L'impaginazione è un caso d'uso comune in tutte le applicazioni client e Web ovunque. Google ti mostra 10 risultati alla volta, la tua banca online potrebbe mostrare 20 fatture per pagina e il software di monitoraggio dei bug e di controllo del codice sorgente potrebbe visualizzare 50 elementi sullo schermo.
Volevo esaminare l'approccio di impaginazione comune su SQL Server 2012 - OFFSET / FETCH (uno standard equivalente alla clausola LIMIT prioritaria di MySQL) - e suggerire una variazione che porterà a prestazioni di paging più lineari nell'intero set, invece di essere solo ottimale all'inizio. Che, purtroppo, è tutto ciò che molti negozi testeranno.
Cos'è l'impaginazione in SQL Server?
In base all'indicizzazione della tabella, alle colonne necessarie e al metodo di ordinamento scelto, l'impaginazione può essere relativamente indolore. Se stai cercando i "primi" 20 clienti e l'indice cluster supporta tale ordinamento (ad esempio, un indice cluster su una colonna IDENTITY o DateCreated), la query sarà relativamente efficiente. Se è necessario supportare l'ordinamento che richiede indici non cluster e soprattutto se sono necessarie colonne per l'output che non sono coperte dall'indice (non importa se non esiste un indice di supporto), le query possono diventare più costose. E anche la stessa query (con un parametro @PageNumber diverso) può diventare molto più costosa man mano che @PageNumber aumenta, poiché potrebbero essere necessarie più letture per arrivare a quella "sezione" di dati.
Alcuni diranno che avanzare verso la fine del set è qualcosa che puoi risolvere dedicando più memoria al problema (quindi elimini qualsiasi I/O fisico) e/o usando la memorizzazione nella cache a livello di applicazione (quindi non lo farai il database). Assumiamo ai fini di questo post che più memoria non è sempre possibile, dal momento che non tutti i clienti possono aggiungere RAM a un server che ha esaurito gli slot di memoria o non è sotto il loro controllo, o semplicemente schioccare le dita e avere server nuovi e più grandi pronti andare. Soprattutto perché alcuni clienti utilizzano l'edizione Standard, quindi hanno un limite di 64 GB (SQL Server 2012) o 128 GB (SQL Server 2014) o utilizzano edizioni ancora più limitate come Express (1 GB) o una delle tante offerte cloud.
Quindi ho voluto esaminare l'approccio di paging comune su SQL Server 2012 - OFFSET / FETCH - e suggerire una variazione che porterà a prestazioni di paging più lineari nell'intero set, invece di essere ottimale solo all'inizio. Che, purtroppo, è tutto ciò che molti negozi testeranno.
Impostazione dati impaginazione / Esempio
Prenderò in prestito da un altro post, Cattive abitudini:concentrandomi solo sullo spazio su disco durante la scelta delle chiavi, dove ho popolato la tabella seguente con 1.000.000 di righe di dati dei clienti casuali (ma non del tutto realistici):
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Poiché sapevo che avrei testato l'I/O qui e che avrei eseguito il test da una cache calda e fredda, ho reso il test almeno un po' più equo ricostruendo tutti gli indici per ridurre al minimo la frammentazione (come sarebbe stato fatto meno in modo dirompente, ma regolare, sui sistemi più occupati che eseguono qualsiasi tipo di manutenzione dell'indice):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Dopo la ricostruzione, la frammentazione è ora compresa tra 0,05% e 0,17% per tutti gli indici (livello di indice =0), le pagine vengono riempite per oltre il 99% e il conteggio delle righe/pagine per gli indici è il seguente:
| Indice | Conteggio pagine | Conteggio righe |
|---|---|---|
| C_PK_Customers_I (indice cluster) | 19.210 | 1.000.000 |
| C_Email_Clienti_I | 7.344 | 1.000.000 |
| C_Active_Customers_I (indice filtrato) | 13.648 | 815.235 |
| C_Nome_Clienti_I | 16.824 | 1.000.000 |
Indici, conteggi di pagine, conteggi di righe
Questo ovviamente non è un tavolo super ampio e questa volta ho lasciato la compressione fuori dall'immagine. Forse esplorerò più configurazioni in un test futuro.
Come impaginare in modo efficace una query SQL
Il concetto di impaginazione, che mostra all'utente solo righe alla volta, è più facile da visualizzare che da spiegare. Pensa all'indice di un libro fisico, che può avere più pagine di riferimenti a punti all'interno del libro, ma organizzato in ordine alfabetico. Per semplicità, diciamo che dieci elementi si adattano a ciascuna pagina dell'indice. Potrebbe assomigliare a questo:
Ora, se ho già letto le pagine 1 e 2 dell'indice, so che per arrivare a pagina 3 devo saltare 2 pagine. Ma poiché so che ci sono 10 elementi in ogni pagina, posso anche pensare a questo come saltare 2 x 10 elementi e iniziare dal 21° elemento. Oppure, per dirla in altro modo, devo saltare i primi (10*(3-1)) elementi. Per renderlo più generico, posso dire che per iniziare da pagina n, devo saltare i primi (10 * (n-1)) elementi. Per arrivare alla prima pagina, salto 10*(1-1) elementi, per finire all'elemento 1. Per arrivare alla seconda pagina, salto 10*(2-1) elementi, per finire all'elemento 11. E così acceso.
Con queste informazioni, gli utenti formuleranno una query di paging come questa, dato che le clausole OFFSET / FETCH aggiunte in SQL Server 2012 sono state progettate specificamente per saltare tante righe:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Come accennato in precedenza, funziona perfettamente se esiste un indice che supporta ORDER BY e che copre tutte le colonne nella clausola SELECT (e, per query più complesse, le clausole WHERE e JOIN). Tuttavia, i costi di ordinamento potrebbero essere schiaccianti senza un indice di supporto e, se le colonne di output non sono coperte, ti ritroverai con un intero gruppo di ricerche di chiavi o potresti persino ottenere una scansione della tabella in alcuni scenari.
