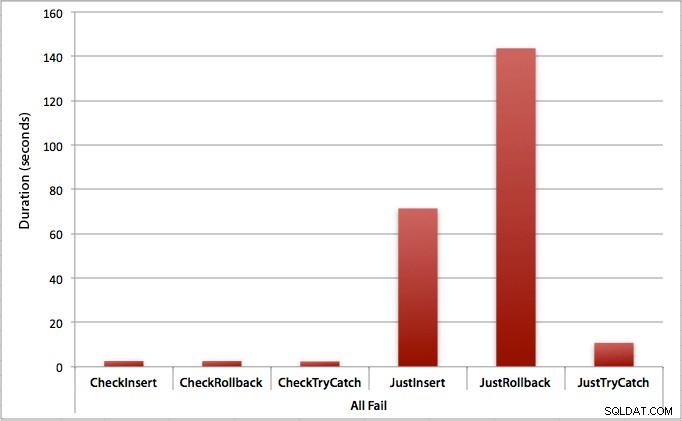
Dove tutti gli inserimenti falliscono
Come ci si potrebbe aspettare, questo mostra l'impatto più pronunciato della gestione degli errori e i vantaggi più evidenti del controllo preliminare. Il metodo di rollback è quasi 70 volte più lento in questo caso quando non controlliamo rispetto a quando lo facciamo (3,59 millisecondi per tentativo contro 0,065 millisecondi per tentativo):
Cosa ci dice questo? Se pensiamo che avremo un alto tasso di guasti, o non abbiamo idea di quale sarà il nostro potenziale tasso di guasti, allora vale la pena controllare prima per evitare violazioni nel motore. Anche nel caso in cui abbiamo un inserimento riuscito ogni volta, il costo del controllo iniziale è marginale e facilmente giustificabile dal potenziale costo della gestione degli errori in un secondo momento (a meno che il tasso di errore previsto non sia esattamente dello 0%).
Quindi per ora penso che mi atterrò alla mia teoria secondo cui, in casi semplici, ha senso verificare una potenziale violazione prima di dire a SQL Server di andare avanti e inserire comunque. In un prossimo post, esaminerò l'impatto sulle prestazioni di vari livelli di isolamento, concorrenza e forse anche alcune altre tecniche di gestione degli errori.
[Per inciso, ho scritto una versione ridotta di questo post come suggerimento per mssqltips.com a febbraio.]