Best practice per l'ordinamento dell'impaginazione SQL
Data la tabella e gli indici sopra, volevo testare questi scenari, in cui vogliamo mostrare 100 righe per pagina e generare tutte le colonne nella tabella:
- Predefinito –
ORDER BY CustomerID(indice raggruppato). Questo è l'ordinamento più conveniente per le persone del database, poiché non richiede un ordinamento aggiuntivo e tutti i dati di questa tabella che potrebbero essere necessari per la visualizzazione sono inclusi. D'altra parte, questo potrebbe non essere l'indice più efficiente da utilizzare se stai visualizzando un sottoinsieme della tabella. L'ordine potrebbe anche non avere senso per gli utenti finali, soprattutto se CustomerID è un identificatore surrogato senza significato esterno. - Rubrica telefonica –
ORDER BY LastName, FirstName(supporto dell'indice non cluster). Questo è l'ordinamento più intuitivo per gli utenti, ma richiederebbe un indice non cluster per supportare sia l'ordinamento che la copertura. Senza un indice di supporto, l'intera tabella dovrebbe essere scansionata. - Definito dall'utente –
ORDER BY FirstName DESC, EMail(nessun indice di supporto). Ciò rappresenta la possibilità per l'utente di scegliere qualsiasi ordine di ordinamento desidera, un modello di cui Michael J. Swart mette in guardia in "Modelli di progettazione dell'interfaccia utente che non scalano".
Volevo testare questi metodi e confrontare piani e metriche quando, sia in scenari warm cache che cold cache, esaminando pagina 1, pagina 500, pagina 5.000 e pagina 9.999. Ho creato queste procedure (diverse solo dalla clausola ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail In realtà, probabilmente avrai solo una procedura che utilizza SQL dinamico (come nel mio esempio "lavello da cucina") o un'espressione CASE per dettare l'ordine.
In entrambi i casi, è possibile ottenere risultati migliori utilizzando OPTION (RICIMPILA) sulla query per evitare il riutilizzo di piani ottimali per un'opzione di ordinamento ma non per tutti. Ho creato procedure separate qui per eliminare quelle variabili; Ho aggiunto OPTION (RICIMPILA) per questi test per evitare lo sniffing dei parametri e altri problemi di ottimizzazione senza svuotare ripetutamente l'intera cache del piano.
Un approccio alternativo all'impaginazione di SQL Server per prestazioni migliori
Un approccio leggermente diverso, che non vedo implementato molto spesso, consiste nell'individuare la "pagina" su cui ci troviamo utilizzando solo la chiave di clustering, quindi unirvi a quella:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
È un codice più dettagliato, ovviamente, ma si spera che sia chiaro ciò che SQL Server può essere costretto a fare:evitare una scansione o almeno rinviare le ricerche fino a quando un set di risultati molto più piccolo non viene ridotto. Paul White (@SQL_Kiwi) ha studiato un approccio simile nel 2010, prima che OFFSET/FETCH fosse introdotto nelle prime versioni beta di SQL Server 2012 (ne ho scritto per la prima volta sul blog più tardi quell'anno).
Dati gli scenari precedenti, ho creato altre tre procedure, con l'unica differenza tra le colonne specificate nelle clausole ORDER BY (ora ne servono due, una per la pagina stessa e una per ordinare il risultato):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Nota:questo potrebbe non funzionare così bene se la tua chiave primaria non è in cluster:parte del trucco che rende questo funzionamento migliore, quando è possibile utilizzare un indice di supporto, è che la chiave di clustering è già nell'indice, quindi un la ricerca viene spesso evitata.
Test dell'ordinamento delle chiavi di cluster
Per prima cosa ho testato il caso in cui non mi aspettavo molta varianza tra i due metodi, l'ordinamento in base alla chiave di clustering. Ho eseguito queste istruzioni in batch in SQL Sentry Plan Explorer e ho osservato la durata, le letture e i piani grafici, assicurandomi che ogni query partisse da una cache completamente fredda:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
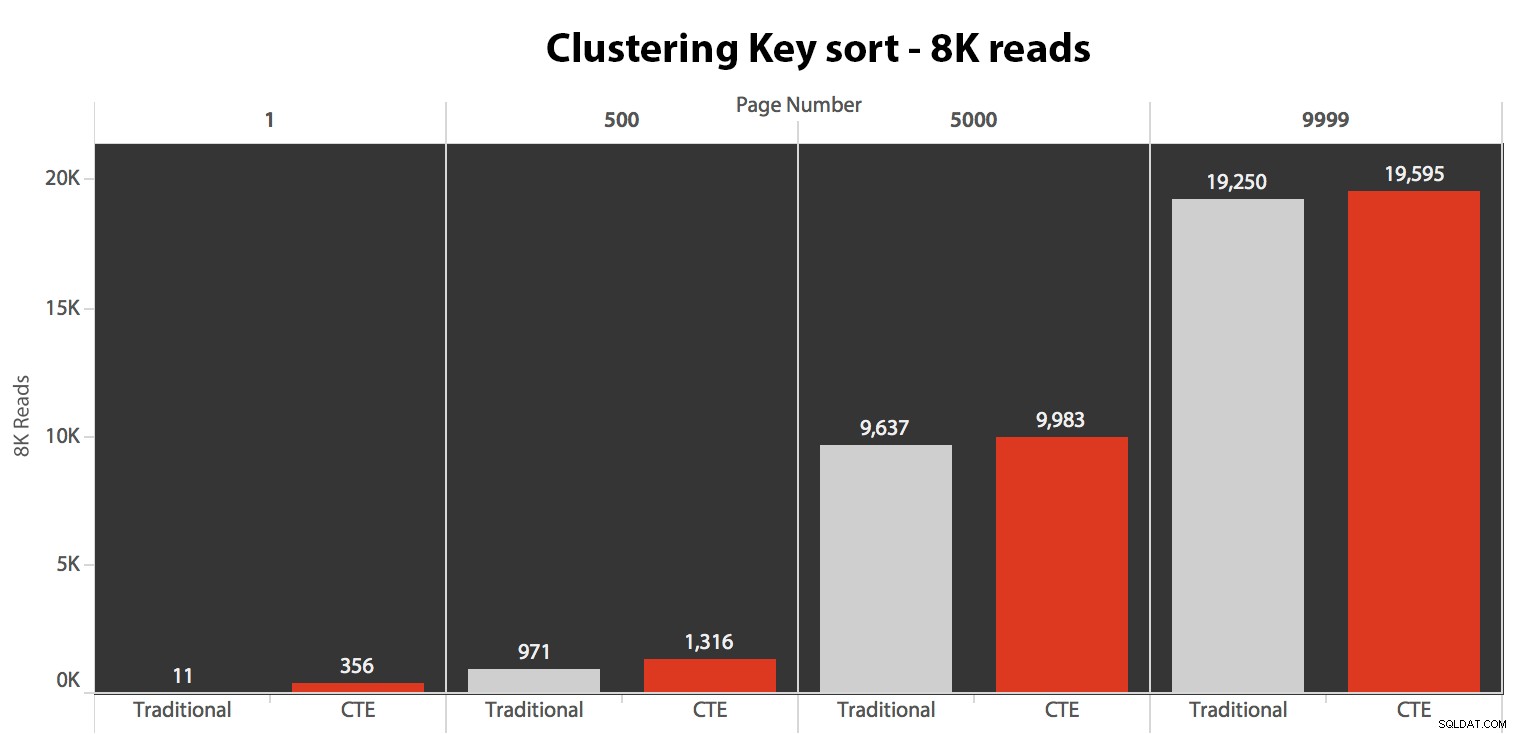
I risultati qui non sono stati sorprendenti. Su 5 esecuzioni qui viene mostrato il numero medio di letture, che mostra differenze trascurabili tra le due query, su tutti i numeri di pagina, quando si ordina in base alla chiave di clustering:
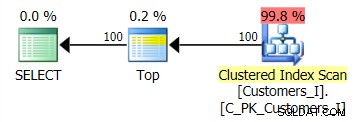
Il piano per il metodo predefinito (come mostrato in Plan Explorer) in tutti i casi era il seguente:
Mentre il piano per il metodo basato su CTE sembrava questo:
Ora, mentre l'I/O era lo stesso indipendentemente dalla memorizzazione nella cache (solo molte più letture read-ahead nello scenario della cache fredda), ho misurato la durata con una cache fredda e anche con una cache calda (dove ho commentato i comandi DROPCLEANBUFFERS ed eseguito le query più volte prima della misurazione). Queste durate erano così:
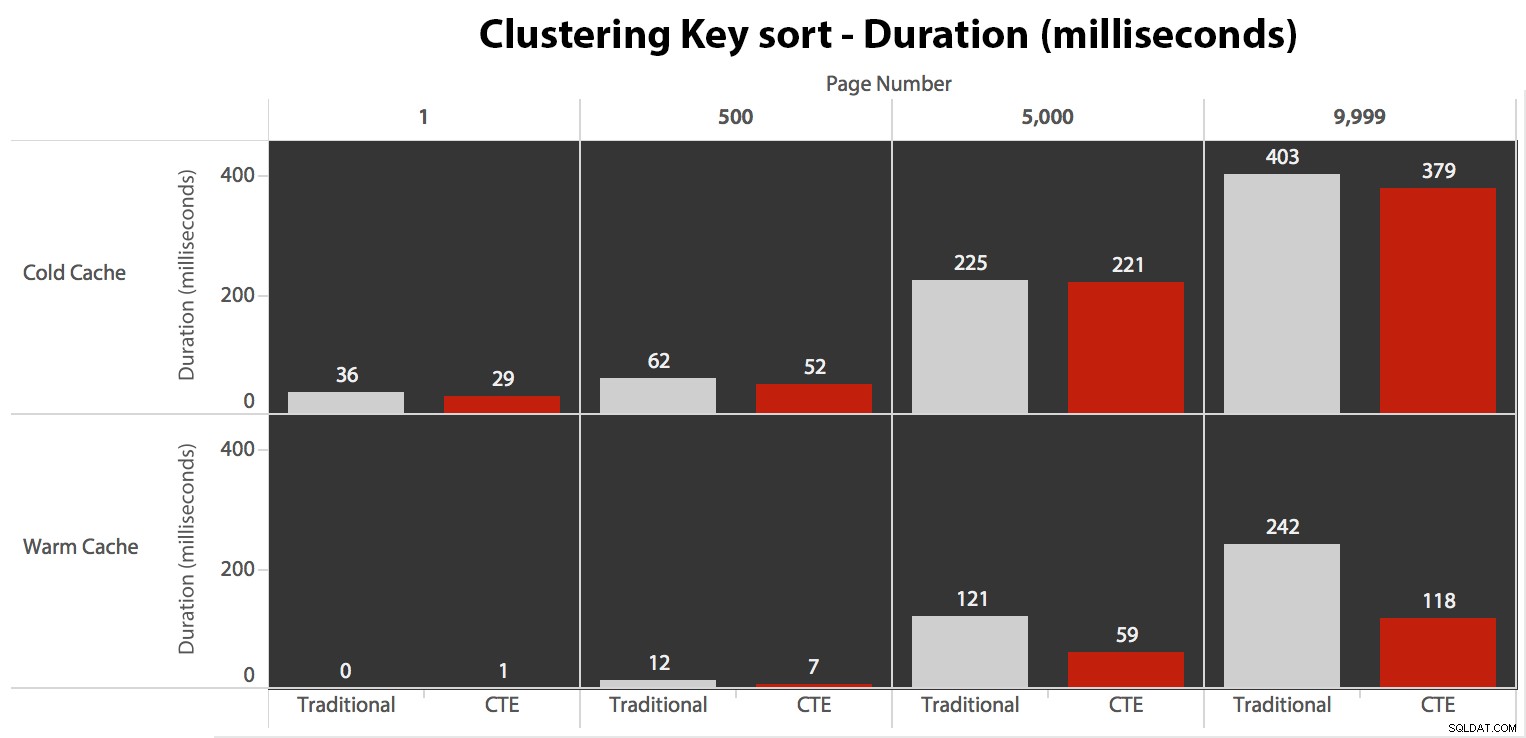
Mentre puoi vedere uno schema che mostra la durata che aumenta man mano che il numero di pagina aumenta, tieni presente la scala:per raggiungere le righe 999.801 -> 999.900, stiamo parlando di mezzo secondo nel peggiore dei casi e di 118 millisecondi nel migliore dei casi. L'approccio CTE vince, ma non di molto.
Test dell'ordinamento della rubrica
Successivamente, ho testato il secondo caso, in cui l'ordinamento era supportato da un indice non coprente su LastName, FirstName. La query sopra ha appena cambiato tutte le istanze di Test_1 a Test_2 . Ecco le letture utilizzando una cache fredda:
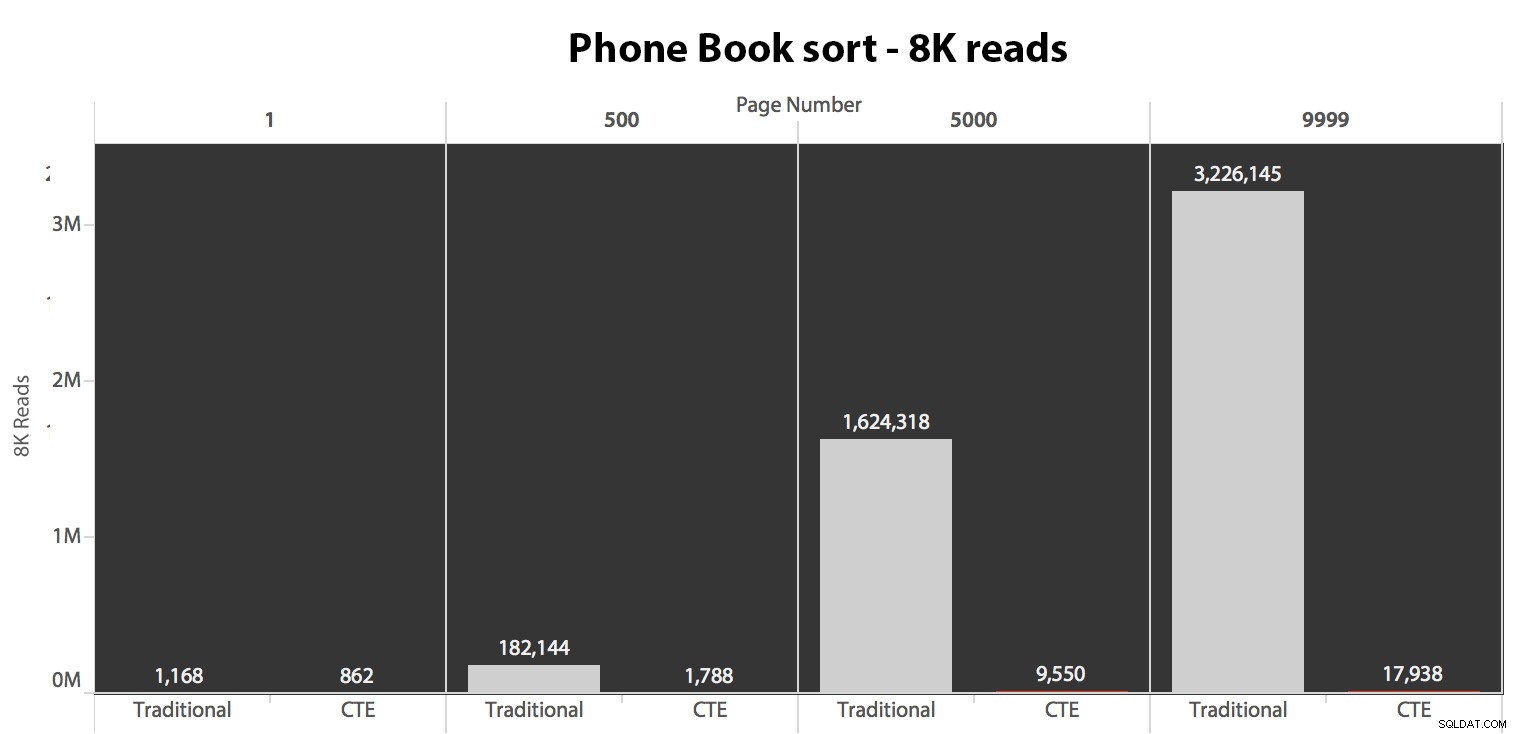
(Le letture in una cache calda hanno seguito lo stesso schema:i numeri effettivi differivano leggermente, ma non abbastanza da giustificare un grafico separato.)
Quando non utilizziamo l'indice cluster per l'ordinamento, è chiaro che i costi di I/O coinvolti con il metodo tradizionale di OFFSET/FETCH sono molto peggiori rispetto a quando si identificano prima le chiavi in un CTE e si estraggono il resto delle colonne solo per quel sottoinsieme.
Ecco il piano per l'approccio di query tradizionale:
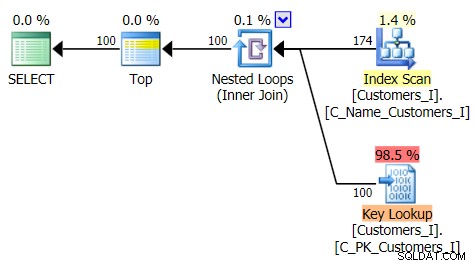
E il piano per il mio approccio alternativo, CTE:
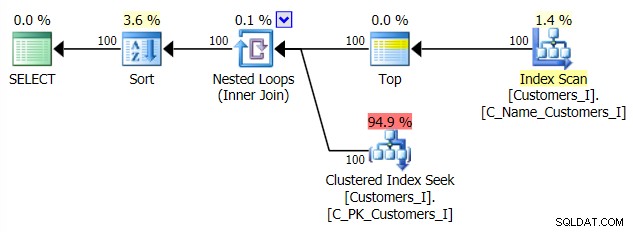
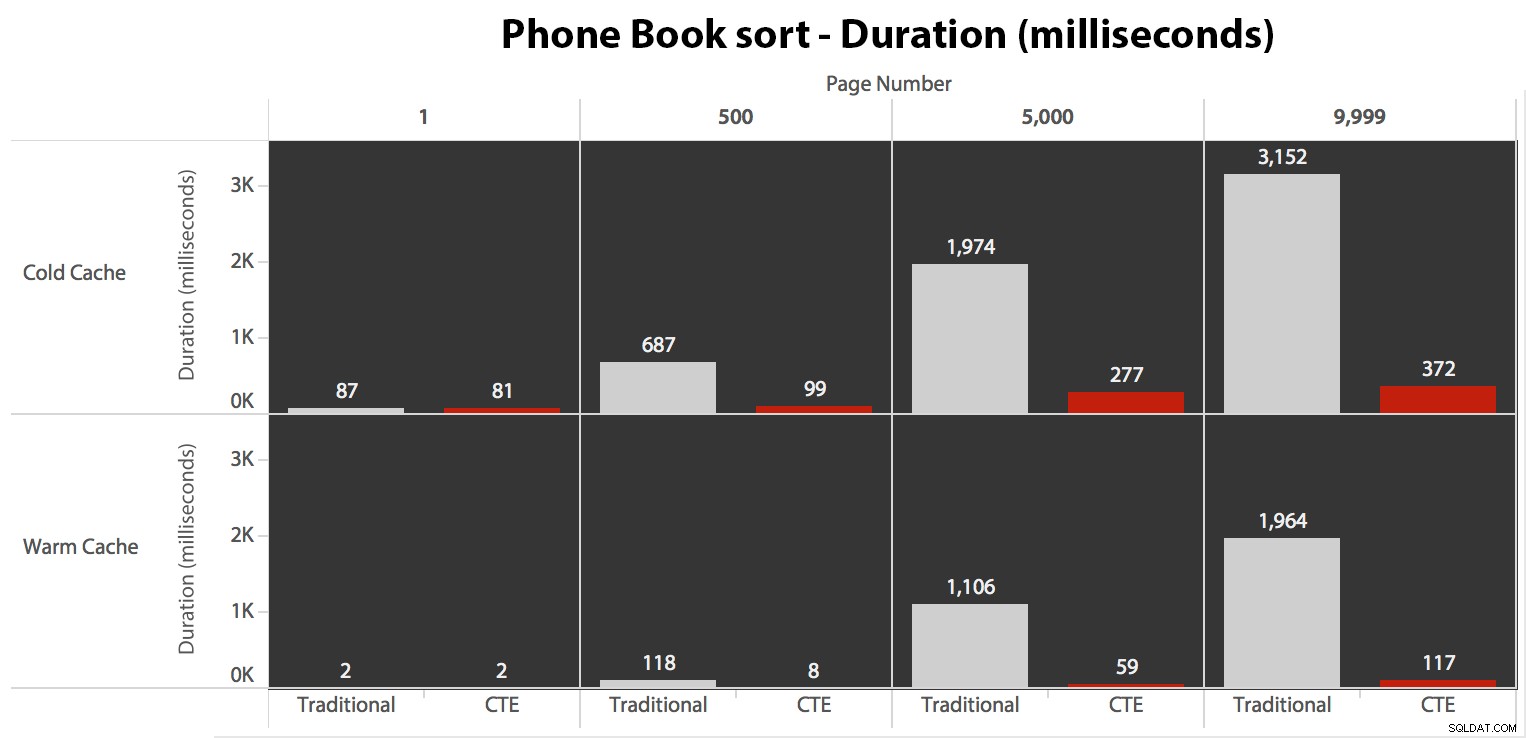
Infine, le durate:
L'approccio tradizionale mostra un aumento molto evidente della durata mentre si procede verso la fine dell'impaginazione. L'approccio CTE mostra anche uno schema non lineare, ma è molto meno pronunciato e produce tempi migliori a ogni numero di pagina. Vediamo 117 millisecondi per la penultima pagina, rispetto all'approccio tradizionale che arriva a quasi due secondi.
Test dell'ordinamento definito dall'utente
Infine, ho modificato la query per utilizzare il Test_3 stored procedure, verificando il caso in cui l'ordinamento è stato definito dall'utente e non disponeva di un indice di supporto. L'I/O era coerente in ogni serie di test; il grafico è così poco interessante, ho solo intenzione di collegarlo ad esso. Per farla breve:ci sono state poco più di 19.000 letture in tutti i test. Il motivo è che ogni singola variazione doveva eseguire una scansione completa a causa della mancanza di un indice per supportare l'ordinamento. Ecco il piano per l'approccio tradizionale:
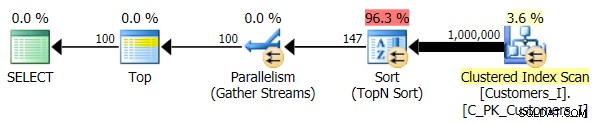
E mentre il piano per la versione CTE della query sembra allarmantemente più complesso...
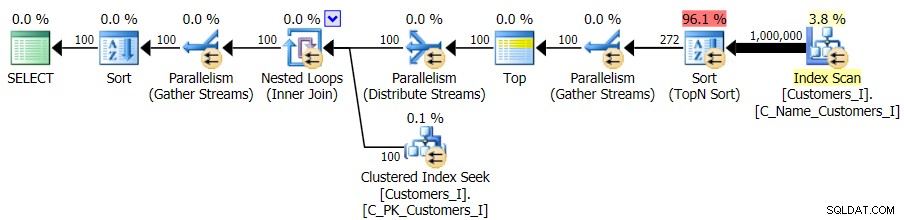
...porta a durate inferiori in tutti i casi tranne uno. Ecco le durate:
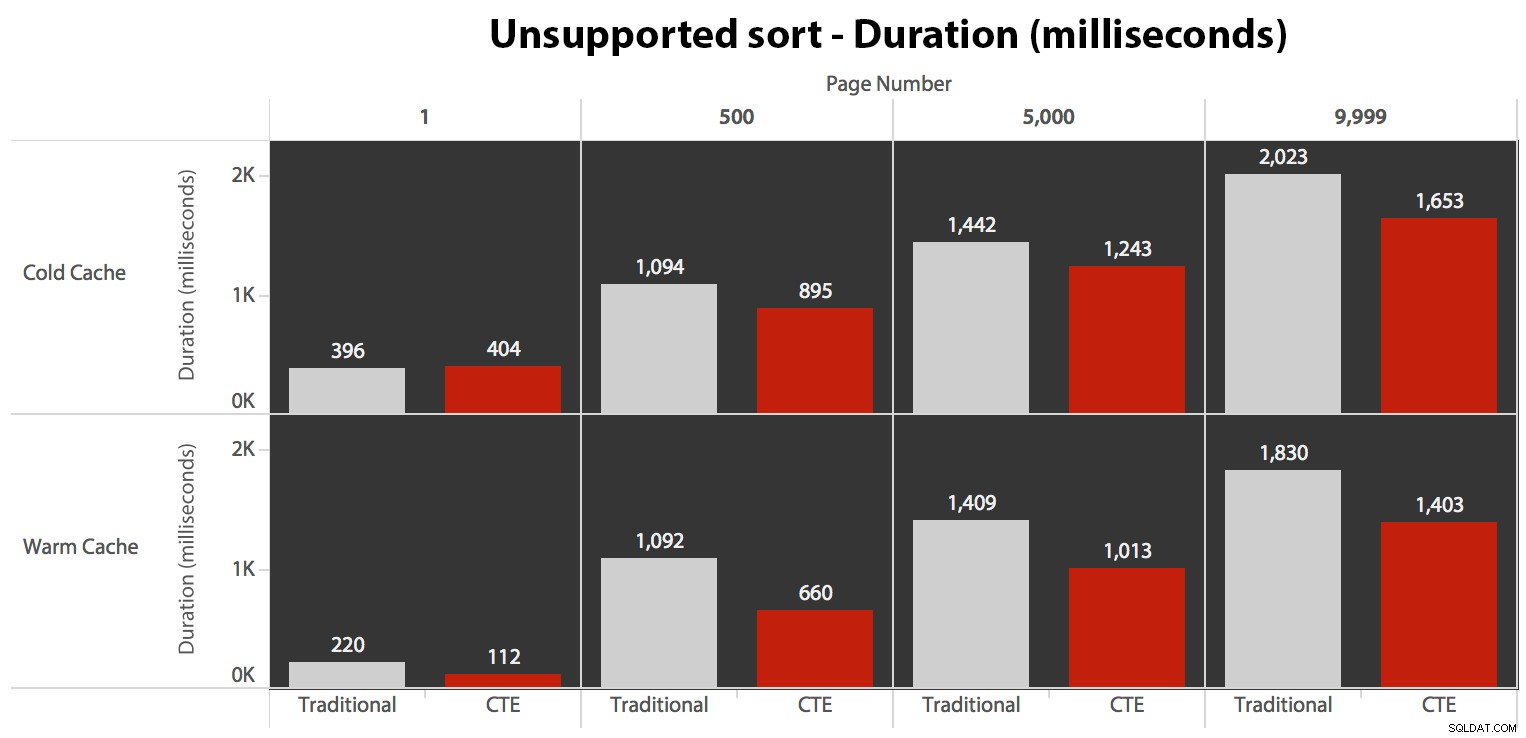
Puoi vedere che non possiamo ottenere prestazioni lineari qui usando nessuno dei due metodi, ma il CTE è in cima con un buon margine (ovunque dal 16% al 65% in più) in ogni singolo caso tranne la query della cache fredda rispetto al primo pagina (dove ha perso di ben 8 millisecondi). Interessante anche notare che il metodo tradizionale non è affatto aiutato da una cache calda nel "mezzo" (pagine 500 e 5000); solo verso la fine del set è degna di nota qualsiasi efficienza.
Volume maggiore
Dopo aver testato individualmente alcune esecuzioni e aver preso le medie, ho pensato che avrebbe anche senso testare un volume elevato di transazioni che simulassero in qualche modo il traffico reale su un sistema occupato. Quindi ho creato un lavoro con 6 passaggi, uno per ogni combinazione di metodo di query (paginazione tradizionale vs. CTE) e tipo di ordinamento (chiave cluster, rubrica e non supportato), con una sequenza di 100 passaggi per colpire i quattro numeri di pagina sopra , 10 volte ciascuno e altri 60 numeri di pagina scelti a caso (ma lo stesso per ogni passaggio). Ecco come ho generato lo script di creazione del lavoro:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
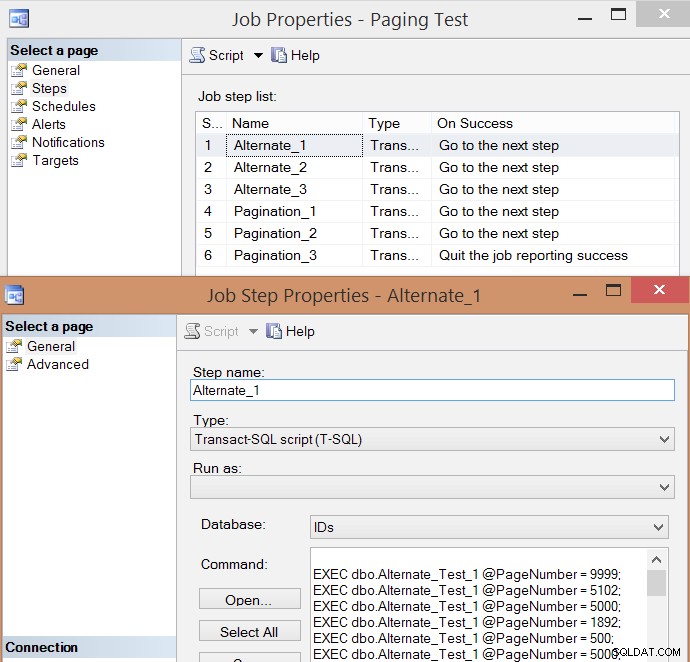
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Ecco l'elenco delle fasi del lavoro risultante e una delle proprietà della fase:
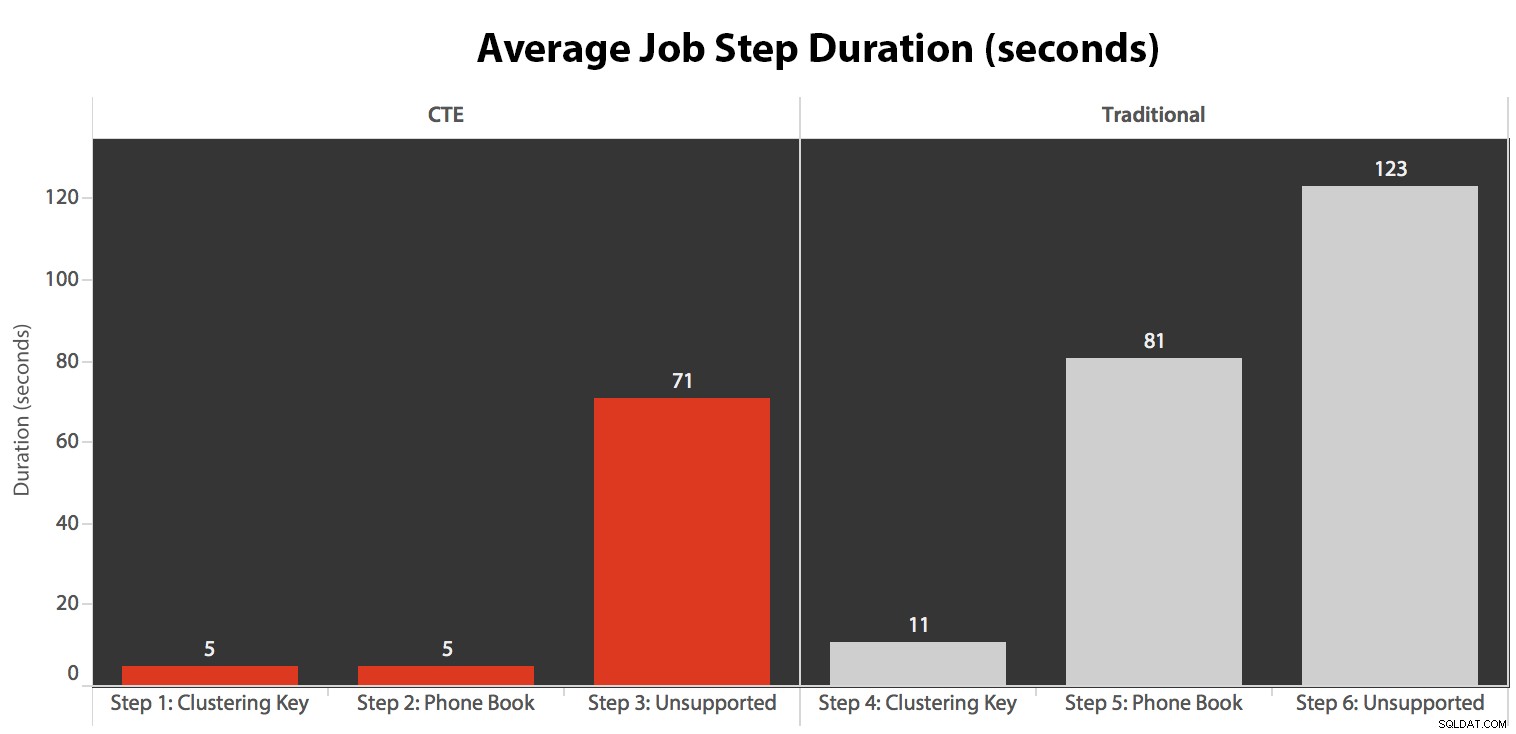
Ho eseguito il lavoro cinque volte, quindi ho rivisto la cronologia dei lavori ed ecco i tempi di esecuzione medi di ogni passaggio:
Ho anche correlato una delle esecuzioni nel calendario di SQL Sentry Event Manager...
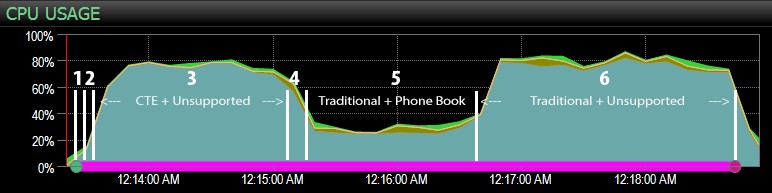
...con il dashboard di SQL Sentry e contrassegnato manualmente approssimativamente dove è stato eseguito ciascuno dei sei passaggi. Ecco il grafico dell'utilizzo della CPU dal lato Windows della dashboard:
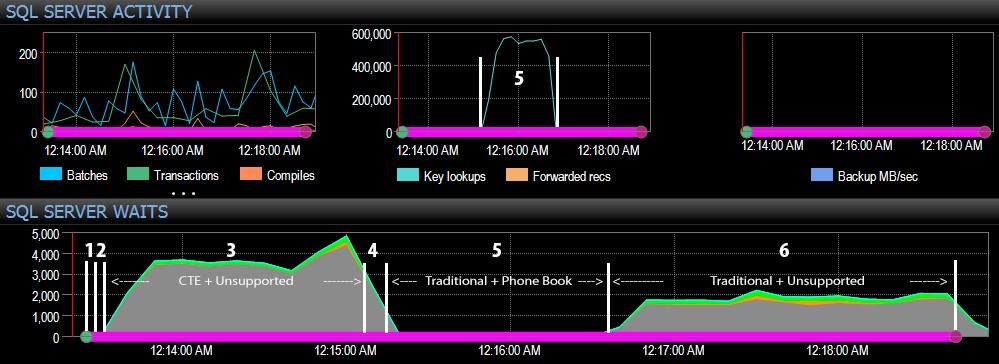
E dal lato SQL Server della dashboard, le metriche interessanti erano nei grafici Key Lookups e Waits:
Le osservazioni più interessanti solo da una prospettiva puramente visiva:
- La CPU è piuttosto calda, intorno all'80%, durante la fase 3 (CTE + nessun indice di supporto) e la fase 6 (tradizionale + nessun indice di supporto);
- Le attese di CXPACKET sono relativamente elevate durante il passaggio 3 e in misura minore durante il passaggio 6;
- puoi vedere l'enorme aumento delle ricerche di chiavi, a quasi 600.000, in circa un minuto (corrispondente al passaggio 5, l'approccio tradizionale con un indice in stile rubrica telefonica).
In un test futuro, come con il mio precedente post sui GUID, vorrei testarlo su un sistema in cui i dati non si adattano alla memoria (facile da simulare) e dove i dischi sono lenti (non così facile da simulare) , dal momento che alcuni di questi risultati probabilmente traggono vantaggio da cose che non tutti i sistemi di produzione hanno:dischi veloci e RAM sufficiente. Dovrei anche espandere i test per includere più variazioni (usando colonne sottili e larghe, indici sottili e larghi, un indice della rubrica che copre effettivamente tutte le colonne di output e l'ordinamento in entrambe le direzioni). Lo scope creep ha decisamente limitato la portata dei miei test per questa prima serie di test.
Come migliorare l'impaginazione di SQL Server
L'impaginazione non deve essere sempre dolorosa; SQL Server 2012 semplifica sicuramente la sintassi, ma se colleghi semplicemente la sintassi nativa, potresti non vedere sempre un grande vantaggio. Qui ho dimostrato che una sintassi leggermente più dettagliata utilizzando un CTE può portare a prestazioni molto migliori nel migliore dei casi e differenze di prestazioni probabilmente trascurabili nel peggiore dei casi. Separando la posizione dei dati dal recupero dei dati in due diversi passaggi, possiamo vedere un enorme vantaggio in alcuni scenari, al di fuori di attese CXPACKET più elevate in un caso (e anche in questo caso, le query parallele sono terminate più velocemente delle altre query visualizzando poche o nessuna attesa, quindi era improbabile che fossero le "cattive" attese di CXPACKET di cui tutti ti avvertono).
Tuttavia, anche il metodo più veloce è lento quando non è presente un indice di supporto. Anche se potresti essere tentato di implementare un indice per ogni possibile algoritmo di ordinamento che un utente potrebbe scegliere, potresti prendere in considerazione la possibilità di fornire meno opzioni (poiché sappiamo tutti che gli indici non sono gratuiti). Ad esempio, la tua applicazione deve assolutamente supportare l'ordinamento per Cognome crescente *e* Cognome decrescente? Se vogliono andare direttamente dai clienti i cui cognomi iniziano con Z, non possono andare all' *ultima* pagina e tornare indietro? Questa è una decisione aziendale e di usabilità più che tecnica, mantienila come opzione prima di schiaffeggiare gli indici su ogni colonna di ordinamento, in entrambe le direzioni, al fine di ottenere le migliori prestazioni anche per le opzioni di ordinamento più oscure.